Running multiple LLMs without aggregation can feel like managing five different clouds with no dashboard. Sure, you can make it work, but you won’t like the bill.
And most SaaS teams didn’t start with a multi-LLM strategy. It just happened. You added one model for reasoning, another for summarization, or maybe a fine-tuned version for customer support.
Fast-forward six months, and your AI stack looks like a tangle of APIs. And each charges tokens on its own terms. Some teams call it herding API cats. But using AI API aggregation can help.
By intelligently routing all your AI calls through a unified layer, you can orchestrate multiple models, control your API spend, and gain end-to-end visibility. All without slowing down innovation. How?
In the next few minutes, we’ll explore how a robust unified API solution can help SaaS teams tame multi-model complexity (and how you can turn your AI cost sprawl into a well-governed growth engine).
What Is AI API Aggregation?
AI API aggregation is about creating one intelligent control layer for all your large language models (LLMs). Instead of every team integrating directly with the OpenAI, Anthropic, Gemini, and Mistral APIs, each with different authentication, rate limits, and billing models, an aggregator provides a single, unified endpoint that does the heavy lifting for you.
A robust AI API aggregator standardizes requests, normalizes responses, and routes each workload to the best-performing or most cost-efficient model based on your policies. And all of that, without your folks needing to rewrite code or juggle multiple SDKs.
Under the hood, a typical AI API aggregator will include:
- A unified endpoint that handles all model calls and normalizes input/output formats.
- Routing intelligence that determines which model to invoke based on cost, latency, or accuracy.
- A centralized billing and telemetry mechanism for tracking usage, token consumption, and performance metrics.
- Access controls and guardrails for authentication, compliance, and data governance.
From an AI cost management perspective, the aggregator gives your finance, FinOps, and engineering leaders a common lens for viewing model performance and spend. And that can help you bridge the gap between technical experimentation and financial accountability.
Report
Finance needs to prove AI’s return: CloudZero report
260 senior finance leaders (more than half CFOs) told us why the speed of seeing AI spend, not the size of it, separates who pulls ahead on AI from who gets burned.
Why Companies Use Multiple LLMs (And Why It Gets Expensive)
One reason. No single large language model is great at everything.
Some excel at reasoning and coding. Others shine at summarization, content generation, or multilingual analysis. So naturally, as AI workloads grow more specialized, more SaaS teams are using multiple models, choosing each for what it does best.
Before you know it, you’re managing an AI zoo of multiple vendors, SDKs, APIs, pricing tiers, and token meters. All running in production.
- Teams want freedom to test and switch between models as performance or pricing evolves.
- Multi-LLM setups provide redundancy. If one model throttles or goes down, its workloads can fall back on another.
- Some models are simply cheaper for specific workloads. And using the right one for the job can cut inference costs by double digits.
The cost of that is complexity. For engineering, that means more integrations and maintenance. For finance, it means unpredictable bills and no easy way to compare model ROI.
But with robust API aggregation, you can turn what was once a messy web of AI connections into an organized, measurable, and cost-aware system built for scale.
Next, let’s look at what happens when you don’t have that unifying layer.
The Challenges Without LLM Aggregation
Without AI API aggregation, you end up with the perfect storm of cost opacity, operational overhead, and performance uncertainty.
Issues with tracking usage and related costs
Every LLM provider measures and bills usage differently. Think of by token, compute unit, or request. Multiply that across five APIs, and it becomes nearly impossible to tie costs back to a specific product feature, individual customer, or business unit.
That makes it tricky to tell exactly who and what is driving certain costs, and, importantly, why, so you can fix waste and improve your AI ROI.
That disconnect is also why FinOps teams struggle to forecast AI budgets or explain why one model costs more than another.
Without a unified view, cost anomalies can go unnoticed until the invoice lands. And by then, it’s too late to course-correct.
Operational overhead and security risks ramp up
Multiple SDKs. Multiple auth systems. Multiple endpoints. Every new integration adds surface area for failure and security vulnerabilities.
For example, your DevSecOps team can struggle to enforce uniform prompt handling, data residency, or access controls when every model plays by its own rules.
Even minor updates, like a provider changing rate limits, can ripple through your stack, breaking automation and increasing your maintenance costs. Aggregation helps you centralize these moving parts into a single, consistent layer.
