

The most successful brands are data-driven. Whether it’s Google, Amazon, or TikTok, they all use data to inform their next moves. But here’s the thing. It’s easy to collect a lot of data. Making sense of all that data is often the most challenging part.
You can do that in three ways.
Scripting is one option. Here, your developers code custom data integration tools in Python and Java alongside technologies like Hadoop and Spark. Taking this route means you’ll maintain your own system, create custom documentation, test consistently, and update it continuously.
This takes time, requires many expert hands, and is still prone to mistakes. Scaling such a custom system is also tricky.
Another option is to use a traditional ETL tool. Here, you employ a tool that combines a graphical interface and custom scripts to move data for further analysis.
The third way is to use an end-to-end ETL tool to automate data extraction, transformation, and loading. This is the most efficient pipeline for both on-premises and cloud data ETL applications.
Here’s what the ETL process is, how ETL tools work, and some of the best ETL tools you can use now.
What Is ETL?
ETL stands for Extract, Transform, and Load. ETL involves pulling data from various sources, standardizing it, and moving it into a central database, data lake, data warehouse, or data store for further analyses.
Here’s how that looks:
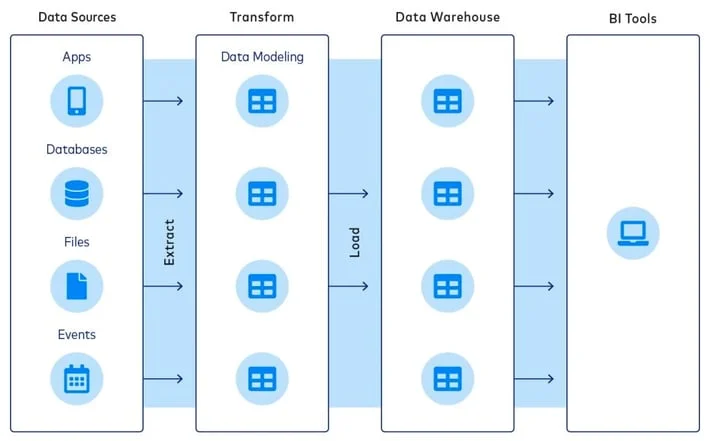
Credit: FiveTran
The ETL process takes structured or unstructured data from multiple sources and processes it into a format your teams can readily understand and use daily. Each stage of the end-to-end ETL process involves:
1. Data extraction
Extraction involves retrieving unstructured and structured data from one or more sources. These sources include websites, mobile apps, CRM systems, on-premises databases, legacy data systems, analytics tools, and SaaS platforms. After the retrieval completes, the data loads into a staging area, awaiting transformation.
2. Data transformation
The transform stage takes the extracted data, cleans it up, and formats it for storage on your desired database, data store, data warehouse, or data lake. The goal is to prepare the data for querying inside the target storage.
Cleaning data typically involves:
- Cleaning corrects for inconsistencies and missing values.
- Standardizing involves formatting according to a set of rules so that its values and structure are consistent with the intended use case.
- Deduplicating removes or discards redundant data.
- Verifying removes unusable data and flags anomalies.
- Sorting organizes data according to type to make it even more usable.
The point of transforming data is fitting it within a consistent schema before moving it to the destination storage. Typical transformations include data masking, aggregators, filter, normalizer, expression, joiner, lookup, H2R, union, R2H, router, rank, XML, and web service.
3. Load
Loading involves moving formatted data into the target database, data mart, data hub, warehouse, or data lake. There are two ways to load data: incrementally (incremental loading) or all at once (full loading). You can also load the data in real-time or schedule it to load in batches.
By evaluating incoming data against existing data, incremental data loading avoids duplication. A full loading takes everything from the transformation assembly line and moves it to the destination warehouse or repository.
playbook
The AI Cost Optimization Playbook
Traditional cloud cost management is broken. Here’s why — and how to make the switch to cloud cost intelligence.
