“It started as an experiment.”
That’s how it begins at most companies. A small team spins up a few GPU instances to train a proof-of-concept model. Maybe it’s a fraud detection algorithm. Maybe it’s GenAI for support tickets.
Either way, it’s just a test. Then the results come in, and they’re promising.
Suddenly, that model is powering new features. Teams are fine-tuning LLMs in parallel. Product, engineering, and data science teams are all pulling from the same budget, experimenting with different AI services, frameworks, and models. And before long, leadership asks the question no one wants to answer:
“How much is all this AI costing us?” The silence that follows says it all.
That silence isn’t unique. A global report published in Sept. 2025 found that 94% of IT leaders are still struggling to optimize their cloud costs. Commissioned by Crayon, the data shows just how urgent the FinOps conversation has become especially for teams navigating AI scale.
This is why FinOps for AI is so crucial now.
In this guide, we’ll explore how teams at every maturity level, from early experimentation to scaled AI production, can apply FinOps principles to gain control of their AI costs. We’ll use the “crawl, walk, run” model to show what practical FinOps for AI looks like at each stage.
What Is FinOps For AI?
FinOps for AI is the application of FinOps principles to the financial management of AI workloads — including model training, inference, GPU usage, and token-based consumption — to deliver cost transparency, accountability, optimization, and measurable business value at AI scale.
Unlike traditional cloud workloads, AI systems introduce highly variable, usage-driven cost models that require deeper visibility and more dynamic financial controls. FinOps for AI extends standard FinOps practices to help organizations understand where AI spend comes from, who owns it, and how it maps to business outcomes. This guide focuses on the FinOps methodology for AI — the governance model, maturity stages, and organizational practices. For the broader discipline of AI cost management — covering visibility, allocation, and optimization — start there.
At CloudZero, we define FinOps for AI as a financial management discipline designed to bring visibility, accountability, and control to AI workloads as they scale.
Report
Finance needs to prove AI’s return: CloudZero report
260 senior finance leaders (more than half CFOs) told us why the speed of seeing AI spend, not the size of it, separates who pulls ahead on AI from who gets burned.
Why Traditional FinOps Falls Short For AI Workloads
Traditional FinOps practices were designed for relatively predictable cloud infrastructure costs such as compute, storage, and networking. AI workloads fundamentally change that cost model.
AI spending is driven by highly variable, usage-based factors including GPU-intensive training jobs, fluctuating inference demand, and token-based pricing. Small changes in model configuration, prompt design, or user behavior can result in disproportionate cost swings that are difficult to forecast or control with traditional FinOps approaches.
AI development also accelerates experimentation. Teams rapidly iterate on models and architectures, often consuming expensive resources faster than standard allocation, budgeting, and governance processes can adapt. As a result, organizations relying on conventional FinOps practices often experience delayed visibility, imprecise cost attribution, and reactive cost controls.
FinOps for AI addresses these gaps by extending FinOps principles to manage the volatility, scale, and economic complexity of modern AI workloads.
What Drives AI Costs?
AI costs are driven by a distinct set of consumption patterns that differ from traditional cloud workloads.
First, model training often requires short bursts of highly expensive GPU or TPU resources, particularly for large or frequently retrained models. Second, inference workloads generate ongoing, variable costs that scale with user demand and request volume.
Many AI platforms also rely on token-based pricing, where costs are tied directly to prompt length, response size, and usage frequency. In addition, organizations increasingly depend on AI platforms, APIs, and SaaS tools, each with its own pricing model and billing granularity.
Finally, underutilized or idle accelerators can silently inflate costs when GPU capacity is provisioned but not fully consumed. FinOps for AI focuses on making these cost drivers visible, attributable, and measurable so teams can optimize AI spend without slowing innovation.
How FinOps For AI Helps Connect Spend To Business Outcomes
FinOps for AI is not about minimizing AI costs in isolation. It is about building the financial visibility needed to begin connecting AI spend to business outcomes, even as AI unit economics continue to evolve.
Unlike traditional software, many AI initiatives lack stable cost models or well-defined return metrics. Training costs can be episodic, inference demand can shift rapidly, and the relationship between model performance and business value is often nonlinear. FinOps for AI helps teams navigate this uncertainty by improving attribution and context — such as understanding AI spend by model, workload, or use case.
Over time, this visibility enables more informed tradeoffs between performance, latency, accuracy, and cost. Rather than assuming precise ROI, organizations can identify which AI investments appear promising, which are experimental, and which are becoming unsustainable as usage grows.
