Most organizations migrate to the Amazon Web Services (AWS) public cloud from on-premises data centers. However, others have switched from another Infrastructure-as-a-Service (IaaS) platform to AWS. The most common reason we hear for choosing AWS is cost savings.
As the largest public cloud provider, AWS leverages economies of scale, making its cloud services more affordable than those a company would have to build itself.
Yet, not every organization can claim that AWS has saved it money. Many companies have been looking for ways to reduce AWS costs for the last five consecutive years.
Below is an overview of what this AWS cost management guide will cover. Feel free to continue or skip to the section that interests you.
What Is AWS Cost Management?
The Amazon Web Services (AWS) cost management process includes planning, organizing, reporting, analyzing, and controlling AWS resource usage and associated costs. Rather than simply calling all of its cost management tools, resources, and services cost management, AWS uses the term cloud financial management to cover the ten cost management services, best practices, and cost optimization techniques it offers.
The practice also involves selecting and allocating just enough computing power, storage, and other cloud resources to ensure a task runs smoothly with minimal cloud waste.
Cost management in AWS is a continuous process of improving cloud cost visibility. AWS billing is also based on usage, so cost management also involves forecasting, budgeting, monitoring, and controlling AWS spending.

Research Report
FinOps In The AI Era: A Critical Recalibration
What 475 executives told us about AI and cloud efficiency.
How Does Cost Management In AWS Work?
You can optimize your AWS bill by utilizing the public cloud’s cost management services, resources, and tools.
They cover three aspects: use case, capability, and ideal tool/resource. Utilizing them will enable you to:
- Manage cloud financial planning
- Forecast and budget costs
- Use consolidated billing for cost control
- Reduce your AWS bill using AWS pricing optimizations.
That’s a mouthful, so let’s look at how these ten AWS cloud cost management services actually work in practice.
Use case | Capability | AWS Tool or Resources |
Access | Track AWS billing information across your organization in one place | AWS Consolidated Billing, AWS Purchase Order Management, AWS Credits |
Organize | Develop your own tagging strategy for cost allocation and governance | AWS Cost Allocation Tags, AWS Cost Categories |
Budget | Set your own AWS budget, spend limit, and receive automated alerts when you are about to exceed that threshold | AWS Budgets, AWS Budget Actions, AWS Service Catalog |
Purchase | Take advantage of AWS free trials and discounts based on your workload needs and usage pattern | AWS Free Tier, AWS Savings Plan, AWS Reserved Instances, AWS Spot Instances, AWS DynamoDB On-Demand |
Report | View a collection of your cost data to raise your AWS spend awareness to inform your next steps | AWS Cost and Usage Report, AWS Cost Explorer, AWS Application Cost Profiler |
Inspect | Monitor your resource deployment on AWS to uncover cost optimization opportunities | AWS Cost Explorer |
Elasticity | Schedule, deploy, and scale your AWS resources based on your workload needs and usage pattern | AWS Instance Scheduler, Amazon RedShift Pause and Resume, Amazon EC2 Auto Scaling, AWS Trusted Advisor |
Rightsize | Allocate a resource size that matches your actual workload demand to avoid waste | AWS Compute Optimizer, Amazon Redshift Resize, AWS Cost Explorer Right Sizing Recommendations, Amazon S3 Intelligent Tiering |
Control | Set up cost guardrails to enhance governance and prevent cost overruns | AWS Organizations, AWS Identity and Access Management, AWS Cost Anomaly Detection, AWS Service Catalog, AWS Control Tower |
Forecast | Estimate your organization’s resource utilization and use the forecast dashboards to guide your AWS spending | AWS Budgets (Event-driven), AWS Cost Explorer (Self-service) |
Viewing previous months’ usage metrics for each service is necessary to manage AWS costs. Logging in to the Billing and Cost Management Dashboard will enable you to examine usage patterns with AWS Cost & Usage Report and AWS Cost Explorer.
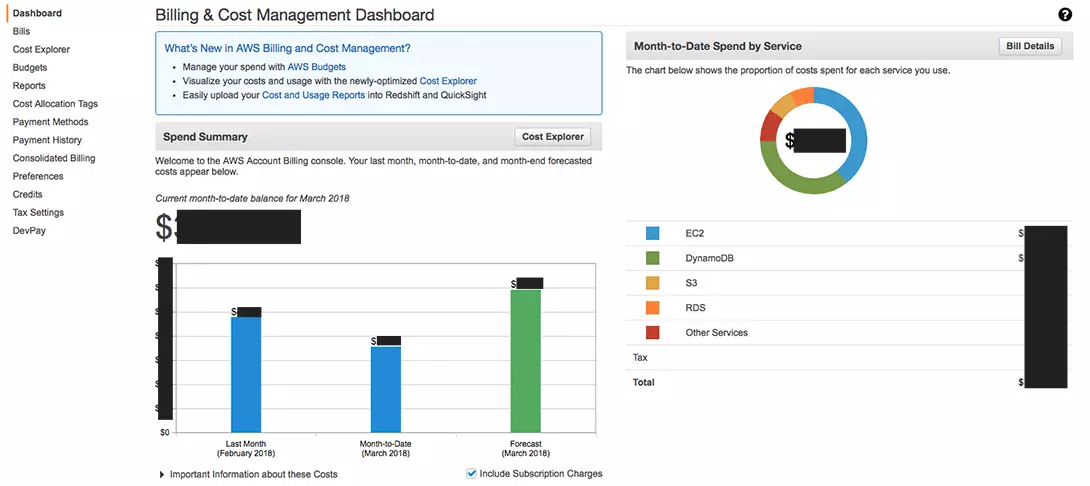
Credit: Billing Manager in AWS
With AWS, you can visualize your historical usage and its cost to your organization through charts, graphs, and other cost data formats. An administrator can then use the average monthly usage or other criteria to estimate future resource utilization on AWS.
But there’s a catch.
First, you must apply cost allocation tags to label, organize, and track usage on the AWS public cloud.
What Is Cost Allocation In AWS?
