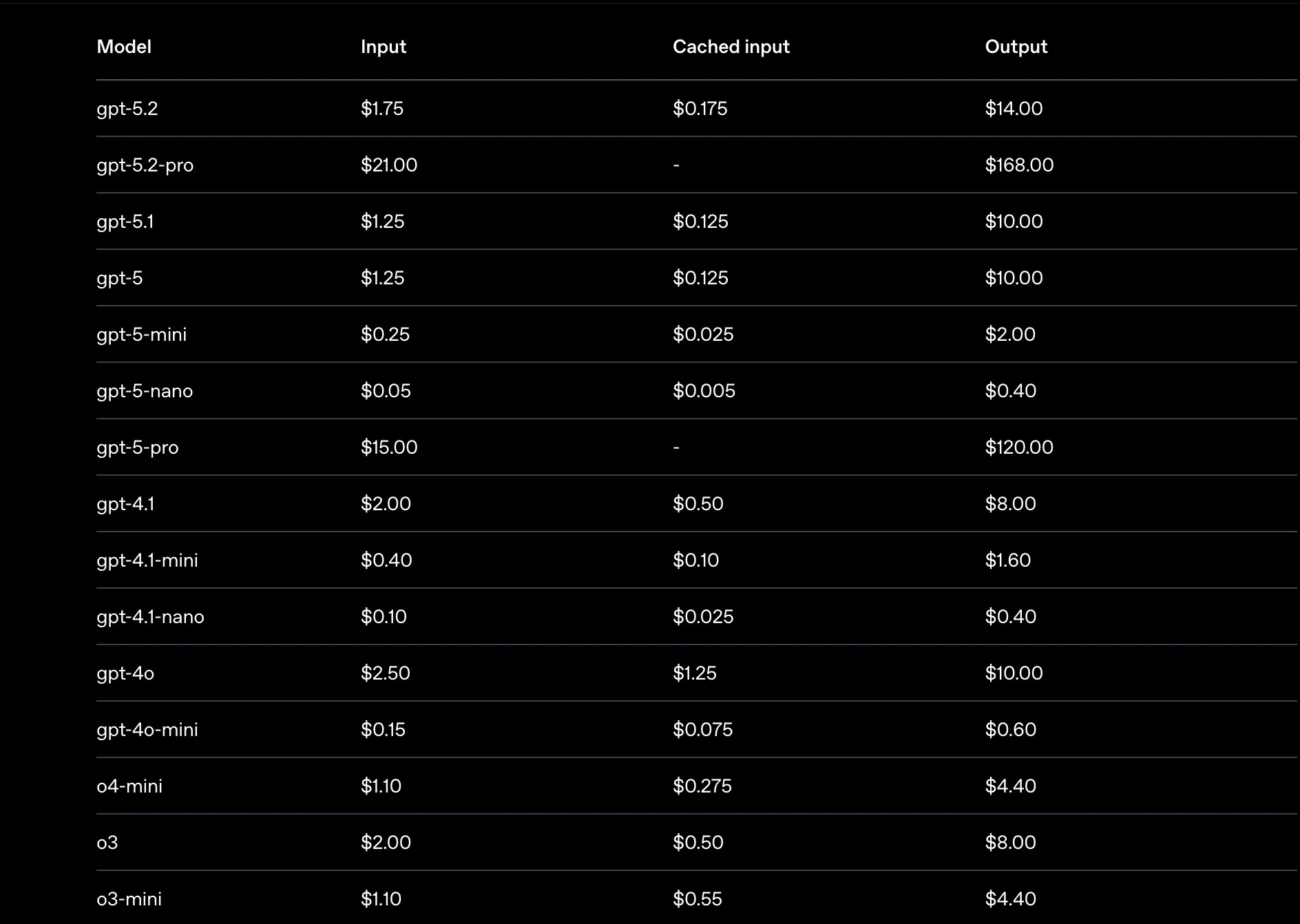
Quick answer: How much does the OpenAI API cost? OpenAI API cost depends on the model you choose and the number of tokens you process. Input pricing ranges from $0.20 per million tokens (GPT-5.4 Nano) to $30.00 per million tokens (GPT-5.4 Pro). Output tokens cost more, ranging from $1.25 to $180.00 per million. A SaaS team routing 10,000 daily support queries through GPT-5.4 Mini, averaging 500 input tokens and 300 output tokens per query, spends about $518 per month. Costs scale directly with usage, and the model you pick is the single biggest lever on your bill.