What Do ETL Tools Do?
An ETL tool automates the entire ETL process. Rather than writing code to extract, transform, and load data manually, ETL tools use various data management techniques to automate the process, reduce errors, and speed up data integration. There’s more. ETL tools use cases include:
- Automate the ingest, processing, and management of massive volumes of structured and unstructured data on-premises and in the cloud.
- Deliver data securely to a suitable analytics destination.
- Make it easier to view, compare, and understand recent and older datasets by organizing them in a historical context.
- Replicate databases from MongoDB, Cloud SQL for MySQL, Oracle, Microsoft SQL Server, and AWS RedShift to a cloud data warehouse. You can use ETL tools to update your data either once or continuously.
- Enable seamless cloud migration by moving on-premises data, applications, and workflows to the cloud.
- Move data from various IoT devices to a single place where you can analyze it further.
- Combine customer support, social networks, and web analytics data into one place for more detailed analysis.
So, which ETL tools are there, and what makes them different?
What Are The Types Of ETL Tools?
There are traditional ETL tools, and then there are cloud ETL tools. There are more unique types of ETL tools within these two categories.
1. Custom ETL Solutions
Organizations with expertise in data engineering and ETL pipelines build, manage, and design custom solutions and pipelines. They may build their data pipelines using SQL or Python scripts or Hadoop workflows. However, this option is time-consuming, labor-intensive, and error-prone despite offering great compatibility and usability.
2. Batch ETL tools
These tools extract data from a variety of sources using batch processing. Extracting, transforming, and loading data takes place in batches. Since the method uses limited resources efficiently, it is cost-effective.
3. Real-Time or Streaming ETL tools
These tools can extract, enrich, and load data in real time. So, this type of ETL tool is becoming increasingly popular as organizations seek actionable insights as soon as possible.
4. On-Premise ETL tools
Some ETL solutions are better suited for on-premises and legacy systems, such as old databases, which use old data management protocols. Others use more modern ETL software to ensure data security and comply with single-tenant architecture standards.
5. Cloud ETL tools
Cloud-based ETL solutions manage large amounts of data from various cloud-enabled and cloud-native sources. They make data much more accessible to stakeholders from anywhere, provided they have express permission.
6. Open-source ETL Tools
Different organizations can build their own ETL tools on top of open-source ETL software. By doing this, they’ll no longer be dependent on third-party tools or companies to integrate, store, secure, and analyze their sensitive data.
7. Hybrid ETL tools
A number of ETL solutions combine features from different ETL platforms to enhance flexibility. The result? One ETL platform that can handle multiple data management tasks at scale.
32 Top ETL Tools In 2025
Here’s the deal. The best ETL tools must be capable of speedy ingest, normalization, and load data workflows. They must also work with structured and unstructured data, accommodate real-time analysis, and handle transactions from virtually any source (whether on-premises or cloud-based).
This is true for enterprise ETL solutions and solutions designed for smaller brands with fewer scalability, analytics, and continuous data integration requirements.
That said, here are some of the top ETL solutions to consider right now.
1. Informatica PowerCenter – Cloud data management solution
Despite its easy-to-use graphical interface, Informatica’s PowerCenter is an enterprise-grade data management system. It is AI-powered, supports on-premises and cloud-based ETL requirements, and is a low code/no-code platform. In addition, it facilitates multi-cloud, hybrid/multi-hybrid cloud, and custom ETL rules.
With PowerCenter, you can complete your ETL needs in one place, including analytics, data warehouse, and data lake solutions. Among Informatica PowerCenter’s many features are extensive automation, high availability, distributed processing, connectors to all data sources, automated data validation testing, and dynamic partitioning.
A few of the files the platform supports include JSON, Microsoft Office, PDF, XML, and Internet of Things (IoT) data. Also, the software supports a variety of third-party databases, including Oracle and SQL.