Gaps in accuracy, quality, and consistency start to crop up
One model might return concise, high-confidence results. Another may generate longer, more verbose answers. When your routing is manual, you can’t standardize output quality or compare cost versus accuracy across workloads.
That inconsistency can quietly erode trust in the models and in your SaaS cost reporting.
Finance might assume cheaper means better value, while engineers know that accuracy failures have hidden costs, including debugging, re-runs, and re-training.
Overall, the lack of aggregation blurs visibility on both sides. Engineering fights complexity. Finance fights uncertainty. And your organization’s bottom line ends up paying for both.
Next, let’s explore how aggregation brings cost management and accuracy together — yes, without forcing teams to choose between innovation and AI cost optimization.
Why Accuracy In API Aggregation Matters Even More In AI Cost Management
When you unify model endpoints under one layer, you gain visibility not only into what each API is doing but also into how much value each call generates per dollar spent. But that insight only holds if your aggregation layer is accurate.
If your aggregation platform misattributes usage or rounds token counts inconsistently, every downstream decision — from routing to budgeting — becomes unreliable.
Inaccurate aggregation can mislead your team in two key ways:
- Operationally, you might route too many workloads to a “cheap” model that produces lower-quality outputs, driving up hidden rework costs.
- Financially, you could over- or under-allocate costs to the wrong product, feature, or team, skewing your view of ROI and efficiency.
The point here isn’t just to centralize your data, but to also normalize and enrich it so comparisons between models, vendors, and workloads are fair, accurate, and actionable.
And in cloud and SaaS operations, accurate API aggregation enables you to answer questions like:
- Which model provides the best output-to-cost ratio?
- Which business unit is driving our LLM costs?
- What’s our cost per thousand generated tokens, and is that sustainable?
When aggregation is precise, you can analyze, allocate, and optimize AI costs with the same rigor as you do for cloud infrastructure costs.
Also see: How To Do AI Cost Optimization Strategies For AI-First Organizations
Accurate AI cost aggregation also enables proactive controls. Think of token quotas, routing thresholds, and performance-based cost triggers. These prevent runaway experiments, enforce consistency, and give both engineering and finance real-time cost clarity instead of postmortems.
How To Implement An LLM Aggregator For AI Cost Control
You want it to decide which model to call, when, and why, while balancing accuracy, latency, and cost, and enforcing governance and AI API cost visibility.
And like many teams, you may start to ask, “Do we build this ourselves, or buy a unified API solution that does it for us?”
Building vs. buying an AI API aggregator
Building your own aggregator gives you total control. You can fine-tune routing logic, implement custom caching, and tailor cost tracking exactly to your business model. If you’re already running a mature MLOps or DevSecOps setup, that flexibility can be powerful.
But it also means maintaining integrations for every model you use. Think of handling API versioning, token accounting, data privacy, and pricing changes. And every new provider adds another moving part. The moment OpenAI tweaks a rate limit or Google’s Gemini launches a new endpoint, your engineers are back in the code.
Buying or adopting a unified API solution lets you trade some flexibility for speed and reliability. These platforms often come with built-in routing logic, usage analytics, and model coverage across major cloud service providers and AI vendors like OpenAI, Anthropic, and Mistral.
