DevOps. DevSecOps. AIOps. NoOps. RevOps. FinOps. It’s hard to keep up sometimes. CloudZero sits at the intersection of finance and operations — and as a Premier Member of the FinOps Foundation, we work closely with the practitioners, engineers, and finance leaders who are defining how this discipline evolves.
In this guide, we’ll break down what FinOps is, how it works, and why it matters — whether you’re an engineer trying to understand cost drivers, a finance leader learning to read cloud bills, or a VP who needs to know if the spend is worth it.
What Is FinOps In The Cloud?
According to Finops.org, “FinOps is shorthand for ‘Cloud Financial Operations.’ This is a relatively new discipline under Cloud Financial Management or ‘Cloud Cost Management.’ Understanding cloud financial operations is essential for any organization looking to bring accountability to variable cloud spend.
FinOps is the practice of bringing financial accountability to the variable spend model of the cloud, enabling distributed teams to make business trade-offs between speed, cost, and quality.”
Credit: FinOps Foundation
The FinOps framework goes beyond just reporting spending. It also enables teams to accurately link spending to the people, products, and processes that generate those costs. You can track who gets what, why, and where your cloud budget goes.
Report
Finance needs to prove AI’s return: CloudZero report
260 senior finance leaders (more than half CFOs) told us why the speed of seeing AI spend, not the size of it, separates who pulls ahead on AI from who gets burned.
The Three Tenets Of Cloud FinOps Explained
FinOps consists of three phases: Inform, Optimize, and Operate. The three tenets emphasize cloud cost reporting, cloud cost optimization, and continuous improvement.
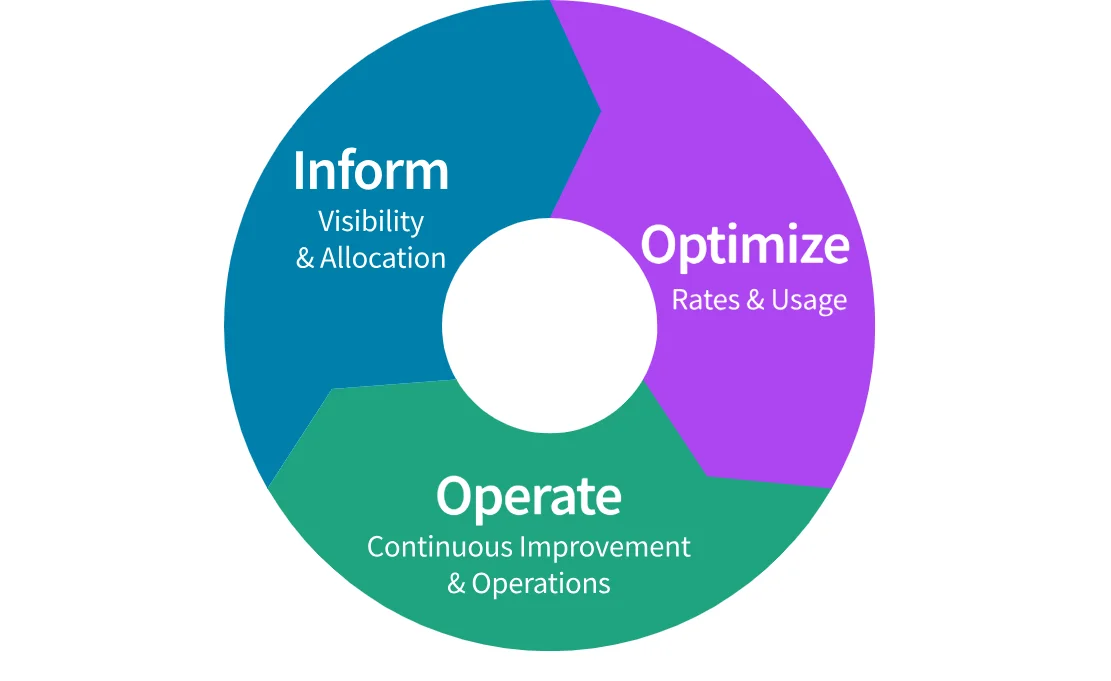
Credit: FinOps phases by the FinOps Foundation
Below is an overview of each phase in the FinOps lifecycle — the three-stage cycle that drives continuous cloud cost optimization:
Inform
A key focus of this first phase of FinOps is increasing cost visibility. This visibility leads to data-driven decisions about cost allocation, budgeting, and forecasting.
How much visibility you’ll have will depend on your business goals and the cloud cost tools you use. Native cloud cost tools on AWS, Azure, and Google Cloud, for example, provide a single cost report every 24 hours.
Considering cloud billing is done per second and hourly, this 24-hour approach leaves much room for cost surprises.
