
AI adoption is reshaping how organizations innovate. It’s also driving cloud costs higher. CloudZero’s State of FinOps in the AI Era report — a survey of 475 senior technology and finance leaders — found that median Cloud Efficiency Rate collapsed from 80% to 65% in a single year, even as FinOps maturity indicators roughly doubled. Visibility into AI costs is a critical first step, but it’s not enough.
To enable fast, responsible AI and machine learning innovation at scale, teams need pragmatic, flexible guardrails. They don’t need rigid budgets or knee-jerk shutdowns that slow progress or push teams into shadow ML.
This post is the implementation playbook for the guardrails step of a broader AI cost program. For the full framework on allocation, unit economics, infrastructure levers, token economics, and deployment strategy, see our deep dive on AI cost optimization.
What follows is a practical blueprint for operationalizing spend guardrails without sacrificing velocity, blending tagging, dynamic budgeting, and collaborative policies to empower AI teams (and keep your CFO happy).
Why Tagging Alone Isn’t Enough
Let’s be clear from the get-go: effective tagging is non-negotiable. Tagging AI workloads by project, function, model lifecycle stage, and even output quality unlocks essential insights. These tags transform opaque technical consumption into transparent business metrics like cost per feature or cost per successful output. With that structure in place, teams can analyze trends, make smarter trade-offs, and foster accountability.
Tagging, however, isn’t foolproof. It can be a tedious effort. You may have already stopped doing it altogether or are looking for a better way. Ephemeral experiments often launch without tags, teams apply them inconsistently, and tag sprawl eventually clutters dashboards.
Fortunately, that’s solvable. You can organize cloud spend, even with untaggable resources.
AI and ML operations pose unique challenges, even with solid tagging. That’s because they are:
- Fast-moving, with rapid model iterations and frequent new experiments
- Cross-functional, involving data scientists, ML engineers, product managers, and finance
- Complex, toggling constantly between exploratory and production workloads
Simply knowing where money is going doesn’t tell you whether spending is on target, or who decides to pull the plug on runaway AI cloud costs. In the world of AI where creativity and costs can surge in tandem, your visibility needs to evolve to real-time agility and enforceable guardrails that still allow for smart innovation instead of blocking it.
Report
Finance needs to prove AI’s return: CloudZero report
260 senior finance leaders (more than half CFOs) told us why the speed of seeing AI spend, not the size of it, separates who pulls ahead on AI from who gets burned.
The Foundational Challenge: Seeing AI Costs In The First Place
Before you can enable adaptive guardrails or dynamic budgets, finance leaders need a reliable way to even see AI costs as a whole. Unlike marketing or sales, AI spend rarely shows up as a single controllable line item. Rather, it’s fragmented across compute, storage, SaaS services, and team budgets.
This is why tagging and showback are so important. Start by treating AI spend visibility as a maturity milestone:
- Level 0: No consistent view. AI is buried inside general cloud, infra costs, or even credit cards
- Level 1: Tagging provides partial visibility into experiments and workloads.
- Level 2: AI spend is aggregated into dashboards and unit metrics (cost per inference, cost per feature).
- Level 3: Costs are fully connected to business outcomes, allowing for budgeting and trade-offs like any other initiative.
Guardrails and dynamic budgeting only work once you’ve reached Level 1–2 maturity. If you’re at Level 0, the priority isn’t enforcing guardrails. It’s building the visibility foundation.
Once that foundation is in place, the question then shifts from “Where are our AI costs?” to “How do we keep them under control without stifling innovation?”
Or, as CloudZero’s founder and CTO Erik Peterson writes: “The key question is no longer, ‘How much did we spend?’ It’s now: ‘Was it worth it?’”
The first step toward effective guardrails, then, is to identify the unit that represents value for your product. Allocate AI spend to that unit. Set a target margin. Then wire live signals to people who can act.
That’s where modern guardrails come in.
The Modern AI Budget Guardrail Philosophy
Conventional cost controls like hard budgets and reactive approvals rigidly constrain teams and frustrate innovation. Leading AI organizations instead build adaptive, transparent, and collaborative guardrails that act as safety nets rather than cages.
These guardrails:
Can be tailored to experiment maturity. Start with conservative limits in R&D, then expand budgets and permissions as models prove value and move toward production. As Larry Advey from CloudZero writes: “True FinOps isn’t just about cost savings or dashboards. It’s a connection — between technology, innovation, and business value. Sometimes this even requires a little shameback.
Detect anomalies in real time. Watch for GPU usage spikes, abnormal cost per inference, or sudden drops in model quality. Use historical patterns to set thresholds, so alerts catch waste without blocking valid experiments. For example, one customer told CloudZero that he wants to spend money on AI and research, but just needs to know what to expect and have some observability, accountability, and especially understanding when a $30K spike shows up.
