
For most of the last decade, the direction of cloud strategy was clear: standardize, consolidate, and reduce sprawl.
Engineering teams worked to pick a primary cloud, reduce vendor dependencies, and simplify their stacks. FinOps teams unwound years of fragmentation. Platform teams built guardrails to make sure it didn’t happen again.
Then AI arrived, and it’s a fundamentally different class of workload.
AI demands specialized hardware and, increasingly, diverging providers.
Now, those same teams are reexamining their architectures through an AI lens. They’re deploying AI features that span clouds, APIs, and regions.
That’s why hybrid and multi-cloud strategies are back, not because teams want more complexity, but because AI makes single-cloud strategies fragile. How?
In this guide, we’ll explore how and why this shift is happening, and what you can do to stay competitive without losing control.
These Are The AI Forces Breaking Single-Cloud Strategies
Three forces, in particular, are now pushing cloud teams back toward hybrid cloud strategies and multi-cloud architectures.
1. Model specialization is fragmenting the AI stack
With AI, no single provider dominates across all model capabilities. Some AI models excel at reasoning. Others are great at long-context retrieval, multimodal inputs, and so on.
Today, those strengths are increasingly tied to specific providers and specific hardware stacks.
As a result, more teams are no longer choosing clouds first and models second. Instead, they’re choosing models first and inheriting clouds as a consequence.
Consider these scenarios:
- An AI-powered customer support feature may depend on one provider’s long-context model.
- A coding assistant may depend on another provider’s reasoning model.
- A vision pipeline may depend on yet another provider’s multimodal stack.
At that point, sticking to your “single cloud” guns can end up being a constraint rather than a strategic choice.
2. Hardware scarcity is reintroducing physical constraints
For the last decade, if you needed more compute, you simply provisioned it. If your usage or demand spiked, you had Autoscaling to expand your capacity. And if a region filled up, you had another region ready to absorb the load.
Now, AI has reintroduced hard physical scarcity.
GPUs and TPUs are not infinitely elastic, after all. Capacity varies by provider, region, accelerator generation, as well as contract and quota limits. In practice, that means:
- Some models are only available in certain regions.
- Others require accelerators that may be backlogged for months.
- And many GPUs can’t scale on demand when usage spikes.
Today, location and hardware availability are key drivers behind modern hybrid AI stacks.
- On-prem GPUs for steady, predictable workloads
- Cloud accelerators for burst capacity
- APIs for frontier models you cannot host yourself
Hybrid, in this case, is increasingly about owning capacity in a world where AI-first capacity is still scarce.
3. Marginal cost concerns are back, too
Most cloud workloads behave like this. Infrastructure is provisioned in advance. Costs are amortized over time.
AI does the opposite. It reintroduces true marginal cost per request. That means every prompt has a price. Every token has a cost. And every routing decision you make changes your SaaS unit economics.
Moreover, those costs vary dramatically by AI model, context length, feature behavior, retrieval patterns, and tool usage.
That means architecture is affecting more than just performance, but also SaaS pricing decisions. For example:
- A routing rule can change your margins.
- A context window can double your costs.
- A model switch can rewrite your cloud unit economics overnight.
In that environment, the cheapest path might be a different model, the fastest path a different provider, and the most profitable path a hybrid AI stack.
Together, these three forces explain the AI-driven return of hybrid and multi-cloud strategies.
In the next section, we’ll look at how this plays out in practice. Then we’ll explore the specific hybrid and multi-cloud patterns AI-first teams are adopting (so you can, too).

How Hybrid And Multi-Cloud Patterns Are Re-Emerging In Practice
AI “multi-cloud” decisions are happening at the inference layer. And instead of choosing one cloud architecture and standardizing everything behind it, more teams are mixing environments and providers at the feature and workload level.
In essence, they are routing AI work to the best option in the moment, not running the same app in two clouds.
Here are the three patterns showing up repeatedly.
