
I admit I was a little skeptical going into KubeCon 2025. The last time I went, in 2022, it felt tactical. I heard lots of conversations around small solutions to small problems. Practical knowledge-sharing is of course beneficial, but I’m most inspired by the big picture — ideally, a picture bigger than you can see anywhere outside of your mind.
I’m heartened to say that KubeCon 2025 was exactly that. The well-attended Atlanta event’s hallways and sessions were filled with engineers thinking about big problems that served ambitious visions.
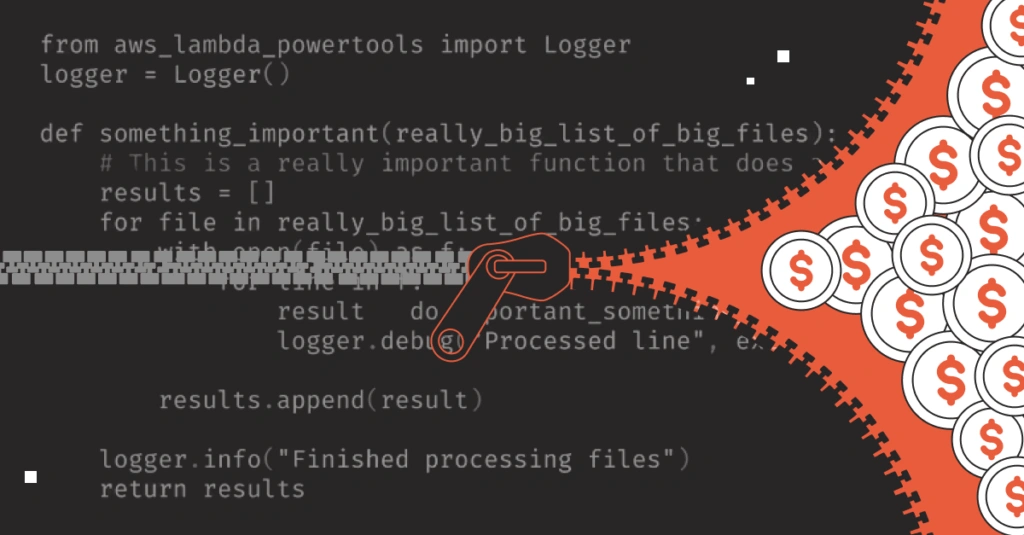
It was never more apparent than at a keynote delivered by Fabian Ponce, technical staff member at OpenAI, who spoke about how eliminating a single rogue line of code recovered 30,000 CPU cores for the burgeoning AI behemoth.
One line of code. 30,000 CPU cores.
The entire crowd was leaning in, hanging on every word. 10 petabytes of logs. 35% of OpenAI’s CPU time. Increased capacity, increased performance, cleaner code, better architecture.
The only metric that was missing? Cost.
To me, it begs the question: Why? Why not put a dollar value — nay, a value value — on it? It would have added yet another oh-sh*t moment to a presentation full of them.
I wanted that moment — for myself, and for engineers in general. So, with the help of OpenAI’s flagship work assistant, I got some credible estimates.


Let’s conservatively estimate it’s on the lower side of that midpoint: $25M. One line of code. $25M. Any takers?
Conception Of Money
Still, $25M alone doesn’t tell the whole story.
As any business leader knows, it’s not just about how impressive the number is, but what that number means, in a concrete business context.
Which, for a number like $25M, isn’t easy to intuitively grasp, partly due to evolutionary limitations. “The human brain is built to understand how much of something is in its environment,” writes NPR. When processing numbers that exceed what we can manually count, “‘we’re recycling these sort of evolutionarily old brain architectures to do something really new,’” per Stanford neuroscientist Elizabeth Toomarian.
To put it in engineering terms, it’s like using a bare-metal data center to do the job of an elastic cloud cluster..
We can see this play out in reality. When you’ve got $25 in your wallet, you can instinctively link that dollar value to its meaning in the world. It’s a movie ticket and popcorn, a couple drinks with your boss, an inexpensive meal on the way to your gate at the airport.
But what if you had $25M in your wallet? Excepting the mega-billionaires in our midst, none of us can instinctively connect that to some kind of lived experience.
Even in a corporate context, where numbers of that size are more common, it’s not simple to know exactly what that $25M means. It could mean extra headcount in one organization or many. It could mean better office space in a more central hub. It could mean equipment upgrades or expanded benefits. What you use it for depends on a wide array of conditions that require intense use of the prefrontal cortex (the newest part of our brain) by all of the highest-ranking members of your organization.
In short: We don’t instinctively assign a dollar value to efficiency gains of Ponce’s type because we don’t instinctively know what those dollar values mean.
I so badly want to change that.
What $25M inherently means, regardless of who saves it: Better-architected systems, systems that burn substantially less fuel in achieving their goals. A car that uses 20% less fuel — gas, electricity, shampoo, or whatever your car runs on — to get from point A to point B is obviously a better car. A chatbot that costs $25M less to generate the same level of revenue is obviously a better chatbot — all the more because it lets you reinvest in innovation.
playbook
The AI Cost Optimization Playbook
Traditional cloud cost management is broken. Here’s why — and how to make the switch to cloud cost intelligence.
A Few Tenths Of A Percent
So let’s get back to what that $25M means for OpenAI’s business.
The highest-level way to conceptualize business impact is in terms of unit cost metrics: representations of your incremental costs in terms of a central demand driver — i.e., what it costs to generate the demand that’s most valuable to your company.
According to our mutual acquaintance, ChatGPT, OpenAI probably leans on a trio of central demand drivers:


A few more inferences later, ChatGPT and I estimated that OpenAI improved their cost per token by as much as a few tenths of a percentage point — call it 0.3%.
Is 0.3% worth writing home about? For a company of OpenAI’s size, and for an optimization that effectively boiled down to deleting a line of code, hell yes it is. Partly because it’s an enormously efficient deployment of engineering resources — to find the code, to save the money, and to reinvest what they saved — and also because of what it represents culturally.
An engineering culture that prioritizes efficiency, quantifies wins, and celebrates those stories creates a positive feedback loop. OpenAI’s 30,000 CPU core reduction won’t be an isolated incident. Engineers will continually find efficiencies of all sizes that represent not just dollar amounts, but quality, performance, and business value.
I was heartened by KubeCon 2025. I imagine I’ll be even more heartened by KubeCon 2026, when everyone has learned how critical it is to frame efficiency wins in terms of business value.











