
Every prompt you send and every response you generate in OpenAI is broken down into tokens.
OpenAI bills you separately for input tokens and output tokens, with different rates depending on the model you’re using.
Token counts don’t behave like static numbers. In production, they grow as prompts evolve, conversation history accumulates, and retrieval context expands.
That often means a feature that looked cheap in staging can become 5X more expensive without any significant increases in your user volume.
So, if you’re building AI-powered features in production (not just experimenting), you need to understand how the true OpenAI cost per token actually works.
Let’s start by looking at what OpenAI cost per token really means.
What Cost Per Token Actually Means In OpenAI Pricing
OpenAI cost per token refers to how OpenAI meters usage behind the scenes. The platform bills your usage per token. A token in OpenAI is the smallest unit of text the model processes across everything you send into the model (input) and everything it generates in response (output).
A token is not the same as a word. OpenAI uses sub-word tokenization, which means:
- Common words might be a single token
- Rare words might be split into multiple tokens
- Punctuation and whitespace can count as tokens
- JSON, code, and structured formats affect token counts
- Emojis, non-English text, and special characters skew the counts even further
So 1,000 words of plain English prose might be about 750 to 1,300 tokens. But that 1,000 “words” (of JSON, SQL, Python, markdown, log files, and retrieved knowledge base text) can easily be 2X–5X more tokens than you expected.
Something else to note here. Because each prompt will comprise a varying number of words and figures, two API calls that look similar will cost different amounts because the two don’t contain the same number of tokens.
See more about OpenAI pricing and tokens in our more in-depth guide here.
Also, output usually costs more
That pricing structure matters because it creates two very different cost profiles:
- Use cases like summarization and classification are usually input-heavy and output-light.
- Use cases like drafting, chatbots, and code generation are often output-heavy.
So depending on how input-heavy or output-heavy a call is, one might process 200 tokens, while another may count 5,000.
How do you convert OpenAI’s “$ per 1M tokens” pricing?
OpenAI publishes prices in dollars per 1 million tokens, with separate rates for input tokens, cached input tokens (for some models), and output tokens.
To convert these rates into usable numbers, use two formulas:
- Cost per token = (price per 1M tokens) ÷ 1,000,000
- Cost per 1K tokens = (price per 1M tokens) ÷ 1,000
For example, if a model costs $10 per 1M input tokens, then: Cost per token = $0.00001, and Cost per 1K tokens = $0.01.
That conversion step is what lets you translate OpenAI’s pricing table into cost per prompt, cost per feature run, cost per customer action, and beyond.
We’ll use this exact math later when we walk through some real SaaS examples.
OpenAI API cost per token pricing (current rates snapshot)
OpenAI pricing is published per model, per token type, and per million tokens. And those prices change over time as new models are introduced, upgraded, or retired.
Always confirm current rates on OpenAI’s live pricing page before making a purchase decision.
Also note that OpenAI no longer offers legacy models in production. All current usage routes through GPT–5–class models and newer ones.
Moreover, pricing is tied to the exact model ID you call today, not to any historical model family. There is no longer a separate “legacy model” tier or special pricing for older generations.
That said, let’s get into it.
Report
Finance needs to prove AI’s return: CloudZero report
260 senior finance leaders (more than half CFOs) told us why the speed of seeing AI spend, not the size of it, separates who pulls ahead on AI from who gets burned.
How To Understand OpenAI’s Pricing Table
When you look at OpenAI’s pricing page, focus on just three things:
1. The exact model ID
2. Separate rates for:
- Input tokens
- Cached input tokens
- Output tokens
3. The unit in dollars per 1 million tokens
Everything else is secondary.
Once you have those three numbers, you’re ready to calculate your cost per token. And that’s exactly what we’ll do next.
How To Calculate OpenAI Cost Per Token (Step-By-Step)
We’ll start with the clean formula, then layer in the real-world factors that usually get missed.
At its simplest, OpenAI’s cost per request is:
Cost = (input tokens × input rate)
- (cached input tokens × cached input rate, if applicable)
- (output tokens × output rate)
Where:
- Input tokens represent everything you send to the model
- Output tokens cover everything the model generates
- Rates refer to dollars per token (derived from the $ per $1M token calculation).
This formula works for single-turn prompts, chat interactions, RAG workflows, and tool-augmented calls.