How Does OpenAI API Pricing Work?
OpenAI uses a usage-based pricing model. You pay per token processed through the API, with separate rates for input tokens (what you send) and output tokens (what the model generates).
There is no flat monthly fee for API access.
A token is roughly three-quarters of a word in English. Every API call consumes input tokens for the prompt you send and output tokens for the response you receive. Both count toward your bill, but output tokens usually cost 4 to 6 times more than input tokens because they need more compute to generate.
OpenAI bills in increments of one million tokens. A single API call might cost a fraction of a cent, but those fractions compound fast at scale. A SaaS product serving 10,000 daily active users can easily process hundreds of millions of tokens per month.
This usage-based structure makes OpenAI flexible for prototyping, but it also means costs are unpredictable without monitoring. Engineering teams often discover their monthly bill has doubled before anyone notices a spike in token consumption. For organizations running OpenAI at scale, this is fundamentally an AI cost management problem — and it requires visibility, allocation, and optimization at the model level.
Related: Tracking your OpenAI spend in real time
Report
Finance needs to prove AI’s return: CloudZero report
260 senior finance leaders (more than half CFOs) told us why the speed of seeing AI spend, not the size of it, separates who pulls ahead on AI from who gets burned.
What Is The OpenAI API Cost By Model?
OpenAI’s current flagship is the GPT-5.4 family, released March 5, 2026, with Mini and Nano variants following on March 17. Here is what each model costs.
GPT-5.4 family pricing

Source: OpenAI API pricing page, verified April 2026.
Batch API offers a 50% discount on all models. Cached input pricing for Mini and Nano follows the same 90% discount pattern as Standard but confirm exact rates on OpenAI’s pricing page.
The difference between Standard and Nano is 12x on input. That gap means model selection alone can turn a $1,200/month workload into a $100/month workload if the task does not need flagship-level reasoning.
Legacy and specialized model pricing
For the full model catalog, including Codex, open-weight, and deep research models, see OpenAI’s complete model list.
OpenAI embeddings pricing
OpenAI offers two embedding models for search, classification, and RAG workloads. Text-embedding-3-small costs $0.02 per million tokens and works well for most retrieval tasks.
Text-embedding-3-large costs $0.13 per million tokens and produces higher-dimension vectors for use cases that need more precision. Both are dramatically cheaper than calling a full LLM, making embeddings the first place to look when building AI-powered search or recommendation features.
OpenAI fine-tuning pricing
Fine-tuning lets you train OpenAI models on your own data. GPT-4.1 is one of OpenAI’s flagship models available for fine-tuning, with training priced at roughly $3.00 per million tokens.
After training, fine-tuned GPT-4.1 inference typically costs around $3.00 per million input tokens and $12.00 per million output tokens, making it more expensive than the base model.
GPT-4.1 Mini offers a lower-cost option, with training at about $0.80 per million tokens and inference at roughly $0.80 input and $3.20 output.
OpenAI may offer discounted pricing for users who opt into data sharing, depending on program terms.
What Drives Your OpenAI API Cost?
Five factors determine how much you actually pay.
Model choice is the biggest lever. GPT-5.4 Nano costs $0.20 per million input tokens. GPT-5.4 Pro costs $30.00 for the same volume. That is a 150x price difference for the same number of tokens.
Token volume compounds quickly. A chatbot handling 10,000 conversations per day averaging 500 input tokens and 300 output tokens processes 240 million tokens monthly. On GPT-5.4 Mini, that costs about $518/month. On GPT-5.4 Standard, the same volume costs $1,725/month.
Context window usage affects every call. GPT-5.4 supports up to 272K tokens at standard pricing. Prompts exceeding that length trigger a surcharge: 2x on input ($5.00 per million) and 1.5x on output ($22.50 per million) for the full session. Long system prompts, retained conversation history, and RAG context all increase token counts.
Caching reduces costs when prompts share common prefixes. OpenAI automatically caches repeated input content. Cached tokens on GPT-5.4 Standard cost $0.25 per million instead of $2.50 — a 90% discount. Applications with consistent system prompts benefit the most.
