
If your team is experimenting with Google’s latest Gemini models, you’ve probably noticed the pricing can get murky. And like any cloud service, usage-based billing means those features can quickly rack up your SaaS costs.
Free tiers fade fast. Token usage gets fuzzy. And before long, your GenAI bill feels more like a guessing game than a budget line item.
In this post, we’ll break down exactly how Gemini AI pricing works today, including the real costs, the factors that drive them, and proven ways to save.
We’ll also share a proven platform to help you rein in AI spend with real-time visibility, precise attribution, and cost-per-feature insights. Heck, you’ll have the power to link Gemini AI costs directly to product features, customers, and business outcomes. Meaning, you can maximize AI’s impact without sacrificing profitability.
Let’s dive in.
What Is Google Gemini?

Gemini is Google DeepMind’s family of next-generation multimodal AI models. It handles text, code, images, audio, and video within the same architecture.
Gemini 1.0 launch in December 2023. It featured model tiers like Ultra, Pro, Flash, and Nano. These were designed to rival ChatGPT’s GPT‑4. Gemini 1.5 quickly followed, improving reliability and performance. And by mid-2025, Google was already retiring 1.5 models.
Enter the Gemini 2.0 Series. This family introduces flexible reasoning, multimodal comprehension, and scalable performance.
Consider these:
- Gemini 2.0 Flash is a faster, multimodal workhorse that outperformed 1.5 Pro on key benchmarks. It offers natively generated images, audio, and video outputs.
