
Quick Answer
DeepSeek API pricing centers on two V4 models. V4 Flash costs $0.14 per million input tokens and $0.28 output. V4 Pro costs $1.74/$3.48 at standard rates, with a promotional discount currently active. Cache hits cost 1/10 of standard input. Both models support 1M token context and 384K max output.
DeepSeek V4 arrived on April 24, 2026, the same day OpenAI shipped GPT-5.5, in what was almost certainly a deliberate scheduling collision. Two models replaced the entire lineup: V3.2, R1, and both legacy API aliases.
The pricing conversation shifted overnight. Not because DeepSeek got cheaper (it was already cheap). Because V4 got good; Codeforces 3,206, open-source SOTA in agentic coding and 1M context, all at a price that makes you wonder what exactly you’re paying 18x more for when you call GPT-5.4.
Two dates belong in every developer’s calendar. The legacy deepseek-chat and deepseek-reasoner aliases are retired July 24, 2026, 15:59 UTC, after that, API calls using those names return errors. And the cache hit price dropped to a fraction of standard input on April 26, 2026 — a discount most teams haven’t structured their prompts to capture yet.
This guide breaks down every DeepSeek pricing detail: model-by-model rates, the migration path for legacy aliases, the competitor math, how caching actually works, and strategies to reduce costs. All rates verified against the official source for DeepSeek API pricing 2026. For context on other providers, see CloudZero’s guides to OpenAI pricing and Gemini API pricing.
What does DeepSeek V4 cost per million tokens?
Here is a DeepSeek API pricing per million tokens table. Both current DeepSeek models bill per token on input and output separately, with cached input at a reduced rate.
|
V4 Flash |
V4 Pro (75% promo) |
V4 Pro (standard rate) | |
|
Model ID |
deepseek-v4-flash |
deepseek-v4-pro |
deepseek-v4-pro |
|
Input (cache miss) |
$0.14 |
$0.435 |
$1.74 |
|
Output |
$0.28 |
$0.87 |
$3.48 |
|
Input (cache hit) |
$0.0028 |
$0.003625 |
$0.0145 |
|
Parameters |
284B total / 13B active |
1.6T total / 49B active |
1.6T / 49B active |
|
Context |
1M tokens |
1M tokens |
1M tokens |
|
Max output |
384K tokens |
384K tokens |
384K tokens |
V4 Flash: the production default
V4 Flash (deepseek-v4-flash) at $0.14/$0.28 per MTok is the cheapest frontier-class API available. Cheaper than Gemini 2.5 Flash ($0.30/$2.50) on both input and output. Flash supports thinking and non-thinking modes, so you get reasoning without switching models.
Chat, extraction, summarization, code completion, agent subtasks — Flash handles all of it.
It’s also what deepseek-chat already routes to under the hood. If you haven’t updated your model parameter, you’ve been running Flash since April 24 and probably didn’t notice.
V4 Pro: the reasoning escalation lane
V4 Pro (deepseek-v4-pro) is for the problems Flash can’t solve in one pass. 1.6 trillion total parameters, 49 billion active per token, Codeforces rating 3,206. At standard rates, Pro costs $1.74/$3.48, roughly 12x Flash. DeepSeek has been running a 75% promotional discount that drops Pro to $0.435/$0.87.
At promo rates, V4 Pro input ($0.435) is cheaper than Claude Sonnet 4.6 ($3.00). A model that outperforms GPT-5.4 on competitive programming, cheaper per token than a mid-tier competitor. That sentence shouldn’t be true, but the pricing page says it is.
The 1M context window expansion
Both V4 models support 1M token context at standard rates. The DeepSeek context window jumped 6–8x from previous generations (V3.2 and R1 maxed at 128K–164K), making full-codebase reasoning, multi-document analysis, and extended agent conversations economically practical, without the per-token surcharges that some competitors apply above 200K tokens.
DeepSeek API pricing tells you what each model costs. The next question most developers ask: what happened to R1 and V3?
Report
Finance needs to prove AI’s return: CloudZero report
260 senior finance leaders (more than half CFOs) told us why the speed of seeing AI spend, not the size of it, separates who pulls ahead on AI from who gets burned.
What happened to DeepSeek R1 and V3 pricing?
If you searched for DeepSeek R1 pricing: R1 no longer exists as a separate model. The deepseek-reasoner alias now routes to V4 Flash thinking mode. R1’s reasoning capability lives inside V4’s thinking mode; same quality, different name, lower price.
What does that mean for DeepSeek R1 API pricing specifically? DeepSeek R1 pricing per million tokens is now V4 Flash pricing: $0.14/$0.28. If you’re budgeting for R1-class reasoning, budget for Flash rates.
The same consolidation applies to DeepSeek V3 pricing. V3.2 was priced at $0.28/$0.56 per MTok. V4 Flash halves that on both input and output while adding 1M context.