Output length is often overlooked. Output tokens cost 4 to 6 times more than input tokens across all models. An unconstrained response that returns 2,000 tokens costs six times more than a response capped at 300 tokens, even though the input was identical.
Related: What factors influence your OpenAI bill
How Do You Calculate Your OpenAI API Cost?
Use this formula to estimate cost per API call:
Cost per call = (input tokens / 1,000,000 x input price) + (output tokens / 1,000,000 x output price)
Here’s an example:
A customer support chatbot sends a 400-token system prompt plus a 100-token user message (500 input tokens) and receives a 300-token response (300 output tokens), using GPT-5.4 Mini.
- Input cost: 500 / 1,000,000 x $0.75 = $0.000375
- Output cost: 300 / 1,000,000 x $4.50 = $0.00135
- Total cost per call: $0.001725 (roughly $0.002)
At 10,000 calls per day, that is $17.25/day or roughly $518/month.
To estimate your own monthly bill, multiply the cost per call by your expected daily call volume and multiply by 30. If your system prompt is reused across calls, apply caching discounts to the shared portion of the input.
For a quick estimate without manual math, OpenAI’s usage dashboard tracks token consumption in real time and projects monthly spend based on current usage patterns.
CloudZero also connects directly to OpenAI to help teams forecast monthly spending with more precision. The integration ingests your OpenAI cost and usage data, then uses your actual token consumption patterns to project future spend by model, feature, customer, or team.
OpenAI API Cost: Real-world SaaS Examples
These examples use GPT-5.4 family pricing as of April 2026 with conservative token estimates.
1. Customer support chatbot
A SaaS company routing 10,000 support queries per day through an AI chatbot. Each query averages 500 input tokens and 300 output tokens.
|
Model |
Monthly input cost |
Monthly output cost |
Total monthly cost |
GPT-5.4 Standard |
$375 |
$1,350 |
$1,725 |
GPT-5.4 Mini |
$113 |
$405 |
$518 |
GPT-5.4 Nano |
$30 |
$113 |
$143 |
Most support chatbots do not need flagship reasoning. GPT-5.4 Mini handles FAQ-style responses and troubleshooting workflows effectively, cutting your total OpenAI cost by 70% compared to Standard.
2. Analytics reporting assistant
A product analytics feature where 2,000 users generate 10 reports per month. Each report averages 2,000 input tokens (data context plus prompt) and 500 output tokens.
Model | Monthly input cost | Monthly output cost | Total monthly cost |
GPT-5.4 Standard |
$100 |
$150 |
$250 |
GPT-5.4 Mini |
$30 |
$45 |
$75 |
GPT-5.4 Nano |
$8 |
$13 |
$21 |
Structured reporting is a strong fit for Nano. When the output format is predictable (e.g., JSON, tables, summaries), the cheapest model often performs well enough. Comparing OpenAI model costs across tiers is the fastest path to lower bills.
3. Semantic search with embeddings
Indexing 10 million documents at an average of 500 tokens each using text-embedding-3-small ($0.02 per million tokens).
- One-time indexing cost: 5 billion tokens x $0.02/1M = $100
- Monthly query cost (1 million queries, 1,000 tokens each): 1 billion tokens x $0.02/1M = $20/month
Embeddings are dramatically cheaper than LLM inference. The OpenAI token cost for embeddings is a fraction of a cent per query, making them the first option for search, classification, and recommendation workloads.
4. Audio transcription (OpenAI Whisper API pricing)
The OpenAI Whisper API cost depends on audio length. A company transcribing 500 hours of customer calls and internal meetings per month pays $0.006 per minute.
- 500 hours = 30,000 minutes
- OpenAI Whisper API cost per minute: $0.006
- Monthly cost: 30,000 x $0.006 = $180/month
For teams evaluating OpenAI Whisper API pricing, the per-minute rate makes transcription one of the most affordable OpenAI services, even at high volume.