FinOps for AI creates the foundation for responsible AI scaling, aligning financial awareness with engineering, product, and business decision-making — even before outcomes are fully predictable.
What Does FinOps For AI Enable?
FinOps for AI enables organizations to bring structure and financial visibility to AI initiatives that are still evolving.
At a foundational level, it helps teams gain clearer insight into where AI spend comes from, how it changes over time, and which models, workloads, or services are driving the most cost. It supports more accurate attribution of AI costs to teams and use cases, even when usage patterns are dynamic or experimental.
FinOps for AI also enables earlier detection of cost anomalies, such as unexpected inference spikes or underutilized GPU capacity, before they become systemic issues. Rather than enforcing rigid controls, it provides guardrails that help teams experiment responsibly while maintaining financial awareness.
As AI systems mature, these capabilities create the groundwork for more advanced forecasting, optimization, and value measurement — without requiring organizations to solve AI unit economics upfront.
CloudZero approaches FinOps for AI by focusing first on visibility and attribution, recognizing that optimization and value measurement follow only after AI costs are understood. For the full three-layer framework, see CloudZero’s guide to AI cost management.
How AI Is Managed Compared To Other Cloud-Based Workloads
If you’ve managed cloud infrastructure for applications, web services, or data platforms, you probably have a good grasp on how to budget, monitor, and optimize those resources. But AI workloads, especially those involving model training or generative inference, operate under a very different set of rules.
To apply FinOps with confidence, it’s crucial to understand where the differences lie.
Similarities AI workloads share with traditional cloud resources
At a surface level, AI workloads behave like other cloud-based resources:
- They rely on compute, storage, and networking,
- They scale up or down, often dynamically,
- They can be tagged, monitored, and cost-allocated,
- And they need optimization to prevent overspend.
That’s where the overlap ends.
The differences that make AI cloud spend so challenging
Here’s where AI workloads diverge, and why they often blow past expectations if left unmanaged:
1. High-intensity, risky resource usage
AI infrastructure relies on premium compute resources like GPUs, TPUs, and accelerated instances. These cost significantly more per hour than general-purpose VMs, and they’re often run for hours or days at a time during training.
And that adds up. Fast. CloudZero’s State of AI Costs report found that average monthly AI spend hit $62,964 in 2024, with projections showing it will rise to $85,521 in 2025. That’s a staggering 36% year-over-year jump.
Yet, just 51% of teams feel confident in their ability to measure AI ROI.
As CloudZero CEO Phil Pergola puts it:
“The dirty little secret about AI is that while its potential returns are vast, without the right management, many investments turn into expensive mistakes rather than profitable innovations.”
This is where AI becomes dangerous, not because the tech doesn’t work, but because the cost-to-value equation goes unchecked. And without clear visibility, teams have no way to distinguish between the promising breakthroughs and the silent budget drains.
2. Bursty, unpredictable usage patterns
Unlike web apps with steady traffic or batch jobs on a schedule, AI workload costs spike irregularly.
- Model training may take place in short, expensive bursts.
- Teams may rerun experiments with slight variations.
- Data processing for ML pipelines can expand unexpectedly.
This makes forecasting AI spend almost impossible without fine-grained visibility.
3. Blurred lines between R&D and production
In traditional environments, it’s easy to separate dev from prod. In AI, that boundary is fuzzy. Research models may quietly become production features. Model iterations might use shared infrastructure. AI/ML engineers often manage both development and deployment environments.
Without clear tagging or segmentation, your production costs could be carrying the weight of failed experiments.
4. Multi-team involvement
AI workloads cut across silos. These involve ML/AI engineers, data scientists, DevOps and platform teams, as well as finance and product owners. Each team may spin up its own infrastructure or tooling. So, without strong coordination, this becomes a visibility nightmare.
5. Difficulty tying spend to business value
Most organizations track cost-per-user or cost-per-feature in app workloads. With AI, equivalent metrics, like cost-per-inference or cost-per-training iteration, are rarely tracked.
Yet without this connection, there’s no way to know whether your most expensive models are worth the spend.
Clearly, AI workloads behave differently. And without adapting your FinOps practices to these behaviors, AI costs can continue to feel like the next moon landing: extensive, expensive, and hard to explain.
Next, we’ll look at why these differences make a FinOps approach essential for managing AI in the cloud.
Why AI Demands A FinOps Approach
Most engineering teams already know the basics of cloud cost optimization: rightsize your instances, shut down idle resources, and tag what you deploy.
But AI workloads are bigger, more bursty, and harder to pin down. That’s why AI demands FinOps.