- Gemini 2.0 Flash‑Lite is designed to be budget-friendly. It delivers better quality than 1.5 Flash, with similar speed and cost, so it is ideal for high-throughput SaaS.
- Gemini 2.0 Pro (Experimental): This model supports huge context windows (up to 2 million tokens) and advanced tool use like code execution and search. Consider it for complex, reasoning-heavy production scenarios.
Then the Gemini 2.5 Series (stable as of mid-2025) rolled out:
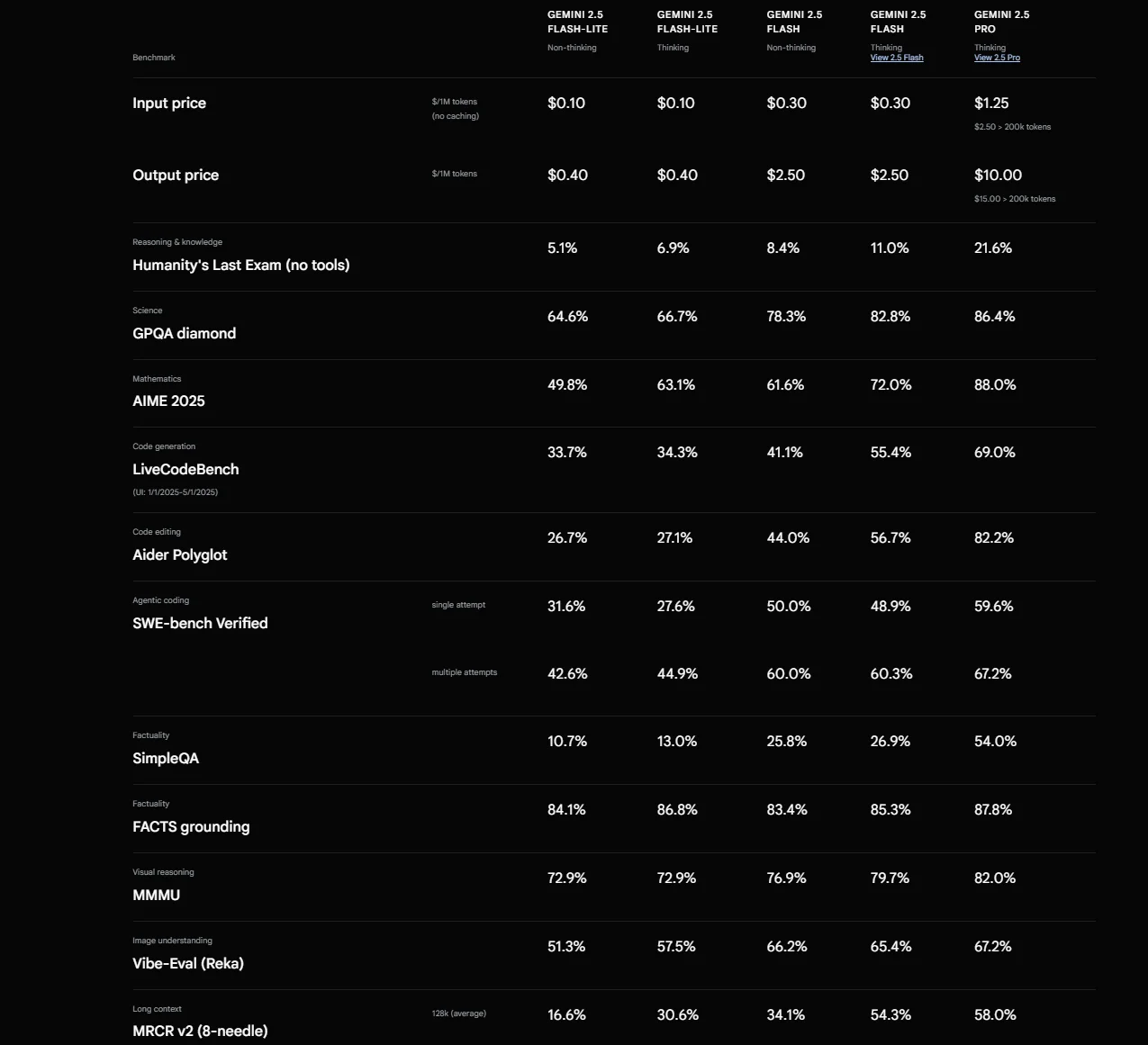
- 2.5 Flash is cost-effective with “thinking” enabled by default, balancing speed and reasoning for everyday enterprise use.
- 2.5 Flash‑Lite is the most economical option in the 2.5 lineup, and is built for high-volume, low-latency tasks.
- 2.5 Pro is the highest-performing “thinking” model. It is optimized for coding, reasoning, and long-context tasks (a.k.a. high-stakes SaaS).
- 2.5 Deep Think is the ultimate reasoning engine, now rolling out to Google AI Ultra users. Think is built to solve demanding challenges like advanced coding and math strategies.
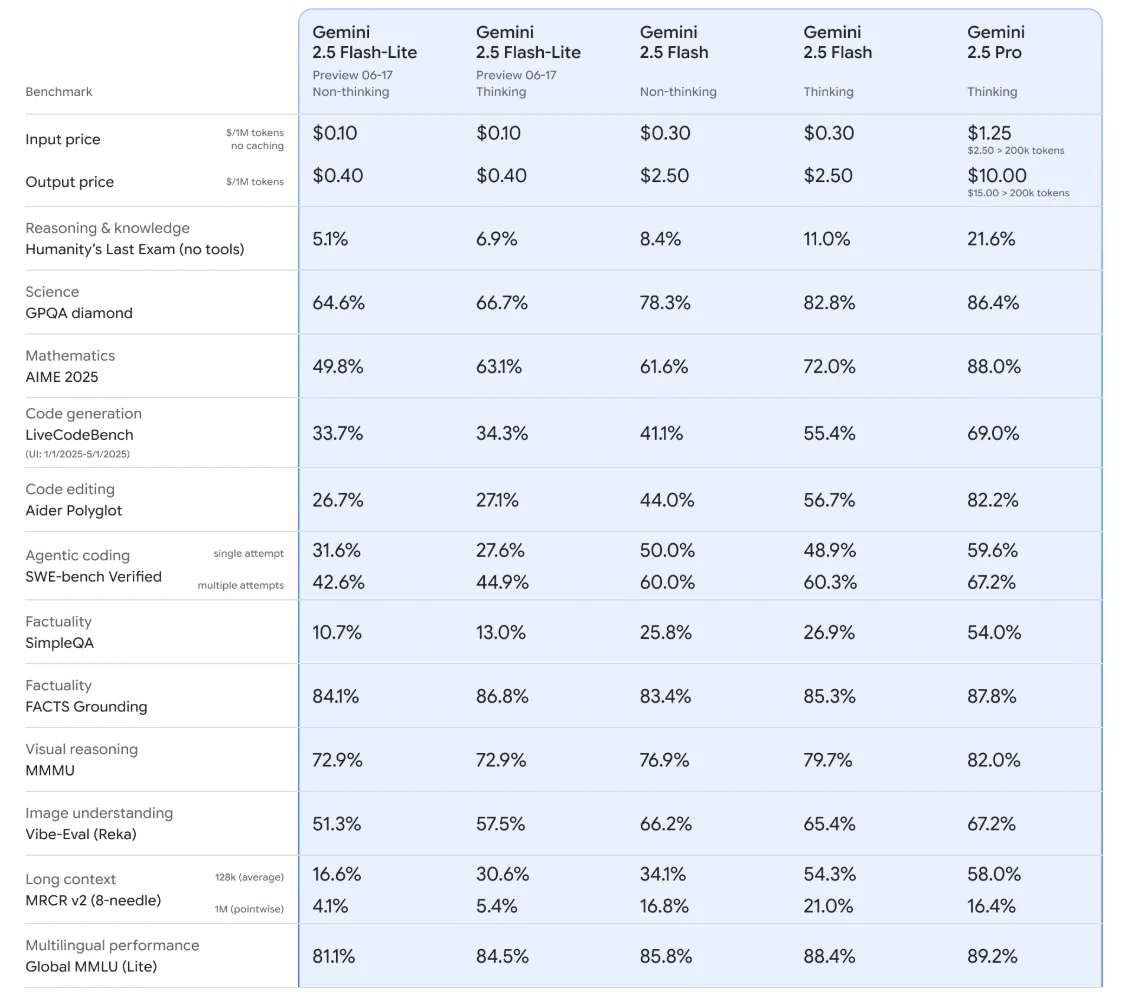
Image: Gemini 2.5 Flash model benchmarks
This tiered structure lets teams choose models that align with their workloads. Think: Flash for real-time agents, Pro for developer tools and analytics, and Deep Think for innovation-heavy tasks where accuracy is critical.
Each model tier comes with its own cost dynamics, from token usage and “thinking budgets” to inference latency and throughput-volume tradeoffs.
This means knowing which Gemini variant best aligns with your workload directly impacts your bottom line.
playbook
The AI Cost Optimization Playbook
