

Cloud costs rarely rise slowly. They jump. A scaling event, an S3 surge, a bad deployment, or a runaway Lambda can add thousands of dollars in minutes. AWS Cost Anomaly Detection helps teams spot these jumps early by identifying unexpected spend across accounts, services, tags, and cost categories.
For many organizations, this is the first step toward real cloud cost intelligence. But anomaly detection alone doesn’t explain why the spike happened or who needs to fix it.
This guide explains what AWS Cost Anomaly Detection offers, how it works, and how CloudZero extends it with deeper engineering context.
What Is AWS Cost Anomaly Detection?
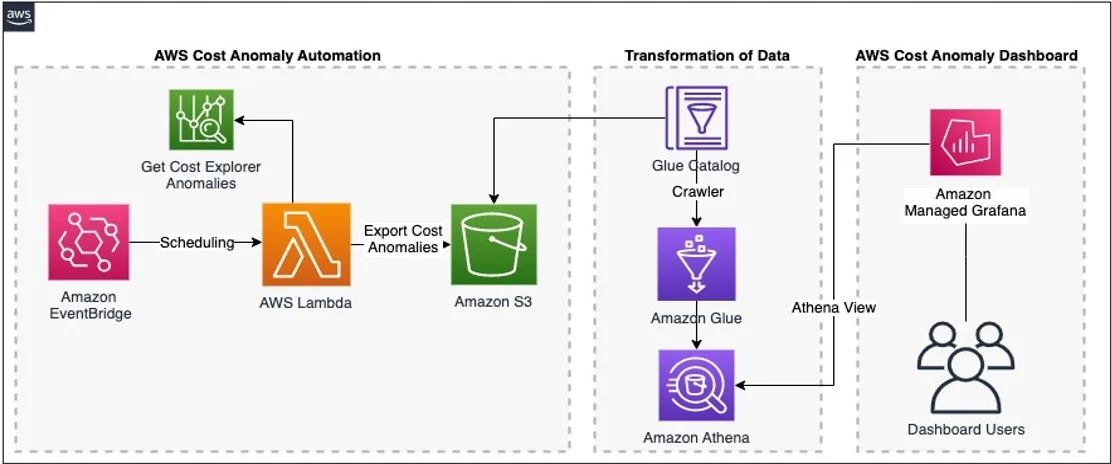
AWS Cost Anomaly Detection is a machine-learning service that monitors your AWS spend and alerts you when charges rise beyond expected patterns. It builds baselines from your historical usage, then flags deviations that may signal waste, misconfiguration, or unexpected activity.
It monitors AWS accounts, services, cost allocation tags, and cost categories. When it detects an anomaly, AWS generates an alert summarizing the spike and estimating the financial impact.
Because it’s built into AWS Billing and Cost Management, teams can begin monitoring immediately with no extra configuration.
Anomaly detection serves as a first-line guardrail for teams operating in dynamic, fast-changing cloud environments.
playbook
The AI Cost Optimization Playbook
Traditional cloud cost management is broken. Here’s why — and how to make the switch to cloud cost intelligence.
How AWS Cost Anomaly Detection Works
AWS uses machine learning to analyze your daily spend and detect patterns that fall outside normal behavior. Instead of using manual thresholds, the model learns your natural cost rhythm and alerts you when something changes suddenly.
It does this through several types of monitors:
- Service monitors: Watch services like EC2, S3, Lambda
- Account monitors: Track spend across linked accounts
- Cost category monitors: Follow custom groupings
- Tag-based monitors: Track specific workloads, environments, or teams
When AWS detects an anomaly, the alert includes:
- Estimated impact
- The service or account driving the spike
- The timeframe
- A short root-cause summary
Alerts can be delivered via email or SNS and routed to Slack, Jira, PagerDuty, or internal workflows.
But AWS Cost Anomaly Detection Alone Doesn’t Provide Engineering Context
AWS shows the spike, but it doesn’t reveal:
- Which feature triggered it
- Which deployment introduced the change
- Which team owns the workload
- If the spike was growth or waste
Without this context, engineering teams have to manually trace anomalies through logs, repos, cluster activity, builds, and deployments. This slows response time, increases cost risk, and creates friction between engineering, product, and finance.
To move from alerts to actionable intelligence, teams need deeper visibility.
How CloudZero Turns Anomalies Into Real Cloud Cost Intelligence
AWS alerts show deviations, but engineering teams need more than notifications. They need to understand the business and technical context behind the spike. CloudZero extends AWS anomaly detection with deep allocation, ownership routing, and engineering-aware insight.
