

Tags have long been the backbone of cloud cost visibility and governance. They help teams understand who owns what, where spend comes from, and how infrastructure maps back to the value the business delivers.
However, AI workloads have altered that model, and exposed the limitations of traditional AI tags in the process.
In fact, many of the most expensive AI operations don’t run on taggable cloud resources at all.
Instead, they run in places where tags can’t follow, even though the costs still land squarely on your bottom line.
Let’s go beyond what doesn’t work, and look at what to do instead.
In the next few minutes, we’ll explore why traditional tagging breaks down for AI workloads, what teams actually need to understand AI costs and behavior, and how to think about AI tagging in a way that reflects how your modern AI systems really operate.
Let’s dive in.
Why Traditional Cloud Tags Can’t Follow AI Workloads
Picture this. Tagging AI workloads using traditional cloud tags is like trying to track international shipments using a warehouse inventory label.
As long as everything stays inside the warehouse, the system works. You know what’s stored where, who owns it, and how much space it takes up.
But the moment those shipments leave the building, moving through ports, carriers, customs, and third-party logistics providers, that label stops telling you anything useful.
That’s what happens when teams apply traditional tags to AI workloads.
Traditional tagging was built for a world where workloads live neatly inside your cloud environment. Compute. Storage. Networking. And managed services that support tagging.
You provision resources. You attach tags. Those tags persist long enough to answer familiar questions, like who owns this resource, which environment it belongs to, and how its cost should be allocated.
AI workloads don’t behave that way
In contrast, most modern AI systems are API-driven, ephemeral, and distributed across services you don’t fully control. As a result, the cost center often shifts away from taggable infrastructure and into places like:
- External LLM APIs
- Managed AI platforms
- SaaS-based inference services
- Vector databases and search layers
- Usage-based pricing models that bill per request or per token
Once an AI request leaves your cloud account, your tags stop traveling with it.
The workload continues.
The usage and the costs continue.
But the metadata you rely on to explain why that cost exists… disappears.
Ephemerality breaks tagging assumptions
Also, AI interactions often last milliseconds. They spin up, execute, and disappear, sometimes thousands or millions of times per day. By the time a tag could theoretically be applied, the cost-driving action has already happened.
In that sense, the tags are working exactly as designed. But they’re attached to the wrong layer of the system.
To make matters more complex, a single AI-powered feature may involve multiple model calls, retries, fallback logic, and downstream services. Many of those never touch a taggable cloud resource at all.
That creates a fundamental mismatch between how cloud tags work and how AI workloads actually run.
Tags describe resources. AI costs come from behavior.
Cloud tags are excellent at describing what a resource is and who owns it. They’re far less effective at capturing how something is used.
AI costs, on the other hand, are driven almost entirely by behavior, such as:
- How often models are invoked
- How large prompts and context windows become
- How frequently retries or fallback models are triggered
- How embedding generation and vector search scale with usage
- How experimentation patterns evolve over time
None of that behavior maps cleanly to a persistent resource with a stable tag.
You can tag the infrastructure that calls an AI service. You can tag the environment it runs in. But it’s nearly impossible to tag the request itself. Yet, that’s where the cost is actually generated.
Why this matters for cost, accountability, and decision-making
When AI workloads escape your tagging model, the impact goes well beyond billing confusion.
You lose the ability to:
- Attribute AI costs to specific features or products
- Understand which teams or workflows are driving usage
- Separate intentional experimentation from accidental waste
- Detect early signals of inefficient AI behavior
- Tie AI spend back to customer value or business outcomes
In other words, traditional tags can still tell you where infrastructure lives, but they stop telling you why your AI costs are changing. And that’s the real problem many teams are now running into (and need to solve).

Research Report
FinOps In The AI Era: A Critical Recalibration
What 475 executives told us about AI and cloud efficiency.
What Traditional Tagging Doesn’t Capture (But AI Teams Must Track)
To manage AI effectively, you’ll need visibility into the signals that tags were never designed to capture. Consider these.
1. Token usage and context growth
Most AI platforms bill based on tokens, not requests. And two API calls may look identical at the infrastructure level, yet differ dramatically in cost depending on:
- Prompt size
- Context window expansion
- Output length
- Conversation history carried forward
Tags can’t express any of that. They don’t show you how token usage grows over time, which features consistently generate large contexts, or which workflows push models toward higher-cost usage patterns.