Meanwhile, a more thorough cloud cost visibility platform like CloudZero surfaces your cloud costs hourly — and maps them to the teams, products, and customers driving them. This enables you to spot anomalies much sooner, minimizing budget overruns.
Additionally, CloudZero offers high-level cost insights, such as total and average costs, as well as more precise insights, such as cost per customer, team, feature, deployment, environment, and more.
This level of cost visibility empowers you to tell exactly who, what, and why your costs are changing so you can actually fix it.
Optimize
Speaking of fixing cost drivers, the Optimize tenet of FinOps focuses on maximizing the return on cloud investment in the most cost-effective way.
Cloud cost optimization is more than just reducing costs. The goal is to maximize ROI without compromising system performance, engineering velocity, or user experience.
This phase involves applying cloud cost optimization best practices such as:
- Rightsizing. This involves matching the type, size, and amount of cloud resources to the type of workload you need to execute. These resources include the type and size of instances or virtual machines (vCPU, memory, storage, and network bandwidth) to reduce overprovisioning (waste) or underprovisioning (performance degradation).
- Minimizing idle resources. Ensure cloud resources are terminated as soon as they finish their tasks. This reduces the amount of money spent on idle or unused resources.
- Using commitment-based discount programs. Take advantage of discounts, such as Reserved Instances (RIs), Savings Plans, and Sustained Use Discounts.
Consider the example we just used about viewing cost per feature.
By knowing which product features cost the most, you can take action. If you offer this feature in a free trial, you could move it to a paid tier and have it pay for itself.
Or, see if it’s popular among your customers. If not, you can decide whether to repurpose or decommission it altogether to protect your margins.
Operate
Operate involves governing cloud costs continuously to ensure you don’t overspend while meeting your cloud computing objectives.
This is where all FinOps stakeholders, including finance, engineering, customers, and management, need to be involved.
A major challenge in implementing FinOps has been the assumption that it is a finance-only function. In reality, it is a joint effort across the organization led by finance.
In particular, you’ll want to improve collaboration between Engineering and Finance. This is because engineering in the cloud tends to spiral out of control more than on-premises.
Additionally, this is why it is so crucial to use cloud cost optimization platforms that incorporate Engineering-Led Optimization (ELO). In this approach, engineers are empowered to make sound cost decisions based on accurate, timely, and actionable cloud cost information in their own language, such as cost per deployment, service, environment, dev team, etc.
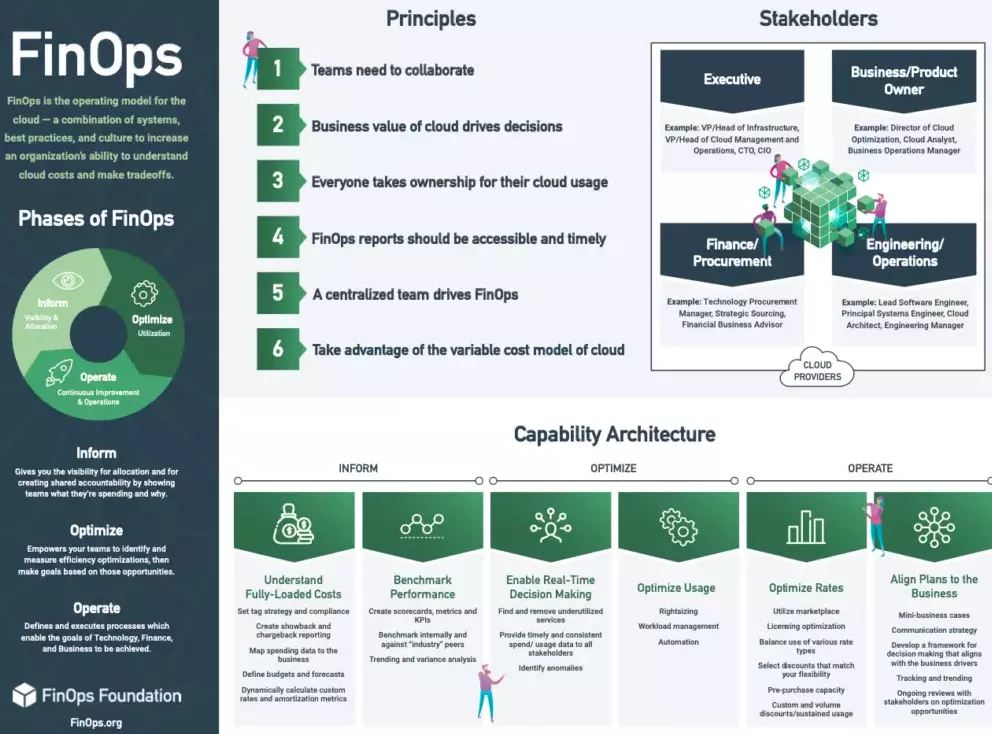
What Are The Six Principles Of FinOps?