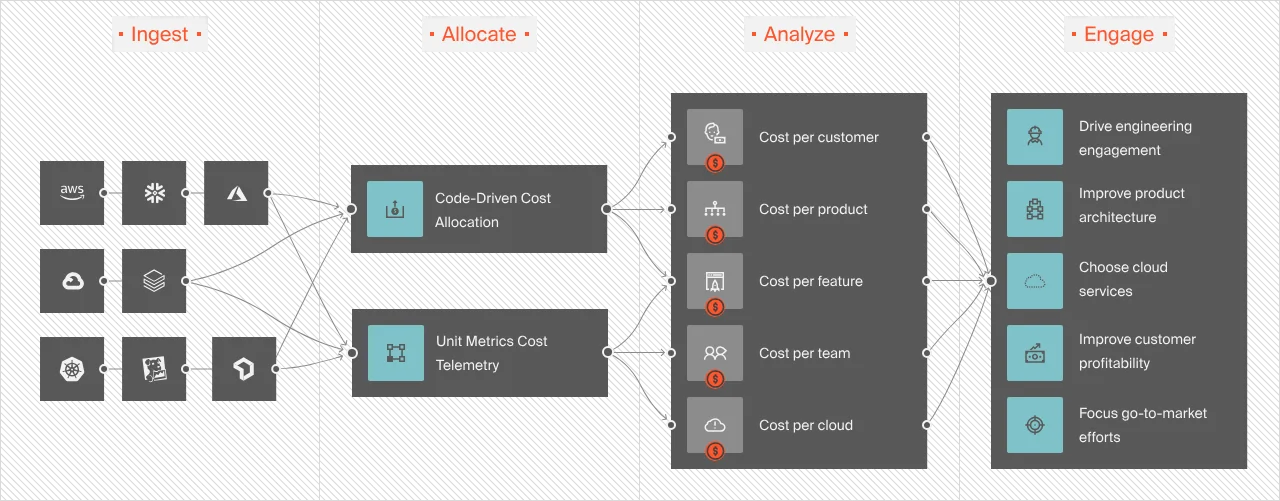
AWS cost allocation involves identifying, aggregating, and allocating cloud spend across multiple cost centers such as a product feature, service, tenant/customer, development team, or engineering project.
It lets you know which services are using AWS resources and how much they cost.
Furthermore, cost allocation establishes a framework for assigning costs to particular cost centers or business units based on their share.
In a typical business setup, cost allocation is based on factors such as revenue, headcount, square footage, direct labor hours, and machine hours.
Cost allocation in the AWS public cloud is based on factors such as the type of Amazon EC2 instances deployed and usage per second.
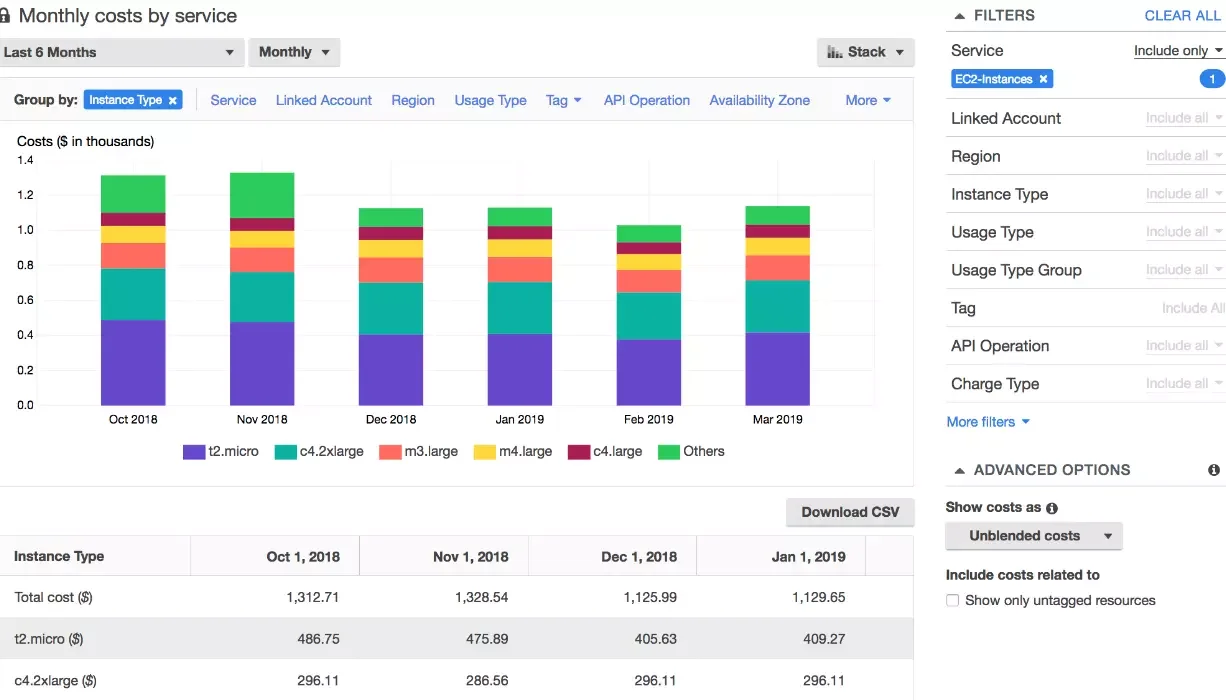
Credit: Cost Explorer Report UI
An ideal cost allocation can help expose the amount of resources each business unit consumes. As a result, each department can be more cost-conscious and accountable in how they use AWS resources, thus reducing overall costs.
What Are The Challenges Of AWS Cost Allocation?
The process of allocating costs in AWS is not without its challenges. Here are some of them and possible solutions.
Challenge 1: Choosing how much and where to allocate resources
Tracking AWS costs at the unit level can be challenging, making determining where to increase or reduce allocations difficult. You must also connect your resources to key business dimensions, outcomes, or cost centers to put the costs in context.
Solution:
Create separate accounts for each team, product, or environment. Organizing your AWS account this way gives you visibility into how each of these cost centers is driving your AWS cloud costs. Check out more about how to allocate AWS cloud spend here.