Feature-level and product-level cost insight
Instead of telling teams that “EC2 costs increased,” CloudZero reveals:
- “The cost to run Feature A doubled.”
- “Service B in production triggered a spike.”
- “Customer segment X drove higher compute usage.”
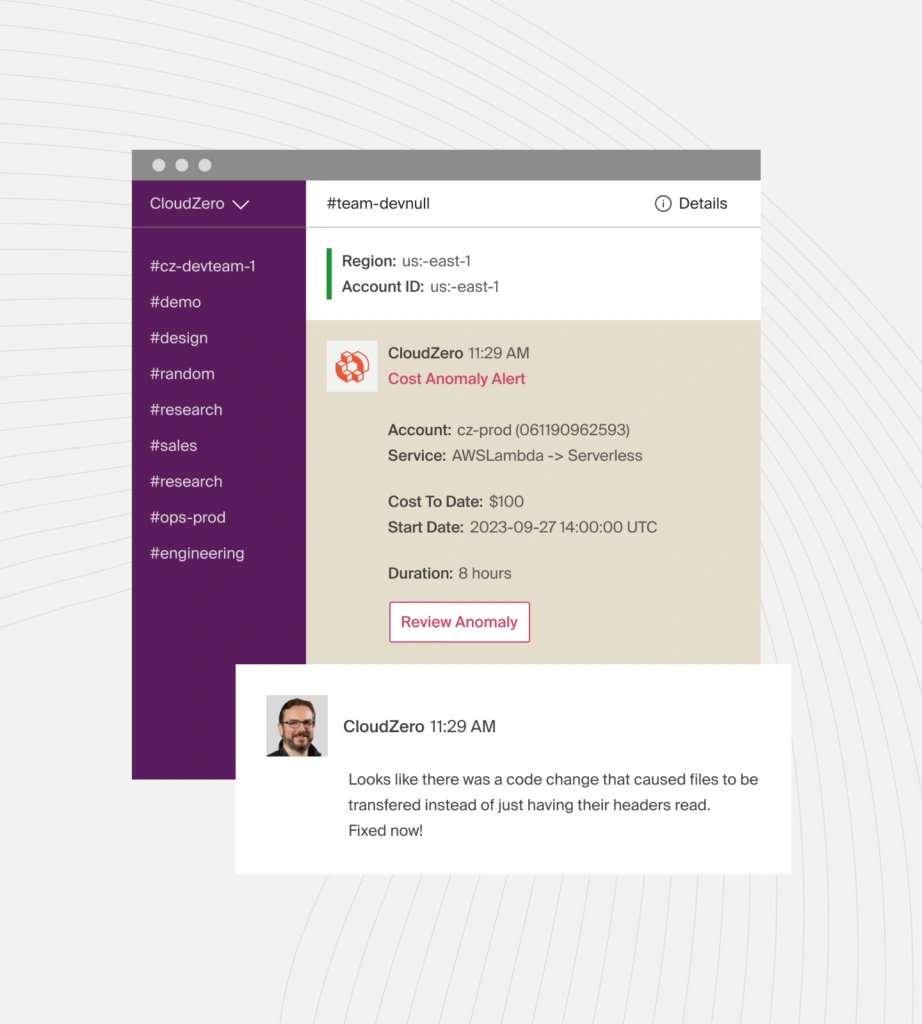
This reduces investigation time from hours to minutes and shows exactly where to focus.
