

AI adoption isn’t just accelerating, it’s compounding. From GPT-5 to Claude to Llama and beyond, engineering teams are integrating diverse LLMs across products, experiments, and services. And finance teams are now grappling with a new kind of cloud complexity: token-based economics and volatile inference costs, often spread across multi-model, multi-cloud, and multi-region architectures.
The modern FinOps stack needs to keep up. CloudZero was built for this moment.
Have AI spend on your mind? Learn more in CloudZero’s Aug. 21 webinar/live demo: “How Top Teams Optimize AI Spend Without Slowing Down”. Register now!
CloudZero: Built For The AI Era — Not Just The Cloud One
CloudZero has long helped organizations optimize cloud spend across AWS, Azure, GCP, Snowflake, and Databricks. But as AI investments balloon, a new frontier has emerged: LLM cost intelligence.
Today, over 90% of CloudZero customers are ingesting AI-related spend in the platform. And just as with traditional cloud cost management, CloudZero brings clarity, precision, and control to chaotic AI spend, without relying on perfect tags or engineering heroics.
Key CloudZero AI-specific FinOps capabilities:
- Token-level cost intelligence: See exactly how much each model, feature, or experiment is costing you, down to the token.
- No tagging required: CloudZero’s ingestion engine doesn’t rely on tags, making it ideal for the messy, fast-moving reality of AI development.
- Model-aware allocation: Allocate spend by model family (e.g., ChatGPT, Claude), cloud region, feature, app, or customer segment.
- Designed for engineering and finance: No YAML, no scripts, no dependencies. CloudZero delivers answers in a way that makes both tech and finance teams successful.
- Real-time visibility for real-time AI: Understand the cost implications of experiments, fine-tuning, token caching, and multi-vendor LLM strategies as they happen.
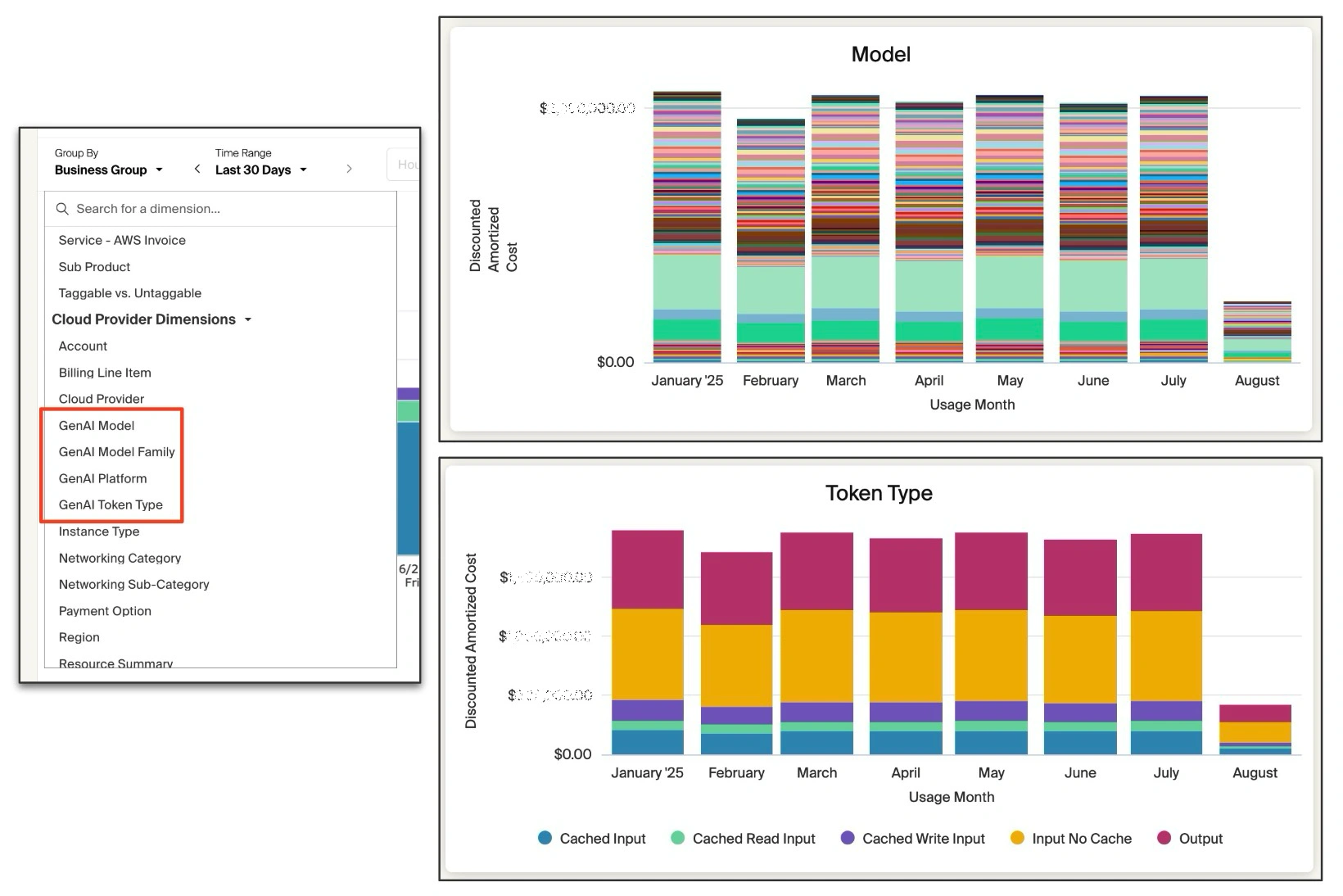
Figure 1: (Left) GenAI Dimension-aware Common Data Model. (Top Right) Various models being used each month. (Bottom Right) Different kinds of token types in use and the costs shown month-over-month. (image edited for privacy)