To increase cost visibility and attribution in AWS, you can also use native AWS cost management tools and third-party solutions like CloudZero to map AWS cost information to specific business activities.
Challenge 2: Breaking through the tagging barrier
Tagging resources on AWS so they are easier to identify, organize, and track can be daunting. A comprehensive plan must be developed, including the labels, how to maintain tagging consistency, and how to get everyone to follow the plan throughout the organization, even after a merger or acquisition.
Solution:
We recommend implementing AWS tagging best practices, which we’ve explored in detail here.
Using a cloud cost intelligence solution can also help you allocate costs even if you have messy AWS tags. For example, CloudZero doesn’t over-rely on a perfect AWS tagging strategy to align cloud costs to a specific business unit or cost center, such as a customer, development team, engineering project, or product feature.
Rather, it gathers cost data from AWS tags, enriches it with infrastructure and application cost indicators, and then maps it to specific cost centers. So, instead of seeing raw AWS data like this:
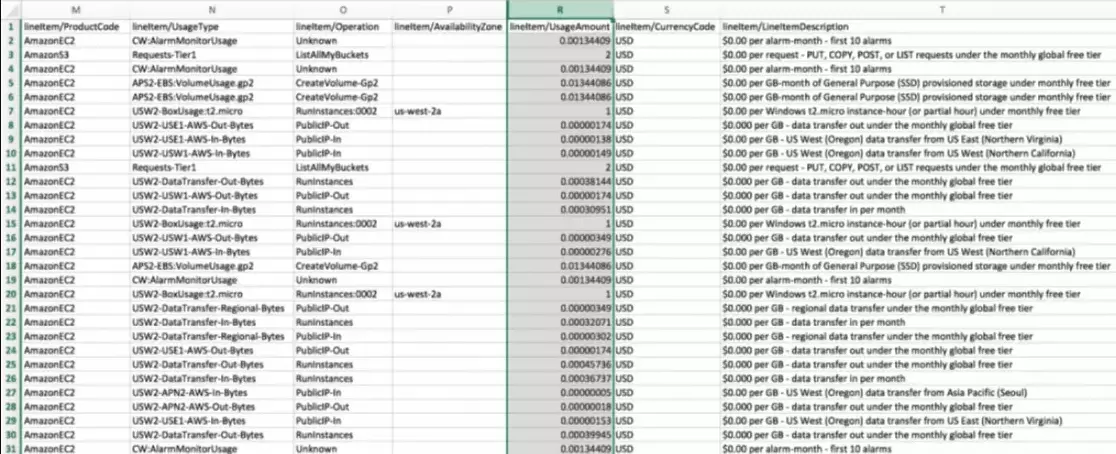
CloudZero presents unit cost information in an easy-to-digest format like this:
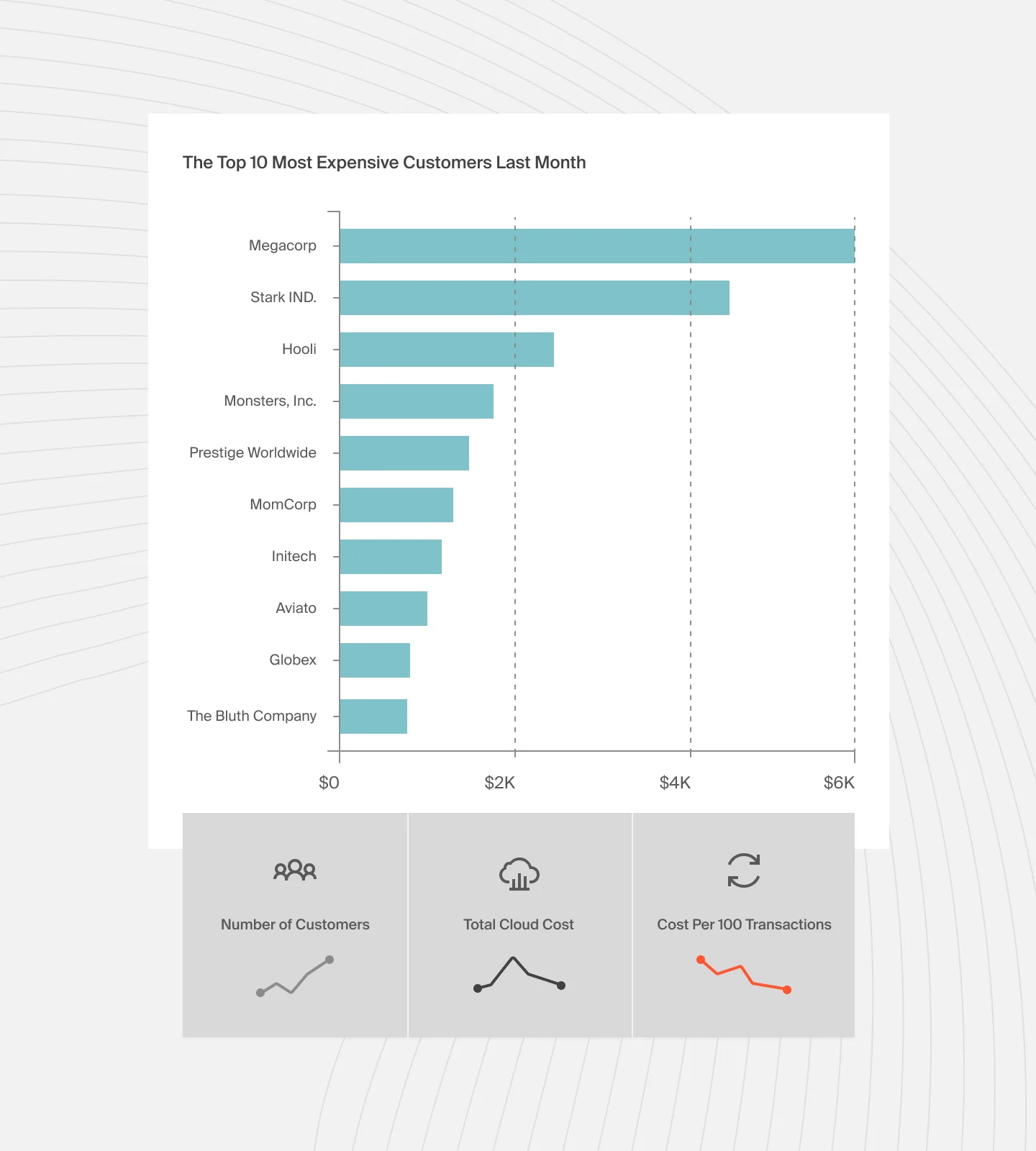
A cost per customer report looks like this:
Once you know what each cost center or business unit consumes, allocating costs to support optimal operations is easier. Or, you can more effectively decide how to pull strings to lower consumption, hence costs, without sacrificing smooth customer experiences.