Picture this:
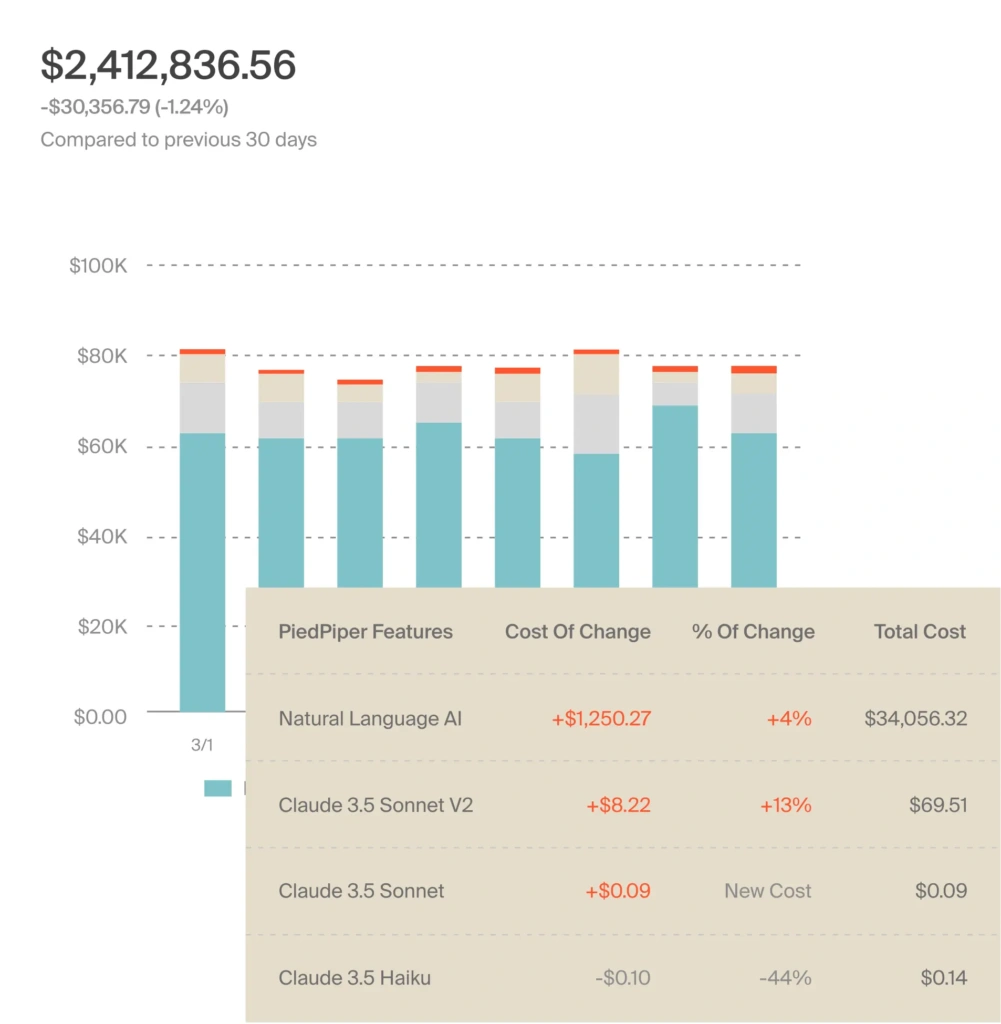
Getting a single view of the different AI services you are using helps you keep organized, beat overwhelm, and prevent blind spots
For teams that value time-to-value over absolute control, that’s a clear win.
Related read: CloudZero Is The First Cloud Cost Platform To Integrate With Anthropic. Here’s What That Means For You
So, here’s a good rule of thumb.
If your team already manages its own model orchestration or observability stack, building makes sense. If not, buying prevents you from reinventing the wheel — see our guide to cloud cost management tools for platforms that can serve as a foundation.
Now consider these architectural factors that could make or break your AI API aggregator
No matter how you implement it, your architecture needs five foundational layers:
- A unified API Gateway: This is a single endpoint for all your model requests. It’ll standardize input/output and enforce authentication.
- The routing Engine: This decision-maker chooses the right model based on cost, performance, accuracy, or your other policy rules.
- Usage and cost telemetry: This helps you track every request, from token counts and latency to provider costs, and normalizes the data for reporting.
- Governance and security controls: These are for handling rate limits, data residency, and prompt compliance across vendors.
- Observability and FinOps layer: You’ll also want a way to surface usage patterns, cost anomalies, and ROI trends in real time.