The following principles serve as north stars for implementing FinOps in your organization. Implement all of them together and refine through experience as your needs evolve.
- Team collaboration. This emphasizes the shared responsibility model of FinOps, which encourages continuous collaboration between all FinOps stakeholders. More on the specific stakeholders below.
- Ownership. Here, the focus is on improving cloud cost accountability. Using real-time cost allocation, chargebacks, showbacks, and measuring cost per unit can all help you achieve this.
- Business-driven decisions. This principle encourages you to understand your cloud costs in the context of your business. This way, you can map your cloud usage and associated costs to the value you derive as a business. You can do this by understanding your cost drivers to decide whether to invest more in certain areas to maximize value or reduce usage in others to cut costs.
- Timely reporting. The goal here is to surface cost data as soon as it is available. A real-time cost allocation method helps accomplish this by generating quick feedback loops.
- Centralized leadership. You should have a dedicated FinOps team to lead its implementation across teams. Having a defined team makes monitoring progress, delivering business value, and governing responsible cloud usage across the organization easier.
- Take advantage of the variable cost model of the cloud. FinOps, much like DevOps, is a cultural shift. And that means it is about making continuous adjustments to how you consume cloud resources as your business grows and evolves, enabling it to thrive at any stage.
FinOps Benefits: Does FinOps Really Matter?
For any organization running in the cloud, controlling costs isn’t just about cutting spending. Knowing how much it costs to run specific aspects of your business and what levers you can pull to change it can give you a competitive edge.
How?
FinOps can help you answer questions such as:
- Where do we cut spending without negatively impacting performance, security, or engineering velocity?
- Which products do we invest more in to generate more revenue or additional revenue streams?
- Are we pricing all of our product features for strong margins? Are there any with unusually low margins?
- Which aspects of our architecture are “always on” versus which are we only paying for when customers utilize them?
- How would our cost change if we doubled our customers tomorrow or hit our sales plan next quarter?
- Which product features are most expensive to run but are popular with customers?
- Which product or features should we retire in favor of revenue-producing ones?
- Who are our most expensive customers, and are we pricing their services profitably?
- How would our costs change if we onboarded new customers tomorrow, next week, or next month?
- What happens to the cost of goods sold if the unit price of one of our inputs changes?
The FinOps approach takes cost data and breaks it down into granular, actionable insights that tell a story in the context of your business.
What The Data Actually Shows
FinOps maturity is real. So is the efficiency collapse that followed it.
In CloudZero’s 2025 cloud cost benchmarking survey — 475 senior leaders at cloud-mature, AI-active organizations — formal cloud cost programs nearly doubled year over year, from 39% to 72%. Budget assignment reached 87%. FinOps functions now exist at 80% of organizations. Every maturity signal improved.
The Cloud Efficiency Rate didn’t. The CER measures how efficiently an organization converts revenue into value net of cloud spend. The formula: (Revenue – Cloud Costs) / Revenue. In 2024, the median was 80%. This year it dropped to 65%. Top performers fell from 92% to 85%. The 25th percentile fell to 45%. Every segment, every quartile, declined.
AI is the clearest factor. 40% of organizations now spend $10M or more annually on AI — approaching the 47% spending that much on cloud. But 78% fold AI costs into overall cloud costs without the granularity to distinguish what’s driving spend. They’re watching a single number grow without knowing why.
The visibility gap is the operational problem. Lack of visibility ranks as the top AI cost challenge — cited in the top three by 60% of respondents. Only 20% of organizations forecasted their AI spend within 10% of actual spend. One in five missed by 50% or more.
The takeaway isn’t that FinOps failed. It’s that AI introduced variables the original playbook wasn’t built for. Token volume, model sprawl, and consumption-driven pricing don’t behave like provisioned capacity. Managing them the same way produces the results above.
FinOps Team And Stakeholders: Who Is Involved In FinOps?
While FinOps is an organization-wide, shared responsibility, there is a select circle of FinOps practitioners with whom you should work together to make it a competitive advantage.
The exact composition of a FinOps team will vary from one organization to the next. A typical FinOps team consists of a representative from the executive, finance/IT procurement, engineering, ITAM, FinOps professional, and the product owner.
Here’s a quick overview of different roles in the FinOps team structure. For each role, we’ve included some metrics and objectives to track, according to the FinOps Foundation.
FinOps practitioner
These professionals help implement best practices for cloud cost optimization in daily operations. They gather unit cost data to drive cost budgeting and forecasting.

Engineering
Cloud engineers must be cost-conscious due to the on-demand nature of cloud resources. When engineering knows how its architectural decisions affect the organization’s bottom line and competitiveness, it can develop cost-effective solutions at the technical level to ensure long-term cost savings — without sacrificing velocity, innovation, and quality.