Traditional cloud cost management is broken. Here’s why — and how to make the switch to cloud cost intelligence.
Gemini Pricing Overview
First, a quick overview of Gemini AI pricing.
AI Model | Pricing Details | Notes |
Gemini 2.5 Pro (API) | ≤200K tokens — Input: $1.25/M tokens, Output: $10/M tokens. >200K tokens — Input: $2.50/M, Output: $15/M. Context caching: $0.31–$0.625/M tokens + storage ($4.50/M tokens/hr). Batch mode ~50% discount. | Includes “thinking tokens” in output cost. Best for complex reasoning, coding, and long-context workloads. |
Gemini 1.5 Pro (API) | ≤128K tokens — Input: $1.25/M, Output: $5/M. >128K tokens — Input: $2.50/M, Output: $10/M. | Retired mid-2025 but still available in some regions. Free tier in Gemini Studio for exploration. |
Gemini 2.5 Flash-Lite (API) | Input: $0.10 (text/image/video) or $0.30 (audio) per M tokens, Output: $0.40/M tokens. | Cheapest tier. Built for high-throughput, low-latency, cost-sensitive workloads. |
Vertex AI (Cloud Console) | Mirrors API rates for Pro/Flash/Flash-Lite. Batch mode ~50% discount. | Adds charges for tuning, deployment, and pipelines. Only HTTP 200 calls are billed. |
Google AI Pro (Google One) | $19.99/user/month. | Bundles Gemini Advanced (2.5 Pro), 2 TB storage, Veo, NotebookLM. Internal productivity use only. |
Google Workspace with Gemini | Business Starter: $8.40/user/month; Standard: $16.80; Plus: $26.40. | AI features are included in the plan price. No per-token billing. |
Gemini Code Assist | Standard: $19/user/month (annual), Enterprise: $45/user/month (annual). | Per-seat developer tool for code and cloud workflows, not token-metered. |
Table: Overview of pricing for Gemini AI products and services.
