Quick Answer
Elastic scaling for AI inference automatically adjusts compute resources — GPU instances, inference servers, or containers — based on real-time demand. While elastic scaling prevents bottlenecks, it also changes the economics of every inference served. Three scaling decisions most affect cost per inference: scaling too aggressively (creating idle GPU waste), scaling too slowly (increasing latency and risking lost revenue), and scaling thrash (creating volatile infrastructure costs from frequent scale-up and scale-down cycles). Managing AI inference costs requires connecting scaling behavior to unit economics — cost per inference, cost per customer, cost per workflow — not just infrastructure metrics.
Many teams think of elastic scaling as a technical safeguard for AI inference workloads. When demand rises, infrastructure scales up. When demand falls, resources scale back. That responsiveness prevents bottlenecks without requiring permanent overprovisioning.
But elastic scaling also has a financial side effect that many teams overlook: it changes the economics of every inference you serve. At CloudZero, we call this AI Scaling Economics — the relationship between scaling behavior, utilization, and cost per inference.
A workload that scales successfully is not always a workload that scales efficiently.
What Is Elastic Scaling For AI Inference?
Elastic scaling for AI inference refers to automatically adjusting compute resources, such as GPU instances, inference servers, or containers, based on the real-time demand your models generate. At CloudZero, we define elastic scaling not only in terms of infrastructure activities, but also in terms of how your cloud and AI costs scale over time as capacity changes.
See, scaling AI inference is not like scaling a typical stateless web app. Scaling AI inference is not like scaling a typical stateless web app.
Inference workloads depend on expensive GPU-backed infrastructure, model-serving layers, and memory-heavy environments that do not scale cleanly or cheaply. Every scale-up event introduces added cost. Every scale-down decision affects latency, availability, or reuse efficiency. And every mismatch between demand and capacity distorts cost per inference.
According to CloudZero’s latest FinOps in the AI Era report, those scaling behaviors have seen 40% of companies now spend more than $10 million a year on AI.
More importantly for this topic, the CloudZero analysis revealed that mean Cloud Efficiency Rate (CER) has plummeted to 65% from 80% year-to-year across all segments. And for 1 in 5 organizations, their AI spend projections were off by 50% or more.
In contrast, data from Epoch shows that AI prices per token have reduced significantly.
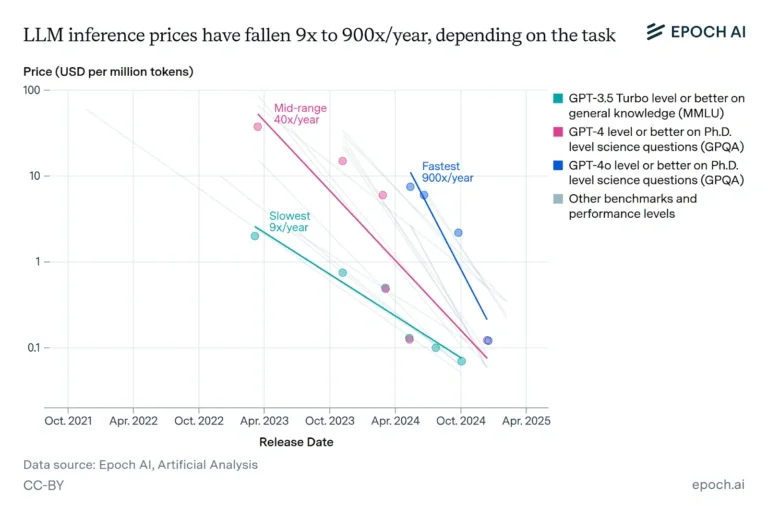
So, as we mentioned earlier, your AI stack can scale successfully but not efficiently (despite reducing token pricing).
That is why at CloudZero, we define inference economics as the discipline of understanding, attributing, and optimizing the ongoing cost of running AI in production.
