
Quick Answer
Claude Opus 4.7 pricing is $5 per million input tokens and $25 per million output tokens, the same rate as Opus 4.6. However, a new tokenizer inflates token counts by up to 35% on identical text, raising your effective Claude Opus 4.7 cost by 0–35% per request depending on content type. Prompt caching (90% off cached reads) and batch processing (50% off) are the primary levers for controlling spend.
If you’ve been tracking Claude pricing since the Opus 3 era ($15/$75 per MTok, a number that made finance teams visibly uncomfortable), the 4.x generation has been a welcome reset. Opus 4.5 dropped the flagship price by 67%. Opus 4.6 held it there. And now Opus 4.7 keeps the same sticker price while delivering what Anthropic calls its strongest generally available model, better coding, sharper vision, and longer-horizon agent work.
The catch, as usual, lives in the details. This guide breaks down every pricing layer, compares all current Claude models, and covers the optimization levers that actually reduce your bill at production scale.
For the full Claude AI model lineup and pricing history, see our complete Claude pricing guide.
How Much Does Claude Opus 4.7 Cost Per Million Tokens?
Here’s the complete Anthropic pricing table for every current-generation model as of April 2026:
| Model | Input (per 1M tokens) | Output (per 1M tokens) | Context window | Max output |
| Claude Opus 4.7 | $5.00 | $25.00 | 1M tokens | 128K tokens |
| Claude Opus 4.6 | $5.00 | $25.00 | 1M tokens | 128K tokens |
| Claude Sonnet 4.6 | $3.00 | $15.00 | 1M tokens | 128K tokens |
| Claude Haiku 4.5 | $1.00 | $5.00 | 200K tokens | 64K tokens |
A few things worth noting. All three current-generation models, Opus 4.7, Opus 4.6, and Sonnet 4.6, include the full 1M token context window at standard pricing, per Anthropic’s documentation. No surcharges for long-context requests. A 900K-token call costs the same per-token rate as a 9K-token call.
The entire Opus line from 4.5 onward sits at the same $5/$25 price point, which itself represents a 67% reduction from the Opus 4/4.1 era ($15/$75 per MTok). Sonnet 4.6 runs 40% cheaper on both input and output. Haiku 4.5 is five times cheaper across the board.
That’s the rate card.
Here’s why it tells roughly half the story.
Report
Finance needs to prove AI’s return: CloudZero report
260 senior finance leaders (more than half CFOs) told us why the speed of seeing AI spend, not the size of it, separates who pulls ahead on AI from who gets burned.
Why The Same Price Doesn’t Mean The Same Bill: The Claude Opus 4.7 Tokenizer Change
The single most important detail in the Opus 4.7 release isn’t a benchmark score. It’s a new tokenizer, and if that sentence sounds about as exciting as a firmware update, it probably costs more.
Tokenization converts your raw text; prompts, code, JSON payloads, conversation history — into the numerical units the model processes and bills against. The Claude Opus 4.7 tokenizer produces up to 35% more tokens from the same input text compared to Opus 4.6. Anthropic confirms this in their migration documentation: the multiplier ranges from 1.0x to 1.35x depending on content type.
In practice, a request that cost you $0.10 on Opus 4.6 could cost $0.10 to $0.135 on Opus 4.7 for the exact same prompt doing the exact same work. The rate card is flat. Your invoice is not.
Three dynamics make this particularly sharp:
- Output tokens cost 5x more than input. If Opus 4.7 produces more verbose responses (which early users report) and the tokenizer inflates those responses further, you’re compounding on both axes, density and verbosity, at the $25/MTok output rate. That’s where the real money goes, and it’s the kind of quiet margin erosion that teams building AI-powered features only catch when the monthly invoice arrives.
- Code and structured data inflate the most. The 35% ceiling shows up most often on code, JSON, and non-English text. If you’re running coding agents or processing structured API responses, plan for the upper bound.
- Thinking tokens bill as output. Opus 4.7 replaces extended thinking with adaptive thinking, and those reasoning tokens bill at the $25/MTok output rate. Without budget controls, a complex agentic loop can chew through thinking tokens the way a junior engineer chews through Spot Instance credits on a Friday afternoon. More on how to prevent that below.
Before migrating any production workload, run a side-by-side test on real traffic. Anthropic provides a token counting endpoint (/v1/messages/count_tokens) that returns different counts for Opus 4.7 vs. Opus 4.6 on identical input. Use it. The cost of a surprise is always higher than the cost of a benchmark.