Pattern 1: Multi-model, multi-provider routing becomes a first-class system component
Teams are increasingly putting a routing layer (a kind of AI gateway) between their application and multiple model providers so they can centralize aspects such as:
- Fallback and failover (to buffer against provider outages, quota limits, rate limits, etc)
- Latency-aware routing (to meet SLOs)
- Cost-aware routing (to protect their unit economics and bottom lines)
- Policy and governance (configuring which teams and features can use which models)
In fact, major hyperscalers and ecosystems are now designing for routing as a core production primitive:
- AWS has published guidance for a multi-provider generative AI gateway architecture that normalizes access to multiple LLMs behind a consistent API and supports routing and fallback patterns.
- Amazon Bedrock’s prompt routing is explicitly designed to choose options that balance quality and cost. It treats routing itself as an optimization problem.
- Azure documents using a gateway in front of multiple Azure OpenAI backends to direct requests server-side without redeploying clients.
- Open-source routing stacks, like LiteLLM’s router, fallback model groups, and cooldown policies, reflect that routing is now an expected production capability.
And on the “how teams implement this” side, NVIDIA has published an LLM router blueprint that explicitly describes automating trade-offs across accuracy, speed, and cost by choosing an optimal model per prompt.
What’s new here is not multi-cloud but where the decision lives. Routing decisions are increasingly made at the feature and request level, not at the “pick one vendor for the whole company” level.
Pattern 2: Three-tier hybrid compute
Another common operating model emerging is to own the baseline and burst to the cloud. In practice, that is looking like this:
- On-prem or dedicated capacity for steady, predictable inference and training
- Public cloud for burst, experimentation, and rapid scale-out
- Managed AI services and APIs when the best models aren’t practical to host yourself
Deloitte describes this as a “three-tier hybrid” approach, explicitly positioning public cloud as the elasticity layer for variable workloads and experimentation.
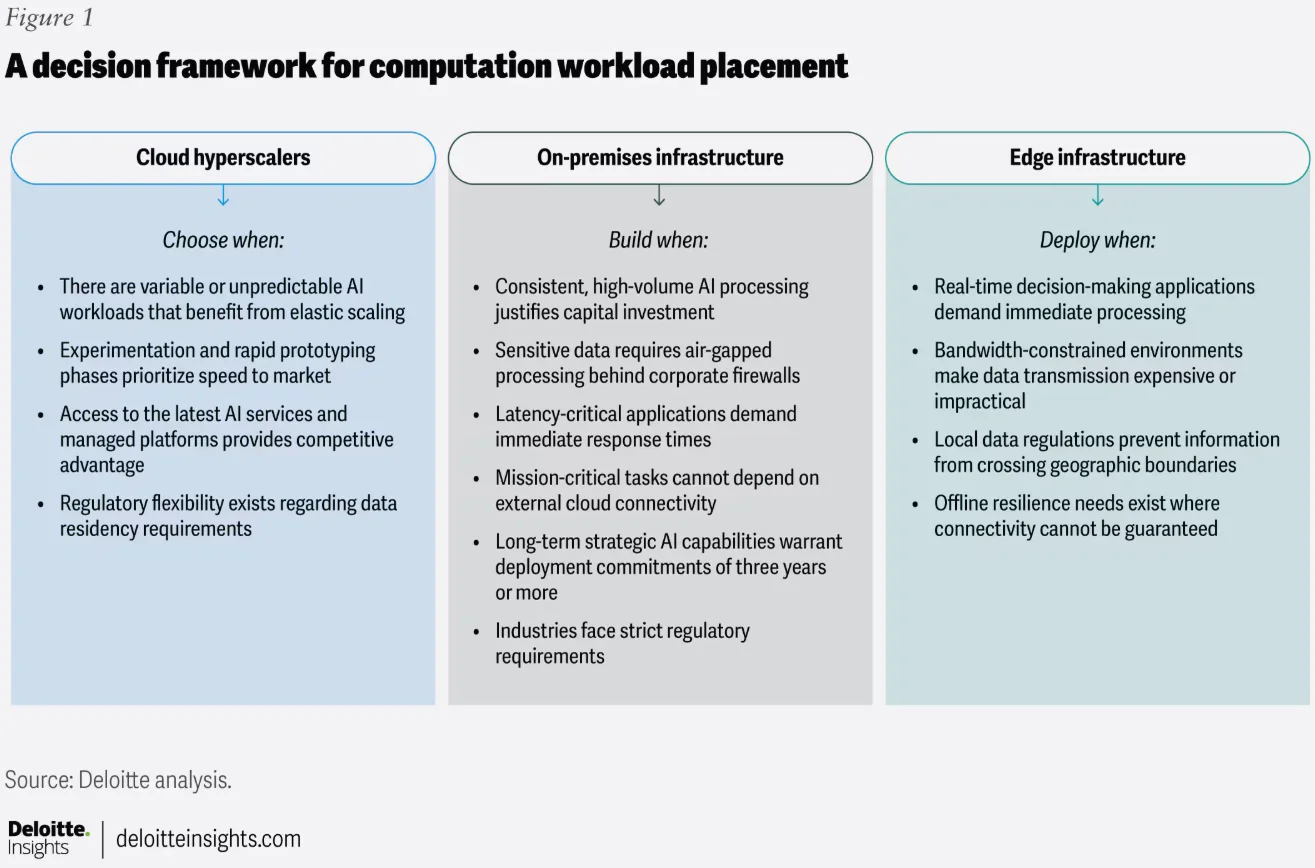
Image: Deloitte’s AI tech trends 2026
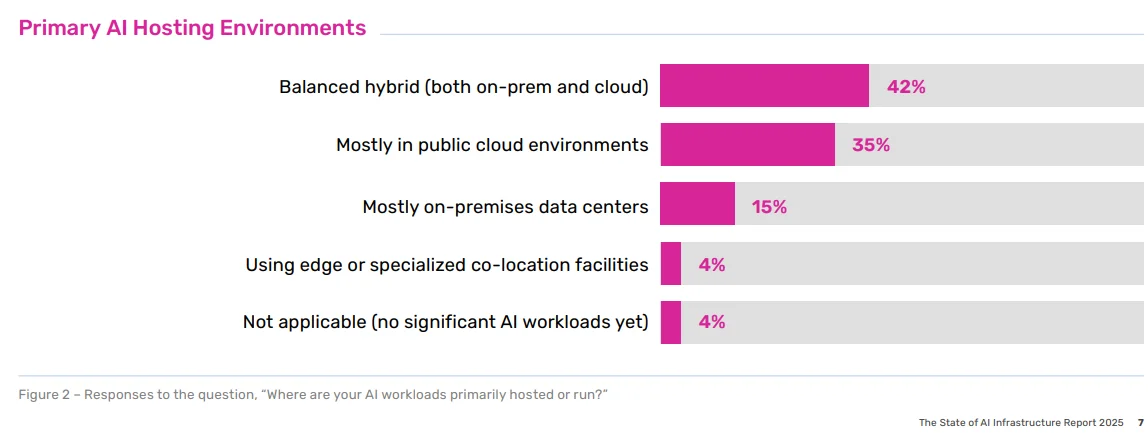
Additionally, survey data points in the same direction. A10 Networks’ 2025 AI Infrastructure report found that 42% of respondents favor a balanced hybrid approach (on-prem plus cloud) for hosting AI workloads, driven primarily by performance, latency, and availability needs.
Teams adopt this pattern for several reasons:
- GPU and accelerator capacity are uneven and sometimes constrained
- Workloads vary wildly between “always on” and “spiky”
- Some data and compliance realities still require local control
- Some models and features are simply better delivered through external APIs
In other words, using AI is making capacity and economics non-negotiable.
Pattern 3: Feature-level cloud fragmentation
Many teams aren’t “going multi-cloud” through a formal platform program. They’re going multi-cloud one product feature at a time.
Picture this:
- Feature A needs long-context and high reliability, so you plug into provider X
- Feature B needs cheap summarization at scale, and provider Y delivers that
- Feature C needs multimodal inference on a specific accelerator, which provider Z excels at
- Meanwhile, internal tooling runs on local GPUs to keep your baseline costs stable.
Over time, AI is pushing multi-cloud decisions down to the level where product decisions are made. One feature. One model choice. And one provider footprint at a time.
