

Quick Answer
Azure OpenAI pricing is token-based and varies by model, deployment type, and region. The most cost-efficient option, GPT-5-nano, costs $0.05 per million input tokens and $0.40 per million output tokens. The flagship GPT-5 model runs $1.25/$10.00 per million tokens (input/output), while GPT-4.1 sits at $2.00/$8.00. Provisioned throughput units (PTUs) can reduce per-token costs by up to 70% for sustained workloads, starting at approximately $2,448 per month. Token pricing is identical to the direct OpenAI API, but total Azure OpenAI costs run higher due to support plans ($100–$1,000+/month), networking, and infrastructure overhead — production deployments typically add 20–40% above listed token rates.
What Is Azure OpenAI Service?
Before dissecting the pricing, it helps to understand what you’re actually paying for, because Azure OpenAI is not just “OpenAI with an Azure logo.”
Azure OpenAI Service gives organizations cloud-based access to OpenAI’s models; GPT-5, GPT-4.1, o4-mini, DALL-E, Whisper, and others, deployed through Microsoft’s enterprise infrastructure. Microsoft and OpenAI co-develop the API surface, so model capabilities are identical across both platforms. The difference is everything around the model: private networking through Azure VNets, data residency controls, Microsoft Entra ID authentication, and integration with Azure services like Cosmos DB, Fabric, and Azure AI Search.
Think of it this way: OpenAI’s direct API gives you a model. Azure OpenAI gives you a model inside a compliance-ready, enterprise-grade box, with a price tag that reflects the box as much as the contents.
That distinction matters for how much AI actually costs your organization. Token pricing is only one layer. The infrastructure costs surrounding it: networking, security, monitoring, fine-tuned model hosting, are where budgets quietly expand. This is the gap that FinOps for AI was designed to close: not just “what does the API cost?” but “what does this AI capability cost end-to-end, and is it generating enough value to justify the spend?” Or, “is it worth it?”
playbook
The AI Cost Optimization Playbook
Traditional cloud cost management is broken. Here’s why — and how to make the switch to cloud cost intelligence.
Azure OpenAI Pricing By Model
Azure OpenAI pricing follows a consumption-based model: you pay per token processed, for both inputs (your prompts) and outputs (the model’s responses).
A token is roughly four characters of English text, or about three-quarters of a word, which means every unnecessarily verbose system prompt is costing real money, one syllable at a time.
Below is the current pay-as-you-go pricing for every major model available through Azure AI Foundry (formerly Azure AI Studio). All prices are per 1 million tokens.
GPT-5 family:
|
Model |
Input |
Cached input |
Output |
Context window |
Best for |
|
GPT-5 |
$1.25 |
$0.13 |
$10.00 |
200K |
Flagship reasoning and generation |
|
GPT-5 Pro |
$15.00 |
$1.50 |
$120.00 |
200K |
Maximum capability, complex analysis |
|
GPT-5-mini |
$0.25 |
$0.025 |
$2.00 |
128K |
Balanced cost and quality |
|
GPT-5-nano |
$0.05 |
— |
$0.40 |
128K |
Ultra-low-cost high-volume tasks |
GPT-4.1 family:
|
Model |
Input ($/1M) |
Cached input ($/1M) |
Output ($/1M) |
Context |
|
GPT-4.1 |
$2.00 |
$0.50 |
$8.00 |
1M |
|
GPT-4.1-mini |
$0.40 |
$0.10 |
$1.60 |
1M |
|
GPT-4.1-nano |
$0.10 |
$0.025 |
$0.40 |
1M |
GPT-4o and reasoning models:
|
Model |
Input |
Cached input |
Output |
Context window |
Best for |
|
GPT-4o |
$2.50 |
$1.25 |
$10.00 |
128K |
Multimodal production workloads |
|
GPT-4o mini |
$0.15 |
$0.075 |
$0.60 |
128K |
High-volume, cost-sensitive tasks |
|
o4-mini |
$1.10 |
$0.275 |
$4.40 |
200K |
Math, coding, visual reasoning |
|
o3-mini |
$1.10 |
$0.55 |
$4.40 |
200K |
Balanced reasoning tasks |
Note: Legacy GPT-4 (8K and 32K context) and GPT-3.5 Turbo remain available but are being phased out. Both are substantially worse value than their successors. Check the Azure pricing page for current legacy model rates, and migrate to GPT-4.1 or GPT-4o for better performance at lower cost.