As a precision-based cloud cost optimization platform, we emphasize truly understanding what you’re paying for, and why.
That’s how you uncover which people, products, and processes are affecting your margins (and discover exactly how to improve them). So, let’s break down what those factors mean.
Gemini Pricing Factors You Need To Know
Gemini pricing appears complicated until you break it down to the levers that impact your bill, especially for SaaS teams.
Let’s start with the factors that matter most to teams using the Gemini API (via AI Studio/Google AI for Developers) and Vertex AI. We’ll add notes for related subscriptions where relevant.
Model family and tier (Pro vs Flash vs Flash-Lite)
Different tiers price input and output differently. 2.5 Pro is the most capable (and the most expensive), 2.5 Flash balances cost and capability, and 2.5 Flash-Lite is the throughput/low-cost option. Audio inputs are priced higher on Flash/Flash-Lite than text/image/video. Pro uses a single (multimodal) input rate.
Prompt size bracket (≤200k vs >200k input tokens)
For models like 2.5 Pro, your unit rates step up once the input exceeds 200k tokens, so very long contexts and retrieval-heavy prompts can cross a pricing tier. The same bracket also affects the output rate on Pro. So, you’ll want to plan for this when you pass large docs or multi-file contexts.
Output pricing includes “thinking tokens”
Many 2.5 models apply a “thinking budget.” Google bills output as response + reasoning tokens together, so aggressive reasoning or Deep-Think-style prompts raise the output side of the bill even when the input is small.
Batch Mode vs interactive calls
If you don’t need immediate responses, Batch Mode prices requests at 50% of interactive cost, with an SLA-free, async turnaround (target about 24 hours). Use it for backfills, offline summarization, ingestion, and evaluations.
Context caching (explicit)
You can cache large, reused context once, then pay a reduced cached-input rate on subsequent calls plus cache storage while it lives. This trades a cache-write and storage line item for big savings on repeated prompts (think of long policy docs, product catalogs). Explicit caching provides the savings guarantee (vs implicit caching).
Grounding with Google Search
When you enable the Google Search tool, you get a daily allowance of free grounded prompts (the allowance differs by model family) and then pay $35 per 1,000 grounded prompts beyond that. Only one grounded-prompt charge applies per request, even if the model issues multiple searches.
Real-time/Live API pricing
For low-latency streaming and multimodal “live” use (such as 2.5 Flash Live API), Google uses a separate I/O price table distinct from standard token rates. If you’re doing real-time assistants, model the Live API rates separately from your regular calls.
Media generation uses different meters
Image and video generation (Imagen, Veo) on the same endpoint family bill per image or per second of video, not per text token. If your roadmap includes image/video outputs, plan those costs apart from Gemini text tokens.
Vertex AI vs AI-for-Developers pricing
You can consume Gemini through Vertex AI or the Gemini Developer API. Rates are very similar but not always identical, and Vertex adds meters for surrounding services (tuning, evaluation, pipelines) plus enterprise controls and consolidated GCP billing. Check the Vertex Generative AI pricing tables before committing budgets. Also note that only 200-status requests are billable on Vertex.
Fine-tuning/tuning
Where supported, you pay for training tokens (for example, 2.5 Flash lists a per-million training-token price on Vertex) and then standard prediction pricing for the tuned endpoint (same as base model). Include training epochs in your forecast.
Rate-limit tier (free vs paid) and data use
The paid tier raises rate limits and changes data-handling (like Gemini not using your usage to improve its products), while the free tier is constrained and may allow product improvement use. If you’re moving to production, flip to the paid tier and enable Cloud Billing; it’s also how you request a rate-limit upgrade.
Error charging and retries
On Vertex AI, only successful (HTTP 200) requests are billed. This helps in scenarios with guardrails/filters. Still, retries can spike usage, so track them and tune safety/validation layers to minimize waste.
Dynamic model selection (Vertex Model Optimizer)
If you opt into Vertex’s Model Optimizer, pricing becomes dynamic because Google routes requests to different Gemini tiers based on your “cost/quality/balance” setting. This can improve $/quality but complicates unit-cost predictability, so budget with a buffer.