So the tokenizer raises your effective cost. The next question is whether Opus 4.7’s capability improvements earn that premium back.
Opus 4.7 Vs Opus 4.6: Is The Upgrade Worth The Extra Tokens?
This is the question that separates cost management from cost intelligence, not “what does it cost?” but “was it worth it?”
Opus 4.7 vs Opus 4.6 comes down to whether the capability gains justify the tokenizer tax:
| Dimension | Opus 4.7 | Opus 4.6 |
| Coding benchmark | ~13% improvement (Anthropic 93-task benchmark) | Baseline |
| Vision capability | Higher image resolution support (~3× increase reported) | Lower resolution baseline |
| Effort levels | Expanded effort levels (low → max) | Standard effort levels |
| Thinking mode | Adaptive thinking (effort-based) | Extended thinking (token budget-based) |
| Task budgets | Available (public beta) | Not documented |
| Tokenizer impact | 1.0×–1.35× more tokens on same text | Baseline |
| Effective cost delta | 0–35% higher per identical request | Baseline |
Here’s how to think about it.
If your workload involves complex multi-step coding, autonomous agents, or vision-heavy tasks like reading dense screenshots, Opus 4.7 is a genuine upgrade. Hex’s independent testing, cited in Anthropic’s announcement, found that low-effort Opus 4.7 roughly matches medium-effort Opus 4.6 in output quality. That efficiency gain can offset the tokenizer cost entirely if you calibrate your effort levels properly.
If your workload is RAG pipelines, classification, content generation, or basic tool use, Sonnet 4.6 at $3/$15 is still the right default. Most teams overpay by routing everything through Opus when Sonnet handles the majority of production tasks at 40% lower cost, a pattern that AI cost optimization consistently exposes.
That brings us to the dollar-for-dollar comparison most teams actually need.
What About Opus 4.7 Vs Sonnet 4.6 pricing?
The comparison tables above tell one story. Your monthly invoice tells a different one. Let’s put real numbers on the Opus 4.7 vs Sonnet 4.6 gap.
The rate card difference is 40%. But once you factor in the tokenizer multiplier on Opus, the effective cost gap widens to over 55%, sometimes more, depending on content type. The question isn’t which model is “better.” It’s which one makes your unit economics work.
Here are directional cost comparisons across three common workload profiles. These are estimated projections based on published token rates and the 35% tokenizer ceiling, your actual numbers will vary by content type, caching behavior, and response length:
| Workload | Opus 4.7 (est. with 35% inflation) | Sonnet 4.6 | Sonnet savings |
| Coding agent: 1M input / 200K output per day | ~$405/month | ~$180/month | ~56% |
| RAG assistant: 5M input / 500K output per day, 70% cache hit | ~$881/month | ~$392/month | ~56% |
| Autonomous SWE agent: 10M input / 2M output per day, no caching | ~$4,050/month | ~$1,800/month | ~56% |
Methodology: Published token rates × daily volume × 30 days. Opus 4.7 figures include 1.35x tokenizer multiplier as upper-bound estimate. Cache-hit savings at 10% of standard input rate per Anthropic’s caching documentation. Sonnet 4.6 uses its own tokenizer with no confirmed inflation. These are directional estimates, not quotes.
For RAG assistants and most general-purpose production workloads, Sonnet 4.6 delivers strong quality at roughly half the effective cost. Reserve Opus for tasks where its reasoning depth produces measurably better outcomes, then track whether that delta justifies the premium.
Speaking of context: Claude API pricing doesn’t exist in a vacuum. Here’s how Opus 4.7 stacks up against other frontier models.
How Does Claude Opus 4.7 Pricing Compare To Other AI Models?
Claude pricing exists in a competitive AI space where pricing shifts quarterly.
Here’s how Opus 4.7 stacks up against other frontier models:
| Model | Input ($ / 1M tokens) | Output ($ / 1M tokens) | Context |
| Claude Opus 4.7 | $5.00 | $25.00 | Up to 1M |
| Claude Sonnet 4.6 | $3.00 | $15.00 | Up to 1M |
| OpenAI (mid-tier models) | ~$2.50 | ~$15.00 | Varies |
| Google Gemini (Pro tier) | ~$2.00 | ~$12.00 | Varies |
Sources: Anthropic pricing, OpenAI pricing, Google Gemini pricing.
On raw per-token cost, Opus 4.7 is the premium option. GPT-5.4 undercuts it by 50% on input and 40% on output. Gemini 3.1 Pro is the cheapest flagship in this set at $2/$12. The case for Opus is quality-adjusted cost, particularly on complex coding, agentic work, and tasks where Opus’s reasoning depth reduces downstream rework.