2. Retries, fallbacks, and hidden amplification
AI systems are rarely single-call, single-model workflows. In practice, many AI features include:
- Automatic retries for failed or low-confidence responses
- Fallbacks to larger or more expensive models
- Chained calls across multiple models or services
- Guardrails that trigger additional evaluation rounds
Each step may be reasonable in isolation. But together, they can multiply your costs far beyond what tags on the calling infrastructure would suggest.
Trad tags offer no way to surface this amplification.
3. Embeddings, vector search, and downstream usage
Now, if you are using embeddings and retrieval-augmented generation, your AI costs won’t stop at inference. They’ll extend into:
- Embedding generation volume
- Vector database storage
- Search and retrieval frequency
- Query fan-out across large datasets
These costs are driven by how often your data is embedded, how frequently vectors are searched, and how queries scale with product usage.
These downstream costs scale with usage, and don’t show up on any persistent cloud resource. And as usage grows, these downstream AI costs often scale faster than teams expect.
4. SaaS AI meters and external usage signals
Many AI workloads run through SaaS platforms or managed AI services that expose their own usage meters, billing dimensions, and limits.
These systems may track requests, tokens, compute time, feature-level usage, and model-specific consumption.
Traditional tags can’t ingest or interpret those signals. That usage never touches a taggable resource, but it drives real cost all the same.
So, teams often end up reconciling cloud bills, SaaS invoices, and AI usage dashboards manually, with no shared source of truth.
And that creates blind spots for experimentation
You know this. AI development is inherently experimental.
You test prompts, swap models, tune parameters, and iterate rapidly. That experimentation is healthy, but without visibility into the behavioral cost drivers, it’s risky.
When tags are the primary attribution mechanism:
- Efficient experiments and waste look the same
- High-impact features and low-value tests blend together, and
- Early warning signs of runaway usage go unnoticed
That leads to higher costs, slower learning, more friction between teams, and harder decisions about where to invest next.
Takeaway: Traditional tags still have a role. They help describe ownership and environment at the infrastructure level. But AI costs live at a different layer, one that requires a different way of thinking about attribution, visibility, and accountability. Here is how.
Rethinking AI Tagging: From Labels To AI Cost And Usage Intelligence
At this point, the issue with AI tags isn’t that teams aren’t tagging enough. It’s that traditional tags were never designed to explain AI behavior (which is what drives AI costs, performance, and risk).
So instead of asking “How do we tag AI better?”, the more useful question becomes:
How do we attribute AI usage and cost in a way that reflects how AI systems actually run?
That shift will change your goal for AI tagging entirely.
What effective AI tagging really looks like
For effective AI tagging, you’ll not want to attach more labels to infrastructure. Instead, you’ll want to answer questions like:
- Which models are driving the most cost?
- Which features or workflows trigger the highest usage?
- Which teams or environments are experimenting (and which are scaling)?
- Which customers or use cases generate disproportionate AI spend?
- When did behavior change, and why?
But those answers don’t come from static metadata. They come from correlating AI usage signals, cost data, and business context in real time.
Helpful resource: Making AI Costs Make Sense: A FinOps Guide To Tagging And Tracking AI Spend
Replace static tags with dynamic attribution
Instead of relying solely on tags, you’ll want a way to dynamically attribute AI activity across dimensions that actually matter. These include:
- Model and provider
- Feature, product, or API endpoint
- Environment (prod, staging, experiments)
- Team or service owner
- Customer, tenant, or account
- Request patterns over time
With this approach, you’ll be treating AI costs as behavioral data, not infrastructure inventory.
Helpful resource: How To Tag AI Cloud Spend: A Practical Framework For FinOps Teams
Why this works better for AI teams
When AI attribution is built around usage and behavior:
- Cost spikes are easier to explain and fix
- Experimentation stays fast without becoming reckless
- Accountability improves without slowing engineers down
- Finance and engineering can speak the same language
- Decisions are grounded in real unit economics instead of estimates
Ultimately, AI tagging stops being a manual governance exercise and becomes a feedback loop teams can actually use.
A Practical Example Of How CloudZero Attributes AI Costs
Instead of relying on tags alone, CloudZero connects AI usage data, cloud and SaaS spend, and business context to deliver granular, actionable AI cost intelligence — even when your workloads run outside your cloud accounts.