Org context: seat vs token
Engineer-facing tools such as Gemini Code Assist/Cloud Assist are per-user, per-month (OPEX by seat), not per token. This is good for predictable internal enablement, but separate from your product’s usage-based Gemini API costs.
That said, let’s see how these Gemini pricing factors translate into dollars per month.
So, How Much Does Google Gemini Cost In 2025, Really?
For up-to-the-second prices, do check the official Gemini AI pricing pages. Here are the prices as of the date of this post. We’ll keep it short and sweet.
1. Gemini API (via Google AI for Developers / Vertex AI)
Consider this for Gemini 2.5 Pro.
- Interactive (≤ 200K input tokens):
- Input: $1.25 per million tokens
- Output (includes “thinking” tokens): $10 per million tokens
- Context caching: $0.31 per million tokens
- Cache storage: $4.50 per million tokens per hour
- Interactive (> 200K input tokens):
- Input: $2.50
- Output: $15
- Context caching: $0.625
- Batch Mode (asynchronous): About 50% cheaper than interactive for both input and output rates
- Grounding with Google Search: 1,500 free queries per day; excess at $35 per 1,000 grounded requests
Gemini 1.5 Pro
- Input: $1.25 up to 128K tokens; $2.50 beyond
- Output: $5 up to 128K; $10 beyond
- Grounding: same $35 per 1,000 over allowance
- Free tier still exists in Gemini Studio for exploration
2. Gemini 2.5 Flash-Lite (API / Studio & Vertex)
- Input: $0.10 (text/image/video) or $0.30 (audio) per million tokens
- Output: $0.40
- Context caching & grounding follow Flash-Lite’s tier limits
- Critically, this model is designed for high-throughput and low-cost usage scenarios
3. Gemini on Vertex AI (Cloud Console)
The cost structure mirrors API rates but with added considerations:
- Same input/output pricing for 2.5 Pro, Flash, Flash-Lite
- Batch jobs deliver about a 50% discount
- Additional charges may apply for related services like tuning, deployment, pipelines
- Only HTTP 200 calls are billed. Failed calls don’t incur cost
4. Gemini Subscriptions: AI Pro & Workspace
Google AI Pro (via Google One)
- Approx $19.99/month per user
- Bundles Gemini Advanced tools, 2 TB storage, Veo, NotebookLM, and app integrations
- Ideal for individual productivity, not usage-based attribution
Google Workspace (Business Plans)
- AI features now included in core Workspace pricing:
- Business Starter: $8.40/user/month
- Business Standard: $16.80
- Business Plus: $26.40
- Useful for internal teams, but no granular cost trace to custom AI features
5. Gemini Code Assist
- Standard: $19/month per user (annual billing)
- Enterprise: $45/month per user (annual)
- Offers developer-focused AI support (IDE, SQL, cloud tooling), predictable costs per seat, not per token
With Gemini’s pricing structure out of the way, the next challenge is making sure every token delivers value.
10 Practical Tips For Cutting Gemini Costs Without Losing Performance
Here are almost a dozen real-world, evidence-backed strategies, rooted in official guidance and industry best practices, that SaaS teams use to optimize Gemini usage and costs:
Use context caching strategically
Context caching saves you up to 75% on input token costs, especially when working with large or repetitive prompts. Cache static contexts, like onboarding instructions or product catalogs, and reference them in your requests.
Here’s a quick tip. Set a thoughtful cache TTL so you only pay storage for as long as the context remains relevant.
Switch to Batch Mode for non-urgent tasks
For bulk processing (like analytics jobs, nightly summarizations, or evaluation pipelines, Batch Mode offers a 50% discount over real-time usage. It can also reduce latency overhead and shorten turnaround for high-volume workloads.
Also, leverage built-in tools like grounding and context caching within batch flows for dual efficiency.
Pick the right model tier based on use case
For high-frequency, lightweight tasks, Gemini 2.5 Flash-Lite is your go-to for cost-efficient and high-throughput.
For complex reasoning or code generation, Gemini 2.5 Pro may be necessary, but only where justified by business value.
