
Quick Answer
Claude pricing in 2026 spans seven tiers: Free ($0), Pro ($20/month), Claude Max 5x ($100/month), Max 20x ($200/month), Team Standard ($25/seat/month), Team Premium ($125/seat/month), and Enterprise (custom). Claude API pricing is per token: Opus 4.7 costs $5/$25, Sonnet 4.6 costs $3/$15, and Haiku 4.5 costs $1/$5 per million input/output tokens. Prompt caching cuts input costs by up to 90%. The Batch API saves 50% on both input and output.
How much does Claude cost when the pricing page meets reality? Whether you are an individual evaluating Claude Pro, a team lead comparing Team plans, or a platform engineer running inference at scale, the answer depends on how you use it, not just what you subscribe to.
A writer on Claude Pro pays $20/month and rarely thinks about tokens. A development team running Claude Code across 10 engineers pays $150–$250 per developer per month and thinks about tokens constantly. An enterprise running inference pipelines through the Anthropic API could pay $5,000–$50,000/month, and the CFO thinks about tokens in their sleep.
The pricing page gives you rates. It does not tell you which costs are producing business value and which are burning money on experiments nobody remembered to shut down. That is the difference between knowing the price and understanding the cost, and the question CloudZero helps you answer.
Who Makes Claude?
Claude is an AI assistant built for natural language reasoning, coding, and content generation. It is developed by Anthropic, an AI safety company founded in 2021 by former OpenAI researchers Dario and Daniela Amodei. By early 2026, Anthropic had reached approximately $14 billion in annualized revenue, closed a $30 billion Series G at a $380 billion valuation, and secured strategic partnerships with AWS, Google Cloud, Microsoft, and NVIDIA. A potential IPO as early as October 2026 is under evaluation, according to multiple reports.
The current model lineup consists of Claude Opus 4.7 (flagship reasoning), Claude Sonnet 4.6 (balanced mid-tier), and Claude Haiku 4.5 (fast and cost-efficient). All three are available through the Anthropic API directly, as well as through AWS Bedrock, Google Cloud Vertex AI, and Microsoft Azure AI Foundry.
Understanding who builds Claude matters for pricing because Anthropic’s business model shapes its pricing structure. Consumer subscriptions fund accessibility. API token billing funds the compute. And Claude Code, which has reached approximately $2.5 billion in annualized revenue, is rapidly becoming the revenue engine that subsidizes everything else. That context explains why the subscription tiers are structured the way they are.
Report
Finance needs to prove AI’s return: CloudZero report
260 senior finance leaders (more than half CFOs) told us why the speed of seeing AI spend, not the size of it, separates who pulls ahead on AI from who gets burned.
Claude Subscription Plans
If you are searching for Claude AI pricing or comparing Claude pricing plans, Anthropic offers four individual tiers:
| Plan | Price | Models | Claude Code | Context window | Key features |
| Free | $0 | Sonnet 4.6, Haiku 4.5 | No | 200K tokens | Web, iOS, Android, desktop; daily usage limits |
| Pro | $20/mo ($17/mo annual) | All models incl. Opus | Yes | 200K tokens | Projects, Google Workspace, file creation, code execution, web search |
| Max 5x | $100/mo | All models incl. Opus | Yes | 500K tokens | 5x Pro usage, priority access, early features, Research mode |
| Max 20x | $200/mo | All models incl. Opus | Yes | 500K tokens | 20x Pro usage, highest priority |
Is Claude free? Yes, the Free tier provides access to Sonnet 4.6 and Haiku 4.5 with daily usage limits. No credit card required. For most professional use cases, Free runs out of road by mid-morning.
Claude Pro costs $20 per month, or $17 per month when billed annually. It remains the standard entry point for professional use. Pro includes all models and Claude Code, but usage operates on rolling windows — hit your limit and you wait. For intensive Claude Code sessions, Pro users regularly hit those limits within hours, which is less a flaw in the pricing and more a testament to how addictive agentic coding becomes once you start.
That frustration is what the Max tiers solve.
What Is Claude Max?
Claude Max is a higher-tier subscription plan from Anthropic that provides 5x or 20x the usage of Claude Pro, with priority access during high-traffic periods. It is Anthropic’s answer to the single loudest complaint from Pro subscribers: running out of usage in the middle of a coding session that was going well.
Max 5x ($100/month) provides five times the Pro usage allowance and priority routing during high-traffic periods. Max 20x ($200/month) provides twenty times the allowance — designed for developers who treat Claude Code as their co-pilot all day, every day.
Is the cost worth it? Anthropic’s own enterprise data shows that 90% of Claude Code users stay below $30 per active day. If you are in the top 10% of usage, Max 20x at roughly $6.50/day is a fraction of equivalent API billing. If you are in the bottom half, Pro is sufficient and Max is a subscription to peace of mind you do not need.