Azure OpenAI embedding pricing
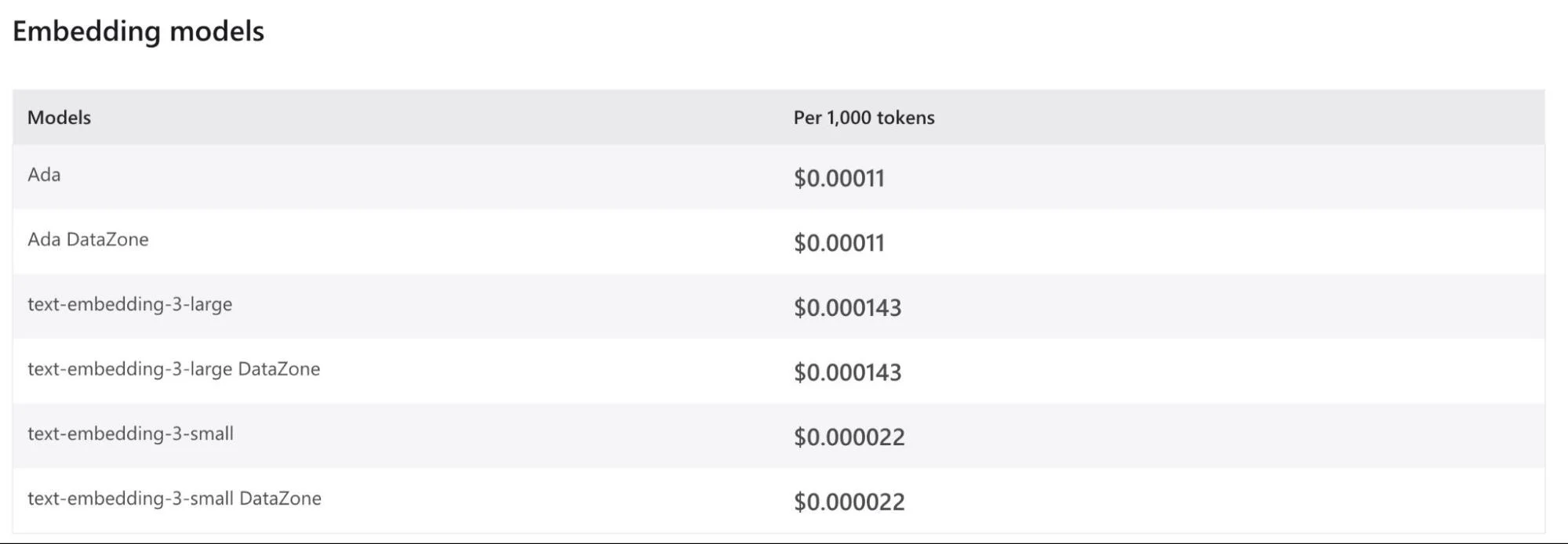
Note: All prices reflect Global Standard deployment. Standard and Data Zone deployments may vary by region. Always verify current pricing on Azure’s official pricing page.
One pattern jumps out from these tables: output tokens cost 4-8x more than input tokens for every model. This isn’t arbitrary, it reflects how transformer inference works. But it means any AI feature that generates verbose responses is hemorrhaging money on the output side.
Constraining max_tokens is the single fastest lever for reducing inference costs.
The model lineup also highlights why AI cost optimization starts with model selection, not infrastructure tweaking. GPT-5-nano at $0.05 input is 50x cheaper than GPT-4o at $2.50, and for classification, routing, and extraction tasks, the quality difference is negligible. Most production teams default to one model for everything; that’s the equivalent of shipping every package via same-day air.
Azure OpenAI Deployment Types And What They Cost
Model pricing is only half the equation. The deployment type you choose determines how that pricing applies, and what you’re optimizing for: flexibility, performance, or cost predictability.