Product owner
This is the stakeholder responsible for delivering value to customers using cloud resources. With accurate, timely, and actionable cloud cost intelligence, the product owner can deliver the product or service at a competitive price (SaaS pricing) at a healthy profit margin.

ITAM practitioner/leader
The IT asset management practitioner is responsible for optimizing resource utilization, minimizing waste, and improving return on investment.

CEO
The Chief Executive Officer wants to know that cloud investments align with the organization’s business goals.

CTO
The CTO’s role in a FinOps team is to ensure that cloud technology delivers value to the business and a competitive advantage among competitors.

CFO
As the organization’s chief accounting officer, the CFO helps everyone understand cloud usage costs (Cloud Total Cost of Ownership (Cloud TCO)).

IT Procurement
In this role, the professional negotiates software license agreements, compares cloud providers and vendors, and employs other tactics to ensure the organization receives the best price-performance value.

After determining your FinOps team structure, you can implement best practices in your cloud environment and across the organization. Here is how.
How To Implement A FinOps Program
So, how do you get a better handle on your cloud spend? Here’s a step-by-step guide to applying FinOps in your organization.
The FinOps Foundation breaks down the process further, as you can see in this image:
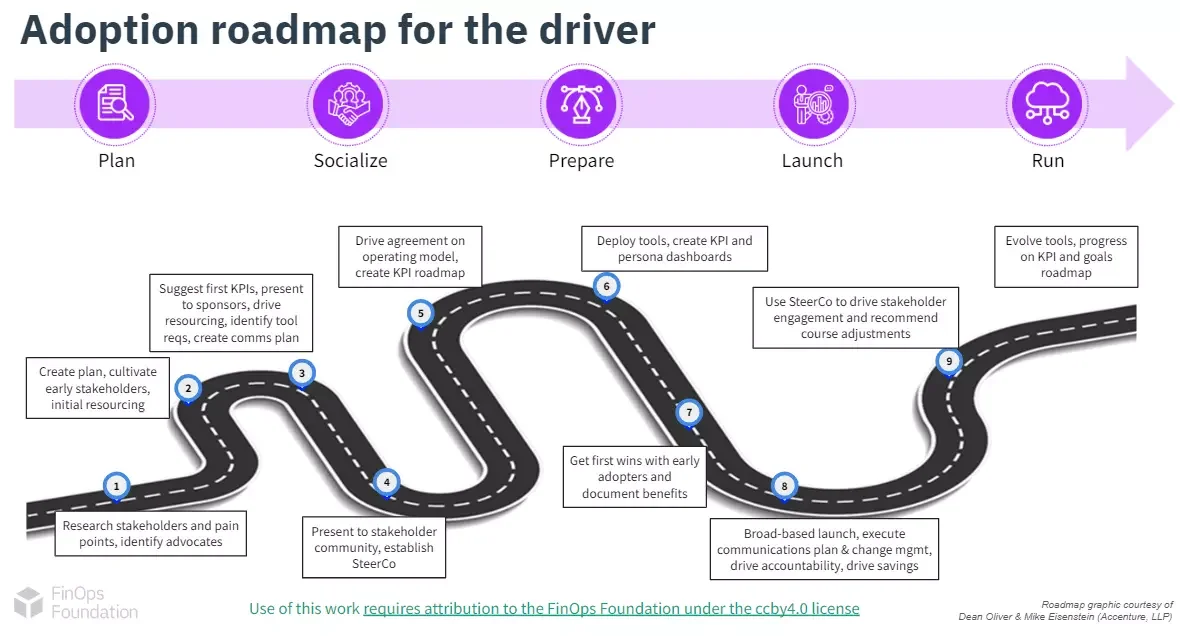
Now, let’s break this FinOps implementation plan down real quick.
1. Plan for FinOps adoption
Start by researching pain points, operational issues, and other challenges that your organization’s teams and business units face. Encourage teams to articulate issues clearly and concisely, including how they believe other teams affect them.
For instance, finance might complain that engineering provisioned more cloud resources than necessary. Engineering might feel that finance only focuses on money rather than providing redundancy to minimize service disruptions.
Then, assemble a pilot team of engineers, finance, and C-Suite representatives to brainstorm a vision of what you’d like to accomplish. At this point, it is okay to ask an external consultant for guidance.
