If you are reading this, you likely understand how Machine Learning (ML) and Artificial Intelligence (AI) can improve your organization, from operational efficiency to boosting your bottom line.
Yet, setting up and running a robust AI infrastructure, including a massive dataset for training and specialized tools, can be expensive.
Amazon Bedrock wants to simplify this challenge, enabling you to build generative AI applications faster and easier. But is Amazon Bedrock pricing worth it?
We’ll explore this and other key considerations in the next few minutes.
What Is AWS Bedrock?
Amazon Bedrock simplifies the process of building and scaling generative AI applications. This involves providing your developers with the tools to create secure, compliant, and responsible AI solutions. That’s not all.
The following Bedrock features highlight the primary problems it solves for building and scaling generative AI applications:
1. Simplified access to Foundation Models
Your team can choose from a diverse range of FMs to identify the most suitable model for their specific use cases — all through a single API. Bedrock now offers 85+ foundation models from providers including Anthropic (Claude Opus 4.6, Sonnet 4.6, Haiku 4.5), Meta (Llama 4 Scout, Llama 4 Maverick), Mistral AI (Mistral Large 3), Amazon (Nova Micro, Lite, Pro, Premier), DeepSeek (V3.2), Google (Gemma 3), Cohere, and AI21 Labs.
This means you can experiment with and pick the most suitable models for your specific use cases without needing extensive AI model management expertise.
2. Supports private model customization
You can use proprietary data with techniques like fine-tuning and Retrieval Augmented Generation (RAG). This means you can tailor models to meet specific needs without compromising data security.
3. Fully managed serverless infrastructure
Its serverless architecture means you won’t need to manage the supporting infrastructure. You can focus on development rather than operational overhead to speed up innovation.
4. Solid security and privacy
Data is encrypted in transit and at rest, and access controls are enforced through AWS Identity and Access Management (IAM) policies.
5. Integrate easily with your AWS stack
Amazon Bedrock integrates with existing AWS services, so you can seamlessly incorporate generative AI capabilities into your workflows.
6. Rapid prototyping and deployment
The platform also supports quick experimentation and prototyping, swiftly helping your projects move from concept to production.
Report
Finance needs to prove AI’s return: CloudZero report
260 senior finance leaders (more than half CFOs) told us why the speed of seeing AI spend, not the size of it, separates who pulls ahead on AI from who gets burned.
What Can You Do With Bedrock?
Amazon Bedrock’s managed agents execute various complex business tasks by leveraging their ability to automate multi-step processes and integrate with company systems.
On top of generating text and images, Bedrock agents can also help you:
- Perform financial due diligence tasks such as analyzing global economic factors, assessing industry trends, and reviewing historical financial data, synthesizing the results into a comprehensive risk profile.
- Automate the insurance claims process by collecting information from users, verifying claims against eligibility policies, and managing the workflow of documentation required for claim approvals.
- Handle complex e-commerce interactions such as updating orders or managing exchanges, responding to customer inquiries about product availability, and executing necessary actions through API calls to the inventory system.
- Analyze customer retention data by breaking down the analysis into manageable steps.
- Manage retail operations tasks like demand forecasting, inventory allocation, supply chain coordination, and pricing optimization.
These capabilities aren’t free, of course. So, how does Amazon Bedrock pricing work?
AWS Bedrock Pricing Options And Examples
Amazon Bedrock pricing offers several tiers to match different workload patterns:
- On-Demand is the default pay-as-you-go option, ideal for unpredictable or experimental workloads. You pay per token (for text models) or per image (for image models) with no upfront commitment.
- Batch Mode offers the same models at up to 50% lower per-token pricing compared to on-demand. It suits large-scale or periodic tasks that aren’t time-sensitive, efficiently handling multiple prompts in a single input file.
- Provisioned Throughput reserves dedicated capacity for consistent, high-performance workloads. Commit for one month or six months — longer commitments yield lower hourly rates.
- Standard, Flex, Priority, and Reserved tiers have also been introduced for select models, giving teams more granular control over the cost-performance tradeoff. Flex pricing provides lower rates in exchange for flexible scheduling, while Priority guarantees faster processing. Reserved tiers lock in discounted rates for predictable, sustained usage.
That’s the short answer.