Pay-as-you-go (standard and global standard)
Pay-as-you-go is the default. You deploy a model, send requests, and pay per token at the rates above. No commitment, no reservations. Azure offers two flavors:
- Global Standard routes requests across Microsoft’s worldwide infrastructure for maximum availability. It’s the most flexible option and the right choice for development, testing, and workloads with unpredictable volumes. The tradeoff: you’re subject to Azure OpenAI rate limits and throttling during peak demand periods.
- Standard pins your deployment to a specific Azure region. Same per-token pricing as Global Standard for most models, but you get data residency guarantees — critical for GDPR, FedRAMP, or any regulatory framework that cares where your data gets processed.
Provisioned throughput units (PTUs)
PTUs flip the model. Instead of paying per token, you reserve a fixed amount of model processing capacity and pay per PTU-hour, regardless of how many tokens you actually process.
Think of it as an all-you-can-eat buffet for AI inference: great deal if you’re hungry, expensive nap if you’re not.
|
Deployment type |
Pricing model |
Commitment |
When to use |
|
Global Standard |
Per token |
None |
Variable workloads, dev/test |
|
Standard |
Per token, region-pinned |
None |
Data residency needs |
|
Provisioned (PTU) |
Per PTU-hour |
Monthly or annual |
Predictable high-volume production |
PTUs start at approximately $2,448 per month and can deliver up to 70% savings over pay-as-you-go for sustained workloads. The break-even point sits at roughly 150-200 million tokens per month for GPT-4o. Below that threshold, pay-as-you-go is cheaper.
The PTU decision mirrors the broader reserved instance vs. on-demand tradeoff that FinOps teams have been navigating for years, just applied to AI inference instead of compute. The same principles apply: measure your baseline, forecast your growth, commit only when utilization justifies it.
What’s different with AI is the volatility. A single prompt change can double token consumption overnight. A new feature launch can 10x inference volume in a week. PTU commitments that looked brilliant in March can look expensive in June if your product roadmap shifts. This is why AI cost management demands real-time visibility that traditional cloud cost tools were never designed to provide.
Deployment type affects how you pay. But it doesn’t change what you pay relative to the alternative, calling OpenAI directly and skipping Azure entirely.
Azure OpenAI Vs Direct OpenAI API: Where The Real Cost Difference Lives
Token-for-token, Azure OpenAI and the direct OpenAI API charge identical rates for the same models. GPT-5 costs $1.25/$10.00 per million tokens on both platforms. If you’ve been researching ChatGPT API pricing and wondering what changes when you route through Azure, the per-token rates don’t. Everything else does.
The total cost of ownership tells a different story:
|
Cost factor |
Azure OpenAI |
OpenAI API (direct) |
|
GPT-5 input/output |
$1.25 / $10.00 per 1M tokens |
$1.25 / $10.00 per 1M tokens |
|
GPT-4.1 input/output |
$2.00 / $8.00 per 1M tokens |
$2.00 / $8.00 per 1M tokens |
|
GPT-5-nano input/output |
$0.05 / $0.40 per 1M tokens |
$0.05 / $0.40 per 1M tokens |
|
Compliance |
SOC 2, HIPAA, FedRAMP |
SOC 2 (limited) |
|
Data residency |
Region-specific deployment |
No guarantees |
|
SLA |
99.9% uptime |
No formal SLA |
|
Private networking |
VNet + private endpoints |
Not available |
|
Support plans |
$100-$1,000+/month (required for production) |
Self-serve |
|
Volume discounts |
PTU commitments (up to 70% savings) |
Tier-based |
|
Batch API |
50% off standard pricing |
50% off standard pricing |
|
Total cost overhead |
Higher above token cost |
Minimal overhead |
For regulated industries such as healthcare, financial services or government, the Azure premium isn’t optional. It’s the cost of compliance. For startups and teams without compliance requirements, the direct API is usually cheaper end-to-end.
But here’s the thing. Many organizations use both. Azure OpenAI for production workloads that need compliance guardrails, and the direct API for prototyping and development. That’s a sound strategy, but it creates a cost attribution challenge that native billing tools on either platform can’t solve. You need a single view across both providers to understand total AI spend, which is exactly where multi-cloud cost intelligence becomes essential.