Hyperscalers are adapting to this reality as well.
Instead of pushing a single flagship model, they’re expanding their model catalogs. As Azure did with DeepSeek, they are offering more third-party models, more partners, and more choices within a single platform surface.
That shift makes one thing clear: there’s no longer ‘one model provider to rule them all.’
Once an AI system starts routing across models, mixing accelerator environments, and fragmenting at the feature layer, the biggest risk is no longer the complexity itself.
It’s what that complexity hides. Your AI unit economics.
Let’s tackle this problem below.
The New Risk Is Ghost AI Economics
In AI-driven hybrid and multi-cloud systems, cost stops living in one place. It spreads across providers, clouds, models, features, and workflows. And when cost fragments like that, visibility is what breaks first.
That’s why the real risk in modern AI systems is ghost economics. These are AI costs that are real, material, and margin-shaping, but largely invisible until it’s too late.
Here’s how high-performing teams are operating AI across hybrid and multi-cloud environments without losing financial or technical control (so you can, too).
Hint: They don’t try to eliminate fragmentation. They design for it.
1. They manage AI at the feature and workflow level
Instead of tracking AI cost by account, project, or provider alone, they are also tracking it by:
- Product feature
- User workflow
- Customer segment
- Internal service
That’s where AI actually creates value. And it’s also where it quietly destroys margins.
That shift is helping these teams understand:
- Which of their product features are cost-heavy
- Which workflows are scaling poorly
- Which use cases are margin-positive, and
- Which experiments to kill early before they scale inefficiency
Once they know those answers, they can more easily avoid a common AI failure happening today: Scaling AI usage before understanding your unit economics.
2. They turn routing and model choice into economic decisions
For these teams, routing is not limited to only availability or latency. It’s also about staying profitable. So, they also actively monitor their unit cost signals, such as:
- Cost per model
- Cost per request
- Cost per feature
- Cost per customer
Then they use that data (not gut instinct) to decide:
- Which models to allow for which features
- When cheaper models are used as substitutes
- When using premium models is justified
- When routing rules need to change
In other words, they don’t optimize for accuracy alone. They also optimize for accuracy within economic guardrails.
3. They close the loop between engineering, FinOps, and product
This is often the biggest difference.
High-performing teams don’t leave AI cost management to finance alone. Instead, they build a tight, continuous feedback loop between engineering (who design the systems), product (who define the features), and FinOps (who track margins and ROI).
That collaboration empowers them to answer hard questions in near real time, including:
- Which release changed our cost per action?
- Which feature update broke our margin targets?
- Which customer segment is becoming unprofitable?
- Which experiment should we double down on — or shut down completely?
- What should we charge for this feature to stay profitable?
Instead of trying to further reduce providers or avoid hybrid and multi-cloud strategies, these teams make their AI economics visible, measurable, and actionable across distributed systems. That empowers them to scale their AI deployments deliberately with cost confidence.
Helpful Resources:
But how do you capture timely, accurate, and immediately actionable unit cost economics like cost per AI model or even per AI service, to begin with?
That’s the missing layer in most hybrid and multi-cloud strategies today. Yet that’s exactly where a platform like CloudZero enters the picture.
AI changed the physics of cloud computing. Reliable cloud cost intelligence is how you regain control.
If your AI workloads already span multiple models, clouds, and providers, your next best step isn’t a leaner architecture.
It’s getting economic clarity back.