As long as you count the tokens correctly.
Step 1: Convert OpenAI’s pricing into usable rates
For any token type:
- Cost per token = (price per 1M tokens) ÷ 1,000,000
- Cost per 1K tokens = (price per 1M tokens) ÷ 1,000
For example:
If your model charges:
- $8 per 1M input tokens
- $24 per 1M output tokens
Then:
- Input cost per token = $0.000008
- Output cost per token = $0.000024
Step 2: Identify all sources of your input tokens
Many teams underestimate input tokens because in production, input isn’t limited to the user’s prompt. Input tokens also include:
- System prompt and instructions
- Developer messages and policies
- Conversation history you retain
- Retrieved context (RAG chunks, documents, embeddings output)
- Tool definitions or schemas
- Formatting and serialization overhead (JSON, XML, Markdown)
A simple mental model:
Input tokens = user prompt + everything else you attach to it
Clearly, if you only count the visible user text, your estimate will be off.
Step 3: Estimate your output tokens
Output tokens are easier to reason about, but still prone to underestimation.
Some common drivers of output growth here include:
- Open-ended generation without strict max tokens
- Long explanations and reasoning traces
- Multi-step tool responses, and
- Verbose default response styles.
If you don’t explicitly constrain output length, the model will usually generate more tokens than you expect with high variance across requests.
That’s why output tokens are often the dominant cost driver in chatbots, code generation, and long-form drafting.
Step 4: Account for multi-turn context
In multi-turn systems, each new request often includes:
- The original system prompt
- The last X user messages
- The last X model responses
That means the same conversation gets more expensive with every turn.
Here’s a quick example.
- Turn 1 input: 400 tokens
- Turn 2 input: 400 + previous 400 + previous output
- Turn 3 input: 400 + two prior turns
- …and so on.
So, even if you keep typing short messages, your input tokens will compound.
Step 5: Include cached input when applicable
Some current-generation models support cached input pricing.
That means:
- If a large portion of your prompt repeats across requests
- And the model supports caching
- You may pay a discounted rate for those repeated tokens
This usually applies to large, static system prompts, reused instruction blocks, and repeated templates.
That said, you’ll want to be aware of two caveats here:
- Cached input only helps if the text is identical
- It only applies to models that explicitly support it
So, if your prompts change frequently, caching won’t materially reduce your OpenAI costs.
Related Resources:
Cost Per Token Examples When Using OpenAI
Using the math we just did, let’s look at two quick production use cases you likely already see.
Example 1: Support chatbot reply
Assume that:
- Input:
- system prompt: 300 tokens
- user message: 150 tokens
- conversation history: 550 tokens
- total input = 1,000 tokens
- Output: Model reply = 250 tokens
- Rates: Input is $0.008 per 1K tokens and output costs $0.024 per 1K tokens
Cost calculation:
- Input cost = (1,000 tokens ÷ 1,000) × $0.008 = $0.008
- Output cost = (250 tokens ÷ 1,000) × $0.024 = $0.006
- Total per reply: $0.014
At 100,000 replies per month, total cost = $1,400.
Example 2: Multi-turn conversation
Let’s assume that Turn 1:
- Input = 500 tokens
- Output = 200 tokens
- Cost would be $0.009
Turn 4 (after we’ve accumulated history):
- Input = 1,800 tokens
- Output = 220 tokens
- The cost comes to $0.021
Same user. Same feature. But more than 2X the cost per turn.
And that right there is why token growth, not traffic growth, often drives AI costs.
Token Budgeting: Here’s How To Set Guardrails For Your Token Usage
Once you understand how token growth happens, the next question is:
How do you stop it from feasting on your margins?
One of the most effective answers we’ve seen in production systems is to treat tokens like a budgeted resource, not as an unlimited byproduct.
That means you’ll want to give each AI feature an explicit token budget. That’s just as you would for latency, memory, or error rates.
What is a token budget exactly (and how do you create a good one)?
A token budget defines the maximum token footprint a single invocation of a feature is allowed to consume.
It usually includes a maximum number of input tokens, a maximum number of output tokens, and a target cost per invocation.
For example, a search summarization feature can have a token budget of:
- Max input: 1,200 tokens
- Max output: 250 tokens
- Target cost: ≤ $0.004 per run.