Hidden Costs That Inflate Your Azure OpenAI Bill
The pricing tables above represent the floor, not the ceiling. Production Azure OpenAI deployments consistently exceed advertised token costs by a wide margin once infrastructure overhead kicks in. Here’s where the extra spend hides.
1. Fine-tuned model hosting
Training a fine-tuned model costs $1.50-$25 per million tokens. But hosting that model runs $1.70-$3.00 per hour regardless of usage. That’s $1,224-$2,160 per month for a model that might answer zero queries.
Organizations routinely discover “zombie” fine-tuned models three to six months after deployment, having burned $5,000–$11,000 on idle deployments. At scale, a single misconfigured PTU reservation or forgotten fine-tuned model can add $50,000 or more to a monthly bill before anyone notices — a scenario documented repeatedly in Azure engineering forums.
This is exactly the kind of waste that AI-powered anomaly detection catches, if you have it running.
2. Retry and error overhead
Failed API calls that partially process tokens still incur charges. Rate-limited requests that process the input prompt before returning a 429 error? You paid for those input tokens. Applications without exponential backoff and proper error handling burn an estimated 10-15% of their token budget on retries.
3. Context window waste
Sending full conversation histories with every request is the AI equivalent of forwarding the entire email chain to reply “sounds good.” Each token in your context window costs money.
A chatbot sending a 128K context window when only the last 4K tokens matter is paying 32x more per request than necessary. Cached input pricing (50-90% savings on repeated prefixes) helps, but only if you architect your prompts to take advantage of it.
4. Support plans and infrastructure
Azure requires a support plan for production workloads, starting at $100/month and scaling to $1,000+ for enterprise support. Add monitoring (Azure Monitor, Application Insights), key management (Key Vault), and cognitive services overhead, and you’re looking at $35-$50 per month in infrastructure costs before a single token gets processed.
5. Data transfer
Inbound data is free. Azure gives you 100GB of free outbound data. Beyond that, egress costs $0.087/GB. High-throughput AI applications processing millions of tokens daily can hit this threshold quickly.
6 Strategies To Reduce Azure OpenAI Costs
Understanding the pricing structure is step one. Reducing what you actually pay requires deliberate action across model selection, prompt engineering, and deployment strategy.
1. Route workloads to the cheapest capable model
This is the single highest-impact optimization. Most teams default to one model for everything. In reality, most of the production tasks such as classification, extraction or simple Q&A perform equally well on cheaper models. GPT-4o mini at $0.60 per million output tokens delivers 94% lower output costs than GPT-4o at $10.00.
Build a routing layer. Send simple tasks to GPT-5-nano or GPT-4.1-nano. Reserve flagship models for complex reasoning. The savings are multiplicative.
2. Enable cached input tokens
Azure caches repeated input prefixes and charges 50-90% less for cached tokens. Put static content such as system instructions, few-shot examples, retrieval context at the beginning of your prompts. Keep variable content (the user query) at the end. The longer the static prefix, the higher the cache hit rate.
3. Use the Batch API for non-real-time workloads
Any workload that tolerates 24-hour latency should use Azure’s Batch API at 50% off standard pricing. Good candidates: nightly data processing, content generation pipelines, document classification, and embedding generation for RAG.
4. Constrain output length aggressively
Output tokens cost 4-8x more than input tokens. Set explicit max_tokens limits. Use structured output formats (JSON schemas) that prevent verbose responses. Instruct models to be concise in system prompts. A 50% reduction in average output length translates to a 50% reduction in your largest cost line item.
5. Audit for zombie deployments
Fine-tuned models, unused PTU reservations, forgotten test deployments accumulate idle resources faster than traditional cloud infrastructure because experimentation is built into the workflow. Your cloud bill is a haunted house, and the ghosts are all fine-tuned models nobody remembers deploying. Set a monthly calendar reminder to audit every active deployment. If it hasn’t processed requests in 30 days, delete it.