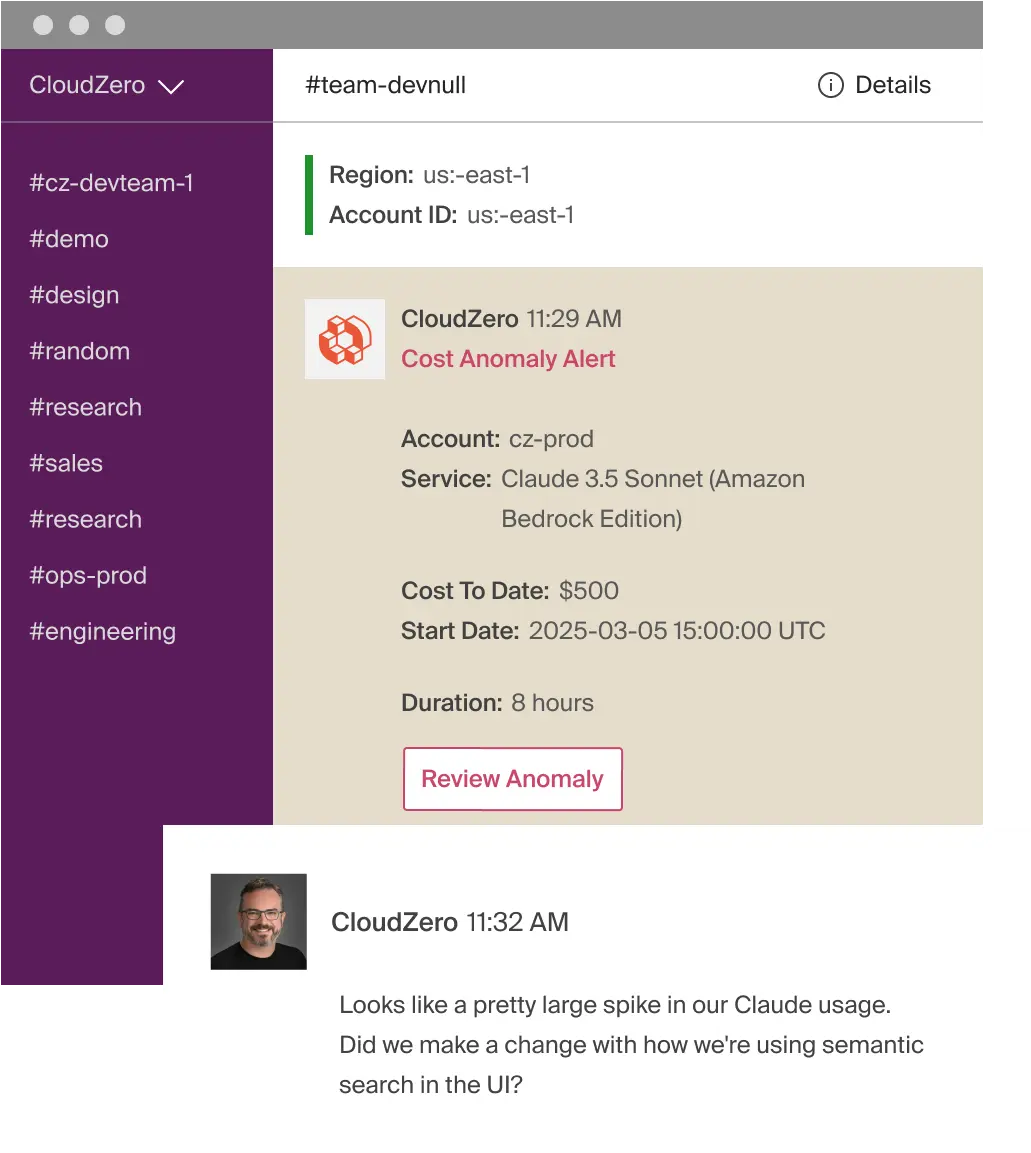
CloudZero’s real-time cost anomaly detection alerting system delivers immediately actionable insights so you can fix issues before they eat through your margins
This structure will empower your engineers to innovate freely without losing sight of financial impact, and help your finance folks see cost drivers without slowing innovation.
Some pitfalls to watch out for here
Many teams underestimate the “plumbing” work. For example, if your routing engine prioritizes cost over quality, you risk flooding your pipeline with poor results that cost more to fix than they saved.