Here’s how pricing for Bedrock features actually works, so you’ll know what you are paying for (and optimize your AWS Bedrock costs for maximum ROI).
First, Amazon Bedrock costs will depend on a couple of factors. These include:
- The volume of tokens used: Input or output tokens; billing is calculated per 1,000 tokens.
- Type of operation: For example, generating images costs more than text.
- Foundation Model: Each model family has its own pricing structure. Some representative examples:
- Amazon Nova Micro: $0.035 per 1M input tokens / $0.14 per 1M output tokens — among the most affordable text models on the platform.
- Amazon Nova Premier: $2.50 per 1M input tokens / $12.50 per 1M output tokens.
- Claude Sonnet 4.5 (Anthropic): $3.00 per 1M input tokens / $15.00 per 1M output tokens.
- Google Gemma 3 4B: $0.04 per 1M input tokens / $0.08 per 1M output tokens — one of the cheapest models available.
Software and pricing information last verified April 2026. Features, pricing, and availability may have changed. Please verify current details with AWS before making decisions.
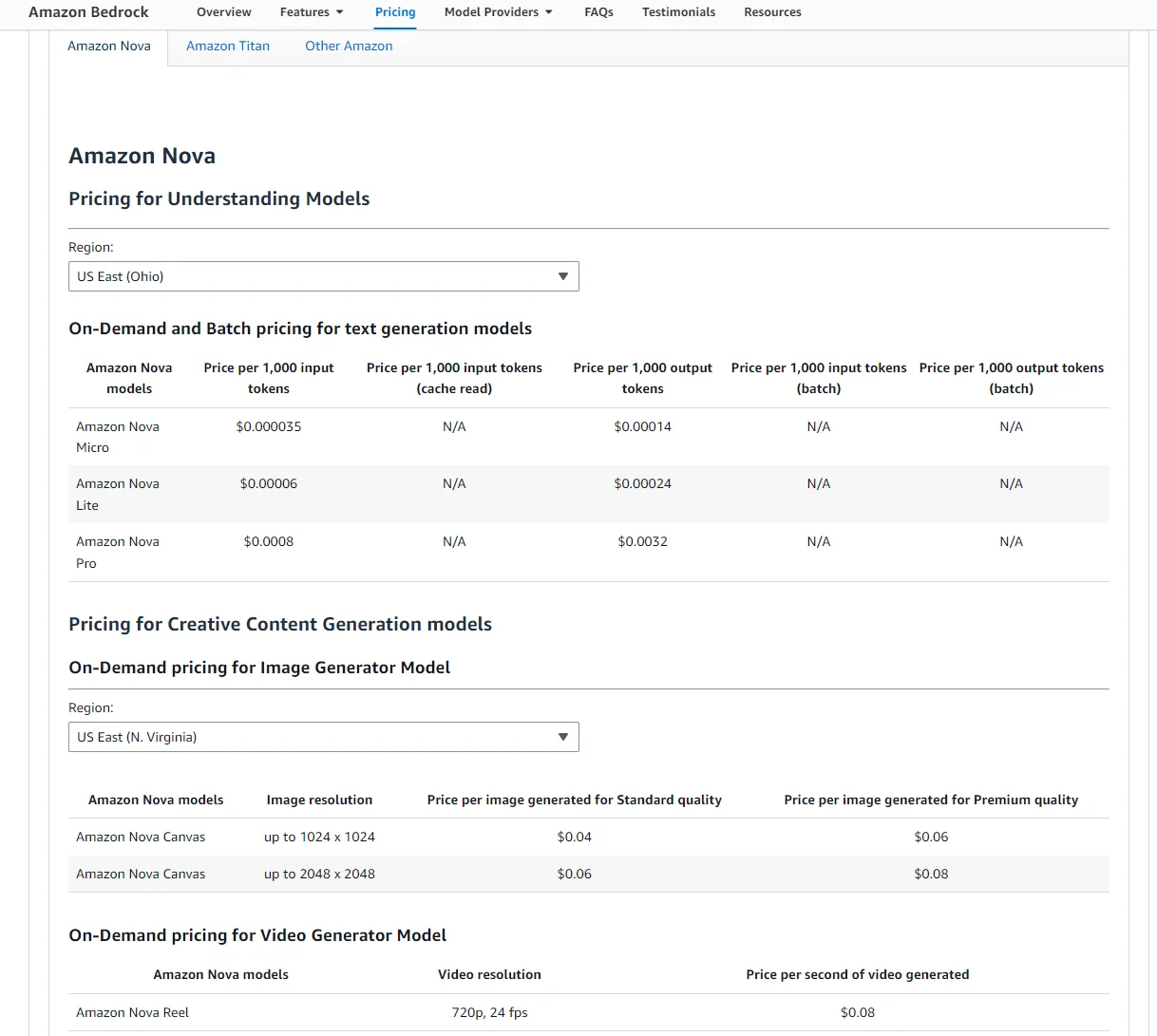
Example Amazon Bedrock pricing for Nova models
- Compute requirements: More intensive tasks require more compute resources, increasing Amazon Bedrock costs.