2. Microsoft SQL Server Integration Services – Enterprise ETL platform
Microsoft SQL Server Integration Services (SSIS) enables the development of high-performance data integration, transformation, and migration solutions at a relatively low cost. It includes extract, transform, and load (ETL) features for data warehousing. The SSIS software is suitable for mining data, copying or downloading files, loading data into warehouses, cleaning it, or administering SQL Server objects or data.
You’ll also want to consider SSIS when loading data from multiple sources, such as flat files, XML files, and relational databases.
Being a Microsoft offering means it offers native support for Azure cloud operations and many on-premises use cases.
3. Talend Data Fabric – Enterprise data integration with open-source ETL tool

Talend offers several solutions for data integration and management in one place. That includes Talend OpenStudio, Big Data Platform, and Stich Data Loader. The Talend Data Fabric provides end-to-end data integration and governance for handling on-premises and cloud data.
It supports cloud, hybrid cloud, and multi-cloud environments. You can also use it with virtually any public cloud provider and cloud data warehouse. You’ll also have hundreds of built-in integrations to work with, so you can extract and transform data from nearly any source and load it to a destination of your choice. You can also enhance your Talend edition’s capabilities by adding tools for Big Data, app integration, and other data solutions.
4. Integrate.io (XPlenty) – ETL tool for e-commerce
Integrate.io provides a low-code data integration tool for businesses collecting, processing, and analyzing e-commerce data. It integrates easily with Shopify, BigCommerce, Magento, and NetSuite. However, it also includes capabilities that are useful in other industries, like healthcare, SaaS, and e-learning.
Integrate.io helps extract data from any RestAPI-enabled source. You can build a RestAPI using the Integrate.io API Generator if there isn’t one already. Once you’ve transformed the data, you can load it into various destinations, such as databases, NetSuite, data warehouses, or Salesforce.
Integrate.io provides Business Intelligence (BI) and reverse ETL tools to distribute cleansed data to various stakeholders. In addition to SOC II certification and field-level encryption for data security, It also provides GDPR readiness and data masking to ensure regulatory compliance.
5. Stitch – Modern, managed ETL service
Talend’s Stitch Data is a fully managed, open-source ETL service with ready-to-query schemas and a user-friendly interface.
The data integration service can source data from over 130 platforms, apps, and services. Then, it can route data to over 10 destinations, including Redshift, Snowflake, and PostgreSQL.
As a no-code tool, you won’t need to write code to integrate your data in a warehouse. It is also scalable and open-source, so you can extend its capabilities as your needs grow. Additionally, it provides compliance tools for both internal and external data governance.
6. Pentaho by Hitachi Vantara – Open-source data integration platform

The Pentaho solution simplifies retrieving, cleansing, and cataloging data so that different teams can use it in a consistent format. The tool facilitates access to IoT data for machine learning purposes. It is also highly scalable, enabling rapid and on-demand analysis of huge amounts of data.
Pentaho Data Integration also provides the Spoon desktop client. The tool enables you to build transformations, schedule jobs, and manually start processing tasks. PDI is also suitable for leveraging real-time ETL as a data source for Pentaho Reporting. It also supports no-code operations and OLAP services.
7. Oracle Data Integrator – Enterprise ETL platform with real-time application testing support
Oracle Data Integrator’s main advantage is that it loads data into the destination first, then transforms it (ELT vs. ETL) using the database’s features or Hadoop cluster’s capabilities.
Still, ODI enables access to other powerful data integration and management features via a flow-based declarative UI. This includes SOA-enabled data services, high-performance batch loads, and deep integration with Oracle GoldenGate.
ODI has long provided a tested platform for high-volume data workflows in various use cases. It is also relatively easy to monitor with Oracle Enterprise Manager.
8. Hevo Data – Managed data pipeline
Hevo is a no-code, real-time, and fully managed data solution that extracts and transforms data from over 150 sources. It also loads the normalized data into a destination of your choice as needed.