This involves applying unit cost logic to AI workloads by defining a unit of AI work, attributing the full cost of delivering it, and tracking whether that cost is moving in the right direction as your usage grows.
Helpful Resource: What Is Cloud Unit Economics (And Why Should You Care Now)
In that context, elastic scaling matters because it directly affects the cost and efficiency of serving each inference. Because the last thing you really want is to improve your infrastructure’s responsiveness, only to be marred by margin killers like higher idle capacity.
That said, even well-intentioned scaling policies can change your AI unit economics in ways that are easy to miss at first. So, let’s start with one of the most common and costly examples.
Report
Finance needs to prove AI’s return: CloudZero report
260 senior finance leaders (more than half CFOs) told us why the speed of seeing AI spend, not the size of it, separates who pulls ahead on AI from who gets burned.
1. Scaling Too Aggressively Creates Idle GPU Waste
When autoscaling policies spin up capacity faster than sustained demand actually requires, those resources can sit partially utilized.
Microsoft’s own empirical study on deep learning jobs found low utilization from data operations (46%) and model issues (45%). The findings also show that the issue worsens during autoscaling interruptions caused by non-GPU tasks.
Anyscale’s January 2026 analysis shows production AI workloads averaging under 50% sustained GPU utilization, even under load. The reason is due to CPU-centric architectures that fail to match AI’s bursty patterns during scaling.
Picture this:
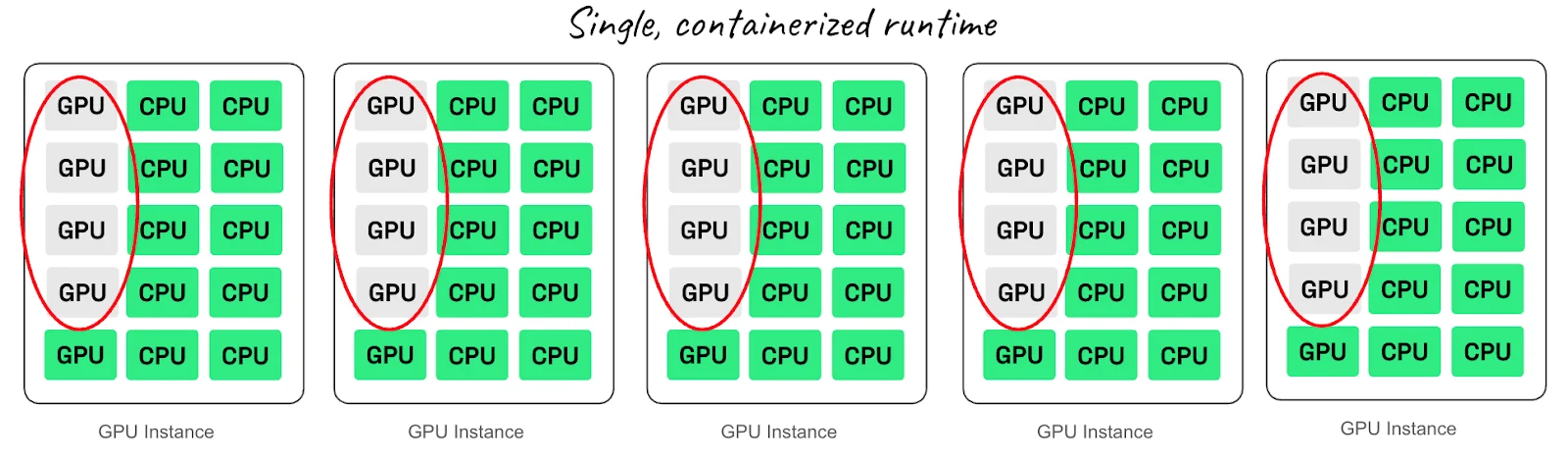
That also shows in other types of workloads, such as AI video processing workloads.