Inside A Multi-Model AI Stack: A Real-World CloudZero Use Case
Companies are using CloudZero not just to get a handle on their AI spend, but to optimize and allocate it.
One global SaaS platform with over 40 million users is navigating the chaos of modern AI at scale. Their engineering org actively leverages over 50 LLMs, spanning multiple GPTs, Claude, Llama, and a bunch of other models, across multiple regions and workloads.
As their architecture matured, cost tracking and allocation grew increasingly complex. CloudZero enabled them to make sense of it all.
Results in Just Months:
- Granular allocations: Spend attribution by customer, region, app, OS (Mac vs. Windows), and user tier (free vs. premium)
- Unit economics by model and segment: Cost-per-token and cost-per-user data tied directly to model usage and customer value
- $1M+ in immediate savings: Uncovered by optimizing inference workloads and leveraging token caching. Also achieved 50%+ reduction in compute spend.
- Clear line of sight to business value: Connected LLM investments to outcomes across 40M users and tens of thousands of orgs.
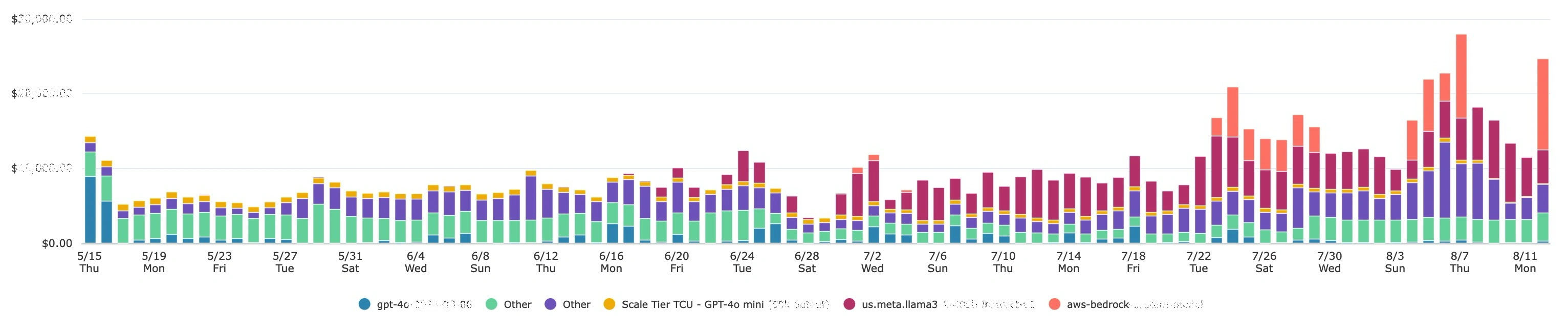
Figure 2: Change in cost by model over a 90-day period. Shows opportunities for optimization and 100% visibility into where the AI costs are going. (image edited for privacy)
Engineering-Led FinOps for the AI Era
AI complexity is already here and it’s not slowing down. If you’re asking questions like:
- How much does each token cost us across models?
- Can finance allocate spend without engineering getting involved?
- Are we capturing fallback and active-active usage patterns correctly?
… you’re not alone. Most teams don’t have a reliable answer. CloudZero gives you one.
If AI spend is on your mind, register now for our August 21st webinar/live demo: “How Top Teams Optimize AI Spend Without Slowing Down”.


The Cloud Cost Playbook
The step-by-step guide to cost maturity