Choosing the model tier carefully based on performance needs can dramatically shift your cost-per-feature.
Limit grounded searches and optimize your logic
Search grounding adds real-time data at scale, but the cost can climb quickly. After the free threshold (1,500 prompts/day API, or 10,000 alerts in some tiers), you’ll pay $35 per 1,000 prompts.
Something else to try. Cap grounding usage and fall back to static data or caching when appropriate.
Monitor and alert using budgets and quotas
Google Cloud doesn’t allow hard spending limits. However, you can set budgets with alerts and even auto-disable billing once thresholds are reached. This prevents runaway costs from runaway usage. Additionally, set budget alerts tied to Cloud Run functions to protect cost control proactively.

Engineer your prompts
Design prompts that reduce token waste. Be concise. Avoid long system messages embedded repeatedly. Practice prompt engineering (using fewer tokens to get the same or better result) to lower your overall consumption. This also dovetails with cost-capping strategies.
Don’t settle for less AI cost visibility
Google Cloud’s FinOps Hub and cost dashboards offer visibility across projects. They surface optimization recommendations and let you allocate AI costs back to features or departments.
If you want true AI cost intelligence, down to unit costs like cost per product, or feature, or team, you’ll need a more robust platform. And we mean this level of cost intelligence:
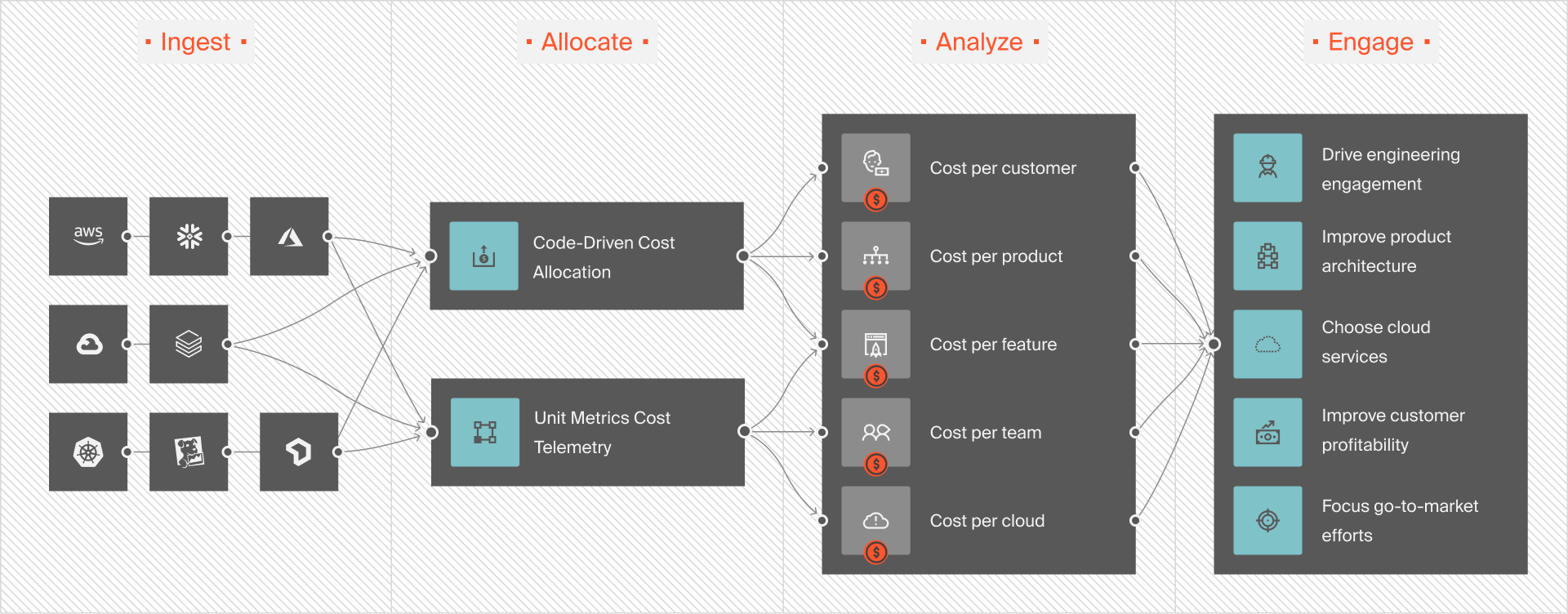
That’s CloudZero.
