Amazon Simple Storage (S3) has become a cornerstone in the world of cloud computing, offering scalable and secure object storage solutions for a wide range of applications.
However, as data accumulates over time, managing it in an efficient manner becomes a challenge. This is where S3 lifecycle policies and lifecycle rules shine.
These rules allow us to automate the transition of data between different storage classes and even schedule automatic deletions, which allows users to optimize costs and operational efficiency.
In this article, we’ll delve into the intricacies of S3 Lifecycle Rules, explaining how they work and how you can implement them to make your data management more effective and cost-efficient.
Table Of Contents
Overview Of Lifecycle Rules
Let’s begin by defining what Lifecycle Rules are: Amazon S3 Lifecycle Rules are a set of regulations that define actions to be taken on objects within an S3 bucket over the course of their lifetime.
These policies help in automating the management of your data, thereby reducing storage costs and simplifying compliance requirements. S3 Lifecycle Rules essentially fall into one of two actions:
Transition actions
Transition actions are responsible for moving objects between different storage classes at pre-defined age intervals. Useful for optimizing storage costs based on how frequently the data is accessed.
Typical use-cases
- Archiving infrequently accessed data to S3 Glacier or S3 Glacier Deep Archive
- Moving frequently accessed data to S3 Standard for better performance
Expiration actions
Expiration actions are responsible for automatically deleting objects after a specified period. This is useful for removing obsolete or temporary data.
Typical use-cases
playbook
The AI Cost Optimization Playbook
Traditional cloud cost management is broken. Here’s why — and how to make the switch to cloud cost intelligence.
Components Of A Lifecycle Rule
Now that we have a general understanding of what Lifecycle Rules are, we can begin to go over the components that make up a rule. Upon selecting the bucket you wish to create the rule for within the AWS console, you’ll see an assortment of tabs that you can select from.
To create a Lifecycle Rule, select the ‘Management’ tab.
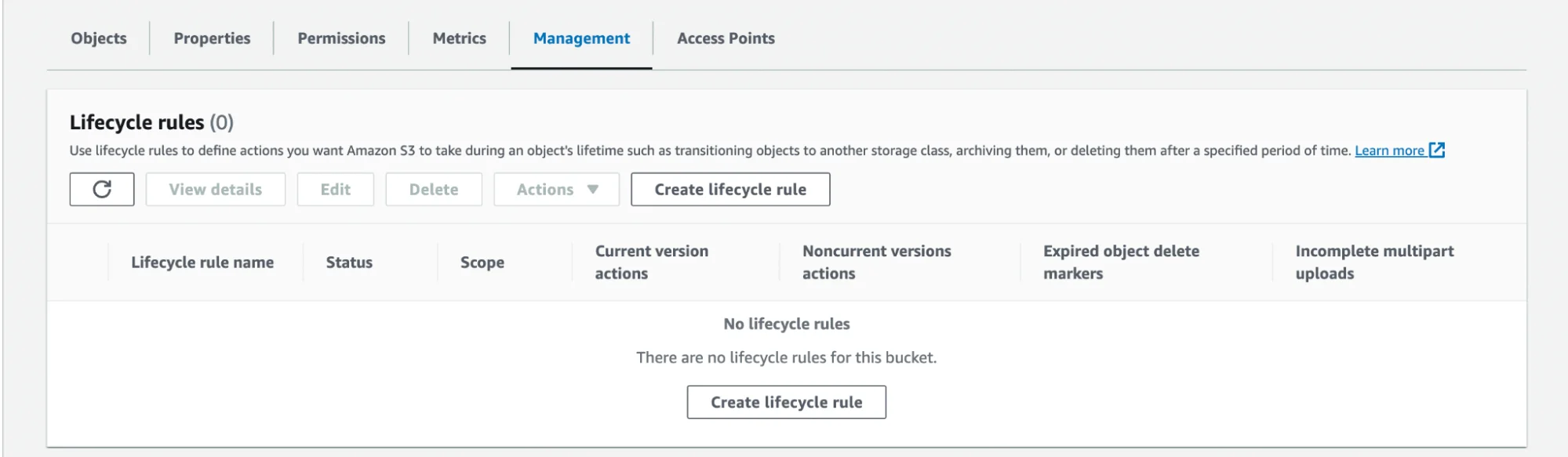
After selecting ‘Create lifecycle rule’, you’ll be presented with the rule configuration screen that will allow you to define the actual components of your policy.