This is why measuring cost per outcome, not just cost per token, changes the decision. A model that costs 2x more per token but solves the problem in one pass is cheaper than a model that takes three attempts and generates three invoices.
Organizations that track inference cost at the unit level — cost per resolved ticket, cost per generated asset, cost per coding task, consistently make better model routing decisions than teams that optimize purely on token rates.
Knowing which model to use is half the equation. The other half is knowing how to use it efficiently.
Here are the levers that matter.
6 Cost Optimization Levers For Claude Opus 4.7
The rate card is where your bill starts. These levers determine where it finishes. Organizations running Claude at scale, the kind managing 50+ LLMs across production workloads, use some combination of all six.
1. Prompt caching (up to 90% off input)
Prompt caching is the single biggest cost lever for any Opus workload. Cache reads cost 10% of the standard input rate, your cached system prompts, tool definitions, and reference documents bill at $0.50 per million tokens instead of $5.00, per Anthropic’s pricing documentation.
Cache writes carry a premium: 1.25x for five-minute duration, 2x for one-hour duration. A five-minute cache pays for itself after just one read. An hour-long cache needs two.
The pattern that saves the most: cache your system prompt, tool schemas, and any static reference material. For agents that chain 10+ turns deep, caching the conversation prefix is the difference between a sustainable product and a FinOps problem nobody saw coming.
2. Batch processing (50% off everything)
Batch processing via Anthropic’s Batch API handles requests asynchronously within 24 hours at half price on both input and output. Opus 4.7 at batch rates drops to $2.50/$12.50 per MTok, cheaper than Sonnet 4.6 at standard rates.
Best candidates: nightly summarization, evaluation sweeps, data enrichment, content generation queues, and red-team testing. Batch and prompt caching stack, a cached batch request can cost as little as 5% of a standard uncached request. That’s $0.25 per million input tokens. At that rate, even finance might crack a smile.
3. Effort levels (new in Opus 4.7)
Opus 4.7 introduces a new xhigh effort level between high and max. The effort parameter controls how deeply the model reasons before responding, lower effort means fewer thinking tokens, faster responses, and lower cost.
Anthropic recommends starting at high or xhigh for coding and agentic work. For simpler tasks routed through Opus (classification, formatting, extraction), standard or low effort cuts cost with minimal quality loss. The savings compound fast across thousands of daily requests.
4. Task budgets (new, public beta)
Task budgets, introduced in Opus 4.7, set a token ceiling for an entire agentic loop, thinking, tool calls, tool results, and final output combined. They prevent the runaway reasoning problem where a complex agent burns through tokens on low-value subtasks.
If you’re building autonomous coding agents or multi-step research workflows, task budgets are the guardrail between a predictable bill and an unpleasant Slack alert from finance.
5. Intelligent model routing
The highest-leverage move is also the simplest: send the right request to the right model.
Haiku 4.5 handles classification, intent detection, content moderation, and simple extraction at $1/$5. Sonnet 4.6 covers RAG responses, content generation, standard tool use, and most production inference at $3/$15. Opus 4.7 takes complex coding, multi-step debugging, autonomous agents, and high-stakes reasoning at $5/$25. Amazon Bedrock offers intelligent routing across Claude models natively.
A well-designed routing layer, even a simple one based on prompt length and task type, drops your blended cost per request by 40–60%. That’s the AI equivalent of rightsizing your EC2 fleet: same output, dramatically lower spend.
6. Unit economics visibility
You can stack every discount Anthropic offers and still overspend if you don’t know what you’re spending on. What does Opus 4.7 cost per customer? Per feature? Per agent run? Is your most expensive model powering your highest-margin product, or quietly subsidizing a feature that erodes your SaaS COGS?
These aren’t rhetorical questions. They’re the difference between profitable AI scaling and the kind of cost surprise that earns its own incident retrospective.
Of course, none of these optimizations matter if your migration breaks your API calls. Here’s what to watch for.
3 Breaking API Changes To Know Before Migrating To Opus 4.7
Opus 4.7 isn’t a drop-in replacement for everything. Three breaking changes, documented in Anthropic’s migration guide, catch teams off guard:
- Extended thinking is removed. Setting thinking: {“type”: “enabled”, “budget_tokens”: N} returns a 400 error on Opus 4.7. Adaptive thinking (thinking: {“type”: “adaptive”}) is the only option, controlled via the effort parameter. Update your API calls before switching model IDs.