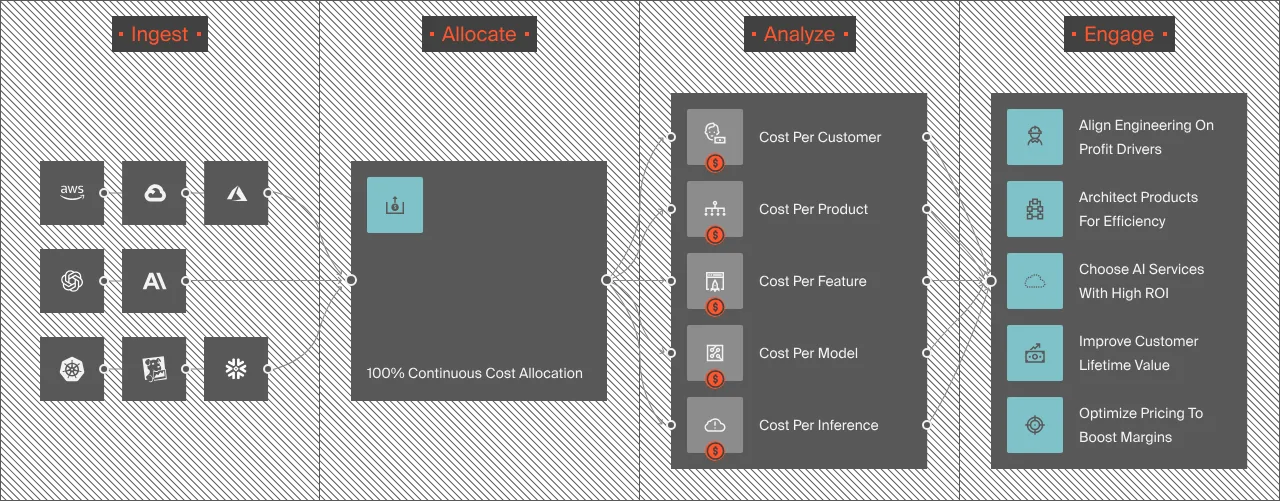
That means you can:
- Attribute AI costs beyond taggable infrastructure to untagged and untaggable resources
- Understand your AI costs per model, service, SDLC stage, feature, team, customer, and beyond
- Track AI unit economics as behavior changes
- Detect anomalies early, with context, so you can tell exactly what’s changing, why, and what to do about it ASAP, like this:
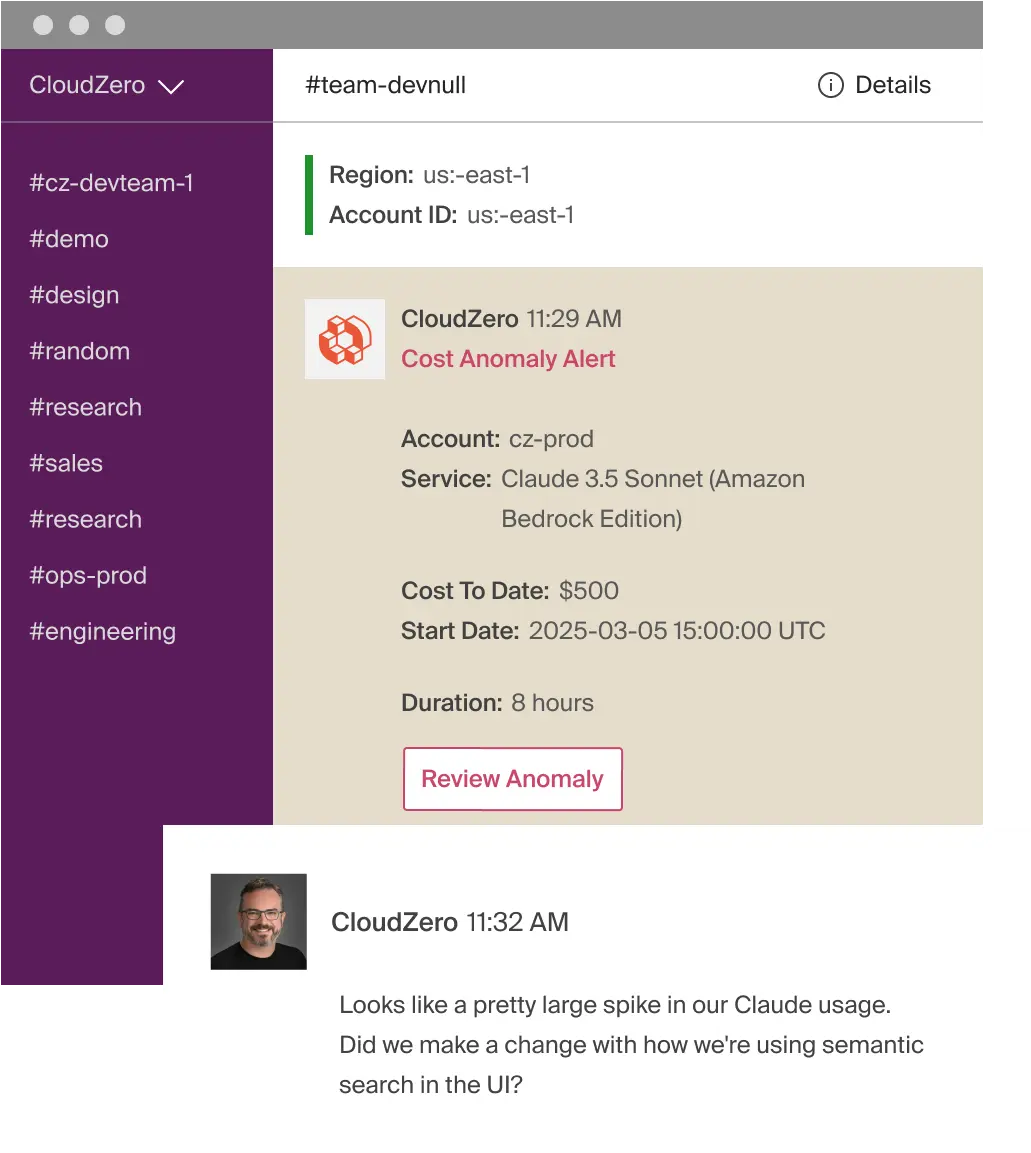
Not by tagging harder, but by measuring what actually matters. With this shift, your AI tagging becomes less about labels and more about clarity.
The final step is seeing how this plays out in real environments, and how to use this visibility to scale AI without sacrificing your margins.
Take The Next Step: Overcome The AI Tagging Barrier Without Losing Your Mind (Or Cost Control)
Tags still play an important role in organizing cloud infrastructure and establishing ownership.
But as AI workloads move beyond the cloud boundary and become more behavior-driven, tags alone can’t explain where your AI costs are coming from. Or, why they are changing. Or how they connect back to your business outcomes.
That gap is what many teams are feeling today.