FinOps brings together engineering, finance, and product teams to collaborate on cloud spending decisions. It’s not about restricting innovation, though. It’s about ensuring every dollar you invest in the cloud creates real, measurable business value.
Related read: How To Align Engineering and Product Teams For Cloud Cost Optimization
Unpredictable costs, unpredictable returns
You might run a six-hour training job that costs $3,000, only to discover the model underperforms. Or, you may leave an inference endpoint running on a high-end GPU because no one knew it was still active.
Without tight feedback loops between usage and cost, this kind of waste becomes normal.
In the State of FinOps 2025 report:
- AI-related cloud spend is growing rapidly. About 63% of organizations now actively manage AI spending, up from just 31% last year.
- While 92% plan to increase their AI investment, only 63% are committing to proactively managing those costs.
- Meanwhile, only 51% of teams feel confident in their ability to measure AI ROI. This highlights a disconnect between spending and visibility.
That last stat may be the one keeping you up at night.
AI cost doesn’t equal business value (unless you measure it)
With AI, spend can escalate quickly and silently. That’s because:
- Experimentation is encouraged, but often untracked.
- Successful pilots lead to production usage without cost checks.
- Teams rarely track unit economics like cost per model version, per prediction, or per feature.
So while your cloud bill grows, it’s not always clear what you’re getting in return.
FinOps provides the structure to fix this:
- Teams tag AI workloads by experiment, owner, or use case.
- You can break down costs by function, feature, individual customer, and other granular, immediately actionable cost insights.
- You review spend regularly with both engineers and finance.
This makes it possible to ask (and answer) key questions like:
- “Is this model still worth running?”
- “Are we paying $0.50 or $0.05 per prediction?”
- “Which team owns this $20K/month inference cluster?”
There is something else.
AI is moving too fast for manual cost management
New GPU types. Evolving cloud pricing models. Emerging managed services for vector search, retraining, or RLHF. If your cost management process depends on spreadsheets, quarterly reviews, or basic billing dashboards, you’re already behind.
Applying FinOps for AI best practices pushes you to build real-time visibility, governance, and dynamic accountability into your workflows.
Think of:
- Alerts when training jobs exceed budgets.
- Dashboards showing AI cost per product feature.
- Automation that pauses idle model endpoints or flags runaway training jobs.
These are table stakes for operating AI at scale. And more teams are appreciating this fact and prioritizing it. Consider this:
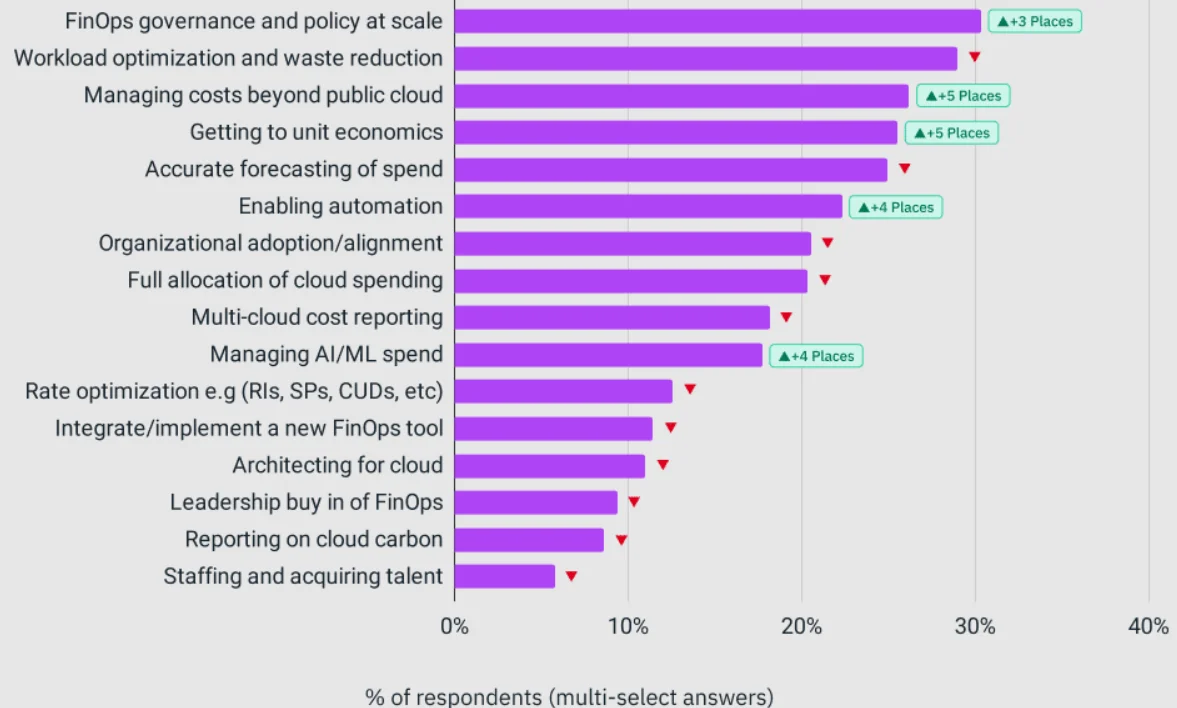
Image: State of FinOps – FinOps Foundation
Ultimately, AI changes the cost equation. FinOps changes the way you solve it. So, how do you apply the FinOps maturity model (crawl, walk, run) specifically to AI workloads?