Related: How CloudZero’s OpenAI integration delivers AI unit economic insights
OpenAI API Cost Vs. Alternatives: Model Comparison
OpenAI is not the only option. As of April 2026, GPT-5.4 Mini at $0.75 input is the most competitive mid-tier model on the market — cheaper than Claude Haiku 4.5 and Gemini 2.5 Flash on input. GPT-5.4 Nano at $0.20 undercuts nearly every alternative. Here is how the full lineup compares.
|
Model |
Provider |
Input (per 1M tokens) |
Output (per 1M tokens) |
Context window |
Best for |
GPT-5.4 Standard |
OpenAI |
$2.50 |
$15.00 |
272K (up to 1M) |
General-purpose, coding, computer use |
GPT-5.4 Mini |
OpenAI |
$0.75 |
$4.50 |
400K |
High-volume chat, content generation |
Claude Sonnet 4.6 |
Anthropic |
$3.00 |
$15.00 |
200K (up to 1M |
Nuanced writing, instruction-following |
Claude Haiku 4.5 |
Anthropic |
$1.00 |
$5.00 |
200K |
Fast, lightweight tasks |
Claude Opus 4.6 |
Anthropic |
$5.00 |
$25.00 |
1M |
Complex reasoning, agentic tasks, nuanced analysis |
Gemini 3.1 Pro (preview) |
|
$2.00 |
$12.00 |
1M |
Long-context reasoning and analysis |
Gemini 2.5 Flash |
|
$0.25 |
$1.50 |
1M |
Budget inference at scale |
DeepSeek V3.2 |
DeepSeek |
$0.28 |
$0.42 |
128K |
Budget chat, classification, extraction |
Sources: OpenAI, Anthropic, Google, DeepSeek. Verified April 2026.
The key takeaway on OpenAI model pricing: GPT-5.4 Mini at $0.75 input is 4x cheaper than Claude Sonnet 4.6 on input, while GPT-5.4 Nano at $0.20 is the cheapest proprietary model available — undercutting Gemini 3.1 Flash-Lite ($0.25) and sitting just below DeepSeek V3.2 ($0.28). For teams running multi-model architectures, mixing providers based on task complexity is the most cost-effective approach.
Related: DeepSeek pricing: models, how it works, and saving tips
Azure OpenAI Cost Vs. Direct API: Which Should You Use?
Azure OpenAI Service offers the same OpenAI models pricing through Microsoft’s cloud infrastructure. The OpenAI pricing model on Azure uses two approaches: pay-as-you-go (per-token, similar to the direct API) and provisioned throughput units (PTUs) for reserved capacity.
Pay-as-you-go rates on Azure are generally comparable to OpenAI’s direct pricing, but Azure adds value for enterprises that need data residency, private networking, or integration with existing Azure services. PTUs make sense for workloads with consistent, high-volume inference needs, since reserved capacity avoids per-token metering.
The tradeoff: Azure gives you compliance and infrastructure control. Direct API access gives you faster access to new models and features plus more transparent OpenAI API billing. Many teams use both, with Azure for production workloads and direct API for prototyping.
6 Ways To Reduce Your OpenAI API Cost
Controlling OpenAI costs starts with understanding where you have leverage. These six strategies target the biggest cost drivers in most production workloads.
1. Use the Batch API for non-urgent workloads
OpenAI’s Batch API processes requests asynchronously within 24 hours at 50% off standard OpenAI API pricing. For nightly data processing, bulk classification, or content generation pipelines, this is the single biggest cost lever available. GPT-5.4 Standard drops from $2.50/$15.00 to $1.25/$7.50 per million tokens.
2. Tier your models by task complexity
Not every API call needs the same model. Route simple classification and extraction to Nano ($0.20 input), use Mini ($0.75 input) for chat and summarization, and reserve Standard ($2.50 input) for complex reasoning. A tiered architecture can cut total spend by 60 to 80% compared to running everything on a single model. Review GPT-5 pricing tiers regularly as OpenAI adjusts rates with new releases.
3. Maximize cache hit rates
Structure API calls so shared content (system prompts, instructions, reference material) appears at the beginning of the prompt. OpenAI caches from the start of the input, so consistent prefixes yield the highest savings. Cached input on GPT-5.4 Standard costs $0.25 per million tokens instead of $2.50, a 90% reduction. This is one of the most effective ways to lower your OpenAI pricing per token.
4. Constrain output length
Set max_tokens on every API call. Unconstrained outputs generate more tokens than needed, and output tokens cost 4 to 6 times more than input tokens. Adding a simple instruction like “respond in under 150 words” to your system prompt can cut output token spend by 40% or more. That directly lowers your effective OpenAI API cost per token.