6. Evaluate PTU commitments with real data
Don’t commit to PTUs based on estimates. Run pay-as-you-go for 30–60 days. Measure your actual P95 hourly token throughput. Then model the PTU option against your pay-as-you-go baseline. The break-even threshold varies by model — for GPT-4o, it’s roughly 150–200 million tokens per month, but newer models like GPT-5-nano may never justify a PTU commitment at their already-low token rates.
These six strategies address the mechanics. But they share a prerequisite that none of them can provide on their own: knowing where your tokens are going, not just how many, but why, and for whom. That’s a visibility problem, and it’s where native Azure billing hits a hard ceiling.
Why Tracking Azure OpenAI Costs Requires More Than Azure Billing
Your Azure OpenAI bill is $40,000 this month. Is that a problem?
It depends.
If $35,000 powered an AI feature that drove $200,000 in revenue, the right move is scaling up, not cutting back. If $35,000 went to a chatbot nobody uses, the right move is shutting it down. Azure Cost Management can’t tell you which scenario you’re in. It shows the cost. It doesn’t show the value.
This is the gap between cost management and cost intelligence, and it’s the problem CloudZero was purpose-built to solve.
How CloudZero tracks Azure OpenAI costs
CloudZero’s native Azure integration ingests 100% of your Azure spend, including Azure OpenAI, and allocates it to the business dimensions that drive decisions: cost per customer, feature, product, team or model. No manual tagging required.
CostFormation allocates without tags. Most Azure OpenAI resources aren’t tagged comprehensively, especially when teams spin up deployments for experimentation. CloudZero’s CostFormation engine allocates 100% of your Azure costs to business dimensions regardless of your tagging quality. When a token gets processed, CloudZero traces it to the feature, customer, and team that triggered it.

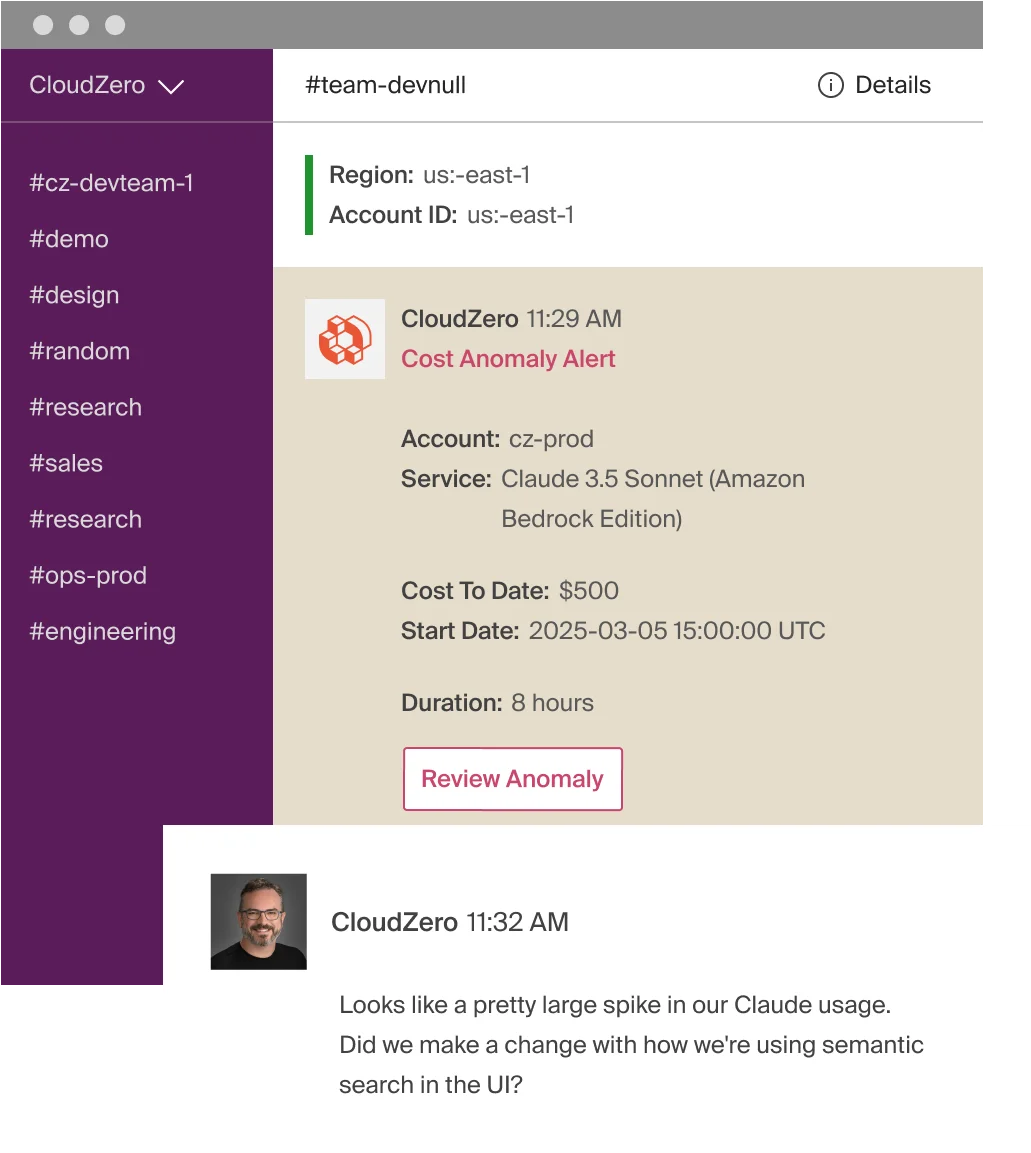