Challenge 3: Beware of overwhelm
There are several ways to manage cost allocation in AWS. The key is maintaining a consistent strategy, as without it, you won’t be able to reliably compare costs from one month to the next.
Solution:
Decide what details to use and stick to them to maintain consistency in your cost analysis from one AWS billing cycle to the next.
What Are The Key Areas Of Cost Optimization In AWS?
The AWS guide to cost management suggests that AWS can help your organization SEE where costs are coming from, RUN operations with minimal unexpected expenses, PLAN for dynamic cloud usage, and SAVE on cloud bills as you scale your use of AWS.
- Seeing refers to increasing your cost awareness using various tools and resources.
- Running here involves monitoring operations daily, to maximize cost-effective resources.
- In planning, cost data is collected, and analyzed, and insight is drawn from it to match AWS resources to workload demands.
- AWS cost optimization techniques and tools can help you optimize savings over time, not only by reducing your AWS bill but also by improving your four key dimensions of business value on AWS:
- Cost savings
- Staff productivity
- Business agility
- Operational resilience
Yet, there are still some challenges that can hinder your ability to reap the benefits of AWS cost management.
What Are The Challenges Of Managing AWS Costs? And How Can You Solve Them?
AWS cloud financial management challenges include low-cost visibility, cost accountability issues, making cloud finance management a finance-only responsibility, and not having the skill set, tools, or time to control cloud costs before it is too late.
Here are more challenges of managing cloud spend in AWS, along with suggestions on how to fix them.
1. Cost accountability issues
It is challenging to determine who or what is driving your cloud spend when a distributed team or a business unit does not assume responsibility for specific cloud costs. An even bigger problem is when there’s no way to uncover how a particular business unit affected costs in a billing cycle. This makes it difficult to figure out where to trim resources without affecting mission-critical activities.
Solution:
Develop a cloud cost governance strategy to guide your organization’s use of AWS cloud resources. It should include specific rules, regulations, and controls that prevent problematic situations, such as defining who should deploy a project and when to prevent project costs from going over budget. Here’s how to set up a cloud cost governance strategy that works.
2. Understanding an AWS bill can be tough work
There is no denying that the typical AWS cloud bill is complex. That complexity stems from its opaque billing. Many companies struggle to break down an AWS bill into unit costs to determine which specific features, customers or tenants, projects, or business units incurred what costs, when, and why.
Solution:
Use cloud cost intelligence to map specific cost metrics to business activities. This modern cost management approach empowers you to organize AWS costs by actionable business factors, such as cost per customer, cost per team, cost per deployment, and cost per product feature — unlike traditional cost management tools.
3. Cloud cost management is not for the manual-hearted
It is virtually impossible to track, analyze, and optimize AWS costs manually, especially for heavily dynamic applications like microservices, Kubernetes, and containerized apps.
Solution:
Utilize automation to identify, track, alert, and control AWS resources. Manual practices are prone to errors, time-consuming, labor-intensive, and prone to security vulnerabilities. You can use these top AWS cloud cost management tools, from rightsizing resources, picking an optimal AWS pricing model, and detecting cost anomalies.
4. Tagging resources is a lot of work — which doesn’t always go as planned, in time, or remain intact
Tracking usage and monitoring costs is easier when AWS resources are labeled. The challenge is developing a detailed, coordinated, consistent tagging strategy. When you do, factors such as mergers, acquisitions, or new members joining or leaving the tagging team could still compromise the entire effort.
Solution:
Start by learning how to create, develop, and implement an effective AWS tagging strategy step-by-step (free guide). Developing a unified tagging strategy will enable your company to track all of its cloud resources into the future, regardless of whether team members stick together or transfer to other projects.
As a next step, use an AWS cost optimization solution that does not depend solely on perfect tags. As an example, CloudZero consolidates cost data from multiple sources — from untagged and untaggable resources to shared and multi-tenant environments. It then enriches the cost metrics by incorporating data from tagged resources, ensuring you analyze enough cost data to avoid surprises.
5. Accurately forecasting AWS costs is difficult
Cloud costs are hard to predict because they are variable. This makes them difficult to budget for in advance. Yet, a budget is supposed to act as a cost guardrail in AWS.
Solution:
Everybody has to start somewhere. In AWS, this means utilizing user-defined and AWS-defined tags to attribute costs.
