

Quick Answer
Google Vertex AI pricing is usage-based with no upfront commitment. The cheapest current model, Gemini 2.5 Flash-Lite, costs $0.10 per million input tokens and $0.40 per million output tokens. The flagship model, Gemini 2.5 Pro, starts at $1.25 per million input tokens and $10.00 per million output tokens. Total monthly costs range from under $100 for prototyping to $100,000+ for enterprise production, depending on model selection, inference volume, training compute, and which Vertex services you stack. Google offers a $300 free trial credit valid for 90 days.
What is Vertex AI?
Vertex AI is Google Cloud’s unified machine learning and generative AI platform. It’s where you train models, deploy them, run inference, build AI agents, and access Google’s Gemini foundation models alongside 200+ third-party models including Anthropic’s Claude, Meta’s Llama, and Mistral, all through a single Vertex AI platform.
If you’ve used Amazon Bedrock or Azure AI Studio, the pitch is familiar: one managed environment, no GPU provisioning headaches. The difference is how tightly Vertex AI integrates with GCP’s data stack — BigQuery, Cloud Storage, Dataflow — which matters when your AI workload depends on data that already lives in Google Cloud.
As of Google Cloud Next 2026, Vertex AI is transitioning to the Gemini Enterprise Agent Platform, a rebrand consolidating Vertex AI and Agentspace into one product. The billing mechanics haven’t changed. The marketing deck has.
Here’s what the platform actually covers, and why the pricing gets complicated:
|
Category |
Services |
What it does |
|
Foundation models |
Vertex AI Studio, Vertex AI Model Garden, Vertex AI OpenAI compatibility endpoint |
Prompt and test 200+ models (Gemini, Claude, Llama, Mistral). Port existing OpenAI code to Gemini without rewrites |
|
AI agents |
Vertex AI Agent Builder, Vertex AI Agent Engine |
Build and deploy production agents with persistent memory, session management, and managed runtime |
|
Search and retrieval |
Vertex AI Search, Vertex AI Vector Search (formerly Vertex AI Matching Engine), Vertex AI RAG Engine |
Enterprise search, similarity search for embeddings, and end-to-end retrieval-augmented generation |
|
Media generation |
Vertex AI Veo, Imagen, Chirp |
Video generation (Veo 3), image generation, and text-to-speech. |
|
ML platform |
Custom training, AutoML, Vertex AI Workbench, Vertex AI Feature Store, Pipelines |
Model training, notebooks, feature management, experiment tracking, and monitoring. |
That’s 15+ separately billed services. Each with its own meter. Some of them call each other under the hood, which means a single user request can trigger charges across three or four services you didn’t explicitly invoke. If that sounds like the kind of billing complexity that needs its own cloud cost management strategy, you’re paying attention.
playbook
The AI Cost Optimization Playbook
Traditional cloud cost management is broken. Here’s why — and how to make the switch to cloud cost intelligence.
How Vertex AI Pricing Works
Vertex AI pricing follows Google Cloud’s standard pattern: pay-as-you-go, metered by usage, with tiered pricing discounts at committed volumes. Your bill breaks into four dimensions:
- Generative AI API calls are billed per token, with rates varying by model and context length. Google’s Standard PayGo tier system automatically increases throughput capacity as your rolling 30-day spend grows. Higher tiers unlock more tokens-per-minute, useful for scaling, but also a reason to keep close tabs on what’s driving that spend upward.
- Agent and application services such as Agent Builder queries, Agent Engine runtime, sessions, memory, and search. Each carries separate per-unit charges that stack on top of model inference. A single user request to an AI agent can trigger four billable events across different services.
- Training and tuning compute is billed per node-hour for custom training and per training token for supervised fine-tuning. This is the spikiest cost category, one misconfigured distributed training job can outspend a month of inference.
- Managed infrastructure such as prediction endpoints, vector search nodes, Workbench notebooks, feature store instances, and pipelines are billed per hour whether you’re sending requests or not.
Google publishes each service’s pricing on separate pages. There’s no single calculator showing the full picture. You’re reading three pricing docs and reconciling them in a spreadsheet that grows a new tab every quarter. At some point, that spreadsheet stops being a cost management strategy and starts being a coping mechanism.