The break-even between Claude Pro and API billing sits at approximately 3.7 million tokens per month. Below that, the subscription wins. Above it, the API gives you more control and no ceiling.
For teams that need more than individual plans, Anthropic offers organizational tiers with admin controls and centralized billing.
Claude Team And Enterprise Plans
Not every Claude deployment is one developer with a terminal. When 50 engineers need access with SSO, compliance, and a single invoice, the Team and Enterprise plans apply.
| Plan | Price | Models | Claude Code | Key features |
| Team Standard | $25/seat/mo | Sonnet 4.6, Haiku 4.5 | Limited | Admin console, SSO (SAML), usage dashboards, shared projects |
| Team Premium | $125/seat/mo | All models incl. Opus | Full access | Everything in Standard + Opus, 500K context, full Claude Code |
| Enterprise | Custom | All models | Full access | Custom usage limits, HIPAA eligibility, data residency, dedicated support |
The most common mistake with Claude enterprise pricing: buying Team Standard for developers and expecting parity with individual Pro. Team Standard runs on Sonnet and Haiku only, no Opus, limited Claude Code. It is the “we have Claude at home” of enterprise plans. If your developers need Opus and full Claude Code, the choice is Team Premium at $125/seat or Enterprise with negotiated terms.
Self-serve Enterprise starts at $20/seat with API usage billed separately. Volume discounts are available for high-usage customers. EU data residency is available for the API; Azure AI Foundry EU inference support is also coming up.
Subscription plans cover chat and desktop use. But the fastest-growing cost center for most Anthropic customers is not chat, it is Claude Code.
Here is a complete guide to Claude Code pricing.
Claude Cowork Pricing
Claude Cowork, Anthropic’s desktop agent for file and task management, follows the same subscription structure as Claude Code. Available on Pro and above, with usage consuming your plan’s conversation budget. Claude Cowork pricing is not billed separately; it draws from the same token pool as chat and Claude Code, which means your $20/month Pro plan is now shared across three consumption surfaces.
For teams running all three; chat, Code, and Cowork, across a development organization, the total Anthropic spend adds up in ways that a subscription price alone does not capture.
CloudZero’s AI cost management tracks all three in a single view, breaking costs down by team, product, and business function so you know which tool is consuming what.
With the subscription and agent pricing covered, the other half of the equation is the API, where most production spend actually lands.
Claude API Pricing by Model
Claude API pricing is billed per token across three current-generation models. All prices per million tokens (MTok).
| Model | Input/MTok | Output/MTok | Context | Best for |
| Claude Opus 4.7 | $5.00 | $25.00 | 1M tokens | Deep reasoning, complex coding, agentic workflows |
| Claude Opus 4.6 | $5.00 | $25.00 | 1M tokens | Same capabilities at identical pricing |
| Claude Sonnet 4.6 | $3.00 | $15.00 | 200K tokens | Balanced cost-performance for production workloads |
| Claude Haiku 4.5 | $1.00 | $5.00 | 200K tokens | High-speed, low-cost: classification, routing, simple tasks |
The Anthropic Claude API pricing story in 2026 is defined by one event: the 67% Opus price reduction from $15/$75 (Opus 4.1) to $5/$25 (Opus 4.6) at launch in February. Opus 4.7 maintained those rates. Claude Opus pricing now sits in the same range as OpenAI’s GPT-4o, which means teams that previously avoided Opus on cost grounds need to reassess. If you are comparing against Claude 3 pricing from the original generation, current Opus costs roughly one-third the price for substantially better performance.
Anthropic pricing overall has moved in one direction: down on per-token rates, up on consumption. The models are cheaper. The features that use them; Claude Code, agentic workflows, 1M-token context, eat tokens faster than ever. Understanding your total Claude cost means tracking both sides of that equation.
Critical caveat on Opus 4.7: The new model ships with an updated tokenizer that can generate up to 35% more tokens for the same input text compared to Opus 4.6. Same rate per token, more tokens per request.
Other charges to watch: Extended thinking tokens are billed at output rates even when not returned in the response. Web search and code execution tools each carry per-use charges. These compound quickly in agentic workflows that chain multiple tools per request.
How To Reduce Claude API Costs
Three mechanisms can cut your effective Claude cost by 40–80% without touching quality. Prompt caching takes 15–30 minutes to configure for a typical project. Batch API integration requires a few hours of engineering. Model routing needs a one-time architecture decision. Most teams have implemented zero of them, which is roughly the same number of teams that review their Claude invoices line by line.
Prompt caching (up to 90% savings)
Prompt caching stores reused context; system prompts, CLAUDE.md files, project documentation, so you pay full price once, then 90% less on subsequent reads. For Claude Sonnet pricing, that means cached reads at $0.30/MTok versus $3.00 standard. Cache writes carry a 25% premium over standard input, so the math favors caching on any content reused more than twice.