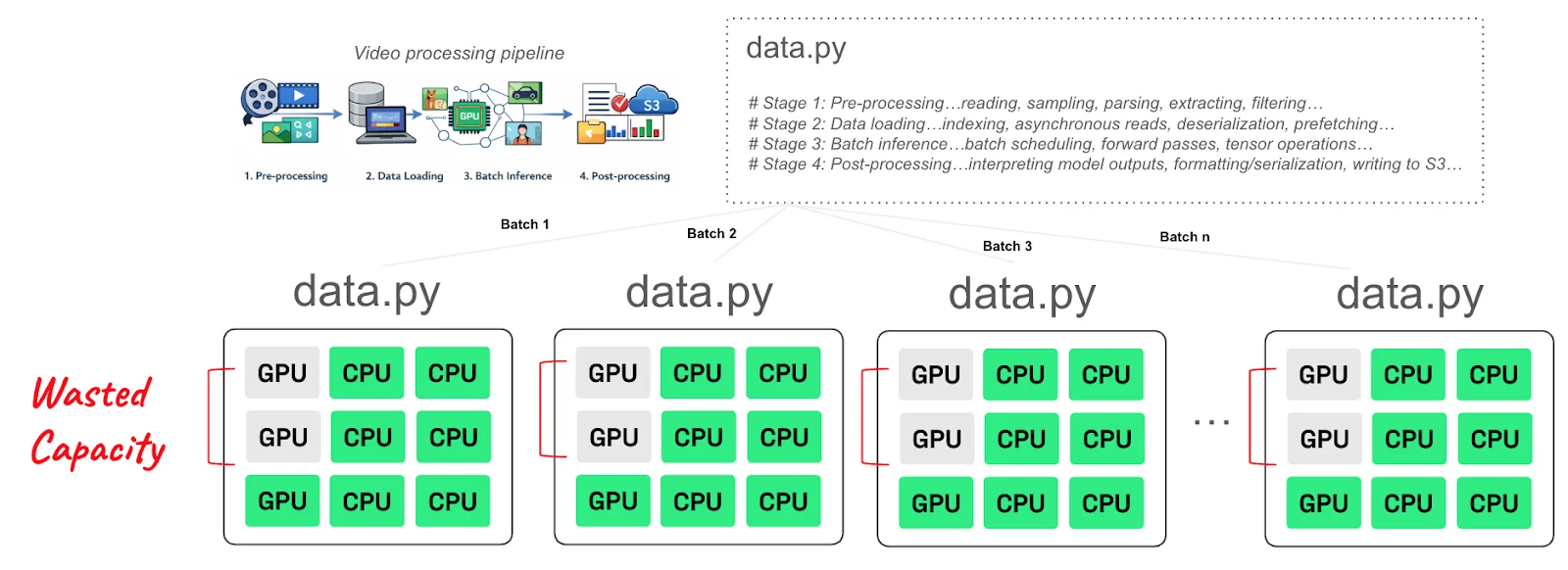
Image: AI (in)efficiency report by Anyscale
When scaling adds capacity that demand does not fully absorb, the numerator — cost — grows faster than the denominator — inference volume. Even half-used GPU capacity distorts AI unit economics when it persists across repeated scale-out events.
Utilization matters, but on its own it does not tell you whether scaling behavior is improving the economics of the AI feature, customer workflow, or product experience you are trying to support. If your workload remains fast and available while becoming more expensive to operate with every spike, scaling too aggressively is working against you.
2. Scaling Too Slowly Increases Latency And Lost Revenue
Picture this. You keep infrastructure leaner, avoid overprovisioning, and delay adding expensive inference capacity until demand clearly requires it. Seems reasonable.
But that restraint can create a different kind of economic problem.
When inference capacity lags behind demand, latency starts to rise. Requests queue longer. Response times slow down. User-facing AI features begin to feel less responsive, less helpful, or less reliable.
In turn, that leads to a poor user experience and low customer satisfaction.