How To Apply A FinOps Framework To AI
Think of your AI cost maturity like your model maturity: it starts rough, then it becomes refined. At first, you’re just trying to make the thing work. Then you’re working to make it efficient. Eventually, you want it to drive meaningful outcomes.
That’s what FinOps for AI is about. And like any good model training process, it happens in stages.
The Crawl: Make it visible
Most AI teams start here. The models are running, the GPUs are humming, and the bills are coming in. But nobody knows where the costs are going.
At this stage, your goal is cost awareness. Cost visibility.
Here’s what crawling looks like:
- Start tagging your AI infrastructure. Training environments. Inference clusters. Data pipelines. Tag anything AI-related, from function to team, project, etc. If it’s using a GPU, tag it.
- Separate experimental from production. You don’t want a failed model experiment to hide in your prod billing line. Set up naming conventions or folders to separate R&D from production environments.
- Track the big stuff manually if necessary. Even a spreadsheet with GPU job IDs, timestamps, and owners is better than nothing. But ideally, you start using cost observability tools (like CloudZero) to track spend by resource and team.
Crawl Stage Milestone: “We know what AI workloads we’re running and who owns them.”
The Walk: Make teams accountable (without killing momentum or morale)
Once you have visibility, the next step is to inject accountability into your AI pipeline without slowing things down.
Here’s what that might look like:
- Assign budgets (not blocks). Instead of saying “no,” say, “here’s what this workload should cost.” Let engineers build within cost boundaries rather than chase optimization post-mortem.
- Start measuring cost-performance tradeoffs. Is training for 72 hours worth a marginal bump in model accuracy? You won’t know unless someone looks at both metrics side by side.
- Introduce regular cost reviews. These aren’t finance-only meetings. Get product owners, engineers, and AI leads involved. Show cost-per-model or cost-per-use-case, not just totals. Like this:
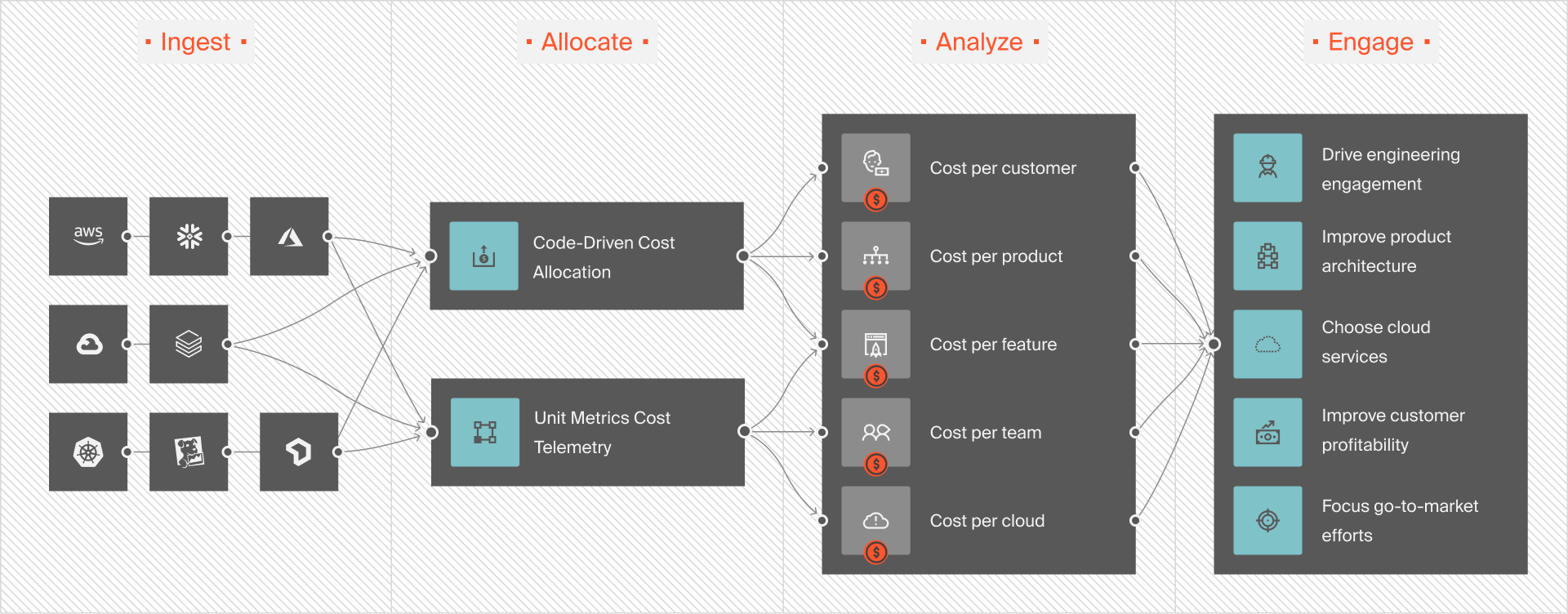
- Promote a culture of “cost-aware experimentation.” You want your engineers to be well aware of what they’re spending when they hit “run.” That starts with cost data being accessible and digestible, not buried in a billing dashboard.
Walk Stage Milestone: “We know what we’re spending, why we’re spending it, and how to course-correct.”
Also see:
The Run: Align AI costs with customer value
At this point, you want to not only watch the spend, but also direct it.
This is where your AI investments begin to drive measurable business value. It’s also where FinOps implementation is part of your engineering DNA.
Here’s what “running” may look like:
- You track unit economics for AI workloads.
- What’s the cost per successful model?
- What’s the cost per 1,000 inferences?