- Storage needs: Keeping datasets and custom models in, say, Amazon S3 has its costs, which vary based on data volume.
- Data transfer charges: During operations, they can also add up, especially if you move a lot of data in and out of Bedrock.
Beyond model inference, several Bedrock features carry their own pricing that can materially shift your bill. Many teams overlook these line items when budgeting for AI workloads.
Knowledge Bases connect foundation models to your private data sources for grounded, RAG-powered responses. The inference tokens are billed at standard model rates, but the underlying vector store adds cost. If you use Amazon OpenSearch Serverless as your vector database (the default option), the minimum cost is roughly $345/month for storage alone — often exceeding inference costs for lower-traffic RAG applications. Teams running Knowledge Bases should factor in this baseline cost from day one.
Guardrails apply content filters, PII redaction, topic blocking, and hallucination detection to model responses. Pricing sits at $0.15 per 1,000 text units processed — an 80% reduction from the original $0.75 rate introduced in late 2024. For high-volume applications routing every response through Guardrails, this cost adds up, but the per-unit economics are now much more favorable.
Agents orchestrate multi-step tasks that chain model invocations with tool calls and API integrations. Each tool call in an agent workflow consumes its own tokens, so an agent completing a task with five tool calls can consume roughly 5x the tokens of a single direct invocation. Plan for $0.05–$0.08 per complex agent task versus ~$0.01 for a simple API call.
Flows let you build visual, multi-step AI workflows. Pricing is $0.035 per 1,000 node transitions, metered daily and billed monthly.
You may also incur additional costs if your operations integrate with other AWS services or use Bedrock’s Data Automation and Model Evaluation features.
Estimating your costs: AWS provides a Bedrock pricing page that lets you model costs across different models, volumes, and feature combinations before committing.
Also, check the supported models page to confirm which regions and models support each feature. Meanwhile, keep reading to learn how to optimize your Amazon Bedrock costs the smarter way.
Amazon Bedrock Cost Optimization Best Practices
Knowing how Bedrock pricing works can help you prevent its costs from calling the shots in your company.
Fortunately, we’ve got some practical cost optimization strategies for Bedrick that you can start using right now.
Optimize your prompts
Streamline prompts to minimize token usage, reducing costs associated with input and output processing. You can also set maximum token limits for model outputs to control response lengths.
Also, consider using prompt caching. By avoiding the need to recompute responses for repeated prompts, prompt caching can reduce costs by up to 90%. This is achieved by minimizing the number of tokens processed and the computational resources required.
Prompt caching can also decrease response times significantly, improving user experience in applications that require quick feedback.
Using cached prompts reduces the cost of inference compared to non-cached tokens. For example, cache reads may incur a 90% discount on input token costs.
Save up to 50% with batch processing
For large-scale inference tasks that are not time-sensitive, take advantage of batch mode to achieve economies of scale and lower per-unit costs compared to on-demand pricing. Better yet, schedule batch jobs during off-peak hours to maximize resource availability and reduce costs further.
Batch mode works particularly well for periodic workloads like nightly report generation, bulk content classification, or weekly data enrichment. The 50% savings compound quickly: a team processing 10 million tokens daily could save over $1,000/month by shifting eligible workloads to batch, depending on the model used.