If your cost telemetry isn’t granular, you’ll miss key optimization opportunities or attribute spend to the wrong products. Instead, you want an aggregator that helps you surface and correlate your AI costs like this:
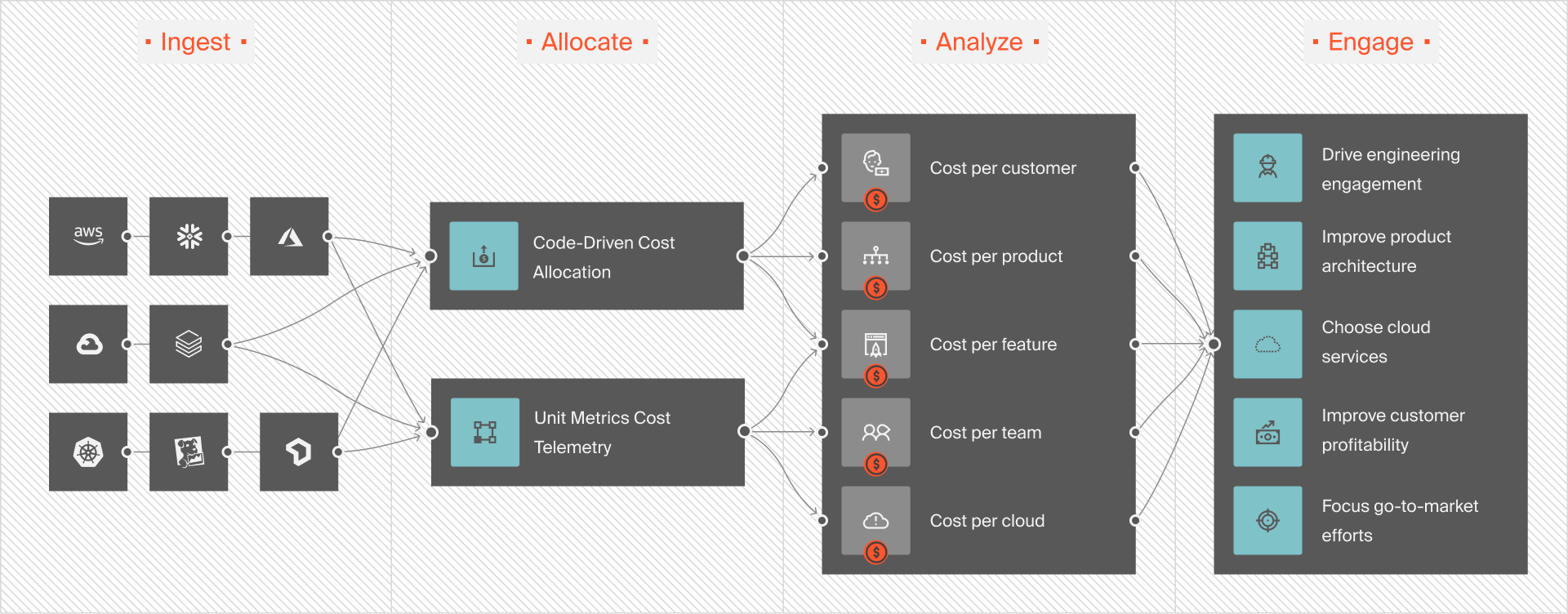
And perhaps most importantly, if finance and engineering don’t collaborate to achieve shared visibility, your aggregator becomes yet another silo rather than the bridge it’s meant to be for both.
Overall, you’ll want to build (or buy) your aggregator like a cost-aware AI system. Instrumented. Observable. Always learning where value truly lives.
That kind of intelligence sets the stage for what’s next, as we’ll see below.
The Future Of Multi-LLM Cost Management
As AI adoption deepens, the challenge won’t just be getting models to talk to your systems, but also getting them to talk to each other.
From integration to orchestration
API aggregation laid the groundwork for multi-model integration. The next evolution is orchestration, a stage where routing isn’t static but adaptive.
Soon, teams will be able to choose models dynamically based on context, cost efficiency, accuracy benchmarks, or even user-level personalization.
Imagine an orchestrator that automatically routes summarization tasks to Claude for nuance, reasoning to GPT-4 for depth, and low-latency classification to Mistral. And all while optimizing for cost and performance in real time.
That’s the logical outcome of unified aggregation done right.
Agentic and Composable AI Pipelines
As agentic AI matures, organizations will move toward composable workflows where LLMs reason, verify, and refine one another’s outputs.
One model might draft, another review, and another evaluate, all coordinated through a central aggregation layer.
So, without fine-grained visibility into token usage, routing accuracy, and cross-model dependencies, your API costs could scale faster than the insight you’re getting.
Future aggregators will therefore need to merge orchestration with real-time cost intelligence. That way, teams can innovate continuously without burning their bottom line.
The Rise of AI FinOps
FinOps principles are expanding beyond cloud infrastructure and into AI itself.
Forward-thinking teams will move from just analyzing API invoices to modeling AI costs per output, per interaction, per decision — applying the same rigor to AI as they do to cloud cost optimization.
Engineering and finance will share dashboards that correlate spend, accuracy, and business outcomes.
Instead of asking, “How much did we spend on OpenAI?” they’ll be asking, “What value did those tokens create?” or “Is this AI feature profitable?”
This new AI FinOps frontier will help them align experimentation with measurable, defensible profitability.