- Temperature, top_p, and top_k are locked. Setting any of these to a non-default value returns a 400 error. If your prompts rely on temperature tuning, remove those parameters and use prompting to guide behavior instead.
- Thinking content is hidden by default. Thinking blocks still stream, but their thinking field is empty unless you set “display”: “summarized”. If your product shows reasoning to users, the new default looks like a long, awkward pause before output. One-line fix, but easy to miss in a migration sprint.
Once you’ve migrated and optimized, the final challenge is connecting Claude costs to the rest of your cloud cost optimization picture.
Frequently Asked Questions About Claude Opus 4.7 Pricing
How CloudZero Tracks Claude Costs Alongside Your Entire Cloud Bill
Here’s the challenge we see across our customer base: Anthropic bills you in tokens. AWS bills you in compute hours. Your Kubernetes clusters bill in node-hours. Snowflake bills in credits. Databricks bills in DBUs. Your finance team wants one number, and they wanted it yesterday.
The 35% tokenizer shift is exactly the kind of change that hides inside a fixed rate card and shows up three weeks later in a reconciliation meeting nobody enjoys. That’s why we moved fast when Anthropic released their Usage and Cost Admin API. CloudZero became the first cloud cost platform to integrate directly with Anthropic, pulling Claude usage and cost data into the same platform used for AWS, Azure, GCP, OpenAI, and other platforms.
That integration isn’t just a data connector. It’s the foundation for treating Claude spend the way you’d treat any other production cost, with full attribution, real-time alerting, and unit-level visibility.
What the CloudZero Anthropic integration actually gives you
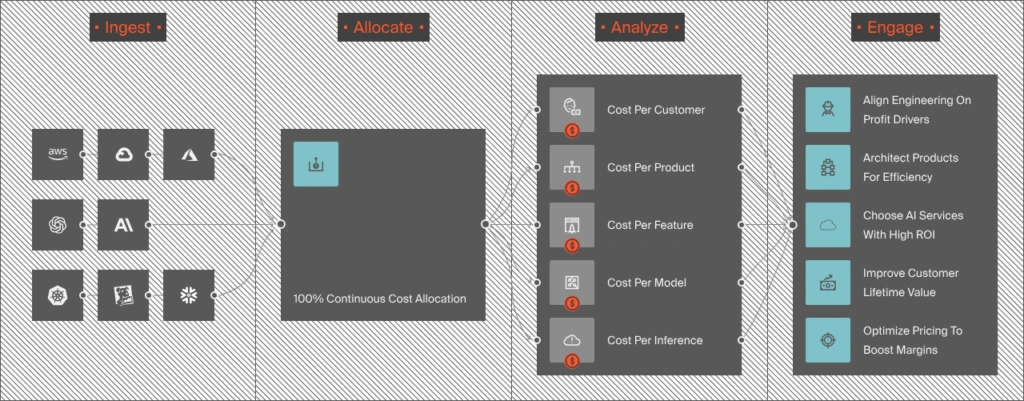
- Token-level spend attribution. CloudZero ingests uncached input, cache hits, output tokens, and tool usage from Anthropic’s API, broken down by model, workspace, and API key. Then our allocation engine maps that data to the business dimensions that matter: team, product, feature, customer, and environment. Claude costs stop being a single line item and start being traceable to the engineering decisions that generated them.