The largest of those tabs, for most teams, is the one tracking Gemini model spend.
Gemini Model Pricing On Vertex AI (2026)
Vertex AI Gemini pricing represents the largest share of cost for most teams. Google prices models per million tokens, with separate rates for input and output.
|
Model |
Input (per 1M tokens) |
Output (per 1M tokens) |
Context window |
|
Gemini 3.1 Pro |
$2.00 (≤200K) / $4.00 (>200K) |
$12.00 / $24.00 |
1M tokens |
|
Gemini 3.1 Flash-Lite |
$0.25 |
$1.50 |
1M tokens |
|
Gemini 3 Flash |
$0.50 |
$3.00 |
1M tokens |
|
Gemini 2.5 Pro |
$1.25 (≤200K) / $2.50 (>200K) |
$10.00 / $15.00 |
1M tokens |
|
Gemini 2.5 Flash |
$0.30 |
$2.50 |
1M tokens |
|
Gemini 2.5 Flash-Lite |
$0.10 |
$0.40 |
1M tokens |
|
Gemini 2.0 Flash |
$0.10 |
$0.40 |
Discontinued June 2026 |
If you’re confused about Vertex AI vs. Gemini: Gemini is the model family; Vertex AI is the platform you access it through.
You can also access Gemini via Google AI Studio (free for prototyping) or the Gemini Developer API, but Vertex AI adds enterprise features: SLAs, Provisioned Throughput, VPC Service Controls, and compliance certifications.
Four dynamics worth understanding:
- Thinking tokens aren’t free. Gemini 3.x models generate internal reasoning tokens billed as output at the standard rate. Setting thinking_level=”high” on a complex task where the model spends 4,000 tokens reasoning before writing a 500-token answer means you pay for 4,500 output tokens. At $12.00 per million output tokens, this adds up. (Reddit’s r/googlecloud is full of engineers who discovered this the hard way.)
- Context length creates cost cliffs. For Pro models, input pricing doubles when prompts exceed 200,000 tokens. This isn’t a gradual increase, it’s a hard threshold. A RAG pipeline pulling long documents can silently push every request into the higher bracket.
- Model selection is the highest-leverage cost optimization decision. Flash-Lite at $0.10/$0.40 is 20x cheaper on input than Gemini 3.1 Pro at $2.00/$12.00. Google’s Model Optimizer auto-routes requests to the cheapest adequate model based on task complexity, dynamic pricing that averages lower than manually choosing Pro for everything. (More on cost reduction tactics in the optimization section below.)
- Model costs are the most visible line item. But for teams building AI agents, the charges stacking on top of model costs are where the real complexity lives.
Vertex AI Agent Builder And Agent Engine Pricing
Vertex AI Agent Builder pricing covers the full stack for building AI agents, search applications, and conversational interfaces. Vertex AI Agent Engine pricing covers the managed runtime.
|
Service |
Price |
Unit |
|
Search (data store queries) |
$4.00 |
Per 1,000 queries |
|
Search with Advanced LLM |
$6.00 |
Per 1,000 queries |
|
Agent Engine runtime |
$0.0864 |
Per vCPU-hour |
|
Agent Engine memory |
$0.0090 |
Per GB-hour |
|
Sessions and Memory Bank |
$0.25 |
Per 1,000 events |
Sessions and Memory Bank billing began February 11, 2026. Free tier: 50 vCPU-hours and 100 GB-hours of memory per month.
These charges are additive. An AI agent that retrieves documents via search ($4-6/1K queries), generates a response via Gemini (model tokens), maintains session state ($0.25/1K events), and runs on Agent Engine ($0.0864/vCPU-hour) triggers four billing events per user interaction.
That’s four different SKUs on your invoice for one user asking one question. At 100,000 daily queries, the math stops being theoretical very quickly.
Many of those agent interactions depend on search and vector retrieval, which brings its own pricing layer.
Vertex AI Search and vector search pricing
- Vertex AI Search pricing: $4.00 per 1,000 standard queries, $6.00 per 1,000 advanced queries. An internal knowledge base handling 100,000 queries/month runs $400-$600 in search alone.