Anything that exceeds those limits is treated as a bug, a regression, or a deliberate product decision — not an accident.
How to create a practical token budget
Some best practices we are seeing teams use include setting token budgets along three dimensions.
Input token ceiling
This caps how large you allow a request to be.
Common strategies here include setting hard limits on system prompt size, retrieved context size, and the length of conversation histories.
If a request exceeds the ceiling, the system must truncate, summarize, or reject it.
Output token ceiling
This caps how verbose the model is in its responses.
The typical controls here are to set the max output tokens, response length classes (short, medium, long), and format constraints (JSON schemas, fixed fields).
This is the single most effective control for chatbots, code generation, and long-form drafts.
Cost-per-invocation target
This ties token usage directly to business economics. So, instead of saying,“This feature can use 2,000 tokens,” you’ll want to say:
“This feature must cost ≤ $0.005 per run.”
Then you work backward by asking:
- Which model can meet that?
- How much context can you afford?
- How much output can you allow?
Where token budgets should live
Token budgets are only useful if they’re enforced close to the code a.k.a. By engineering. High-performing teams usually:
- Define budgets in code or config
- Version them like any other dependency
- Validate them in CI
- Alert when they’re exceeded
For example, you can reject any request with input tokens greater than the budget. Or, you can truncate the context when limits are exceeded.
This helps you turn token control into an engineering concern instead of a finance afterthought.
A practical rule of thumb
When you’re designing or reviewing an AI feature, ask: “Is this workload primarily input-driven or output-driven?”
Then:
- If it’s input-driven, optimize retrieval size, context windows, and system prompt length.
- If it’s output-driven, optimize max output tokens, response formats, and verbosity controls.
- If it’s balanced, assume higher variance, higher monitoring needs, and tighter guardrails from day one.
Oh, one more thing.
Turn Token Math Into Real AI Cost Control
If you’re already tracking token usage, the next step is turning that data into something your teams can actually act on.
Not just this:

But also this:

And also this:
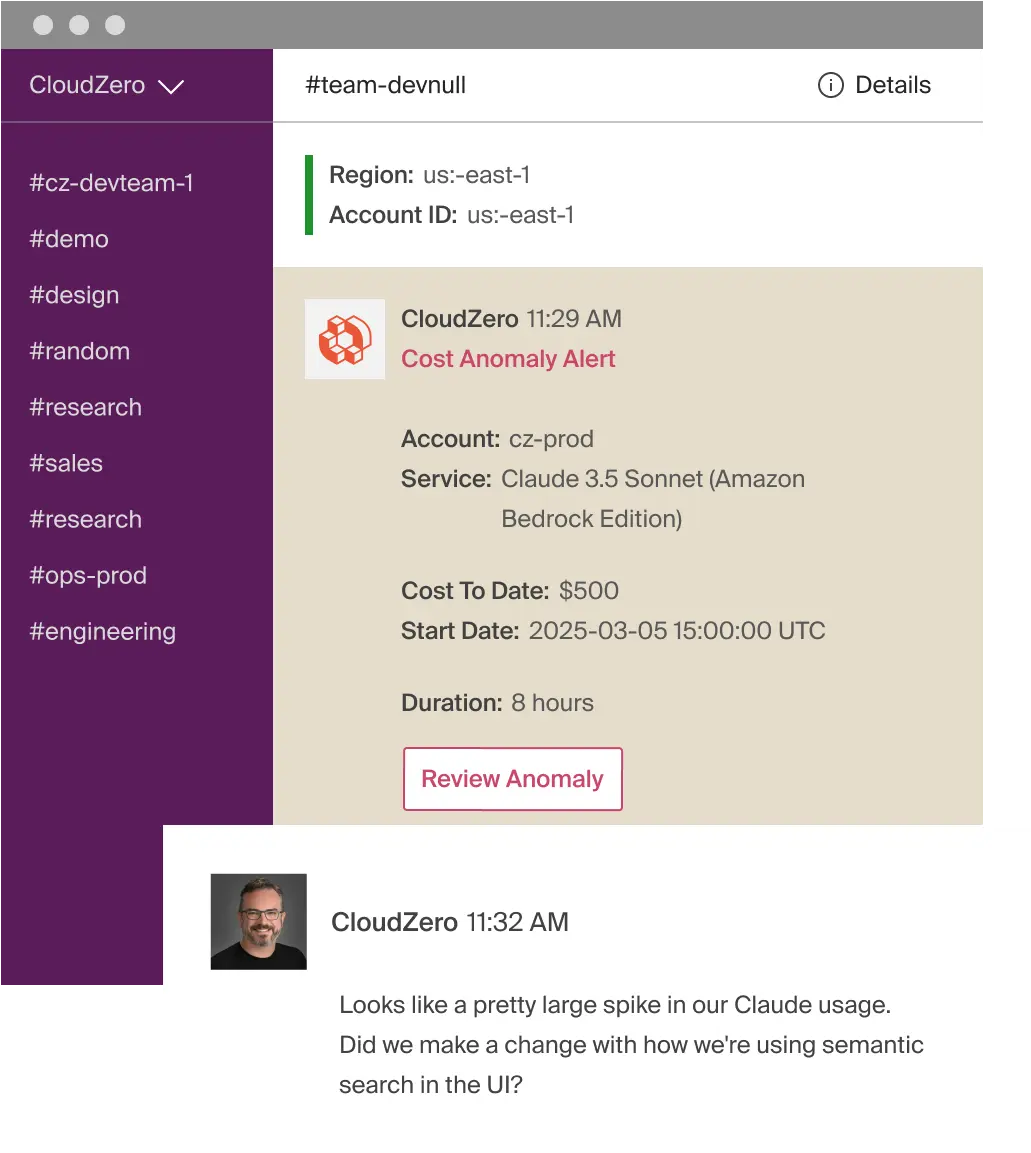
With CloudZero, you get that and more. You also give your engineering, FinOps, and finance teams a shared view of how your OpenAI token usage connects to real business context. So everyone can see:
- Which features are driving AI spend, so you can optimize the right things
- Where token growth is eroding margins, so you can pinpoint what to cut and what to keep, and