For teams running Claude Code with consistent project context, this is the single highest-impact optimization, and the one most teams have not implemented yet.
Batch API (50% discount)
The Batch API processes requests asynchronously with results within 24 hours, at exactly half the standard token price. A team processing 500,000 documents monthly saves $750–$2,250/month by routing eligible workloads to batch.
No quality difference, only timing. Best for document processing, data enrichment, nightly analytics, and content generation. Not for anything that needs a response before the user loses patience.
Model routing (choosing the right model per task)
Not every task needs Opus. Claude Haiku pricing at $1/$5 per MTok is 80% cheaper than Sonnet and 95% cheaper than Opus. Route classification, summarization, and extraction to Haiku. Reserve Opus for complex reasoning and multi-step coding. A well-designed routing layer cuts total spend by 40–60% with no measurable quality loss on routed tasks.
These three optimizations are table-level savings. Knowing which features, teams, and customers are consuming those tokens is a different problem, and the one that determines whether your AI investment is paying off or just running up a tab.
Claude Vs. OpenAI Vs. Google Gemini Pricing
If you are evaluating Claude AI pricing against the alternatives, or searching Claude vs ChatGPT to decide where to spend, here is the head-to-head comparison. For deep dives on each, see our guides to OpenAI pricing, ChatGPT pricing, and Gemini API pricing.
| Dimension | Claude (Anthropic) | ChatGPT / OpenAI | Gemini (Google) |
| Free tier | Sonnet 4.6, Haiku 4.5 | GPT-4o mini | Gemini 2.0 Flash |
| Individual paid | Pro $20/mo, Max $100–200/mo | Plus $20/mo, Pro $200/mo | Advanced $19.99/mo |
| Team plan | $25–125/seat/mo | $25–30/seat/mo | $19–25/seat/mo |
| Flagship API (input/MTok) | Opus 4.7: $5.00 | GPT-4o: $2.50 | Gemini 2.5 Pro: $1.25 |
| Flagship API (output/MTok) | Opus 4.7: $25.00 | GPT-4o: $10.00 | Gemini 2.5 Pro: $10.00 |
| Mid-tier API (input/MTok) | Sonnet 4.6: $3.00 | GPT-4o mini: $0.15 | Gemini 2.0 Flash: $0.10 |
| Coding agent | Claude Code (Pro+) | Codex (API) | Jules (preview) |
| Max context | 1M tokens (Opus) | 128K tokens | 1M tokens |
| Prompt caching savings | 90% on reads | 50% on reads | Context caching available |
| Batch discount | 50% | 50% | No standard batch tier |
Anthropic is not the cheapest per token. OpenAI and Google undercut on mid-tier and flagship rates. Claude’s advantages are context window depth (1M tokens on Opus versus 128K for GPT-4o), caching savings (90% vs. 50%), and Claude Code’s maturity as a production coding agent.
As one of CloudZero’s engineers recently observed: “The right question isn’t which model costs less per token. It’s which model costs less per business outcome. A cheaper model that requires twice as many iterations is not actually cheaper.”
The pricing page that matters is not the one with the lowest number. It is the one that shows the lowest cost for the output quality your business actually needs, and the only way to know that is to measure it.
How CloudZero Manages Claude and AI Costs
Claude pricing is transparent. Claude costs are not. And the distance between those two statements is where most organizations lose money.
The pricing page tells you Opus costs $5 per million input tokens. It does not tell you which product feature consumed 60% of your Opus budget last month, or whether the Claude Code sessions your team ran all week produced value proportional to what they cost. Your monthly API invoice says “$14,000 in Claude usage.” It does not say “$8,200 went to your enterprise RAG pipeline (justified), $3,100 went to customer support automation (also justified), and $2,700 went to a staging experiment that finished last Tuesday but is still running because nobody turned it off.”
That third bucket is where the money goes. Not because teams are careless, but because nobody gave them a dashboard that makes the waste visible.