Deepseek no longer lists V3.2 or R1 as separate models. Both are historical references now. Everything consolidates into V4 Flash and V4 Pro.
The migration: one line of code, one gotcha
Update the model parameter from deepseek-chat to deepseek-v4-flash. Same base URL, same API key, same OpenAI and Anthropic-compatible endpoints.
The gotcha everyone hits: deepseek-reasoner routes to V4 Flash, not Pro. If you were using deepseek-reasoner for heavy reasoning and want equivalent or stronger capability, you need to explicitly switch to deepseek-v4-pro. The alias won’t upgrade you, it just gives you Flash-tier reasoning at Flash prices. That might be fine. Benchmark before assuming.
Deadline: July 24, 2026, 15:59 UTC. After that, the old names return errors. No extension has been announced. Don’t be the team that discovers this at 16:00 UTC on a Thursday.
With the model lineup and migration covered, the obvious next question: how does DeepSeek actually compare to the alternatives?
Is DeepSeek cheaper than GPT, Claude, and Gemini?
Yes. Here’s how much cheaper:
|
Model |
Input/MTok |
Output/MTok |
Cache Hit Input |
Context |
|
DeepSeek V4 Flash |
$0.14 |
$0.28 |
$0.0028 |
1M |
|
DeepSeek V4 Pro |
$1.74 |
$3.48 |
$0.0145 |
1M |
|
Gemini 2.5 Flash |
$0.30 |
$2.50 |
N/A |
1M |
|
GPT-5.4 |
$2.50 |
$15.00 |
Prompt caching available |
1M |
|
Claude Sonnet 4.6 |
$3.00 |
$15.00 |
Prompt caching available |
1M |
|
Claude Opus 4.7 |
$5.00 |
$25.00 |
Prompt caching available |
1M |
|
GPT-5.5 |
$5.00 |
$30.00 |
Prompt caching available |
1M |
V4 Flash input at $0.14 is 18x cheaper than GPT-5.4 ($2.50) and 36x cheaper than Claude Opus 4.7 ($5.00).
On output, where agent and code-generation workloads spend most of their budget, Flash at $0.28 is 54x cheaper than Sonnet 4.6 ($15.00) and 107x cheaper than GPT-5.5 ($30.00).
The closest competitor on price is Gemini 2.5 Flash at $0.30/$2.50. DeepSeek Flash is roughly half the price on input and one-ninth on output. The gap widens further when you add cache hit discounts, DeepSeek’s automatic caching has no equivalent in Gemini’s pricing structure at this tier.
Pricing isn’t the only variable in an inference cost decision, and DeepSeek’s price advantage come with tradeoffs:
- DeepSeek’s API runs from China-based infrastructure, which affects latency for US/EU users and matters for data residency
- Reliability and rate limit guarantees differ from Anthropic and OpenAI
- The cheapest model that can’t meet your quality bar isn’t cheap, it’s a regression with a low price tag. But for workloads where DeepSeek’s benchmarks hold up (and early testing suggests they do for coding and reasoning), the price gap is hard to argue with.
The comparison shows the headline savings. Caching is where the savings get absurd.
How does DeepSeek caching work?
DeepSeek uses automatic disk-based prefix caching. When your prompt starts with tokens that match a recently processed prefix, those tokens are served from cache at 1/10 of the standard input price. No SDK changes. No cache-control headers. No opt-in flag. It just works.
On V4 Flash, cached input costs $0.0028 per MTok, down from $0.14 for cache misses. That’s a 98% discount. The reduction took effect April 26, 2026, two days after V4 launched, and applies across all models.
The caching math that matters
A V4 Flash request with 100K cached input tokens and 10K output tokens: $0.00028 (cached input) + $0.0028 (output) = roughly $0.003 total. The same request without cache: $0.014 + $0.0028 = $0.017. Over 10,000 requests per day, caching saves about $140 daily, $4,200 monthly on a single prompt pattern. That’s the math that actually matters: not the rate card, but the effective rate after caching.
Structure your prompts with consistent system prefixes, stable tool definitions, and shared document preambles across turns. The more stable your prefix, the higher your cache hit rate, and the closer your effective DeepSeek pricing per million tokens approaches zero on input. Teams paying the least per request aren’t negotiating volume discounts, they’re engineering cache hit rates above 80%.
That covers the rate card and the caching lever. Here’s how to stack both with two more optimization layers.
4 strategies to reduce DeepSeek API costs
V4’s rates are already aggressive. These four moves stack on top of each other to push effective DeepSeek cost even lower:
1. Route by model, not by habit
Flash at $0.14/$0.28 handles most production tasks. Pro at $1.74/$3.48 standard (or $0.435/$0.87 promo) handles the hard reasoning problems. The 12x price gap at standard rates means routing is the single biggest DeepSeek API cost lever. Build a router that sends simple tasks to Flash and escalates to Pro only when Flash’s output quality falls short. If every request goes to Pro because nobody wrote the routing logic, your agent loop costs more per hour than the engineer who wrote it.