- Vertex AI Vector Search pricing (formerly Vertex AI Matching Engine pricing) is infrastructure-based, you pay for compute nodes hosting your vector index, billed per node-hour. Cost depends on machine type, index size, and replica count. A moderately sized index on three replicas runs roughly $700-$800/month.
- The Vertex AI RAG Engine orchestrates end-to-end retrieval-augmented generation, combining embedding, retrieval, and generation into a managed pipeline. RAG Engine billing includes separate charges for corpus storage, retrieval queries, and the underlying model calls.
A common billing confusion: Agent Builder uses Vector Search under the hood, but you’re billed at the Agent Builder query rate. If you build a custom RAG pipeline, you pay Vector Search infrastructure costs directly. These are different prices for overlapping functionality. Pick one path, paying for both is how the bill doubles without the value doubling.
All the costs so far — models, agents, search — are inference costs. Training and fine-tuning is where the bill can jump by an order of magnitude overnight.
Training, fine-tuning, and GPU costs
Custom model training is where Vertex AI GPU pricing and Vertex AI training cost can spike dramatically. Billing is per node-hour, determined by accelerator type:
|
Accelerator |
On-demand (per GPU/hour) |
With Vertex AI management fee |
1-yr CUD (~30% off) |
|
NVIDIA A100 40GB |
~$2.93 (us-central1) |
~$3.37 |
~$2.36 |
|
NVIDIA H100 80GB |
~$10–$11 |
~$11–$12 |
~$7–$8 |
|
Google TPU v5e |
Not fixed |
Included |
Custom / contact sales |
Note: CUD discounts approximate; vary by region. Compare to EC2 pricing and savings plans vs. reserved instances for AWS equivalents.
An H100 at $11.27/hour means a 24-hour distributed training run on eight GPUs costs roughly $2,164. Multi-day runs exceed $10,000 per experiment. Teams exploring spot instances can save up to 60-91% on interruptible training workloads, a pattern well-established on AWS that applies equally to GCP’s Spot VMs.
Vertex AI Workbench pricing is straightforward. Notebook instances are Compute Engine VMs, so you pay standard Compute Engine rates for whatever machine type you configure. An e2-standard-2 instance (the default) costs roughly $0.077/hour. Add a T4 GPU and it’s about $0.40/hour more. The catch: these VMs run whether you’re actively coding or not. Every open notebook is a running meter.
Vertex AI Feature Store pricing charges for feature serving (per node-hour) and online/offline storage. Teams building ML pipelines with shared feature repositories should account for this in total cost calculations.
Without visibility into which team, project, or experiment is driving GPU consumption, training costs stay opaque until the invoice arrives. It’s the cloud equivalent of discovering your water bill tripled because someone left a hose running in the backyard.
GPU compute isn’t the only production cost that surprises teams. Media generation adds another dimension entirely.
Vertex AI Veo and media generation pricing
Vertex AI Veo pricing covers Google’s video generation models. On Vertex AI, Veo 3 costs $0.50 per second for video-only and $0.75 per second for video with audio. Veo 3.1 Fast — the lighter variant — starts at $0.10 per second without audio. For context, a single 8-second video with audio runs $6.00 on Vertex AI. Imagen and Chirp (image generation and text-to-speech) carry separate per-unit charges, check the Vertex AI generative AI pricing page for current rates.
For teams building multimodal applications, these costs add a dimension that doesn’t appear in standard LLM pricing discussions. A single AI-generated marketing video can cost more than thousands of text inference calls, a fun discovery to make when the invoice arrives.
With all these cost surfaces, the natural question is whether Google offers anything for free. They do, with limits.
Is Vertex AI free to use?
Partially. Google offers three free pathways for Vertex AI pricing free tier access:
- $300 free trial credit applies to all new Google Cloud accounts and covers any GCP service, including Vertex AI. It expires after 90 days.
- Vertex AI free tier provides rate-limited access to Gemini models (up to 1,000 requests/day for some models), free Workbench notebook compute (limited hours), and free Agent Engine runtime (first 50 vCPU-hours/month).