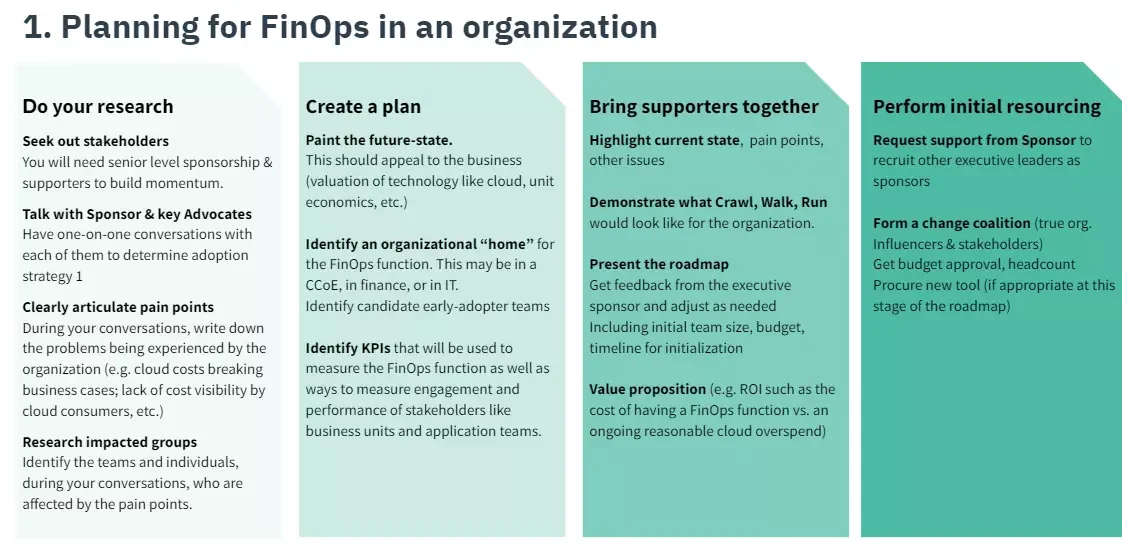
Credit: How to plan a FinOps adoption – FinOps Foundation
2. Socializing FinOps to the team
The next step is to vividly communicate how adopting a FinOps framework works so you can foster goodwill. You’re also trying to mentally prepare all involved about what they’ll have to improve regarding their values and routines to start seeing progress (a cultural shift).
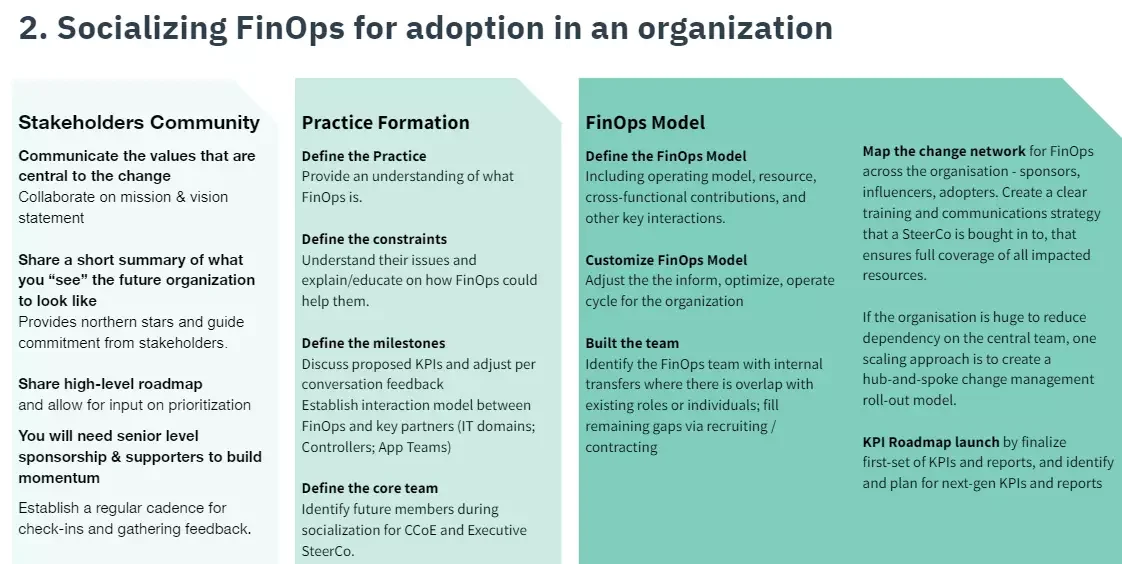
How to promote a cultural shift to FinOps in your organization
3. FinOps preparation phase
In this phase, you establish key performance indicators (KPIs) to measure your FinOps progress.
You can also create a roadmap defining the progression of your FinOps adoption journey: crawl (starting), Walk (scaling), and Run (mature, full-blown, cost-conscious operations).

Credit: Preparing for FinOps adoption
4. Launch FinOps
After laying down the fundamentals theoretically and in terms of infrastructure changes, it is time to implement FinOps best practices sustainably.