You’ll want to have your AI economics visible at the level where profitability is actually decided, such as per feature, per SDLC stage, or per AI service, like this:
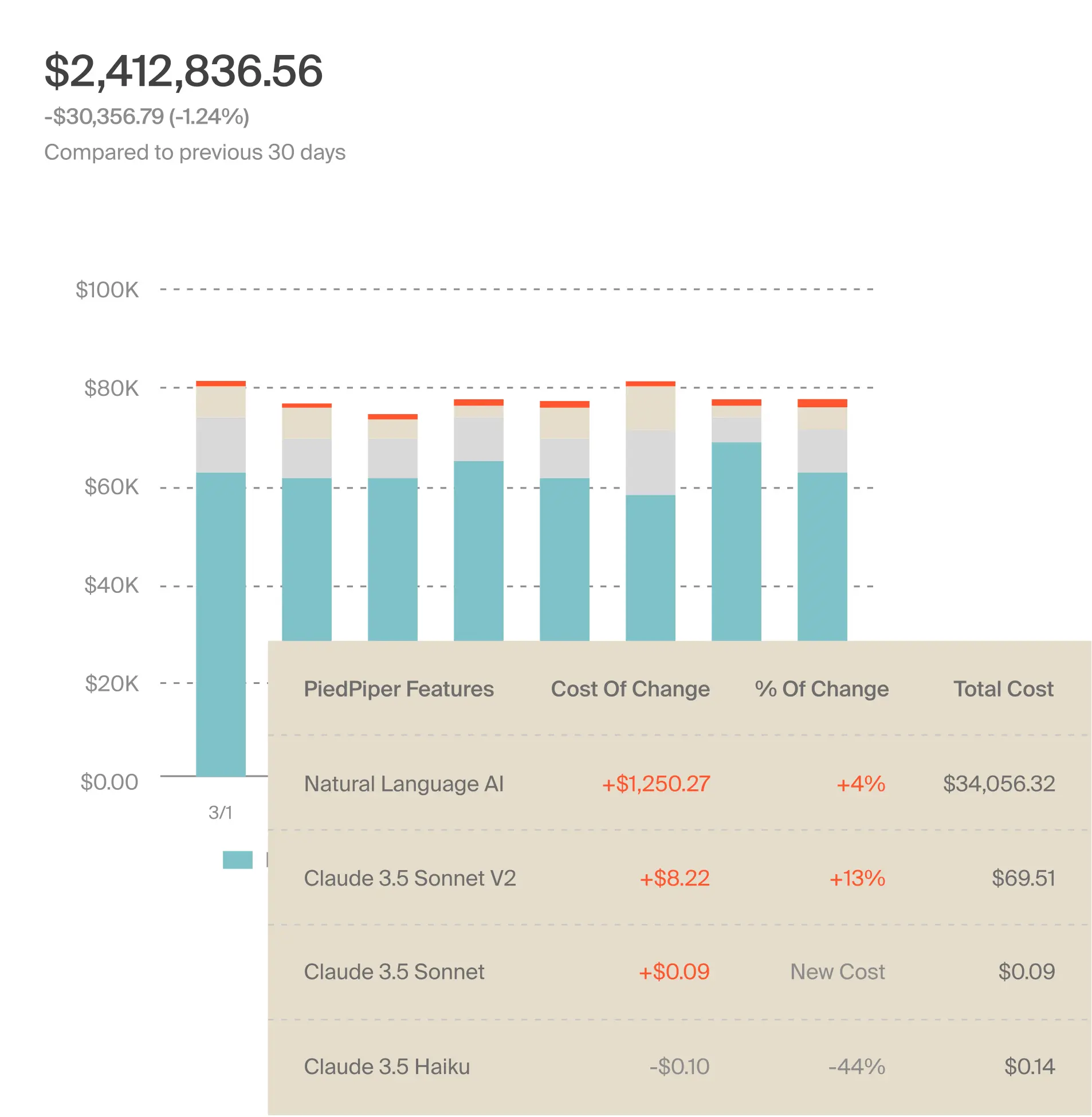
Because in AI systems, architecture choices don’t just affect performance. They also directly shape your margins.