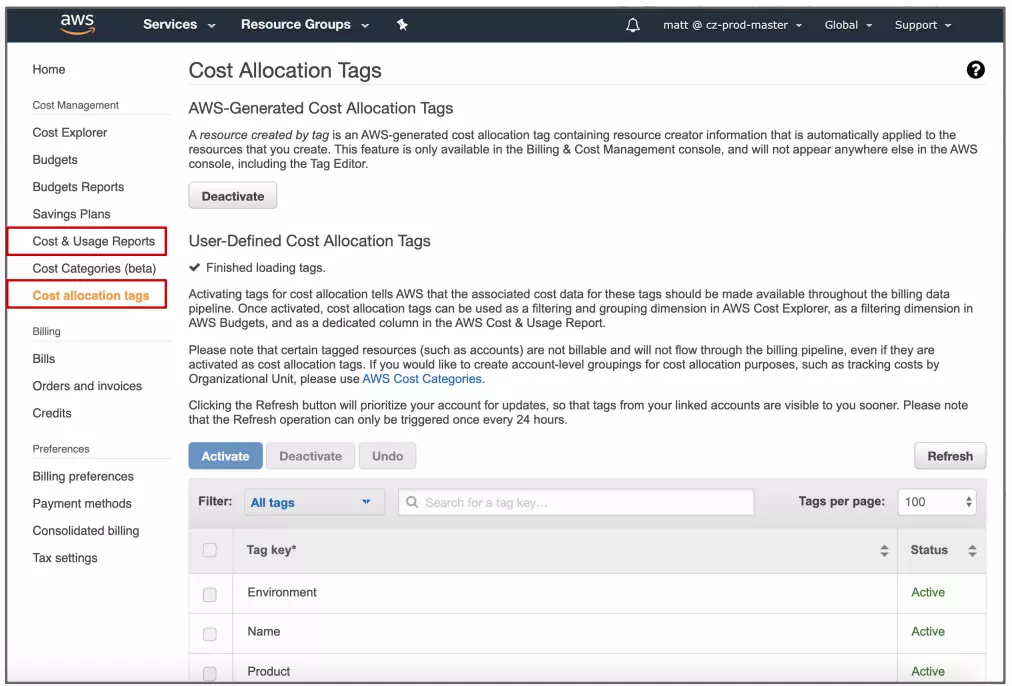
However, a cost intelligence platform can also help you gain insight into your unit costs as early as possible without endless tagging, enabling you to identify which areas to allocate more or fewer resources in the next billing cycle.
6. Trying to reduce your AWS bill can be counterproductive
A high AWS bill often prompts an organization to seek out ways to reduce their bill at all costs. But, such an approach limits an organization’s ability to innovate, grow, and implement cloud cost optimization.
Solution:
A high cloud bill can also indicate growth in the form of releasing additional features, onboarding more customers, and supporting more tenants’ workloads. So, rather than reduce your AWS costs indiscriminately, use unit cost analysis to find out which of your resources you can reduce and which you can increase to maximize your ROI.
7. Engineering and finance struggle to read from the same cost script
In many organizations, engineers do not participate in discussions about cloud costs, so they tend to focus on promoting properly functioning code and a good user experience. Cost is often overlooked. As a result, finance has struggled to get engineers to keep cloud budgets in check.
Solution:
Engineers can avoid this tug-of-war by understanding how their actions impact an organization’s budget, bottom line, feature pricing, and overall competitiveness. Using a tool like CloudZero can offer engineers valuable insights into technical unit costs, such as cost per feature, cost per deployment, and cost per development team. See seven reasons engineers love CloudZero here.
8. Nonoptimal architectural design leads to overspending
Take rehosting, for example, which is a common strategy for companies moving to AWS. Overlaying a flawed or suboptimal design on top of the AWS framework can lead to long-term costs that are challenging to reverse.
Solution:
Refactor applications from traditional on-premises environments to cloud-native ones takes time, skill, and money. So if you cannot afford it, you can use the AWS Well-Architected Framework to enable your architects to create a secure, cost-effective public cloud environment to rehost your applications, data, and other workloads.
It is also common for teams to realize cost spikes and trends too late.
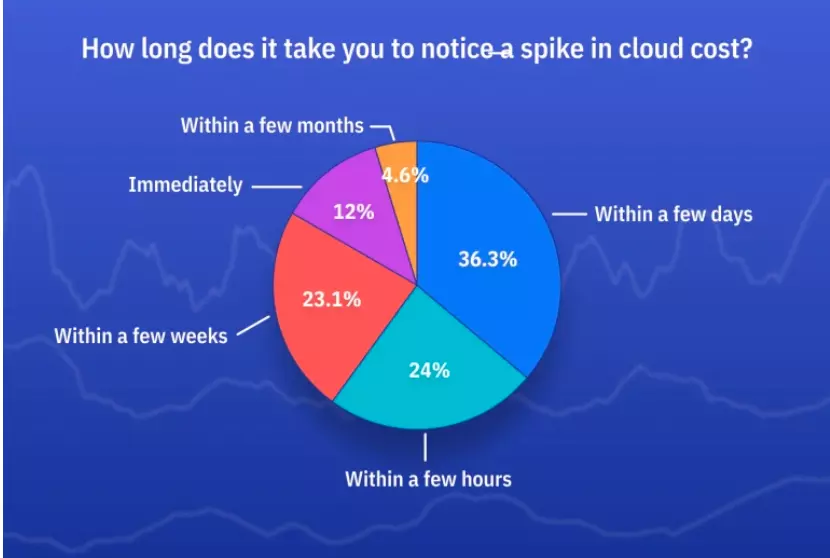
Credit: ProsperOps
Thus, you’ll want to set up an AWS cost anomaly detection system to alert your team of cost spikes or trends before going over your AWS budget.