5. Use embeddings instead of LLM calls for search
Semantic search, classification, and recommendation tasks do not need a full LLM response. Text-embedding-3-small costs $0.02 per million tokens. That is 125 times cheaper than GPT-5.4 Standard for input. Pre-compute embeddings once, then query against them for pennies.
6. Monitor usage by feature, team, and customer
Token consumption that is invisible is token consumption that grows unchecked. Set up dashboards that track OpenAI pricing by the dimensions that matter to your business, not just total tokens. When you can see that Feature X costs $0.12 per user per month and Feature Y costs $0.003, you can make informed decisions about model selection, caching, and product pricing. CloudZero is the only cost intelligence platform that can help with that.
Related: 14 OpenAI cost optimization strategies
How Does CloudZero Track And Optimize OpenAI Costs?
Most teams track OpenAI spend at the billing level: total tokens consumed, total dollars spent.
That tells you what you spent, but not why or where.
CloudZero’s OpenAI integration ingests both cost and usage data from OpenAI’s APIs, then allocates that spend to the business dimensions that actually drive decisions: cost per customer, cost per feature, cost per AI model, cost per environment. This is the same unit economics approach CloudZero applies to AWS, Azure, GCP, Snowflake, and Datadog spend.
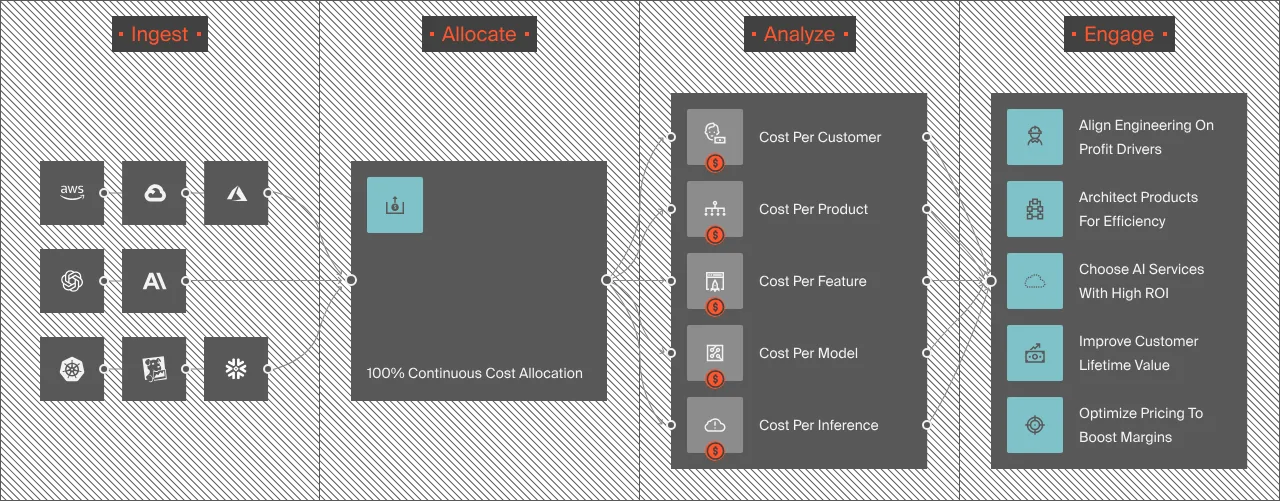
The result is granular visibility into questions like: How much does OpenAI API cost for Customer X? Which product feature consumes the most tokens per user? Is our inference spend growing faster than revenue?