With our AI cost optimization resources, you can track your AI costs by the hour, per model, project, user, and beyond — and even see how those costs trend over time. You’ll also get timely, context-rich alerts straight to your inbox, so you can catch and prevent overspending before it hits your bottom line.
Innovative, cost-intelligent teams at Toyota, Duolingo, Grammarly, and Rapid7 already trust CloudZero to help them innovate without compromising sustainability. You can, too.  to see CloudZero in action yourself.
to see CloudZero in action yourself.
Exploit multi-modal input efficiency
If your workload includes images, audio, or video, remember that different input types have different cost profiles. For example, short audio clips on Flash-Lite can be cheaper than converting them to long transcripts and sending them as text tokens.
Choosing the most cost-efficient modality for your use case can cut processing costs without losing fidelity.
Better still, benchmark the cost per request across modalities to pick the cheapest viable input type for each workflow.
Additional resources:
- Stop Trying To Cut Cloud Costs, Start Trying To Price AI Correctly
- AI Cost Optimization Strategies For AI-First Organizations
- How To Price AI Features To Actually Make A Profit
- AI Costs In 2025: A Guide To Pricing, Implementation, And Mistakes To Avoid
- In The AI Era, The Winning Teams Track Cloud Unit Costs From Day 1
Segment workloads by latency requirement
Not every AI feature needs sub-second responses. For features with flexible latency, like background processing and weekly reports, route them to cheaper Batch Mode or Flash-Lite endpoints.
Reserve Pro or real-time endpoints only for features where latency is part of the value proposition.
Additionally, build latency-aware routing into your application so model choice is automatic.
Purge and rotate context caches on a regular basis
Context caching is a cost-saver. But stale caches can quietly accrue storage costs. So, delete unused caches on a schedule and rotate large context documents to ensure you’re only paying storage for active assets.
For example, audit cache usage monthly and set automatic TTLs for non-critical cached contexts.
Gemini AI Pricing FAQs
Is there a free tier?
Yes. Google AI Studio offers limited free access for experimentation, and some Workspace and Google One plans bundle Gemini features at no extra token-based cost. The free API tier has strict rate and usage caps.
Is Gemini cheaper than OpenAI’s GPT models?
It depends on the model tier and workload. For high-volume, low-latency tasks, Gemini 2.5 Flash-Lite can be significantly cheaper than GPT-4o or GPT-4 Turbo. For reasoning-heavy tasks, Gemini 2.5 Pro’s pricing is in the same range as premium OpenAI tiers, though batch mode and context caching can tilt the economics in your favor.
Are Vertex AI and the Gemini API priced the same?
Mostly, but not always. The base token rates are similar, but Vertex AI may add charges for related services (tuning, pipelines, evaluation) and can have small rate differences. Vertex also offers enterprise-level IAM controls, regional deployment, and consolidated GCP billing.
How does grounding with Google Search affect my bill?
Gemini includes a free daily quota (1,500 prompts for 2.5 Pro/Flash API) for search grounding. Beyond that, it’s $35 per 1,000 grounded prompts. For grounding-heavy workloads, budget for this separately.
Do I pay for failed or filtered responses?
On Vertex AI, only successful (HTTP 200) requests are billed. However, retries can still inflate usage, especially if safety filters trigger frequently.
What’s the cheapest way to run large-scale workloads?
For non-urgent, high-volume jobs, use Gemini 2.5 Flash-Lite in batch mode, pair it with context caching, and minimize grounding calls.
Do subscription plans like Google AI Pro make sense for businesses?
Only for internal productivity. Subscription plans are not designed for cost-per-feature attribution, which is essential in most SaaS contexts. But if you’re ready to keep innovation high and AI costs a competitive edge (not a surprise margin killer), see how CloudZero gives you full Gemini AI cost visibility here — and start making every token count.