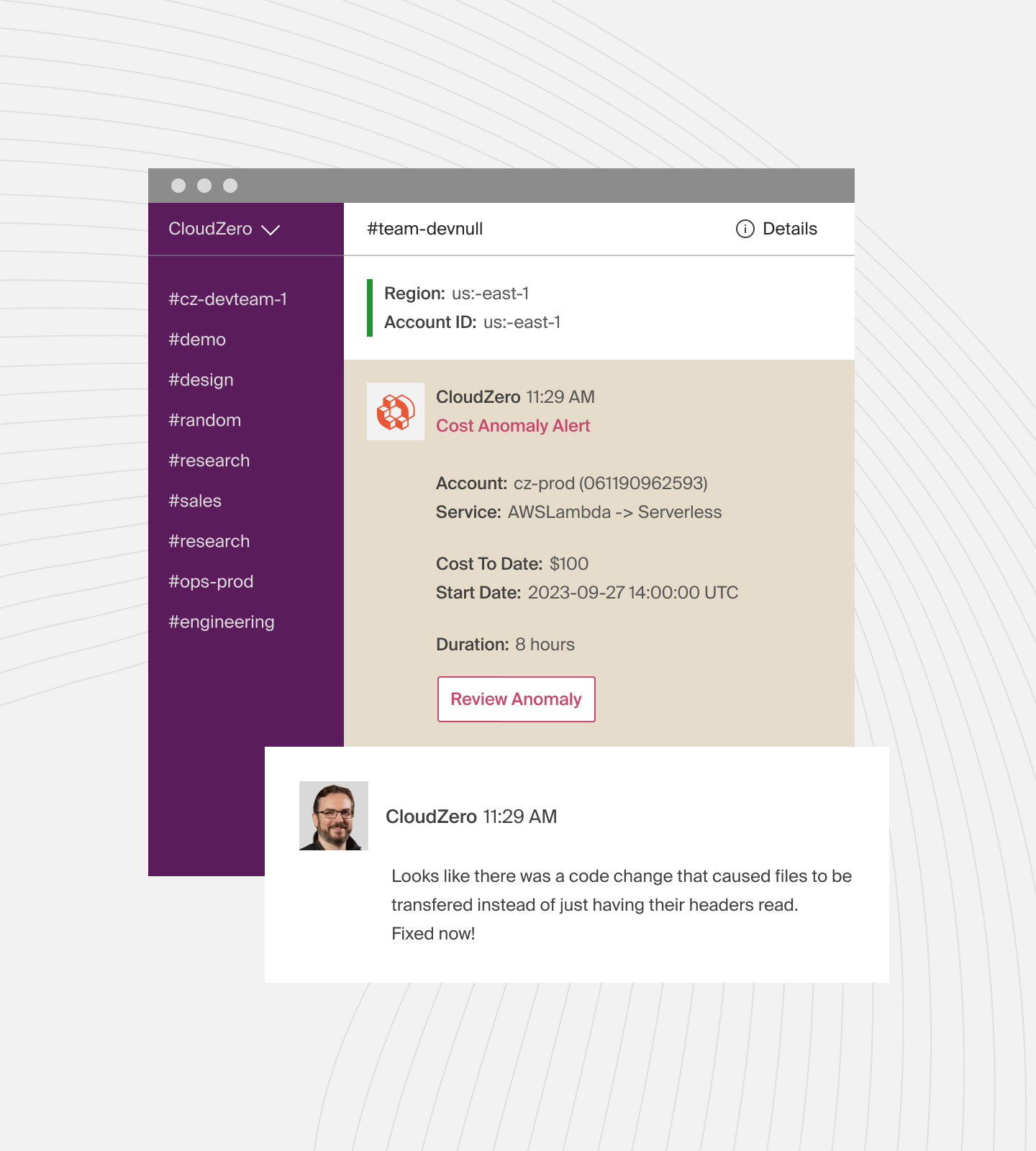
Other AWS Cost Management Best Practices Include:
Using Reserved Instances and Savings Plans
Use AWS Reserved Instances (RIs) and Savings Plans to save on long-term costs. These options provide significant discounts compared to On-Demand pricing. Analyze your usage patterns to determine which RIs or Savings Plans best fit your needs.
Use predictive analytics for cost forecasting
Use predictive analytics to forecast future AWS spending based on historical data and usage trends. CloudZero’s advanced analytics capabilities allow you to predict costs, enabling better budgeting and financial planning accurately.
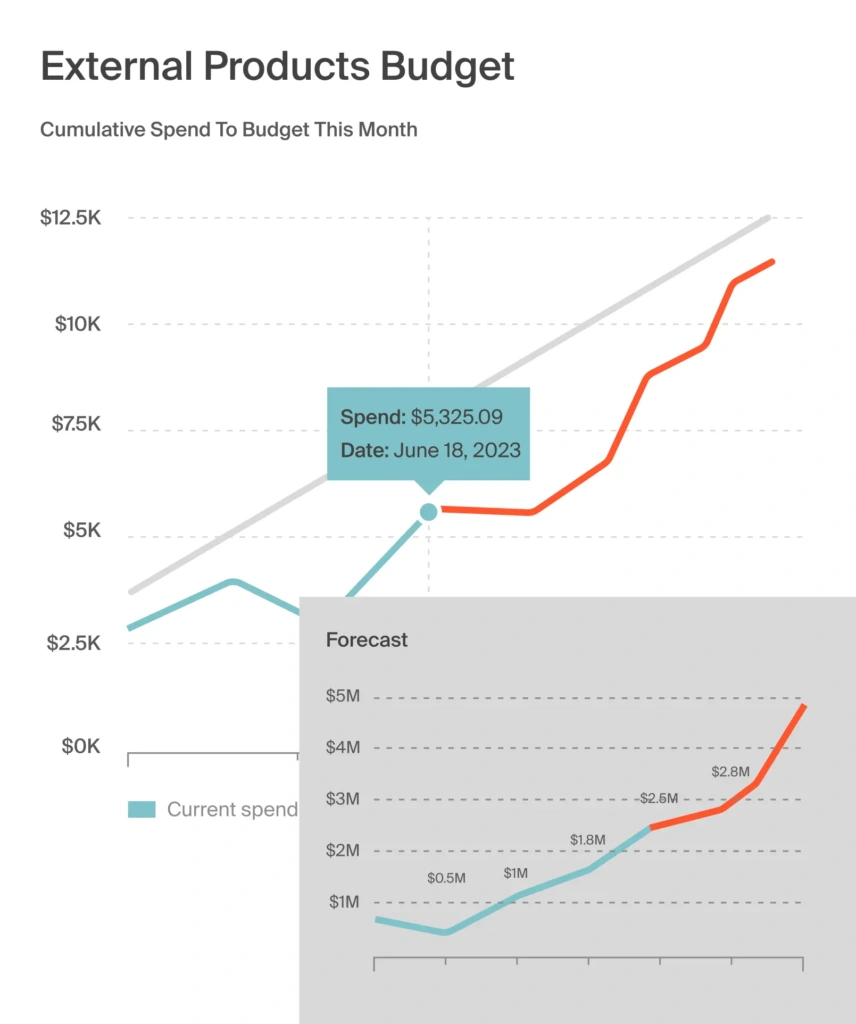
Optimize resource utilization
Regularly review and optimize your resource utilization. Use AWS Trusted Advisor and AWS Compute Optimizer to identify underutilized or idle resources. Right-size your instances and consider using Auto Scaling to match your resource allocation with demand. This practice reduces waste and ensures you only pay for what you need.
