

You’re funding AI across four billing relationships – Anthropic direct, OpenAI, Claude through Bedrock, Claude through Vertex – and the spend climbs every month. When your CEO asks what it’s producing, you have a number and no answer. Not which product it built, which customer it served, or which bet it’s paying off. And you’re being asked to approve more of it.
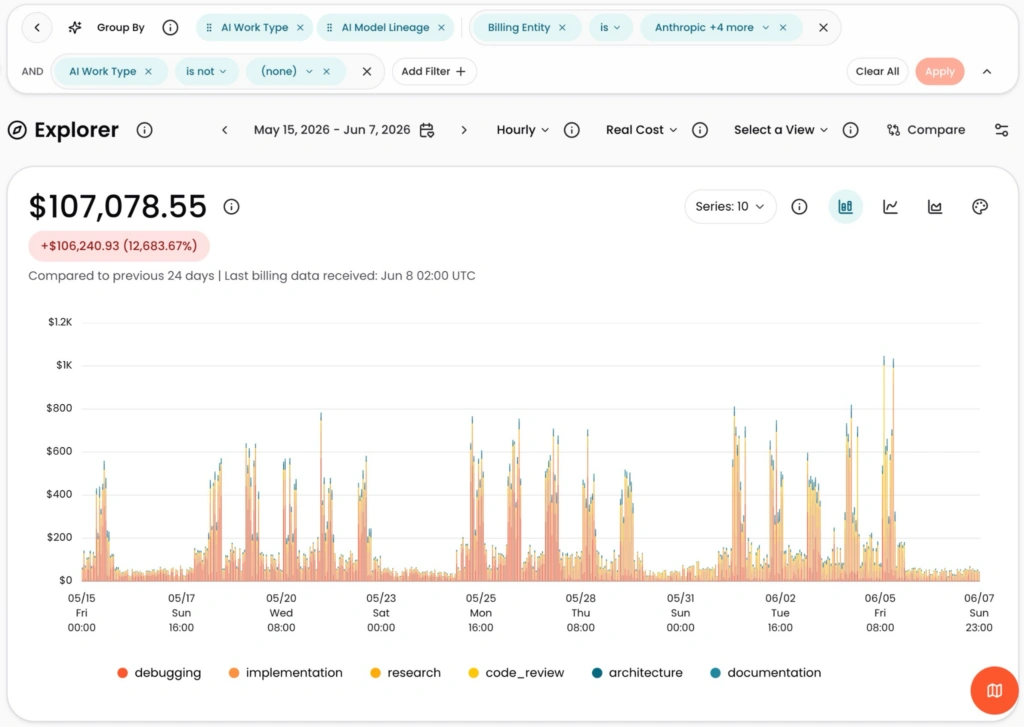
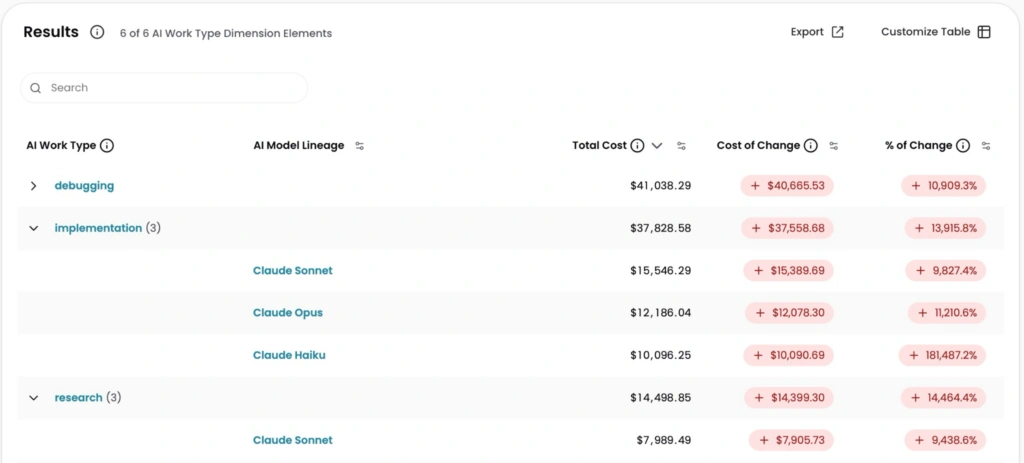
Now you can answer that. Every call, whether Anthropic or OpenAI, direct or through Bedrock or Vertex, shows up within seconds of firing. Within minutes it’s broken out by model, provider, agent, and user. Within hours it’s fully allocated across every dimension you track: team, product, customer, the bet it’s funding, to finance-grade accuracy. Not a sampled export. Not the bill three days late.
Seeing what you spent is the easy part now. Every gateway meters it, and the model providers give the breakdown away for free. That’s all the rest of this market sells you: activity metrics. Tokens burned, calls made, a bill sliced by team and model. They tell you what got used, never what it produced – and that’s the question a bill was never going to answer, no matter how finely you slice it.
Why this matters
The hard part is running more than one provider. Claude direct, Claude through Bedrock, Claude through Vertex, GPT through the gateway: different endpoints, different billing, and nothing downstream reconciles them into a number you can trust. No hyperscaler will normalize cost across its competitors’ models. No gateway will tie that spend to the outcome you’re measured on. That gap is structural, and it’s where this lives.
What we built
None of this is a new product. It’s the allocation engine that’s costed CloudZero customers’ spend in production for ten years (14 trillion billing events a year, built to pass the financial audits our customers put it through), now fed with real-time AI data. You point your gateway’s OpenTelemetry output at CloudZero. From then on every request carries its tokens, model, and provider into the engine, along with whatever business context you’ve tagged onto your virtual keys. It lives at the gateway — one integration point, no code changes to your apps.
How design partners use it
This is in design partners’ hands now. Point an existing LiteLLM gateway at us and you start seeing AI spend allocated by team and repo – Anthropic and OpenAI traffic through the same path, no new instrumentation. If you run a gateway and want your AI spend tied to outcomes instead of metered by token, this is the fastest way in.
Talk to us about the design partner program.