- Express Mode lets you use Vertex AI Studio and Agent Builder with limited quotas (up to 10 agent engines, 90 days) without enabling billing.
The free tier works for prototyping. It does not work for production. Treat it as a sandbox, useful for proving a concept, not for serving real users.
Once you’re past the sandbox, the next question is usually how Vertex AI stacks up against the competition.
Vertex AI Vs AWS Bedrock Vs Azure AI
Every enterprise evaluating Google Cloud Vertex AI pricing also looks at the other hyperscalers.
Here’s the comparison at equivalent capability tiers:
|
Capability tier |
Google (Vertex AI) |
AWS (Bedrock) |
Azure (OpenAI) |
|
Flagship (highest reasoning) |
Gemini 2.5 Pro → $1.25 / $10.00 |
Claude 3 Opus → ~$15 / ~$75 |
GPT-4o → ~$5 / ~$15 |
|
Mid-tier (balanced) |
Gemini 2.5 Flash → $0.30 / $2.50 |
Claude 3.5 Sonnet → ~$3 / ~$15 |
GPT-4o-mini → ~$0.15 / ~$0.60 |
|
Cost-efficient |
Gemini 2.5 Flash-Lite → $0.10 / $0.40 |
Claude 3 Haiku → ~$0.25 / ~$1.25 |
GPT-4o-mini → ~$0.15 / ~$0.60 |
Verify current rates before committing, AI model pricing changes frequently. Teams comparing Vertex AI alternatives should factor in total workload cost, not just model rates.
At the budget tier, Gemini 2.5 Flash-Lite ($0.10/$0.40 per million tokens) is among the cheapest foundation models available from any major provider. At the flagship tier, Gemini 2.5 Pro is significantly cheaper on input tokens than both Claude 3 Opus on Bedrock and GPT-4o on Azure — though output token rates and performance differences make direct comparisons imperfect.
At the flagship tier, Gemini 2.5 Pro is significantly cheaper on input tokens than both Claude 3 Opus and GPT-4o, though differences in performance and output efficiency make direct comparisons imperfect.
But model rates alone don’t determine total cost. A Gemini Flash call may cost $0.30 per million input tokens, but additional services such as retrieval, grounding, or agent orchestration, can add separate per-query charges depending on how the system is built.
Each cloud provider bundles and meters services differently. For multi-cloud teams, apples-to-apples comparison is difficult without a unified cost model across the full architecture.
And even within a single provider, listed model rates rarely reflect the total cost drivers that impact production workloads.
Hidden Costs That Inflate Your Vertex AI Bill
Every number above comes from a pricing page. The costs below don’t. They’re the charges that show up on your invoice with no corresponding line in any pricing table, and they’re the reason engineers post $7,000+ billing screenshots on Reddit:
- Idle endpoints. A deployed A100 endpoint costs roughly $2,642/month, whether it handles requests or not. One forgotten A100 endpoint generated a $7,889 invoice for a Google Cloud engineer — a bill documented on Reddit’s /r/googlecloud subreddit and replicated across dozens of similar threads. If you’ve ever left a cloud monitoring dashboard open and seen a cost graph shaped like a hockey stick, this is usually why.
- Thinking token inflation. As covered in the Gemini pricing section, reasoning tokens billed as output can double or triple the effective cost of a request. Teams running complex agentic workflows at scale discover this when output costs outpace input by 10-15x instead of the expected 4-6x.
- Grounding surcharges. Google Search grounding costs $14 per 1,000 queries for Gemini 3 models and $35 per 1,000 queries for Gemini 2.x — often more than the model inference call itself. For teams grounding every response, this single line item can become the largest charge on their Vertex AI bill.
- LiveAPI session re-billing. Charged per turn for all tokens in the Session Context Window — including accumulated tokens from previous turns. Turn 10 of a conversation bills for every token from turns 1-9 again. Multi-turn conversations don’t just get longer; they get exponentially more expensive.
- Data transfer and logging. Moving data between BigQuery, Cloud Storage, and Vertex AI incurs network egress fees, especially across regions. Cloud Logging ingestion can add meaningfully to your AI infrastructure bill, a pattern familiar to anyone who’s audited CloudWatch pricing on the AWS side.