Take advantage of Free Tier and Spot Instances
Maximize the AWS Free Tier and Spot Instances to reduce costs. The Free Tier offers limited free usage of AWS services. Spot Instances provide discounts for unused EC2 capacity. Use Spot Instances for flexible, non-critical workloads to achieve substantial savings.
Review and adjust cost allocation
Review your cost allocation strategy often and ensure it matches your business goals. Use CloudZero to analyze your spending and identify trends or areas for improvement. Adjust your allocation methods as needed to reflect organizational structure changes or business priorities.
Regularly audit and optimize
Conduct regular audits of your AWS environment to identify opportunities for cost optimization. Use tools like AWS Config to track changes and ensure compliance with your cost management policies. Regular audits help control your AWS spending. They also uncover new ways to save.
Implement detailed cost reporting
Create detailed cost reports that provide insights into various aspects of your AWS spending. CloudZero can generate comprehensive reports that break down costs by service, team, project, or feature. This helps you identify cost drivers and optimization opportunities.
Educate your team
Ensure your team understands the importance of cost management and how their actions impact AWS spending. Provide training on best practices and tools for managing AWS costs. Encourage a culture of cost-awareness and accountability. This will lead to more efficient use of AWS resources.
We’ve discussed AWS cost management tools several times so far. Let’s examine a few more closely.
Top 3 AWS Cloud Cost Management Tools To Start Using Immediately
AWS provides several cost management resources and tools you can use immediately. But as your AWS workload increases, you may need to use a more advanced platform.
The following are three tools to consider, ranging from the most basic to the most advanced.
1. AWS Cost Explorer
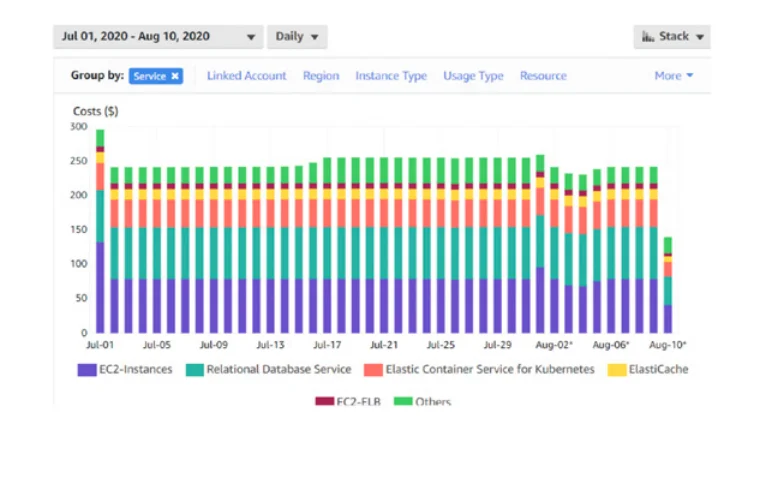
With Cost Explorer, your organization can visualize, understand, and manage cost and resource usage. It is accessible inside the Billing and Cost Management console, where you can create custom reports, analyze data at a high level, and discover cost trends.
Historical data is also available for up to 12 months, which can help you estimate future budget allocations.
2. ProsperOps
ProsperOps takes a traditional approach to cloud cost management and adds a modern touch. The tool provides recommendations on Reserved Instances (RI) and identifies AWS savings opportunities.
Using the cost tool is ideal if you are looking for an AI-driven, automated, and relatively simple way to improve your compute savings strategy. Once you’ve installed the tool and granted it access to your AWS payer account, it will conduct an AWS savings analysis.
Once you’ve seen where you’ve lost, saved, or can gain, it’ll attempt to maximize your AWS compute savings plan, RI, and leverage other discount programs to give you the highest possible savings.
But if you want to see precisely how much it costs you to support a specific customer, team, project, or product feature so you can tell where to make cuts without sacrificing system performance, the next tool can help.
3. CloudZero
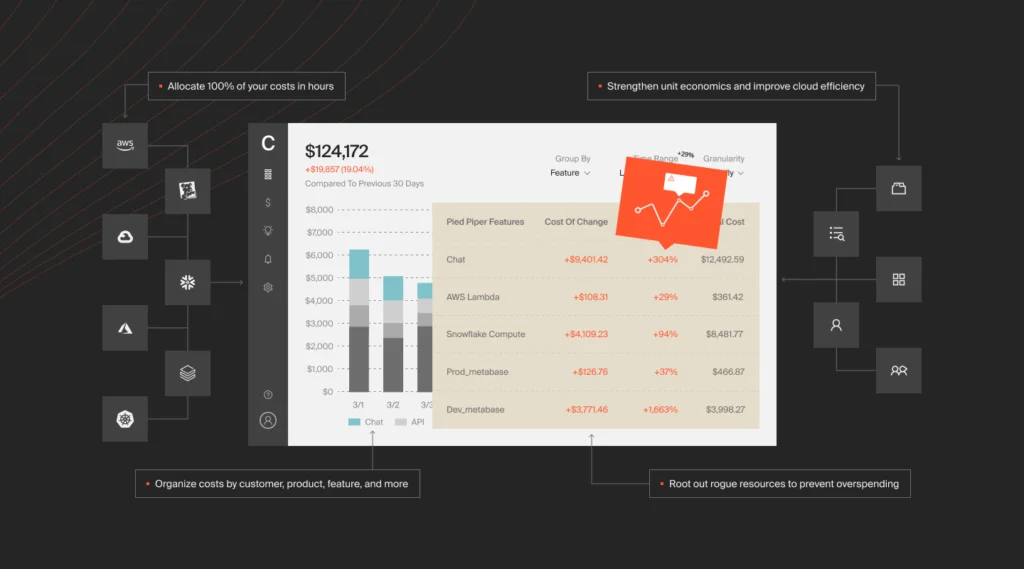
With CloudZero’s cloud cost intelligence platform, you can collect, aggregate, enrich, and align costs to specific business dimensions. It goes beyond providing a mere overview of cloud costs, offering you several granular insights that matter, such as cost per customer, cost per team, cost per project, and cost per feature.