These include the following:
- Rule Name – Define a name for the rule that will identify it appropriately.
- Scope – Do we want the rule to apply to all objects within the bucket, or do we want to use a filter to limit what is affected?
- Filter types – If we choose to filter, you can accomplish this by matching tags, prefixes, or size.
- Lifecycle Rule Actions – These are the individual actions that our policy can perform on our behalf.
- Transition current versions of objects between storage classes – Select this action if you want to move the current version of objects between different storage classes based on your use case scenario and performance access requirements. These transitions start from when the objects are created and are consecutively applied.
- Transition noncurrent versions of objects between storage classes – Select this action to move noncurrent versions of objects between storage classes based on your use case scenario and performance access requirements. These transitions start from when the objects become noncurrent and are consecutively applied.
- Expire current versions of objects – For version-enabled buckets, Amazon S3 adds a delete marker and the current version of an object is retained as a noncurrent version. For non-versioned buckets, Amazon S3 permanently removes the object.
- Permanently delete noncurrent versions of objects – Choose when Amazon S3 permanently deletes specified noncurrent versions of objects.
- Delete expired object delete markers or incomplete multipart uploads – This action will handle the deletion of both incomplete multipart uploads and object delete markers.
- Expired object delete markers – This action will remove expired object delete markers and may improve performance. An expired object delete marker is removed if all noncurrent versions of an object expire after deleting a versioned object. This action is not available when “Expire current versions of objects” is selected.
- Incomplete multipart uploads – This action will stop all incomplete multipart uploads, and the parts associated with the multipart upload will be deleted.
Upon defining each of these rules, you’re able to see a handy image that breaks down all of the rules that are currently in place:

Why Transition Objects Between S3 Storage Classes?
So, we now understand the process of creating a rule, but we should also take some time to understand the reasoning behind transitioning our data between different classes. Let’s take a moment to familiarize ourselves with the different tiers and what their primary use-case is:
Standard
- Use case: Frequently accessed data (think website content or actively used applications)
- Durability and availability: High
- Cost: Moderate
Intelligent-Tiering
- Use case: Data with unknown or changing access patterns that are unpredictable. Automatically moves between frequent and infrequent access tiers — learn more about how Intelligent-Tiering works.
- Durability and availability: High
- Cost: Moderate to low, depending on access pattern
One Zone-Infrequent Access (One Zone-IA)
- Use case: Infrequently accessed data that can be recreated if lost, stored in one single availability zone
- Durability and Availability: Low
- Cost: Low
Standard-Infrequent Access (Standard-IA)
- Use case: Data that is less frequently accessed but requires rapid access when needed
- Durability and availability: High
- Cost: Lower than standard but higher than One Zone-IA
Glacier
- Use case: Archival data that may be accessed infrequently and can tolerate accessibility delays
- Durability and availability: High
- Cost: Low
- Retrieval time: Minutes to hours
Glacier Deep Archive
- Use case: Long-term archival, such as compliance and regulatory data, which is rarely accessed
- Durability and availability: High
- Cost: Very Low
- Retrieval time: Hours to days
The primary reason for using Lifecycle Rules is S3 cost optimization.
For example, you might initially store data in the Standard class for anything that is frequently being accessed.
However, as data becomes less frequently accessed over time, it may be more cost-efficient to move it to Infrequent Access (IA) or One-Zone IA classes, which offer lower storage costs at the expense of slightly lower availability.
In conclusion, AWS S3 Lifecycle Rules are an incredibly powerful tool for any organization looking to optimize storage costs without sacrificing data availability or durability.
By setting up these rules, you can automate the transition of your data across various storage classes, each tailored to specific access patterns and cost points.
This ensures that you’re not paying premium prices for data that is infrequently accessed, while still keeping it readily available for those times when it is needed.
Take action today by reviewing your current S3 storage costs and implementing lifecycle rules that align with your data’s lifecycle needs. The savings in both time and money will make it a worthwhile investment!