

Like every engineer, I’ve been doing a lot more with AI recently, from personal experiments to direct applications at work. I believe that the world of AI is riddled with both hype and real value, and the only way for me to distinguish one from the other is concrete experiments. I want to revolutionize the way I work, I want to make unprecedented contributions to my company, and I don’t want to incur unnecessary costs in the process.
In a period of experimentation, it’s not always easy to prioritize cost. To see experiments through, you have to spend money that doesn’t produce instantaneous returns. Efficiency can feel like a hard-to-define metric. But it’s not impossible to define, and as I felt in the midst of my personal experiments, it’s critical to try. As I play with AI, I see the meter running: I feel every token, cheap models produce cheap results, expensive models produce quality results, and, as ever, the cost-quality balance becomes central to the success of a project.
The good news: You don’t have to do it alone. As Claude can help you build the software, it can also help you optimize its costs.
I recently built a return on investment (ROI) calculator for my company, CloudZero. Its purpose is to improve conversion rates during our sales process. The more prospects can see what they’ll get in return for a CloudZero license, the more likely they’ll be to buy. ROI includes concrete things like hard-dollar savings and more nuanced factors like time savings, streamlined FinOps processes, and stronger unit economics. The goal would be to use the ROI calculator both during the sales process (immediately) and as a lead magnet on our website (eventually).
I used Claude from end to end, from planning all the way through deployment and postmortem analysis. In the process, I gained a lot of clarity around the real cost of model selection — and how I could build well and cost efficiently going forward.
How I Used Claude To Build And Assess The ROI Calculator
I’m a sales engineer (SE), so I’m not usually deploying code directly to production within the CloudZero environment. It was a big learning curve to get up to speed. I had to work with IT/security to make sure I understood our security requirements, define the AWS infrastructure I’d use to build it, create automation to plug into our CI/CD system, and deploy it according to engineering team standards.
What made that possible was doing it interactively using the most modern methods of AI-assisted app and code development — i.e., Claude Code. I used it for every step of the process, including:
- Planning: Assessing what I’d need to build the ROI Calculator successfully
- Deployment tests: Avoiding costly manual interventions post-deployment for stuff I could’ve caught during the planning stage
- Writing the code: Every line of it
- Infrastructure-as-code authoring: Writing the IaC templates to make these deployments
- Monitoring: Validating the efficacy of the app before, during, and after deployment
Critically, I had to choose a model for every stage of this process, and every sub-stage therein. When in doubt, I defaulted to the largest, most expensive model, Opus 4.6. Even if it was arguably too large/expensive, doing so gave me peace of mind that I’d be producing high-quality code.
I knew this peace of mind might be costing me more than it should have. But still being new to this process, I didn’t know how to evaluate each model myself. So, I asked Claude.
Here’s the actual prompt I used:
> “Spawn a subagent to create a report on how well I used subagents and skills in this session. Specifically look at context management, model and token usage.”
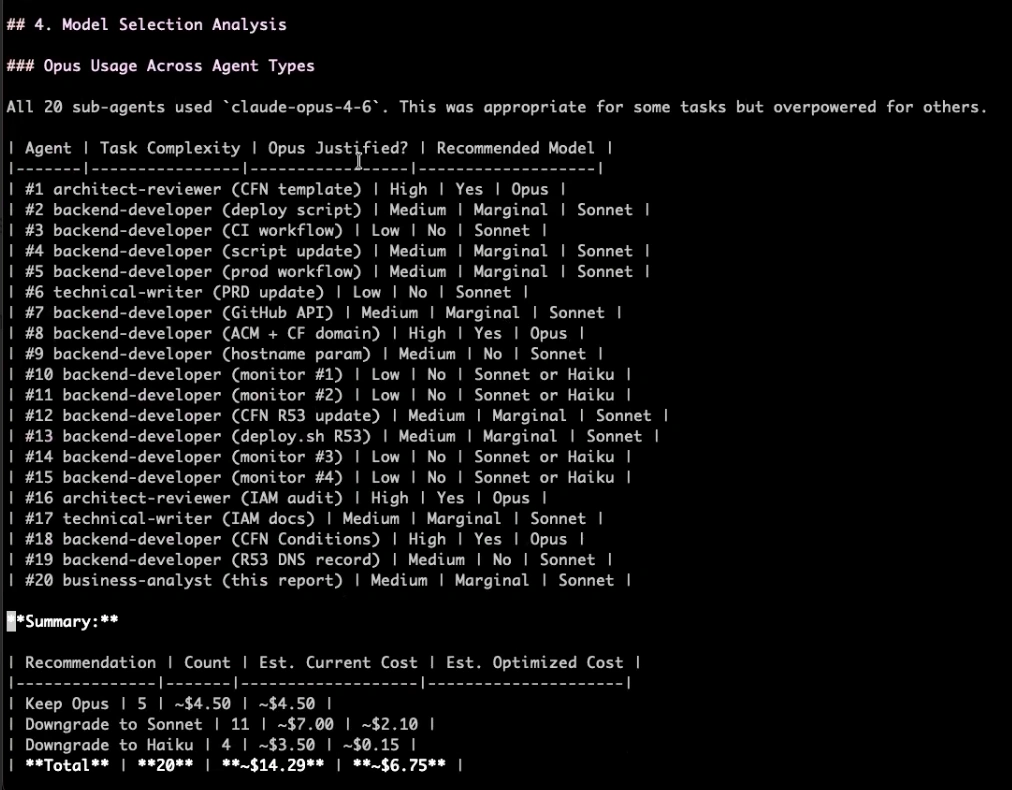
In numerous cases, I’d chosen the right model. In others, I’d chosen an unnecessarily expensive model. Claude assessed all of these and put them in a big list for me. The report even included my cost per line of code: $0.0196. Here’s the Model Selection Analysis part of Claude’s report (look at the “Opus Justified?” and “Recommended Model” columns especially):

Research Report
FinOps In The AI Era: A Critical Recalibration
What 475 executives told us about AI and cloud efficiency.
Takeaways
- I don’t always need Opus. Sometimes Sonnet is plenty, and in certain cases, it actually yields better results than its heavier-duty counterpart.
- I can build this knowledge into Claude. I put the results from this efficiency report into Claude to teach it to use the appropriate model next time.
- I’m always gonna ask for a session report like this. I can trust myself to remember everything I learned from these sessions, or I can trust Claude to remember 100% of the lessons 100% of the time and keep me honest as I build in the future.
Now, we’ve got our ROI calculator, and I’ve got a slew of new efficiency standards built into Claude Code.
Now, I’d love to hear from you. How do you measure the value you’re getting from novel AI uses? Do you measure that value at all? Do you think cost per line of code is an interesting metric, or do you have a better one? We’re all learning at the same time; I’d genuinely love to hear.
Onward and upward.


FinOps In The AI Era: A Critical Recalibration
What 475 executives told us about AI and cloud efficiency.