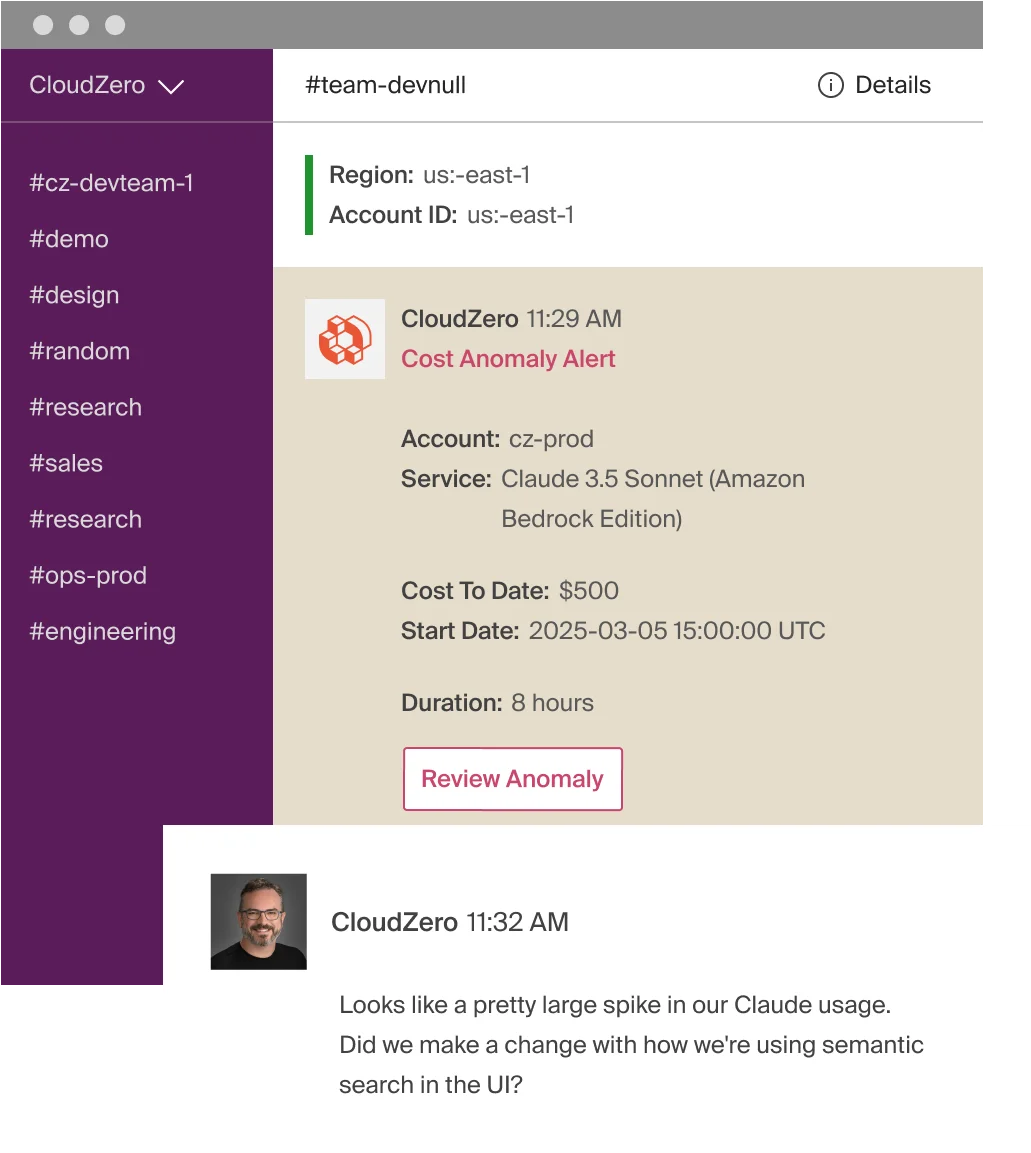
CloudZero also helps when your AI usage surpasses expected limits. The platform’s AI-powered anomaly detection monitors OpenAI spend on an hourly basis, comparing the last 36 hours against 12 months of historical data to define what “normal” looks like.
When a deployment, prompt change, or traffic spike pushes token consumption outside that baseline, CloudZero sends automated alerts directly to the engineers who own the affected infrastructure through Slack, Jira, or email. That gives your team time to investigate and fix the issue before a small spike turns into a runaway bill.
Teams using the integration have deployed it in minutes and gained 12 months of historical OpenAI cost data within 48 hours. One customer discovered that OpenAI accounted for 25% of their total cloud spend, a blind spot they had no way to quantify before.
Read more: How CloudZero’s OpenAI integration delivers AI unit economic insights
 to see how ambitious brands like Grammarly, Skyscanner, Duolingo, Toyota, and more use CloudZero to track and optimize their AI costs across models, teams, and features. You can also get a free cloud cost assessment to find out exactly where your OpenAI costs stand today.
to see how ambitious brands like Grammarly, Skyscanner, Duolingo, Toyota, and more use CloudZero to track and optimize their AI costs across models, teams, and features. You can also get a free cloud cost assessment to find out exactly where your OpenAI costs stand today.
Frequently Asked Questions About OpenAI API Cost