You can load data from different sources, including NoSQL databases, relational databases, S3 buckets, SaaS applications, and files into 15 distinct data warehouses (from Amazon Redshift to Google BigQuery to Snowflake).
With its streaming architecture, Hevo detects schema changes within incoming data and automatically replicates them to your chosen destination. Hevo transformations include drag-and-drop ones like Event Manipulation, Date and Control Functions, and JSON.
Hevo’s reverse ETL solution, Hevo Activate, helps you transfer data from your Hevo data warehouse to different teams and business applications.
9. FiveTran – Quick ETL with fully managed connectors

Some of the best FiveTran features include simple data replication, automated schema migrations, and many connectors. In addition, FiveTran uses a sophisticated caching layer to move data over a secure connection without ever storing a copy on the application server.
Pre-built connectors help transform data faster. These connectors are fully managed, enabling you to automate data integration without compromising reliability. Expect complete replication by default. Its low-impact change data capture (CDC) database replication helps move large volumes of data.
10. IBM InfoSphere DataStage – Modern enterprise ETL solution with big data and Hadoop support
IBM’s data governance and integration platform is popular with users in many industries, including finance, healthcare, and life sciences. InfoSphere DataStage enables you to create and manage jobs via a Windows client using a server-based repository. You can do this on an Intel, UNIX, or LINUX server or an IBM mainframe.
With the software, you can integrate your data across multiple sources on demand, regardless of the volume of data. It can also target applications using a high-performance parallel framework.
Whether you have large servers or mainframes, IBM InfoSphere DataStage can handle high-volume processing and data, enterprise-level connectivity, and metadata governance. It also supports on-premises and cloud-based workflows and a wide range of connectors, including JSON, AWS, Snowflake, Azure, Teradata, Google, Hive, SyBase, Kafka, Oracle, and Salesforce.
11. Denodo Platform – Logical data warehouse and operational tool
The Denodo Platform excels in big data, operations, and logical data warehouses. Self-service data discovery and search help you find and use your data faster. It also connects to various data sources, such as web, unstructured, and semi-structured data from any source and format.
Expect high-performance adapters across all primary sources, like relational databases, Web, Hadoop, multidimensional databases, NoSQL (key-value, document, triple, columnar, and graph), streaming data, web services (SOAP/WSDL and REST), flat files (Excel, XML, Log, Delimited), email, and documents (Word, PDF).
Denodo provides a connector SDK for unsupported data sources, including an Eclipse plugin, to simplify connections to custom data sources. Some big data sources it supports include Amazon Redshift, Impala, HP Vertica, Apache Spark, Teradata, Hive, Netezza, and Greenplum.
12. Amazon Web Services ETL Services
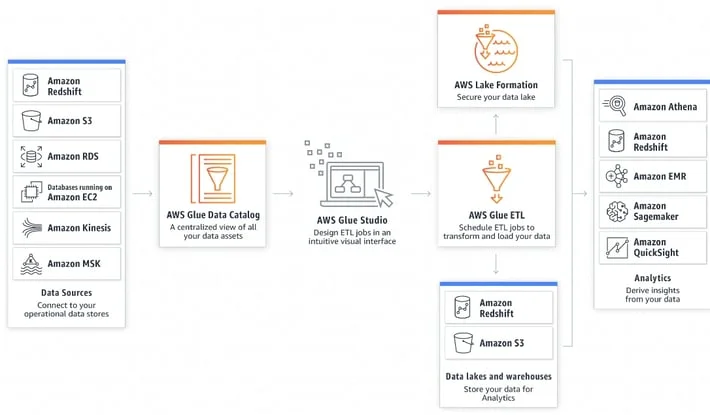
AWS offers two primary cloud ETL services:
AWS Elastic MapReduce (EMR) is a cloud big data platform ideal for running large-scale and distributed data processing workflows and interactive SQL queries.