Get lower rates when you use Provisioned Throughput
Think of Provisioned Throughput as the Reserved Instances approach for Amazon Bedrock. For applications requiring consistent performance, purchasing provisioned throughput with time-based commitments (one-month or six-month terms) locks in reduced hourly rates while guaranteeing dedicated capacity.
This option makes the most sense for production workloads with predictable traffic patterns — chatbots handling thousands of daily conversations, real-time content moderation systems, or customer-facing AI features where latency matters. If your usage is spiky or experimental, on-demand or the newer Flex tier will likely serve you better until your traffic stabilizes.
Use intelligent prompt routing
The method uses advanced prompt matching and model understanding techniques to predict which model in an FM family will provide the best response quality at the lowest cost for each request.
For instance, you can route requests between Claude Sonnet 4.5 and Claude Haiku 4.5, or between Llama 4 Scout and Llama 4 Maverick, sending simpler queries to the lighter (cheaper) model while directing complex reasoning tasks to the more capable one.
Access intelligent prompt routing through the AWS Management Console, AWS Command Line Interface (CLI), or AWS SDKs.
See the exact people, products, and processes that drive your Amazon Bedrock costs
Continuously track resource usage and costs using native AWS tools like Cost Explorer. Better yet, use robust third-party services like CloudZero. See how Cost Explorer compares to CloudZero here.
Unlike most cloud cost optimization tools, CloudZero precisely maps your expenses to the people, products, and processes driving your AWS service costs. Beyond average costs, it also provides insights into cost per customer, per feature, and even per request.
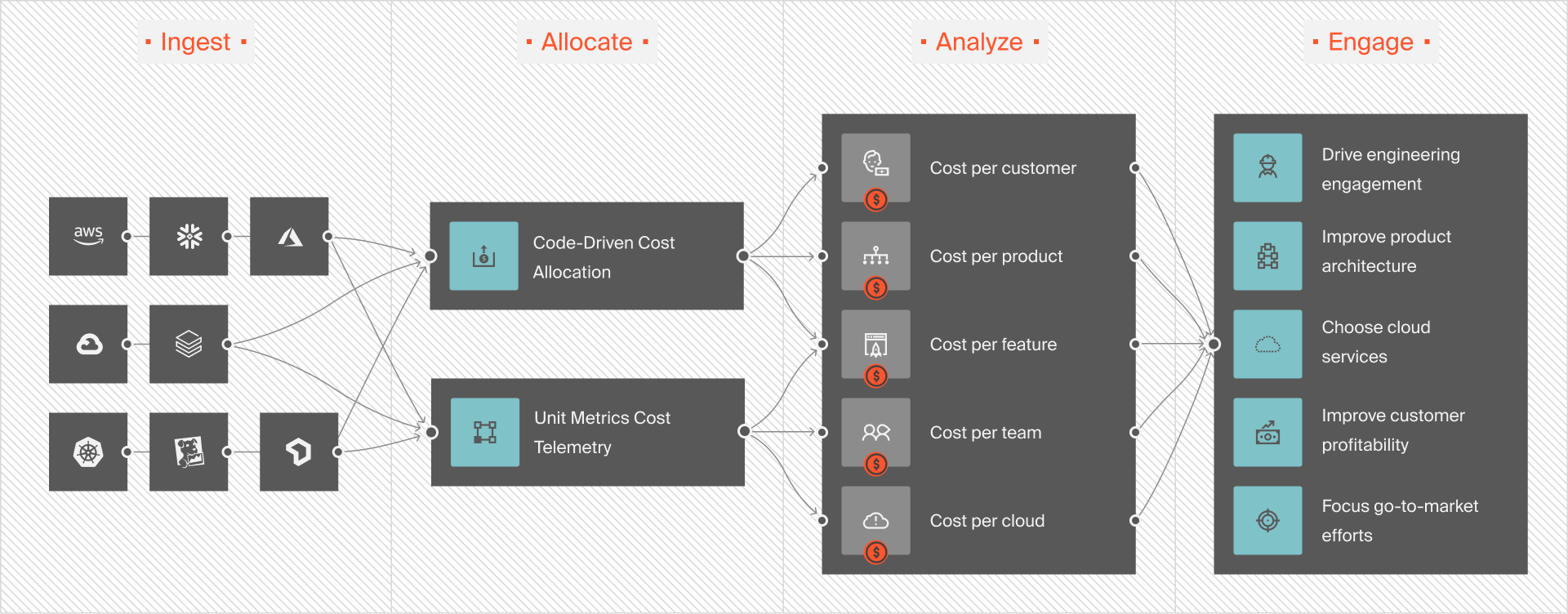
This means you can pinpoint areas where you could improve to cut waste (and boost your bottom line).