Change the basics first. Getting the simple things right will help your team develop the enthusiasm and momentum needed to build more complex workflows.
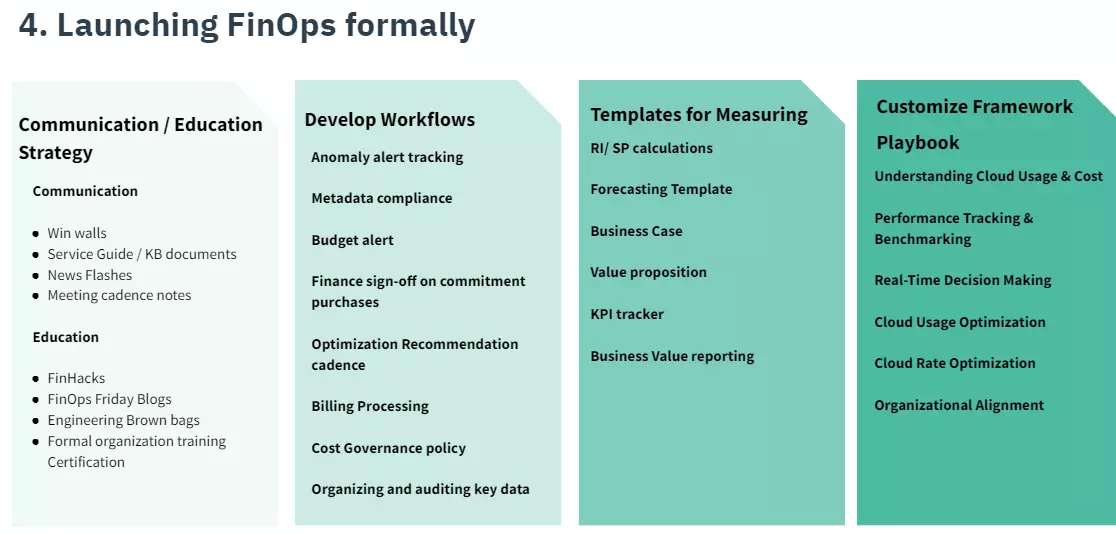
5. FinOps running phase
In this phase, you’ll actively implement several FinOps principles in production. Be sure to compare actual performance against the KPIs you established earlier to gauge progress.
Continuous monitoring will help you identify which areas need more attention to achieve your FinOps goals.
So, what FinOps best practices will you want to apply right away?
FinOps Best Practices To Make Your FinOps Initiative A Success
Here are some of the critical FinOps principles to apply right away.
- To chart the course for FinOps, a diverse team representing all stakeholders must be brought together.
- Consider inviting external experts to strengthen your team’s expertise at any stage.
- Sell FinOps’s benefits to specific teams or business units to get buy-in. This creates an incentive for your people to overcome resistance to change.
- Align engineering and finance teams by encouraging early and frequent communication so they understand each other’s priorities and problems.
- Agree on which decisions to shift left to engineering to encourage faster responses to architectural issues where delayed answers may lead to overspending.
- Measure unit costs, such as cost per customer, cost per deployment, and cost per team. This will help you identify key levers, trade-offs, compromises, and opportunities that can be used without compromising smooth service delivery.
- Encourage practices that foster a cost-awareness culture, such as right-sizing resources and terminating idle ones.
- Leverage user-friendly and robust FinOps tools to automate continuous monitoring and optimization.
FinOps In The AI Era: What’s Changed
The three-phase framework — Inform, Optimize, Operate — still holds. What changed is what you’re trying to see, and how hard it is to see it.
Traditional cloud costs scale with infrastructure decisions. You provision capacity, you pay for it, you right-size it. The cost drivers are controlled by engineering teams and visible in billing consoles. FinOps built its entire methodology around that model, and it worked.
AI costs don’t behave that way. Token volume, model selection, prompt efficiency, and user behavior patterns now move the needle in ways provisioning decisions didn’t before. A customer asking longer questions or a product team choosing a larger model can shift the bill significantly — and neither shows up cleanly in a standard cost report.
The result: organizations that perfected their budgets, chargebacks, and governance processes are still losing the efficiency battle. Because the cost drivers moved, and the measurement didn’t follow.
What separates organizations that are adapting:
- They track AI spend separately from cloud — not just as a line item, but with attribution to customers, products, and features
- They’ve moved cost optimization down the stack, from contract negotiations to code and model selection
- They treat cost intelligence as a continuous feedback loop, not a monthly report
- They know the difference between strategic unprofitability (deliberate investment ahead of revenue) and unquantified leakage — and they can prove which one they’re in
FinOps isn’t broken. It’s at the beginning of a new maturity curve. The organizations investing in granular AI cost visibility now will have the infrastructure to optimize when the market stops tolerating unprofitable AI. That window is closing.