These costs compound in ways no pricing table can predict. The question isn’t whether you’ll encounter them — it’s whether you’ll catch them before or after the invoice.
How To Reduce Vertex AI Costs
Seven tactics, ordered by expected savings:
- Route requests to the cheapest adequate model. Use Google’s Model Optimizer or build a custom routing layer. Send classification and extraction to Flash-Lite ($0.10/$0.40), reserve Pro ($2.00/$12.00) for complex reasoning. AI cost optimization analysis consistently show model routing as the highest-impact optimization for AI workloads.
- Use the Batch API. Non-urgent workloads such as document processing, nightly analytics or content pipelines get 50% off standard rates. Gemini 2.5 Pro drops from $1.25/$10.00 to $0.625/$5.00 per million tokens in batch mode.
- Cache aggressively. Context caching saves up to 90% on repeated input. Reads cost roughly 10% of base input price, with storage charges per million tokens per hour. If your app reuses system prompts or document preambles across requests, caching is the single highest-ROI optimization on the platform.
- Scale endpoints to zero when idle. Configure autoscaling with minimum replicas at zero for dev and staging. For production, match minimums to baseline traffic, not peak.
- Use committed use discounts for steady GPU workloads. One-year CUDs save ~30%, three-year save ~50%. Breakeven: roughly four months of consistent usage. Similar logic to savings plans vs reserved instances on AWS.
- Control thinking token spend. Default to thinking_level=”medium”. The Gemini 3.1 Pro documentation confirms medium delivers comparable reasoning depth to high, at meaningfully lower cost per request.
- Get granular cost attribution. GCP billing budgets catch aggregate spikes. But aggregate alerts don’t tell you which team, project, or AI feature is driving the spend. And every tactic above such as model routing, batching, caching or CUDs requires knowing where your costs are concentrated before you can optimize them.
That last point is the one most organizations hit a wall on. Google’s billing console shows you SKU-level totals. It doesn’t show you cost per customer, feature, team, product or cost per inference call. It can’t tell you whether your AI spend is generating business value or just generating invoices. That’s a different kind of tool entirely. That’s CloudZero.