- Which design decisions are changing your AI unit economics, so you can prevent surprises before they hit your P&L.
All in real time, not weeks later, so you can protect your margins when it matters — well before the damage is done.
If you’re ready to move from understanding OpenAI cost per token to controlling it at scale,  to see why AI-driven teams at Grammarly, Skyscanner, and Coinbase use CloudZero to keep their AI costs visible, predictable, and tied directly to product decisions.
to see why AI-driven teams at Grammarly, Skyscanner, and Coinbase use CloudZero to keep their AI costs visible, predictable, and tied directly to product decisions.
FAQs
What does OpenAI cost per token mean?
OpenAI cost per token is the price you pay for each unit of text processed by a model, including both input and output tokens.
Is a token the same as a word in OpenAI?
No. A token can be part of a word, a whole word, punctuation, code, or even whitespace.
Does OpenAI charge differently for input and output tokens?
Yes. Input tokens and output tokens have separate prices, and output tokens usually cost more.
Why does OpenAI pricing use “per 1M tokens” instead of per request?
Because OpenAI prices usage, not requests. Each request can contain vastly different token counts.
How do you calculate OpenAI cost per token?
Divide the price per 1M tokens by 1,000,000 to get cost per token.
How do you calculate OpenAI cost per API call?
Multiply input tokens by the input rate, then add output tokens multiplied by the output rate.
Why do OpenAI costs increase over time without more users?
Because token usage grows as prompts expand, context accumulates, and conversations become multi-turn.
What causes token usage to spike in production?
Common causes include long system prompts, retained conversation history, RAG context, and unconstrained output length.
Are output tokens usually the biggest cost driver?
Yes. Chatbots, drafting, and code generation are typically output-heavy and more expensive.
What is cached input pricing in OpenAI?
Cached input is discounted pricing for repeated prompt text, available only on supported models.
Does cached input significantly reduce OpenAI costs?
Only if large prompt sections are identical across requests and the model supports caching.
Why is OpenAI cost hard to forecast?
Because pricing scales with token usage, not traffic, infrastructure, or fixed capacity.
What is a token budget?
A token budget sets a maximum number of input and output tokens per feature invocation.
Why should token budgets be enforced in code?
Because token growth is an engineering problem, not a finance problem discovered after billing closes.
What is OpenAI cost per token vs. cost per feature?
Cost per token measures usage. Cost per feature translates that usage into real product economics.