FinOps Tools: Which FinOps Solutions Are Best for Getting Started?
The right FinOps tool depends on what’s driving your cost complexity. Choosing FinOps software that maps spend to business context — not just billing — is the key differentiator. Here are 3 to consider based on the problem they solve best.
1. CloudZero
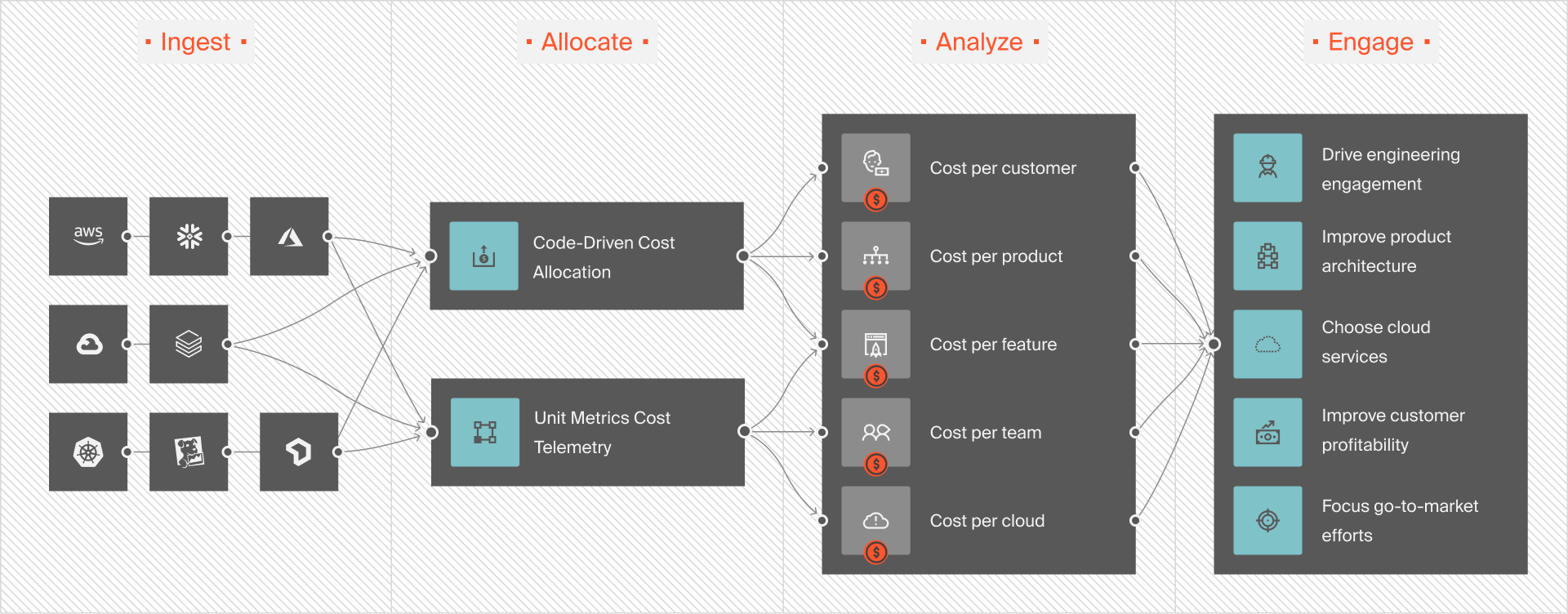
CloudZero is a cloud and AI cost intelligence platform built around a single question: is this spend delivering value? It maps costs from more than 50 cloud, data, and AI providers — including AWS, Azure, GCP, Kubernetes, OpenAI, Anthropic, Snowflake, and Datadog — to the business context that makes them actionable.
- Engineers see cost per deployment, service, environment, team, and Kubernetes cluster — and can now query spend directly inside Claude Code via the new CloudZero Claude Code Plugin, which embeds CloudZero’s full cost model into the engineering workflow via an MCP server and nine pre-packaged FinOps skills.
- Finance sees cost per customer, COGS, and gross margin — with 100% of cloud spend allocated, even without perfect tagging. CloudZero was the first cloud cost platform to deliver unit economics without requiring complete tag coverage, using a code-driven allocation approach that works regardless of tag hygiene.
- FinOps teams can allocate spend in minutes, detect anomalies hourly against 12 months of historical patterns, and route alerts directly to the relevant team in Slack or email.
- AI cost management goes beyond a line item. CloudZero connects token usage, model costs, and inference spend to the specific products and customers driving them — making it possible to calculate cost per inference, cost per AI feature, and AI’s actual contribution to COGS.
- Leadership gets the unit economics needed to answer the question every board is now asking: is our AI investment worth what we’re spending?