Balance oversight with speed. Give engineers autonomy on low-risk overruns, while escalating bigger exceptions to finance or product leaders. That way, spend stays controlled without bottlenecking innovation.
Guardrails are levers, not shackles. Think of them as financial limits that enable speed rather than block it.
Examples from the Field
- Experiment sandboxes: Pre-approved spend zones isolate exploratory models from production workloads, allowing teams to try new ideas with sanctioned budgets.
- Anomaly alerting: Automated flags routed to ML leads and FinOps when usage spikes, unusual resource mixes appear, or model quality dips unexpectedly.
- Progressive budget gates: Spending limits increase as experiments prove value, moving from conservative thresholds in early trials to loftier caps in scaled production.
- Fast-fail mechanisms: Automation halts experiments exceeding cost or quality redlines, conserving budget while preserving team agility.
Rather than a blunt “cut spend now” approach, these guardrails form a flexible continuum from soft nudges to hard stops and everything in between. They give teams a predictable financial runway, and enough confidence to run daily experiments, test variants in parallel, and know when the next budget checkpoint is coming. The resulting clarity speeds up delivery without creating unchecked risk.
Integrating Guardrails And Tagging: The 3-Layer Approach
Layering guardrails over tagging transforms cost data from a reporting tool into a governance engine.
Layer 1: Tagging for unit economics (foundation)
Deploy a tagging taxonomy that spans:
- Workload Types: Training, inference, fine-tuning, data preparation
- Business Features: e.g., “recommendations-v2-inference”
- Experiment vs Production Status: Clearly demarcate exploratory from revenue-facing work
This foundation enables clear calculation of unit economics: cost per feature, output, and customer segment. Teams link cloud consumption to business value and prioritize accordingly.
Layer 2: Dynamic budgeting and alerting
With tagging as your lens, establish budgets that flex with project lifecycle and risk:
- Define spending “safe zones” per function and phase (e.g., $X/month for exploratory training, $Y/output for inference).
- Equip teams with real-time dashboards showing burn rates against dynamic budgets, with spend-of-change impact.
- Automate anomaly detection using pattern recognition to catch emerging risks rather than relying only on fixed thresholds.
Layer 3: Policy automation and adaptive optimization
Elevate budgeting and guardrails into automated, code-driven policies:
- Use “policy-as-code” to deploy spend guardrails alongside your infrastructure and security controls.
- Create role-based workflows. These allow engineers to approve minor budget overruns, while finance or product leadership get involved in major decisions.
- Dynamically scale budgets as pilots prove ROI, turning successful experiments into larger investments seamlessly.
Keep in mind that policy automation works best once tagging is consistent and budget ownership is clearly defined. Without it, you risk false positives, constant overrides, and policy churn that frustrates engineers. Done right, though, this approach keeps cost controls ‘just tight enough’ while avoiding bottlenecks that drag innovation.
Cross-Functional Collaboration: Making Guardrails Work
Even the most elegant guardrails will fail without shared ownership. Finance and engineering must own AI cost guardrails together. But this isn’t always smooth.
Finance may worry about runaway GPU costs while engineers push to keep experiments running at all costs. Without clear guardrails, these tensions turn into friction and slow decision-making.
Collaborative policies and councils resolve this by setting rules up front: which costs can engineers approve on the spot, and which need finance or product sign-off before proceeding.
For example, a SaaS company sets a policy where engineers can greenlight small budget overruns themselves. Larger overruns trigger a same-day joint review with finance and product. If expectations are set for all parties with clear deliverables and timelines, this can keep GPU-heavy experiments moving quickly without losing financial discipline.
In short, successful organizations build intentional forums and clear processes to foster collaboration and real-time visibility into AI budgets and experiments:
Experiment councils
These are fast, recurring cross-team meetings where product, engineering, ML, and FinOps stakeholders review sandbox requests, cost reports, budget exceptions, and anomalies collaboratively.
Forbes highlights the value of creating dedicated FinOps and AI steering groups, often called Cloud Centers of Excellence, that include AI/ML representation to align spending with business goals and speed decision-making without friction or finger-pointing.
InformationWeek’s coverage of AI Councils showcases enterprises using these bodies to monitor cost efficiency and business impact, effectively bridging finance and engineering perspectives.
Quarterly budget retrospectives
Leading FinOps practices embed deep-dive reviews into quarterly cycles, bringing together finance, engineering, and product teams to spotlight which cost rules foster innovation and which policies slow down velocity.