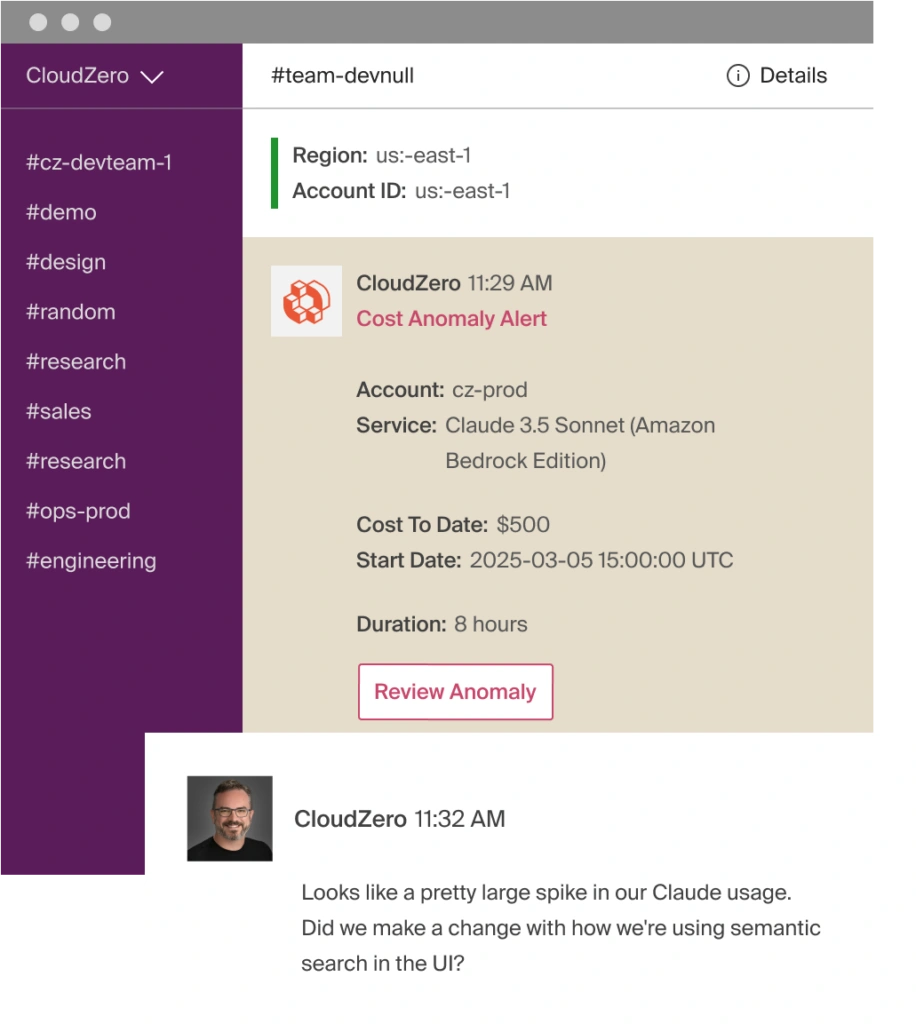
- Real-time anomaly detection. If your Anthropic costs spike, from a context-window change, a prompt regression, or an agent that decided to go full max-effort on a classification task, CloudZero sends alerts directly to the teams who own the affected workspace. Hour-level granularity means you catch problems before finance does, which is better for everyone’s blood pressure.
- Unit cost metrics for AI. This is where the cost question gets a real answer. CloudZero surfaces cost per token type, cost per inference, cost per customer, and cost per feature, the same unit economics framework that teams use for traditional cloud spend, extended to AI workloads. When you can see, for example, that Opus 4.7 costs you $0.14 per coding task for one customer segment but $0.03 per classification for another, routing and pricing decisions stop being guesswork.
- Claude Code visibility. Developer usage through Claude Code is unpredictable by nature, engineers experiment with prompts, stretch context windows, and rewire workflows day to day. CloudZero’s AI Hub brings cost intelligence directly into agentic coding tools, so engineers see the cost impact of their Claude Code usage without leaving their workflow.
What this looks like in practice:
One CloudZero customer managing spend across 50+ LLMs, including multiple Claude models across regions and workloads, uncovered over $1 million in savings by mapping token-level costs to customers, features, and business outcomes. They achieved 50%+ reduction in compute spend and gained cost-per-user data tied directly to model usage and customer value. That’s the kind of visibility that turns AI cost management from a defensive exercise into a competitive advantage.
As Josh Collier, FinOps Lead at Superhuman (formerly Grammarly), put it: “Understanding the direct correlation between our AI investments and business outcomes is critical. CloudZero has been instrumental in providing the granular visibility we need to optimize our AI infrastructure costs while maintaining our service quality.”
For a deeper dive into building a FinOps practice around Claude API costs, including forecasting, guardrails, and attribution frameworks, we’ve published a dedicated guide.
The bottom line:
The question that matters isn’t “how much does Claude cost?” It’s “was the spend worth it?” That’s the unit economics lens that separates cost management from cost intelligence, and it’s what CloudZero customers are increasingly applying to their AI cost management workflows, with over 90% now ingesting AI-related spend into the platform.
CloudZero manages over $15 billion in cloud and AI spend for some of the world’s leading organizations such as Toyota, Duolingo, Coinbase, Wise, PicPay, Skyscanner, and more. Our anomaly detection has flagged over $20 billion in anomalous spend before it hit a single invoice. Schedule a free demo to see how CloudZero connects your Claude, OpenAI, and cloud costs to the business outcomes that matter.
Not ready to talk yet? Start with a free cloud cost assessment to see where your spend stands today, no commitment required. Or take a self-guided product tour to explore the platform on your own terms.