Year founded: 2016
Category: Cloud Cost Intelligence
Best for: Mid-market to enterprise organizations that need granular cost attribution, unit economics across cloud and AI spend, and engineering-led optimization — not just spend reporting
Pricing Model: CloudZero pricing is custom to your environment.
 to see CloudZero in action. One of our Certified FinOps professionals is waiting to engage your team and provide insider tips and tricks to get you from Crawl to Walk to Run in days to weeks — not months or years.
to see CloudZero in action. One of our Certified FinOps professionals is waiting to engage your team and provide insider tips and tricks to get you from Crawl to Walk to Run in days to weeks — not months or years.
2. AWS Cost Explorer
Cost Explorer is free to all AWS customers. If your requirements are relatively straightforward and you don’t need cost visibility across complex, variable infrastructure, Cost Explorer might be enough for you.
The tool features dashboards, rightsizing, Savings Plans recommendations, and cost anomaly alerts.
Year founded: 2014
Category: AWS Native Tools
Pricing model: Free with AWS
Best for: Businesses that have relatively straightforward billing and spending patterns
3. Cast.ai
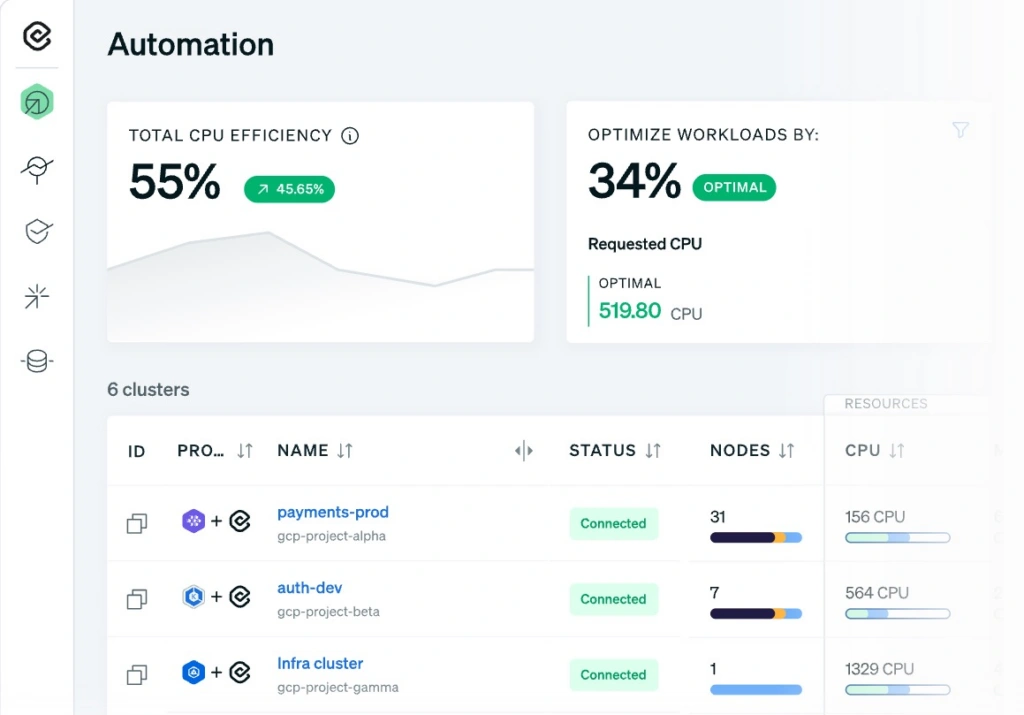
Cast.ai is a Kubernetes automation platform that uses machine learning to continuously optimize cloud infrastructure costs in real time — without requiring manual tuning or intervention. Where most FinOps tools surface recommendations for engineers to act on, Cast.ai acts autonomously: rightsizing nodes, orchestrating spot instances, and scaling workloads to match demand on an ongoing basis.
Cast.ai is recognized as an IDC Innovator for FinOps and Cloud Cost Transparency and was named in the Forrester Cloud Cost Management and Optimization Solutions Landscape in 2025.
Year founded: 2019
Category: Kubernetes Cost Automation
Pricing model: Custom; tiered by node count
Best for: Engineering and FinOps teams running Kubernetes workloads on AWS, Azure, or GCP that want automated, continuous cost optimization rather than manual recommendations
Frequently Asked Questions About FinOps
Here are some answers to frequently asked questions about FinOps meaning, adoption, and implementation.
See what’s driving your cloud and AI spend
Most organizations know their cloud bill is growing. Fewer know which customers, products, or teams are driving it — or whether the spend is delivering value. CloudZero maps your costs to the business context that makes them actionable. Schedule a demo to see it in your environment.