- What’s the cost per customer using your AI feature?
- You automate waste elimination. Idle GPUs are shut down. Redundant training jobs are flagged. Inference clusters auto-scale based on real usage. It’s baked into the pipeline.
- You link AI costs to outcomes. At CloudZero, we call this the “next leap” in FinOps maturity. It’s about being able to tie AI infrastructure costs directly to product lines, user behavior, or revenue. That’s how you justify further investment.
- You forecast with confidence. With historical data and real-time visibility, you can finally answer leadership’s favorite question: “What will this cost if we scale it?”
Run Stage Milestone: “We treat AI like a product, and costs are part of its lifecycle.”
Does that all feel like a little too much? The good thing is that nobody gets there overnight. The crawl-walk-run model gives your team a roadmap and step-by-step clarity to achieve FinOps maturity and mastery.
The Next Step: Like Other Cloud Resources, Visibility Is Critical To Optimizing AI Costs
A year ago, a startup spun up its first GenAI pilot. It worked. Customers loved it. So they scaled.
Fast-forward to today, and they’re spending tens of thousands each month on GPUs, storage, and model endpoints. Yet when finance asks, “What’s this $17K charge from last week?” the answer is a shrug.
Sound familiar?
They didn’t do anything wrong. Like many teams, they moved fast. But they moved without the guardrails that keep AI innovation from becoming an uncontrolled expense.
What changed?
They adopted FinOps, tailored for AI.
- They tagged every AI job, model, and cluster.
- They reviewed costs on a biweekly basis, not quarterly.
- They linked spend to features and customers.
- And they used CloudZero to break everything down, from cost per training run to cost per feature in production.
Now, when the leadership at Helm.ai, Rapid7, or Upstart asks, “Is our AI investment working?”, they have an answer backed by real data. So do the teams at Moody’s, Grammarly, and Skyscanner, who all prefer CloudZero’s approach. And we just helped Upstart save $20 million.
FinOps for AI, Summarized
- FinOps for AI applies FinOps principles to the unique cost models of AI workloads.
- AI introduces volatile, usage-based costs driven by training, inference, tokens, and accelerators.
- Traditional FinOps practices often lack the visibility and attribution needed for AI systems.
- FinOps for AI focuses on building financial awareness and guardrails before precise unit economics are established.
- This foundation enables organizations to scale AI responsibly as usage, complexity, and spend increase.
You didn’t get into AI to babysit GPU bills. If you’re ready to turn your AI costs into a competitive edge (not just another line item), we’re ready to help you.  to give your AI strategy the financial visibility it deserves.
to give your AI strategy the financial visibility it deserves.











