A global outage at Amazon Web Services (AWS) did more than knock popular apps offline. It laid bare the cost risks embedded in many cloud architectures — and exposed serious cloud cost visibility gaps that most teams didn’t know they had.
As services fail, the hidden costs of high availability, from redundancy planning to recovery operations, often multiply. For cloud cost leaders, this isn’t an issue of uptime; it’s a visibility and budget-shock issue. It’s a key reminder that architecting for resilience involves difficult trade-offs.
Internet outages are, in short, expensive. The cost of a one-hour outage in the United States alone approaches an estimated half a trillion dollars, and that’s just one part of the global internet pie. Check out our full study into the costs of shutting down the internet at large.
What Happened — And Why It Matters
To AWS’s credit, the situation has been resolved: “The underlying DNS issue has been fully mitigated, and most AWS Service operations are succeeding normally now.”
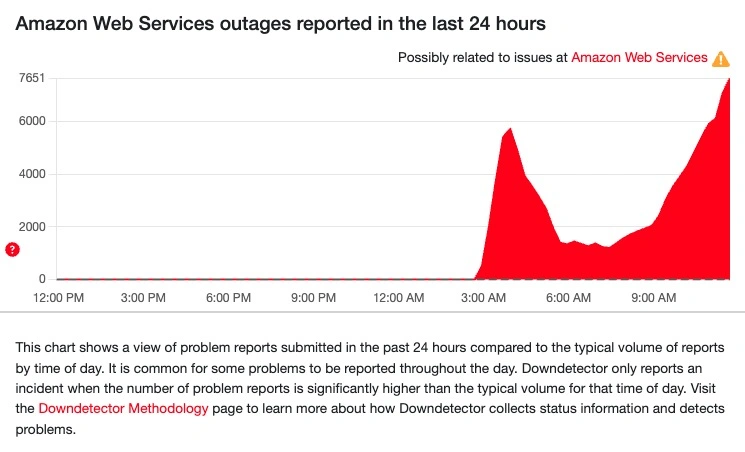
So what happened? Earlier today — Oct. 20, 2025 — AWS flagged elevated error rates and latencies across multiple services in its US-East-1 (Northern Virginia) region.
Platforms impacted included Venmo, Snapchat, Fortnite, Duolingo, airline websites, and multiple government services, with some tracking over 15,000 incident reports during the peak.
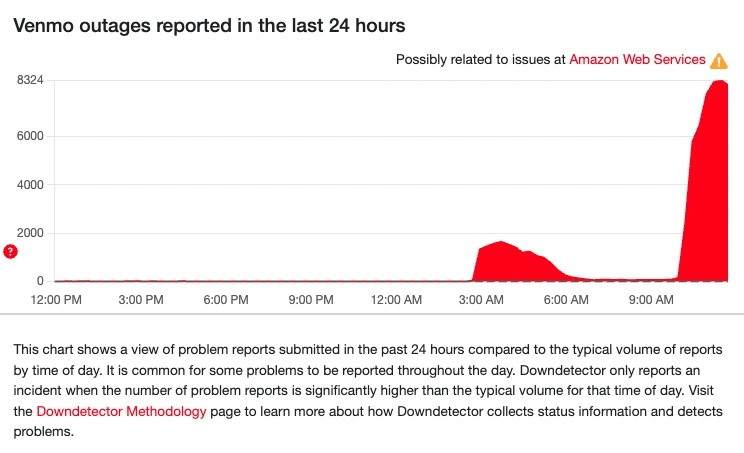
Cumulatively, the numbers are even higher with more than 1,000 companies affected worldwide, according to The Guardian, The publication also highlighted data from Downdetector showing 6.5 million reports of problems including a million in the US alone.
Even as services recover, the operational reality is more complex. Most teams weren’t spinning up additional infrastructure during the outage — simply because they couldn’t. Instead, the true effort comes after: ensuring systems come back online cleanly, debugging issues, restarting dependent services, and validating that what appears online is actually functioning.
These recovery actions, while necessary, can create cost spikes and require deep coordination across engineering, platform, and finance teams.