AI-powered anomaly detection catches cost spikes in real time. CloudZero’s anomaly detection compares hourly spend data from the past 36 hours against 12 months of historical patterns, automatically defining what “normal” looks like for every view. When a deployment, prompt change, or traffic spike pushes Azure OpenAI consumption outside that baseline, CloudZero alerts the specific engineering team that owns the affected infrastructure, with direct links to hour-by-hour spend views showing exactly when and where the anomaly started.
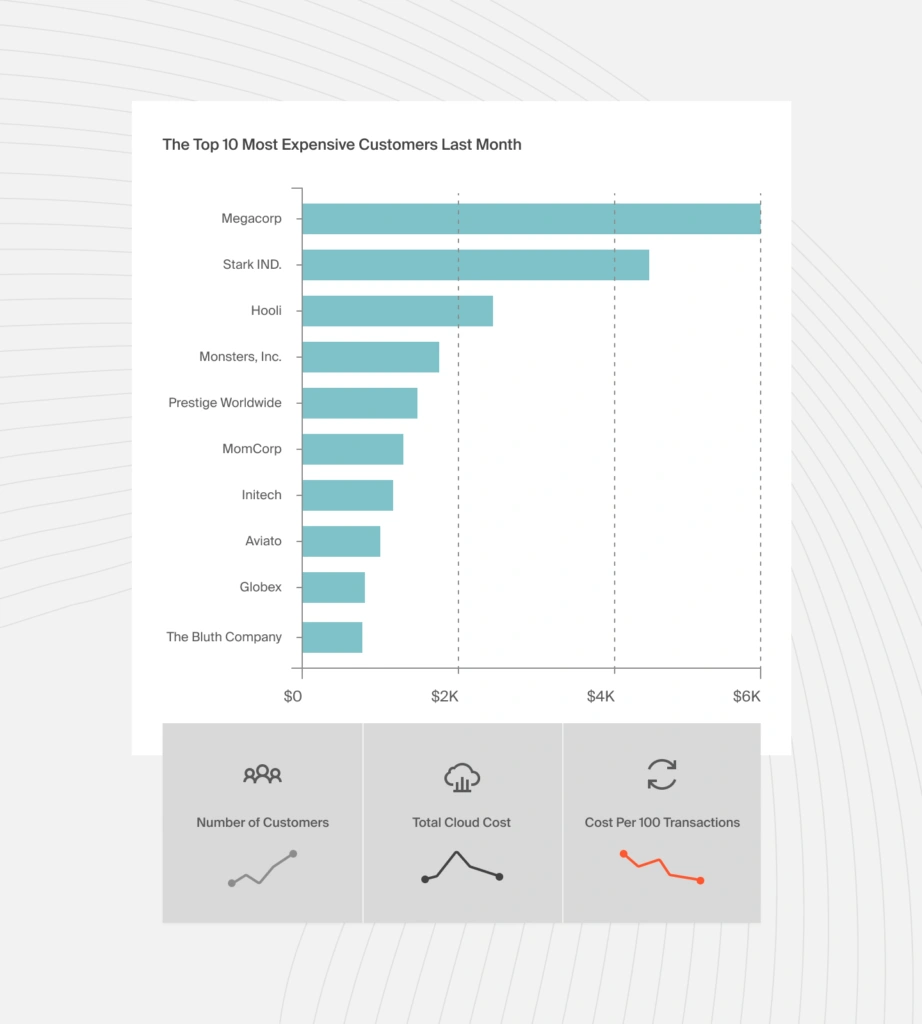
Unit economics reveal if the spend is worth it. This is where CloudZero’s approach diverges from every native billing tool and most third-party platforms. Instead of just showing “Azure OpenAI costs $40,000,” CloudZero answers: what is the Azure OpenAI cost per customer? Per product feature? Per inference call? Per environment? These unit cost metrics; no averages, no estimates, let you distinguish healthy AI spend (growing because the product is scaling) from unhealthy spend (growing because of waste, inefficiency, or zombie deployments).
Cost per customer is particularly powerful for Azure OpenAI workloads. If Customer A generates $500 in monthly AI costs and pays you $50 in subscription fees, you’ve found a margin problem before it compounds. If Customer B generates $5,000 in AI costs but pays $100,000, you’ve found a case for investing more in the AI feature that serves them.
Budgeting and forecasting close the loop. CloudZero transforms scattered Azure billing data into forecasts that finance teams can actually use, projecting AI spend growth by product line, by customer segment, and by model tier. That’s how you move from reactive bill panic to proactive AI investment planning.
CloudZero’s integration depth across AI providers
Azure OpenAI is rarely the only AI cost on an enterprise bill. Organizations run workloads across AWS (Bedrock, SageMaker), Google Cloud (Vertex AI, Gemini), Oracle Cloud (OCI), and direct API providers.
CloudZero integrates natively with AWS, Azure, GCP, and Oracle Cloud, plus direct integrations with OpenAI and Anthropic. CloudZero is the first cloud cost platform to integrate directly with Anthropic, joining its existing OpenAI integration. It also ingests costs from SaaS platforms like Snowflake, New Relic and Datadog, and any other source through its AnyCost API.