2. Maximize cache hit rates
The April 2026 cache price reduction made this the second-biggest lever. Consistent system prompts. Shared document prefixes. Stable tool schemas across conversation turns. Every reusable prefix that hits cache drops effective input cost to near zero. Monitor your cache hit rate in the DeepSeek dashboard, if it’s below 50%, your prompt structure has room to improve.
3. Batch non-urgent work into off-peak windows
DeepSeek has historically offered 50–75% discounts during off-peak hours (usually 16:30–00:30 UTC). Check the pricing page for current windows. Evaluation runs, batch processing, content generation, anything that doesn’t need real-time response can stack off-peak scheduling on top of caching for compound savings.
4. Know what your multi-provider mix actually costs
Most teams running DeepSeek also run Claude, GPT, or both, routing different tasks to different providers based on quality, latency, and cost. The routing saves money only if you can measure each provider’s cost per business outcome. Otherwise you’re just shuffling spend between undifferentiated line items on the cloud bill.
CloudZero’s AI cost management platform attributes AI spend across DeepSeek, Anthropic, OpenAI, and Amazon Bedrock by team, project, and customer through the CostFormation.
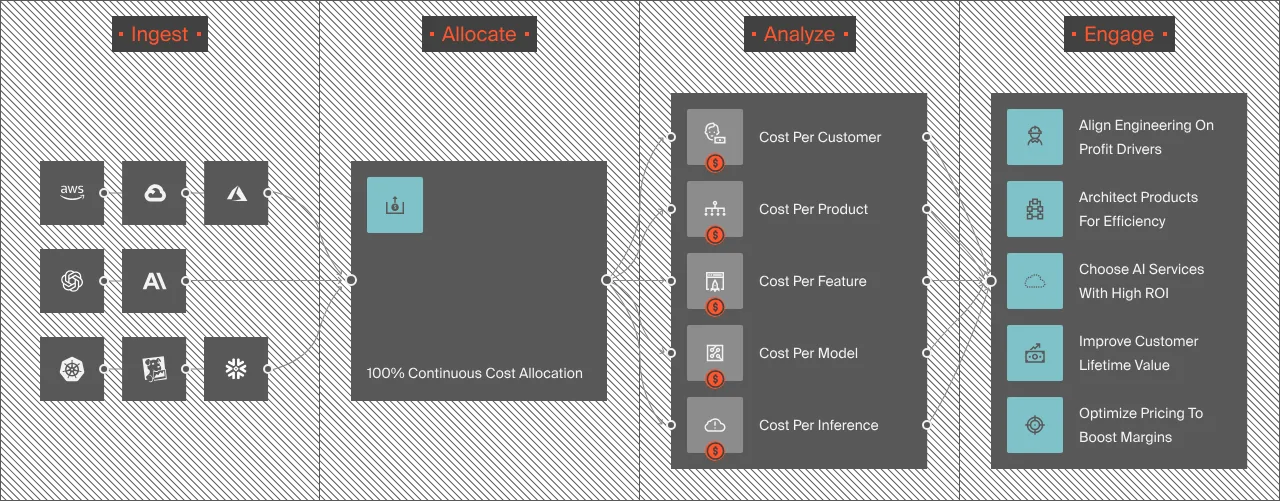
It turns “we saved money by routing to DeepSeek” from a hypothesis into a number. According to the FinOps Foundation’s State of FinOps 2026 report — based on responses from 1,192 practitioners managing over $83 billion in cloud spend — AI and machine learning cost management was the most-cited emerging challenge, with organizations reporting that inference costs from multiple providers are the fastest-growing and least-visible line item on their cloud bill. Without attribution at the model level, you can’t tell if your routing strategy saved $50K or just moved it.
That attribution problem gets worse when you consider where DeepSeek actually runs. V4 is available as a managed service on Amazon Bedrock, Microsoft Azure AI Foundry, and Google Vertex AI, plus data platforms like Snowflake Cortex AI and Databricks, where DeepSeek inference runs alongside your analytics workloads. Since V4 is open-weight (MIT license), teams can also self-host on any cloud GPU infrastructure.
Each of those paths generates a different line item on a different invoice. DeepSeek on Bedrock shows up as AWS compute. On Snowflake, it’s Snowflake credits. On Databricks, it’s DBU charges. The word “DeepSeek” doesn’t appear on any of those bills — the actual cost of your DeepSeek usage is scattered across platforms, invisible unless you have something stitching it together.
That’s where CloudZero’s cross-provider attribution earns its keep: it maps DeepSeek inference costs back to the teams and projects driving them, regardless of which platform the tokens ran through; direct API, Bedrock, Azure Foundry, or self-hosted GPU instances.
 to see CloudZero in action.
to see CloudZero in action.
Frequently Asked Questions about DeepSeek Pricing