How CloudZero Maps Vertex AI Spend To Business Outcomes
Google’s pricing page gives you list prices. GCP’s billing console gives you totals by SKU. Neither answers the question engineering leaders and CFOs actually need answered: what is AI costing us per customer, per product, or per feature, and is it generating more value than it consumes?
That’s the question CloudZero exists to answer. How?
Direct GCP integration
CloudZero connects to Google Cloud billing and maps every Vertex AI line item — inference, training, search, agent runtime, Workbench, Feature Store, to teams, products, features, and customers. No manual tagging. CloudZero automatically allocates 100% of spend, including shared and untaggable resources that GCP’s native tools simply can’t attribute.
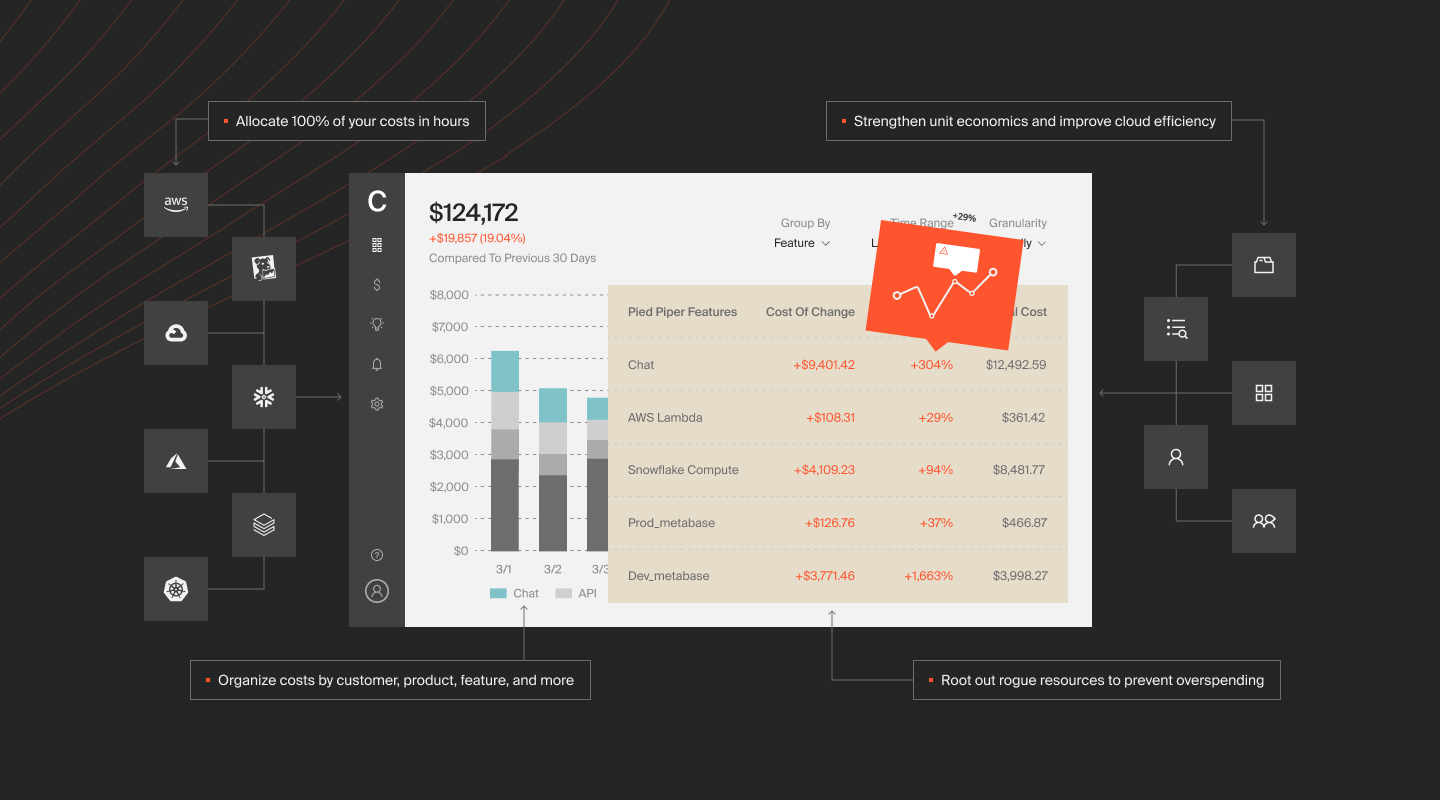
Multi-provider, single pane of glass
Most enterprises running Vertex AI also run workloads on AWS, Azure, or Oracle. CloudZero provides a unified cost view across providers. The real question isn’t “what does Vertex AI cost?”, it’s “what does our AI workload cost across every platform it touches?”
First-ever Anthropic integration, plus OpenAI
CloudZero was the first cloud cost platform to integrate directly with Anthropic, and also integrates with OpenAI. For teams running Gemini on Vertex alongside Claude on Bedrock and GPT via Azure, CloudZero normalizes every provider into a single cost-per-inference metric. One number. Across all models.
Cost per customer. Cost per feature. Cost per inference.
This is CloudZero’s core differentiator, and it’s what makes it relevant to Vertex AI specifically. Instead of a billing line that says “Vertex AI API: $23,847,” CloudZero shows what that $23,847 bought in business terms. How much does your AI search feature cost per user session? Is inference cost per customer growing faster than revenue per customer? Is that new Agent Builder workflow delivering $3 of value for every $1 of compute? These are the questions that turn cost monitoring into cost strategy.

Real-time anomaly detection
CloudZero flags spending anomalies as they happen. That runaway training job, that forgotten A100 endpoint, that Agent Builder query volume spike. Teams get alerted before the invoice arrives.