That means your Azure OpenAI token costs, your AWS Bedrock inference spend, your self-hosted GPU costs, and your Anthropic API usage all appear in a single dashboard, allocated to the same business dimensions, measured against the same unit economics, and governed by the same anomaly detection system.
For organizations running multi-model AI architectures across multiple providers, this single-pane view is the difference between “we’re spending a lot on AI” and “we know exactly which AI investments are paying off and which aren’t.” That distinction is what the FinOps for AI discipline is built on.
The proof is in the numbers
CloudZero manages over $15 billion in cloud spend across customers including Toyota, Duolingo, Skyscanner, and Coinbase. CloudZero customer Upstart saved $20 million through granular cost visibility. PicPay saved $18.6 million. These aren’t savings from turning things off, they’re savings from understanding which spend created value and which didn’t, then acting on that insight.
As NVIDIA CEO Jensen Huang put it at GTC 2026: the compute demands of AI have increased roughly one million times over two years. Inference, not training, is the dominant AI workload now, and it scales with every user interaction. Organizations that can’t attribute that scaling spend to business outcomes are flying blind.
CloudZero is also a Gartner-recognized Visionary in cloud cost management, purpose-built for exactly that shift, from “how much did we spend?” to “was it worth it?”
 to experience CloudZero for yourself. Take a free cloud cost assessment to find out where your AI spend is hiding. Or explore the Azure integration to see how CostFormation allocates 100% of Azure costs without tags.
to experience CloudZero for yourself. Take a free cloud cost assessment to find out where your AI spend is hiding. Or explore the Azure integration to see how CostFormation allocates 100% of Azure costs without tags.
Azure OpenAI Pricing FAQs