CloudZero already helps teams at Grammarly, Toyota, and Drift turn distributed AI usage into a single, trusted view of:
- Which people, products, and processes are driving AI costs
- What each AI feature costs
- Which customers are profitable
- And which decisions to change next, like this:
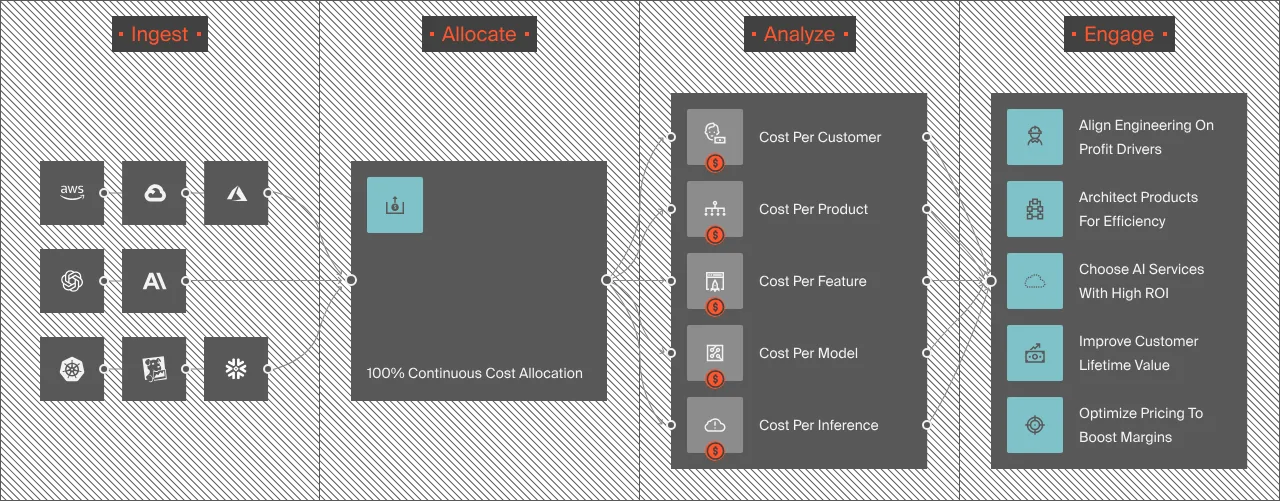
That’s how they’re scaling AI across hybrid and multi-cloud environments; with financial clarity, not guesswork.
Are you ready to turn your distributed AI infrastructure into clear, actionable cost intelligence? Then  to see how to do exactly that firsthand.
to see how to do exactly that firsthand.
Hybrid And Multi-Cloud For AI Workloads FAQs
Why is AI pushing companies back to hybrid and multi-cloud strategies?
AI workloads break the assumptions that made single-cloud strategies efficient. Specialized AI models, scarce accelerators such as GPUs, and per-request marginal costs force teams to choose models and hardware first, then inherit cloud providers as a consequence.
Is multi-cloud for AI about avoiding vendor lock-in?
No. AI-driven multi-cloud prioritizes performance, availability, and unit cost. Each request is routed to the best model and infrastructure.
Why can’t a single cloud provider handle all AI workloads effectively?
No single provider leads across all AI model types. Capabilities vary by model, accelerator, and region. Single-cloud strategies limit AI feature flexibility.
How do leading organizations manage AI costs in hybrid and multi-cloud environments?
High-performing teams track AI cost by feature, workflow, and customer, not just by infrastructure. They treat routing and model selection as economic decisions and align engineering, product, and FinOps around shared unit-cost signals.
Is hybrid and multi-cloud complexity the real risk with AI?
No. The main risk is the hidden AI cost. Complexity becomes dangerous only when cost drivers lack visibility.
What is an AI routing layer, and why is it important?
An AI routing layer directs requests across multiple models. Providers are selected dynamically at request time. Routing controls cost, latency, and availability.
How are hyperscalers adapting to AI multi-cloud realities?
Cloud providers are expanding model catalogs and supporting routing instead of pushing a single flagship model. Platforms like AWS and Azure are now designed for multi-model access within their ecosystems.
How does hardware scarcity affect AI cloud architecture?
Unlike traditional cloud computing, GPUs and TPUs are physically constrained. Availability varies by provider, region, generation, and quota. As a result, teams combine on-premise GPUs for steady workloads, cloud accelerators for burst demand, and APIs for frontier models.
What does “marginal cost” mean in AI systems?
Every AI request has a direct cost. Tokens, context length, and retrieval increase spending. Architecture decisions directly affect unit economics.


The Cloud Cost Playbook
The step-by-step guide to cost maturity