CloudZero also includes real-time cost anomaly detection. You get timely and contextual alerts to notify your team when spending approaches predefined limits, preventing unexpected overruns.  to see how CloudZero works. Better yet, get your free cloud cost assessment here.
to see how CloudZero works. Better yet, get your free cloud cost assessment here.
Minimize data transfer costs when using Amazon Bedrock
Consider the following strategies:
- Retain data in the same AWS Region as much as possible to avoid the more expensive cross-region transfers.
- When transferring data across regions is necessary, batch your transfers to minimize data movement frequency.
- Use private IP addresses rather than the more expensive public IPs for internal communications.
- Consider using AWS CloudFront, the CDN, to cache content closer to users. This can reduce the volume of data transferred from your origin servers.
And last but by no means least.
Make ongoing reviews and optimization a habit
Conduct regular reviews of workloads and AWS pricing updates to adapt strategies as business needs evolve, ensuring continued cost efficiency. For example, regularly review your data transfer reports through AWS Cost Explorer to identify and eliminate unnecessary transfers.
AI pricing on AWS shifts frequently — new models launch, existing models get price cuts, and new features introduce new billing dimensions. A quarterly review cadence keeps your optimization strategy current rather than reactive.
Want more ways to optimize your AI project costs? Check out our bookmarkable guide to OpenAI cost optimization here.
Prevent Overspending On Bedrock With CloudZero
Here’s the deal: if you’re actively invested in AI, you’re likely building crazy, innovative models on top of your company’s data. That often means AI costs are becoming large, untraceable expenses that are tough to tie back to specific features, products, teams, microservices, etc.
Not with CloudZero.
CloudZero can allocate 100% of your AI costs programmatically in just minutes or hours, even if you have imperfect tags. This level of proactive visibility prevents overspending (and emergency meetings with the board over surprise costs).
Now, it may take time before your AI projects need to turn a profit. But that day is coming. When it does, you’ll be in a much stronger position if you’ve already established the tools to track and manage AI costs. And we are happy to demo these tools for you. — risk-free, of course.
Amazon Bedrock FAQs
What does Amazon Bedrock do?
Bedrock is a serverless AI platform on AWS that provides access to tools for building and scaling AI apps through a single API. It offers 85+ foundation models from leading providers and includes features like Knowledge Bases (RAG), Guardrails (safety filters), Agents (multi-step automation), and Flows (visual workflow builder).
How much does Amazon Bedrock cost?
Amazon Bedrock pricing varies based on factors such as the model selected, the volume of input/output tokens used, the pricing tier (On-Demand, Batch, Provisioned Throughput, Flex, Priority, or Reserved), and whether you use additional features like Knowledge Bases, Guardrails, or Agents. Costs can range from $0.035 per million input tokens (Nova Micro) to $15.00 per million output tokens (Claude Sonnet 4.5).
Is Amazon Bedrock cheaper than Azure OpenAI?
That depends on your usage patterns, model preferences, and commitment level. Bedrock can be more cost-effective thanks to its batch inference discount (50% off on-demand), a wider selection of lightweight models (Nova Micro, Gemma 3 4B), and flexible commitment tiers. Azure OpenAI may offer better rates for teams heavily invested in GPT-4o or GPT-4 Turbo specifically. The best approach is to run a parallel cost estimate using both platforms’ pricing calculators with your actual token volumes.
What are the hidden costs of Amazon Bedrock?
The most commonly overlooked costs include Knowledge Bases infrastructure (OpenSearch Serverless starts around $345/month), Guardrails processing fees ($0.15 per 1,000 text units), agent orchestration token multiplication (5x+ for multi-step tasks), Flows node transition charges, and cross-region data transfer fees. These feature-level costs can exceed your base inference spend if you’re running RAG applications or complex agent workflows at scale.