Managing AI costs now means understanding how specific models are used, how requests behave, how experimentation scales, and how all of that translates into real costs. It requires visibility that follows AI workloads wherever they run (across cloud services, SaaS platforms, and external APIs) and ties usage back to teams, features, and services, like this:
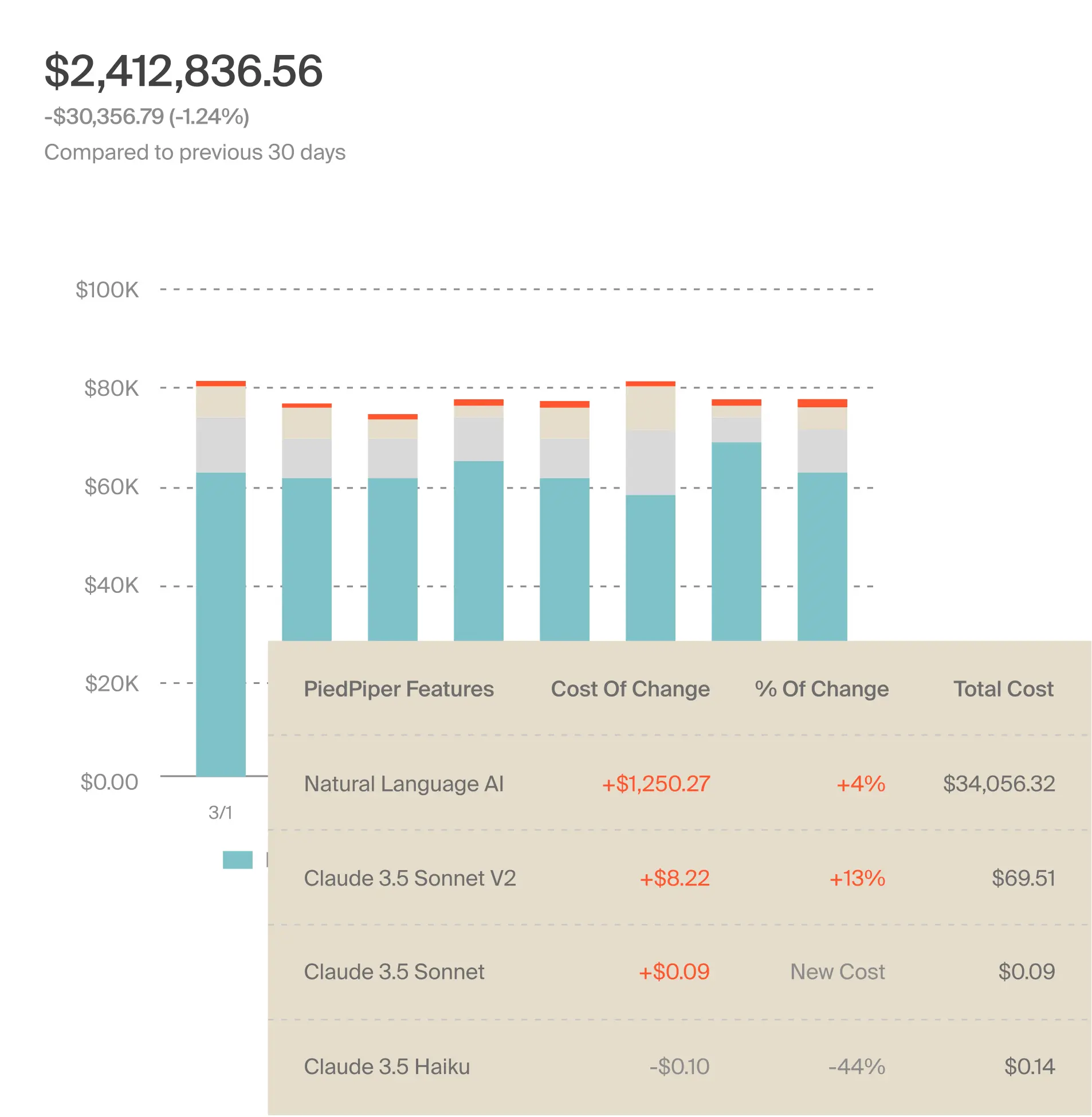
That’s the shift from tagging AI to understanding AI.
If your organization is investing heavily in AI, the question isn’t whether you should use tags. It’s whether you have the visibility needed to make confident decisions as AI usage grows.
If you want to see what that level of clarity looks like in practice,  here to explore how CloudZero already helps teams at Grammarly, Helm.ai, and Coinbase understand their AI costs through usage, behavior, and business context. No pressure. Just better answers to the questions AI makes unavoidable.
here to explore how CloudZero already helps teams at Grammarly, Helm.ai, and Coinbase understand their AI costs through usage, behavior, and business context. No pressure. Just better answers to the questions AI makes unavoidable.
Frequently Asked Questions:
What are AI tags?
AI tags are metadata approaches used to attribute ownership, environment, or purpose to AI-related costs. Unlike traditional cloud tags, effective AI tagging focuses on usage behavior (such as model calls and token consumption) rather than static infrastructure labels.
Why don’t traditional cloud tags work for AI workloads?
Traditional cloud tags fail for AI workloads because most AI costs are generated outside taggable cloud resources. API-based LLM calls, SaaS AI platforms, and usage-based pricing models produce costs driven by behavior, not by persistent infrastructure where tags can be applied.
Can you tag AI API calls or LLM requests?
No. AI API calls and LLM requests cannot be directly tagged in the same way as cloud resources. These requests are ephemeral and execute outside your cloud account, which means traditional tagging metadata does not persist with the cost-driving activity.
What drives AI costs if not infrastructure?
AI costs are driven by behavioral usage signals, including:
- Token usage and context window size
- Model selection and fallback logic
- Retry frequency and chaining
- Embedding generation and vector search activity
These factors determine cost far more than the underlying infrastructure.
How should FinOps teams track AI costs instead of using tags?
FinOps teams should track AI costs using dynamic attribution models that correlate:
- AI usage data (tokens, requests, embeddings)
- Cloud and SaaS spend
- Business context (features, teams, customers)
CloudZero provides this type of AI cost intelligence by connecting usage signals directly to financial outcomes.


FinOps In The AI Era: A Critical Recalibration
What 475 executives told us about AI and cloud efficiency.