In that context, slow scaling risks weakening the return you get from the inference infrastructure you are already paying for.
This is especially important for AI features tied to conversion, retention, support quality, or product engagement, leaving revenue on the table.
There is something else. Elastic scaling does not need to be too fast or too slow to become expensive. Sometimes the real problem is how often the workload scales, and how much churn that repeated motion creates.
3. Scaling Thrash Creates Volatile AI Infrastructure Costs
Scaling thrash happens when autoscaling policies trigger frequent, alternating scale-ups and scale-downs — creating overhead in the form of node churn, container pulls, model reloads, and cold starts with each cycle.
The cost may come from the repeated cost of reloading, reallocating, and rewarming infrastructure that never stays stable long enough to operate efficiently.
Once scaling behavior turns erratic, AI infrastructure costs become harder to explain, forecast, and control. And that creates a serious visibility gap for both engineering and finance.
That’s how 1 in 5 organizations in the CloudZero report found their AI cost expectations were 50% off.
Even so, idle waste, latency, and cost volatility all point to a deeper issue. Many teams still judge scaling success using infrastructure metrics alone. But the more important question is whether that scaling behavior is improving cost per inference, cost per customer, cost per workflow, and other unit economics that actually shape profitability.
CloudZero analysis shows that 43% track AI and related costs by customer, and only 22% track them by transaction. That leaves many teams pricing AI offerings with more guesswork than precision.
And it is not hard to see why.
AI cost reporting is messy by default. Plus, most companies now spread AI workloads across public cloud, private cloud, third-party GPU providers, and hosted LLM APIs.
Moreover, each provider comes with its own billing model, reporting cadence, and data format.
That makes it incredibly hard to build a single, reliable picture of AI spend, much less understand what those costs are actually supporting.
That is also exactly why you’ll not want to evaluate elastic scaling in isolation. Instead, you’ll want your team to connect scaling behavior to clear unit cost signals.
The alternative is to leave them seeing infrastructure activity and making technical decisions without fully understanding those decisions’ impact on your economics, competitiveness, and, ultimately, profitability.
Get the Cost Intelligence to Connect Scaling Decisions to Profitability — In Real Time
Elastic scaling is supposed to help your AI inference workloads stay responsive as demand changes.
But as we’ve seen, scaling behavior also changes the economics behind every inference you serve.
That is why profitable AI growth depends on more than elastic infrastructure. It also depends on being able to see how scaling behavior affects utilization, cost per inference, and the business value of the features you are scaling.
CloudZero helps teams do exactly that.
Instead of leaving engineering, FinOps, and finance teams to piece together fragmented billing data from cloud providers, GPU vendors, and hosted AI platforms, CloudZero connects your cloud and AI spend to the business dimensions that matter most, such as cost per customer, cost per feature, cost per workflow, and cost per inference.
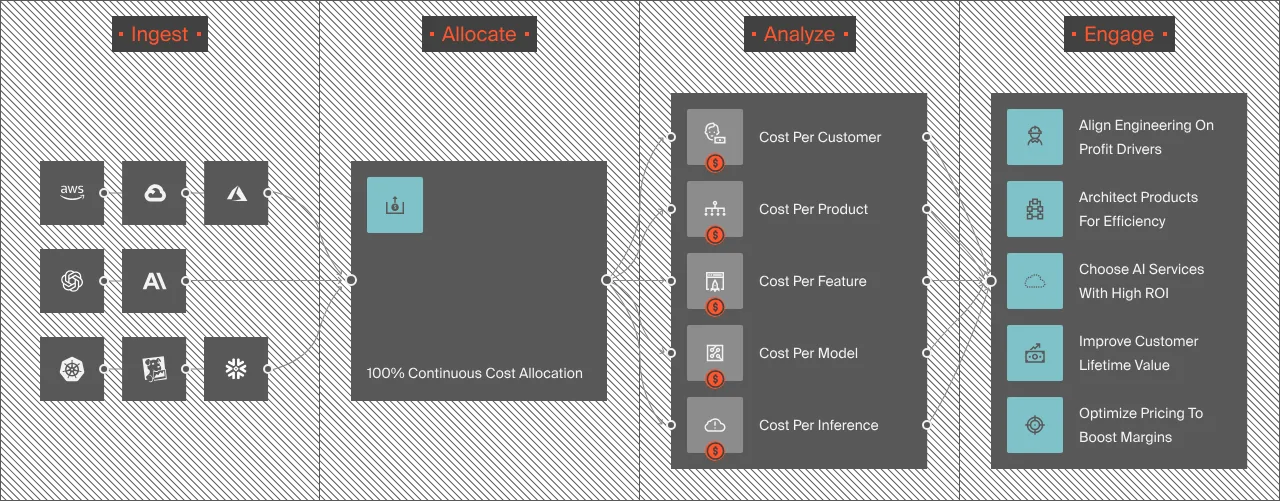
This AI unit economics approach helps your team connect AI costs to business outcomes in ways they can immediately understand and act on.