Team-specific alerts are delivered where engineers work
AWS supports email and SNS. CloudZero routes anomalies directly to:
- Engineering Slack channels
- DevOps workflows
- Team dashboards
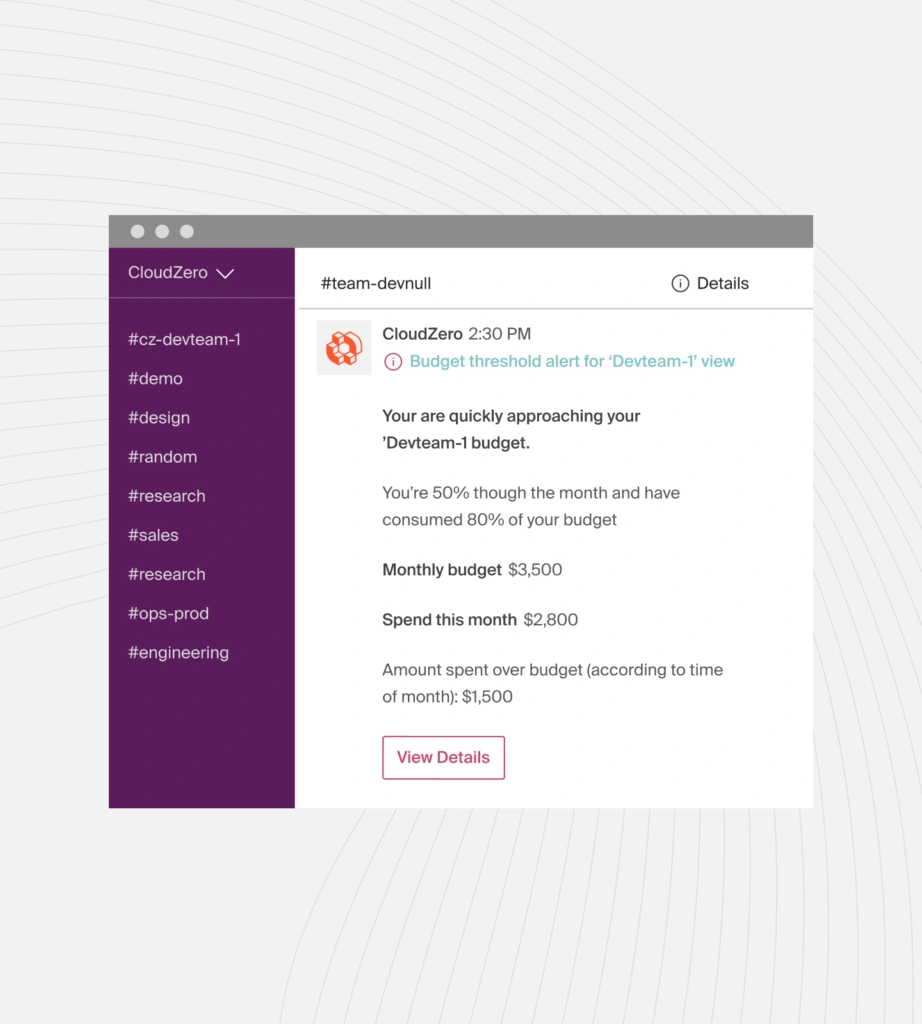
Each team sees only the anomalies tied to the services they own. This eliminates noise and accelerates response time (decision velocity).
Kubernetes, deployments, and CI/CD context AWS cannot see
AWS shows service-level spikes, but not which Kubernetes workload caused them. CloudZero maps pod and namespace costs, links spend to deployments, and reveals overprovisioned workloads so teams can pinpoint the source fast.
Near real-time cost updates
AWS processes cost data daily. CloudZero continuously processes usage and allocation data.
This helps teams catch regressions earlier and detect risks on the same day they occur.
Global organizations such as Duolingo, Skyscanner, HelloFresh, Toyota, Rapid7, and more use CloudZero to save millions of dollars in cloud spend. See what’s possible for your team: take the product tour, then  with our experts.
with our experts.
FAQs
Why do cost anomalies happen in cloud environments?
Cost anomalies often result from scaling events, misconfigured services, deployment changes, increased data transfer, or batch workloads running longer than expected. Dynamic orchestration systems, such as serverless architectures, also introduce unpredictable cost swings.
Can AWS anomaly detection monitor Kubernetes workloads?
Not directly. AWS monitors costs at the service/account level. Kubernetes clusters require cost allocation based on pod-level usage, container scaling, and node activity, which AWS does not provide. CloudZero combines AWS spend with K8s use for complete insight.
How does AWS anomaly detection compare to CloudWatch alarms?
CloudWatch alarms trigger on resource metrics or static thresholds. AWS Cost Anomaly Detection uses machine learning to detect unusual spend patterns, not resource usage. Both can complement each other in dynamic workloads.
Resource: CloudWatch Metrics Your Organization Should Track
How often does AWS update anomaly data?
AWS processes spend daily. This means anomalies may surface up to 24 hours after the spike occurs. Real-time or near-real-time anomaly detection requires additional telemetry and cost allocation layers.
What’s the difference between anomaly detection and budgeting alerts?
Budget alerts fire when spend crosses predefined thresholds. Anomaly detection fires when spend deviates from learned patterns, even if it is within budget. Anomaly detection is better for early detection; budgets help with financial guardrails. See more on AWS Budget Alerts.
Can anomaly detection reduce cloud costs?
Yes, but only when paired with an engineering context. Alerts help teams detect cloud waste early, prevent repeated incidents, and improve architecture. But anomaly detection alone does not optimize; it requires investigation and remediation.
How does anomaly detection support unit economics?
Anomalies show where cost behavior shifts unexpectedly. When mapped to specific features or customer workloads, teams can see how anomalies impact cost per customer, feature, and other unit metrics that matter for margins.