CloudZero recommends incorporating anomaly alerts, performance metrics, and iterative budget updates into these sessions to make governance an ongoing, data-driven process, not a once-a-year checkbox.
Integrated runbooks
Automated guardrails and anomaly detection tools are only as effective as the documented playbooks governing exceptions. CloudZero advises maintaining clear runbooks that define when and how budget exceptions are escalated and resolved, using policy-as-code for version-controlled enforcement logic with defined finance-engineering workflows.
The FinOps Foundation also promotes pairing threshold alerts with formal escalation paths to ensure spend stays on track while minimizing disruption to engineering agility. They share the following structure courtesy of Eric Lam, Head of FinOps at Google Cloud:
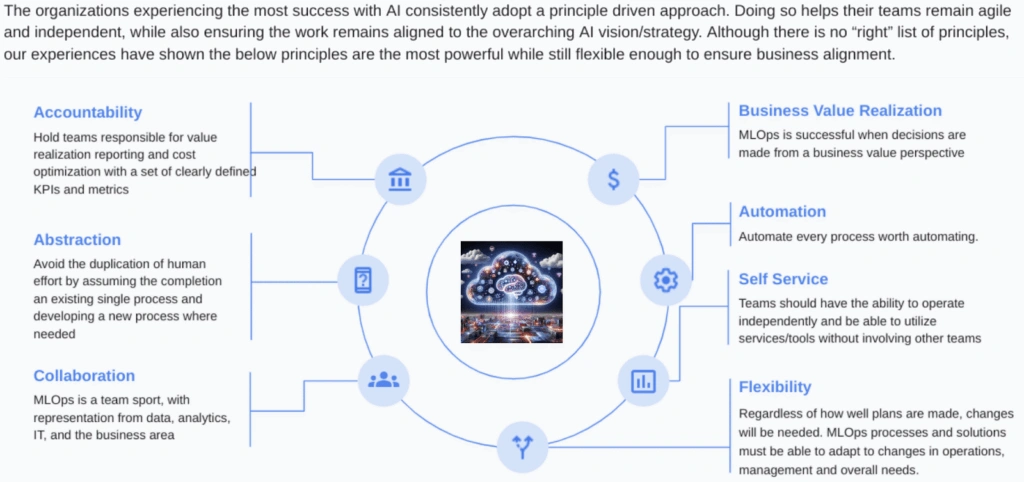
Also, consider a fintech startup that enables 60+ ML experiments within controlled sandboxes. When a GPU cost spike occurs, cross-team anomaly alerts quickly trigger a collaborative root cause analysis, resolving the issue without lengthy finance reviews or team blame.
This exemplifies how the right guardrails, backed by councils, retrospectives, and runbooks, create an environment where innovation thrives within financial guardrails, embodying the best practices validated by CloudZero customers and the FinOps community.
Dashboards, KPIs, and reporting
The AI cost guardrails blueprint delivers different insights tailored to key roles:
- For engineers: spend per experiment, cost against model accuracy, anomaly queue,
- For product owners: feature cost forecasts, scaling impact projections,
- For finance: unit costs by customer segment, spend vs. revenue overlays, budget runway,
- For executives: R&D spend ratios, innovation velocity, infrastructure efficiency.
Robust dashboards merge financials, performance, and engineering workflows—helping all teams move in sync.
This is a sandbox request workflow that you can start acting on:
- Submit project plan with tagging and cost estimate,
- Receive capped resource allocation,
- Activate work environment,
- Anomaly triggers auto-review and escalation.
And common gotchas and future-proofing to build in:
- Guardrail rigidity: Overly strict policies curb innovation; stay open to feedback and review quarterly.
- Shadow ML spend: Proactively encourage reporting and demystify cost tracking to prevent off-the-books experiments.
- Evolving AI governance: Prepare for integrating ethical and regulatory guardrails as AI accountability frameworks advance.
Build Enablement, Not Bureaucracy
In today’s AI era, FinOps leaders are enablers, not cost cops. AI ROI comes from letting teams run dozens of experiments, test models quickly, and scale the successful ones without losing financial alignment.
If you’ve established tagging discipline, now’s the time to build adaptive guardrails, dynamic budgets, and cross-functional policies that make costs predictable while keeping experiments flowing.
Start small. Audit your tagging and sandbox governance, pilot policy automation, and convene your experiment council. Then iterate quickly, using each cycle to expand what teams can try next while keeping spend under control. For the foundational framework that guardrails plug into, see how CloudZero approaches AI cost management.
For the full framework behind these guardrails — covering lifecycle budgeting, multi-cloud governance, and FinOps culture — download CloudZero’s AI Cost Optimization Playbook.