Research Report
FinOps In The AI Era: A Critical Recalibration
What 475 executives told us about AI and cloud efficiency.
The Cost-Risks You Might Not Be Watching
While the headlines focus on downtime, the financial ripple effects go unnoticed.
As CloudZero’s Director of Cloud Platforms & FinOps Larry Advey says, “Architecting for outages like this one can be challenging, and costly: both before, during, and after an outage. There is a double edged sword here that must be balanced: uptime vs. cost. The more 9s of availability you want, the more it will cost.”
From engineering hours to persistent infrastructure, the path back to full service can quietly inflate cloud spend. Here’s where to look for the hidden risks.
1. Recovery complexity comes at a price
“Most companies don’t spin up new infrastructure during an outage. They simply cannot. The services are not available to do so but what happens instead after the outage is ensuring systems are online and functioning as expected,” says Larry.
“Systems are designed to continuously run but with something like this, which caused numerous errors at different levels, systems have to be validated as part of the recovery efforts. One system or feature may be working just fine but another may need a reboot or tweaking to come back online fully.”
Architecting for failure means building systems that degrade gracefully and recover reliably. But that recovery isn’t free. Teams often spend hours and sometimes days validating that interdependent systems are fully operational after a major cloud provider disruption.
Even when infrastructure remains up, service-level errors, timeouts, or silent failures can require manual intervention. These post-incident operations come at a cost, both in compute resources and team hours.
2. Resilience isn’t free — and must be accountable
The more availability you want, the more you pay. Some of it is upfront, but some also comes during and after recovery. Building for five-nines (99.999%) uptime means investing in duplicated infrastructure, robust failover testing, and failback plans.
But in the heat of recovery, it’s easy to lose sight of which resources are actively needed and which were provisioned as temporary workarounds. Without strong cost tagging and automated monitoring, many of these assets stick around unnoticed.
3. Visibility and ownership fail under stress
Finance and product leaders want postmortems, but many organizations lack real-time cost instrumentation or granular cost allocation. As Business Insider reported, the outage highlighted how interconnected today’s online infrastructure is — and why managing recovery effectively requires both robust systems and coordinated human oversight.
If your cost model can’t attribute recovery activities accurately, such as reboots, failbacks, and service validations, you’re left scrambling for answers when leadership asks, “What did this cost us, and why?” This is exactly where cloud cost allocation capabilities matter most — if your cost model can’t tag and attribute recovery activity by team or service, you’re blind.
4. Architecture choices come under C-suite scrutiny
When an outage like this happens, tough questions invariably come up: Is a single-cloud strategy still defensible? Are cost-efficiency efforts undermining resilience? What will it cost to avoid a significant outage like this in the future?
The incident reveals the dangers of relying on a small number of cloud providers — showing that strategic decisions about architecture aren’t just about performance, but also about concentration risk and resilience. It highlights just how fragile and far-reaching cloud infrastructure failures can be.
These aren’t just availability concerns. They’re strategic trade-offs. Every additional “nine” of uptime comes with rising cost. That tension between uptime and efficiency must be evaluated explicitly with finance and engineering at the same table.
Resilience Spending Today, Cost Control Tomorrow
Following incidents like this, many organizations will pour time and resources into redundancy and failover projects; urgent efforts to harden systems and reduce risk exposure. But not long after, cost-control efforts will kick in to rein back the scope and spending of those same initiatives.
This reactive rhythm is familiar: resilience investments made under pressure, followed by financial clean-up. While both responses are necessary, the lag between engineering action and cost oversight creates avoidable inefficiencies.
FinOps maturity means connecting the two early — ensuring that resilience is designed with cloud cost optimization in mind from the start, not retroactively.
What You Can Do This Week
As a cloud cost manager, there are quick actions you can take to mitigate damage.
Start by auditing for cloud cost anomalies — not just from new provisioning, but from delayed cleanup or prolonged service recovery. Investigate systems that required manual restarts or ran in degraded mode longer than expected — and use cloud cost anomaly detection to flag unexpected spend before leadership asks.
Then, run a cross-functional recovery review. Which teams had trouble validating services? What was escalated? What was spun up but never turned off? Use that to tighten ownership models and automate where possible.
Next, revisit your resilience strategy. Don’t just look at whether systems stayed up, but also at whether they recovered cleanly and what it cost. Are your failback plans lean and measurable? Is recovery cost factored into your availability target decisions?
Finally, communicate, communicate, communicate. Prepare a FinOps incident brief: what happened, how cost and operations were impacted, and how you’re improving. Use this moment to strengthen coordination between platform, engineering, and finance.
Don’t Let the Outage Become A Budget Catastrophe
An outage at a top cloud provider is more than a technical hiccup. It’s a mirror held up to our operational and financial preparedness. While AWS services are recovering, the questions it raises about system design, cost trade-offs, and cross-functional coordination will linger.
Cloud disruptions like this one create not just technical chaos but financial uncertainty. It’s an important moment to reassess how your teams detect, manage, and learn from cost impacts in real time. It’s also an opportunity to ensure your FinOps practices can stand up to the next unexpected event.


FinOps In The AI Era: A Critical Recalibration
What 475 executives told us about AI and cloud efficiency.






![Amazon RDS Instance Types Explained [Classes, Sizes, Costs, and Tradeoffs]](https://www.cloudzero.com/wp-content/uploads/2026/01/rds-instances.webp)