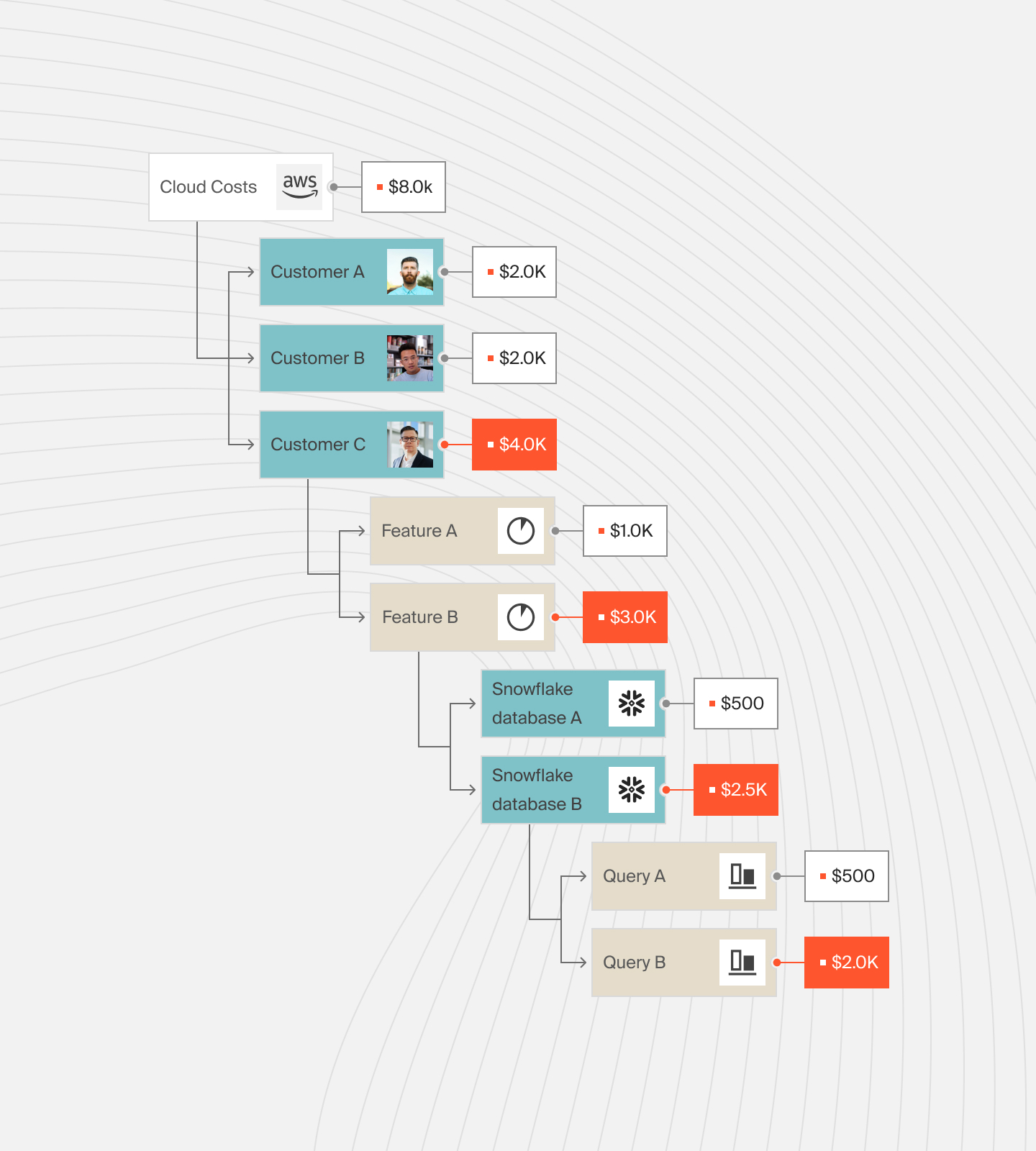
DevOps teams can use unit cost metrics to determine where to cut costs without sacrificing innovation, growth, or smooth customer experiences.
With CloudZero, engineers can see the cost impact of their work and make informed engineering and product decisions, keeping cost in mind.
 , to see how CloudZero can help you organize, analyze, and break down your AWS bill.
, to see how CloudZero can help you organize, analyze, and break down your AWS bill.
AWS Cost Management FAQs
1. What are AWS’s three pricing models?
AWS offers three primary pricing models:
On-Demand
With On-Demand, you pay for computing or database capacity by the hour or second with no long-term commitments or upfront payments.
Reserved Instances
With Reserved Instances, you can commit to using a certain amount of capacity for a one — or three-year term and receive a significant discount over On-Demand pricing.
Spot Instances
With Spot Instances, you can bid for unused EC2 capacity, saving up to 90% off On-Demand prices. However, AWS can interrupt this on short notice.
2. What is the AWS Billing and Cost Management console?
The AWS Billing and Cost Management console is a dashboard to manage your billing information and payment methods, view detailed cost and usage reports, and set up billing alerts. It helps you track your spending and optimize your costs.
3. How do I see all costs in AWS?
To see all costs in AWS, use the AWS Cost Explorer. This tool provides detailed visualizations of your costs and usage. You can view data by service, account, or tag. The AWS Cost and Usage Report offers comprehensive data for more detailed analysis.
4. How to use AWS Cost Estimator?
The AWS Cost Estimator helps you estimate the costs of your AWS services. Input your planned usage details into the estim


FinOps In The AI Era: A Critical Recalibration
What 475 executives told us about AI and cloud efficiency.