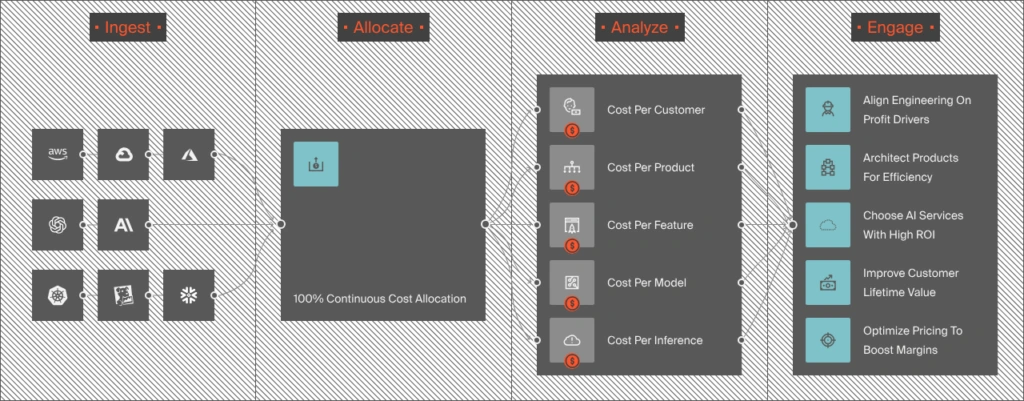
CloudZero is the first cloud cost platform to integrate directly with Anthropic, giving teams real-time visibility into Claude AI cost broken down by model, feature, team, customer, and environment, without manual tagging. CloudZero tracks 50+ LLMs across providers, so your Claude spend, your OpenAI costs, your AWS Bedrock usage, and your traditional cloud infrastructure all appear in one place.
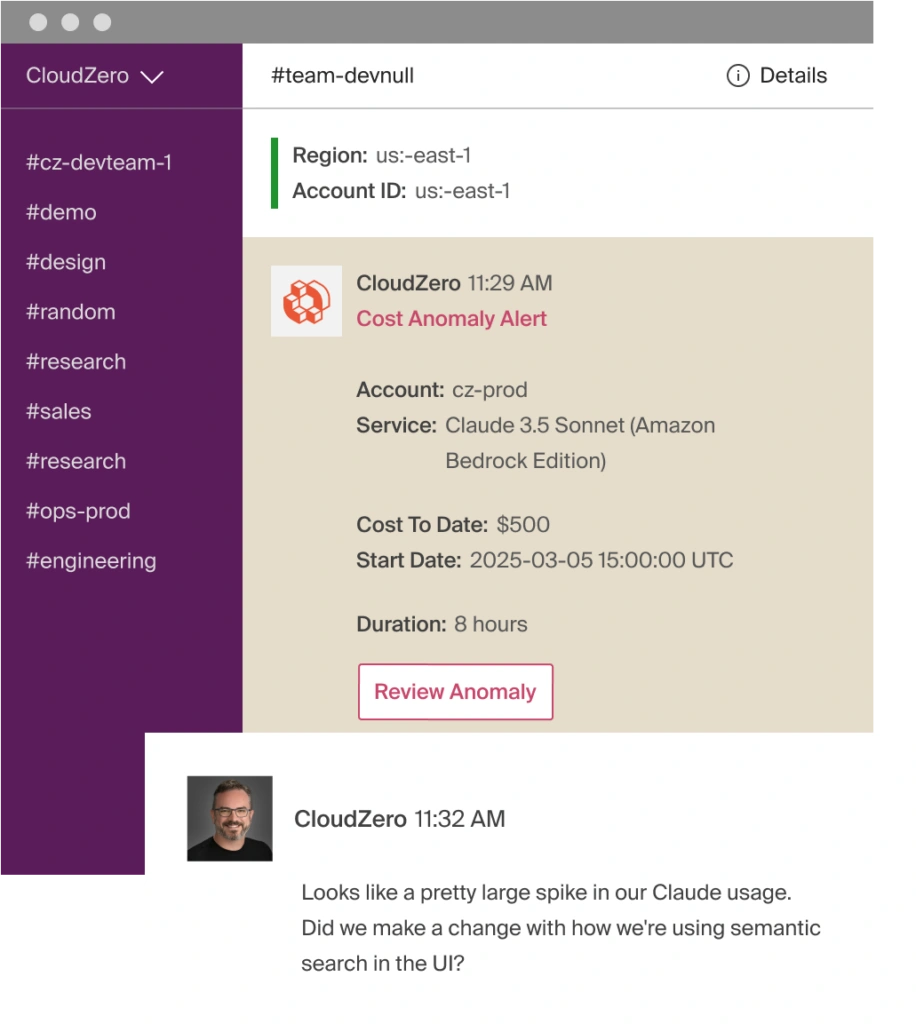
Anomaly detection catches cost spikes, a runaway Code session, a prompt without caching, a batch job that ran twice, and alerts the team that owns the code in Slack, not in a monthly finance report.
Unit economics turn the invoice into cost per customer, feature, model or per inference call. The question stops being “what did Claude cost?” and becomes “was it worth it?”
The goal isn’t to spend less on AI. It’s to spend smarter. And leading teams like Grammarly, Skyscanner, and Toyota already trust CloudZero to manage their $15 billion in cloud spend. Heck, we’ve just helped Upstart save $20 million and Drift over $2.4 million.
You can be next. Schedule a demo today to see how CloudZero aligns Claude usage with business value, ensuring every token has a measurable return.
Frequently Asked Questions About Claude Pricing