Aggregation as Strategic Infrastructure
As the AI ecosystem fragments, AI API aggregation will evolve from a convenience into strategic infrastructure, even as critical as CI/CD or observability in modern software delivery.
It will underpin governance, accelerate experimentation, and provide the visibility needed to scale AI responsibly.
Organizations that master this early will iterate faster, deliver more accurate results, and protect their margins with real-time cost intelligence.
AI API Aggregation FAQs
What is AI API aggregation?
AI API aggregation is the practice of routing all your large language model (LLM) calls through a single unified layer — instead of integrating directly with each provider’s API separately.
Rather than managing different authentication, rate limits, billing models, and SDKs for OpenAI, Anthropic, Gemini, and others, an aggregator provides one standardized endpoint that handles all of that behind the scenes.
From a cost management perspective, it also gives finance and engineering a shared view of model performance and spend — which is often the harder problem to solve.
What is an LLM aggregator?
An LLM aggregator is the software layer that implements AI API aggregation. It intercepts model requests, routes them to the appropriate provider based on your rules (cost, latency, accuracy, or availability), normalizes the responses, and tracks usage for billing and analytics.
Well-known examples include LiteLLM and OpenRouter on the open-source and developer side. Enterprise teams often build custom aggregators or adopt cloud cost platforms that can ingest and normalize spend data across providers.
Why do companies use multiple LLMs?
No single model is best at everything. Organizations typically end up running multiple LLMs because different models perform better on different tasks — one for reasoning, another for summarization, another for customer-facing generation — and because multi-model setups provide redundancy if one provider throttles or goes down.
The problem is that each model has its own pricing, billing structure, and SDK. Without a unifying layer, the result is fragmented visibility, unpredictable costs, and significant engineering overhead.
How does LLM routing work in an aggregator?
An aggregator’s routing engine evaluates each incoming request and decides which model to invoke based on policies you define. Common routing criteria include cost per token, expected latency, model accuracy benchmarks, and workload type.
Some aggregators support dynamic routing — choosing models in real time based on live performance data — while others use static rules configured at setup. Either way, the goal is to match each workload to the most appropriate (and cost-efficient) model without requiring developers to hardcode those decisions.
What’s the difference between building and buying an LLM aggregator?
Building gives you total control over routing logic, cost tracking, and integrations — but means your engineers own every integration, API version update, and pricing change across all providers you use.
Buying (or adopting an existing platform) trades some flexibility for speed. You get built-in routing, usage analytics, and model coverage without reinventing the plumbing. For most teams, the build vs. buy decision comes down to whether you have mature MLOps infrastructure already in place. If you don’t, buying almost always wins on time-to-value.
How does AI API aggregation help with cost management?
Without aggregation, AI costs are scattered across provider invoices with no common unit of measure. You can’t easily compare cost per output across models, attribute spend to specific features or teams, or detect anomalies before they hit your bill.
A well-instrumented aggregator normalizes token counts, latency, and costs into a consistent format — making it possible to ask questions like “which model gives us the best output-to-cost ratio?” or “which team is driving our inference costs?” That shift from reactive billing review to proactive cost intelligence is the core value proposition.
Keep AI Spend Tracking Accurate, Efficient, And Within Your Control
As your AI stack grows, so does the complexity from new models, APIs, and billing rules that quietly add friction and opacity. Without a unifying layer, those parts eventually pull in opposite directions.
The teams that win the AI era won’t be the ones who integrate the most models, but the ones who integrate them intelligently.
With CloudZero, you get a single source of truth for your SaaS and AI costs. You can ingest spend data from any AI service, cloud, PaaS, or SaaS provider, normalize it in a common data model, and view it all through a single, clear pane of glass.
No waiting for connectors or “Coming Soon” integrations. Just plug in via the AnyCost API and start seeing how your API spend trends in real time.
From cost per user, per AI service, or per dev stage, CloudZero delivers granular, actionable insights that show exactly where your costs are, and why. Meaning, you can act before anomalies hit your invoice or margins.
See it for yourself (just as leaders like Duolingo, Drift, and Moody’s are doing with CloudZero). Risk-free.  to start unifying your cost visibility across AI models, APIs, and cloud workloads – and turn your data chaos into strategic control.
to start unifying your cost visibility across AI models, APIs, and cloud workloads – and turn your data chaos into strategic control.