With that level of visibility, you can catch idle GPU waste earlier, understand when latency is becoming a business risk, spot cost volatility before it becomes the norm, and make scaling decisions with clearer economic context. And you can see exactly how this works right now, risk-free.
And, with the new and improved Claude Code Plugin, the workflow now looks something like this: ask Claude Code what changed and why, get an answer that spans services, teams, environments, pipelines, ticket systems, and custom dimensions, see who’s accountable, understand whether the spend was justified, and decide on next steps — all in one conversation, without leaving the terminal.
Frequently Asked Questions About Elastic Scaling For AI Inference
What is elastic scaling for AI inference?
Elastic scaling for AI inference is the automatic adjustment of compute resources — GPU instances, inference servers, or containers — based on real-time demand. When demand rises, infrastructure scales up to maintain performance. When demand falls, resources scale back to reduce cost. The challenge is that scaling behavior directly affects cost per inference, not just availability and latency.
What is cost per inference?
Cost per inference is a unit economics metric that measures the total cost of delivering a single AI model response. It includes GPU compute, model-serving overhead, memory, data transfer, and supporting infrastructure. Tracking cost per inference — rather than total cloud spend — reveals whether AI infrastructure is scaling efficiently as usage grows. Learn more about inference costs.
What is scaling thrash in AI inference?
Scaling thrash occurs when autoscaling policies trigger frequent, alternating scale-up and scale-down cycles. Each cycle introduces overhead through node churn, container pulls, model reloads, and cold starts. The cumulative cost of that overhead can make AI infrastructure costs volatile and difficult to forecast, even when total utilization appears reasonable.
Why does idle GPU waste happen during elastic scaling?
Idle GPU waste occurs when autoscaling policies spin up capacity faster than sustained demand actually requires. GPU instances that are partially utilized still generate full compute costs. Production AI workloads average under 50% sustained GPU utilization even under load, according to Anyscale’s 2026 analysis — meaning aggressive scale-out policies frequently create paid-for capacity that demand never fully absorbs.
How do you connect elastic scaling decisions to AI unit economics?
Connecting scaling decisions to AI unit economics requires attributing infrastructure costs to the business dimensions they support — cost per customer, cost per feature, cost per workflow, cost per inference. Most cloud billing tools show cost by service or account, not by the AI workload or product feature generating it. Platforms like CloudZero map GPU spend, inference costs, and model-serving overhead to the teams and products consuming them.
 to see how leaders like Toyota, Duolingo, Grammarly, and Coinbase are using CloudZero to turn AI scaling behavior into clearer unit economics, better forecasting, and more profitable growth.
to see how leaders like Toyota, Duolingo, Grammarly, and Coinbase are using CloudZero to turn AI scaling behavior into clearer unit economics, better forecasting, and more profitable growth.