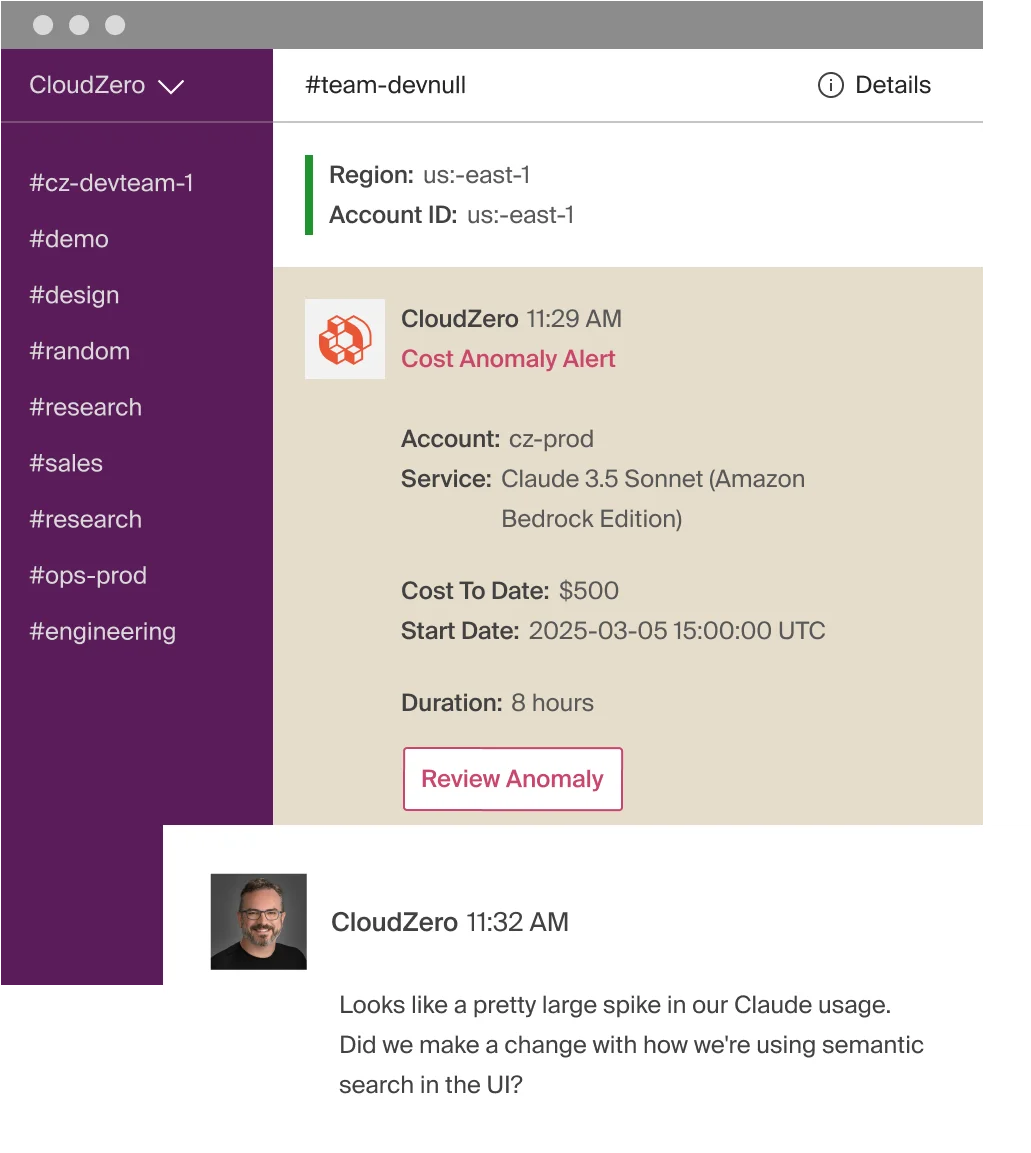
Forecasting and budgeting
CloudZero projects AI spend based on actual usage patterns, giving finance teams data-driven budgets instead of spreadsheet guesswork.
CloudZero manages $15 billion+ in cloud and AI spend across global organizations such as Upstart, PicPay, Toyota, Duolingo, Coinbase, Skyscanner, among others.  to see CloudZero in action. You can also start with a free cloud cost assessment to find where your AI spends today.
to see CloudZero in action. You can also start with a free cloud cost assessment to find where your AI spends today.
FAQs