You can also use it for Machine Learning (ML) use cases with open-source tools, such as Apache Hive, Apache Spark, and Presto. EMR is robust, scalable, and capable of working with structured and unstructured data. Besides, you only pay for what you use, although some might find it tricky.
AWS Glue is a fully managed, no-code, serverless data integration service ideal for extracting, transforming, and loading semi-structured data.
It organizes, cleanses, validates, and formats data for storage in data lakes or warehouses.
AWS Glue comprises a centralized metadata repository (AWS Glue Data Catalog), an ETL engine that auto-generates Scala or Python code, and a scheduler that manages dependency resolution, retries, and job monitoring. Glue offers native integration with other AWS services, like Amazon S3, Amazon RDS, Amazon Redshift, and AWS Lambda (serverless).
With AWS data services, pricing is on a pay-as-you-go basis, which allows you to take full advantage of the AWS ecosystem.
13. Matillion ETL – Extract, load, transform (ELT) for enterprises and SMBs
The Matillion ETL solution is unique because it is enterprise-grade and supports small and medium-sized business use cases. It is also a cloud-native ETL platform that makes sense of data at every stage of its lifecycle: data preparation, transformation, integration, analytics, and storage in a data lake or warehouse.
Another unique feature is that Matillion lets you speed up transformations by loading data before transformation (ELT vs. ETL). The Matillion Data Loader allows you to run CDC and batch pipelines without coding expertise, so most of your people won’t struggle to access the business intelligence it offers.
Matillion’s ETL tool includes adequate connectors out of the box and supports many cloud data warehouses, such as Snowflake, Amazon Redshift, Delta Lake, Microsoft Azure Synapse, and Google BigQuery.
14. Skyvia – Data integration SaaS
Devart’s Skyvia is a modern data platform with code-free solutions like data integration, data management, and cloud backup. It offers over 90 connectors and supports many cloud use cases, including apps, file storage services, databases, and data warehouses.
APIs allow you to work uniformly with data from different sources, just like relational databases. Skyvia’s data integration tool supports ETL, ELT, and reverse ETL capabilities.
Its cloud data import feature lets you use a wizard-based ETL solution for data imports, migrations, and continuous integrations. So, you can move your data visually between different sources without writing any code.
15. Portable – Extensive ETL connector support
Portable boasts support for over 500 ETL connectors that work with the common data warehouses and platforms: Amazon Redshift, Snowflake, MySQL, BigQuery, PostgreSQL, and even Google Sheets.
The platform designed this combo to help you minimize using scripts, infrastructure, or suffer missing data. The cloud ETL tool supports the long tail of business applications with comprehensive coverage and rapid development.
16. Azure Data Factory – Scalable, serverless data integration

If you are looking for a Microsoft ETL, Azure Data Factory may be the data integration service to beat. It is especially suitable for simplifying hybrid data integration at the enterprise scale. It supports that because it is not only serverless but also fully managed, reducing your ETL management effort.
Also, you can expect over 90 connectors to work with your favorite data warehouses and platforms and pay-as-you-go pricing. The platform also lets you build an ETL or ELT (extract, load, and transform) with your own code or code-free. Plus, it works natively with other Azure data analytics tools.
17. Upsolver – Streaming and batch data lake ETL
The Upsolver cloud data ingestion platform markets itself as a robust streaming and batch data lake ETL with SQL.
It simplifies the Extract, Transform, and Load process for live data streams and historical big data into Amazon Athena, Relational Database Service (RDS), Redshift, and ElasticSearch using the familiar ANSI SQL. It is self-service, and you can build your streaming data pipelines without Apache Spark or Hadoop.
18. Apache NiFi – Flow-based data automation
Apache NiFi uses flow-based programming. It offers a clean web UI, supports drag and drop, and offers scalable data transformation and routing methods. You can implement the methods on a single server or across several servers in a cluster.
NiFi workflow processors can validate, process, filter, split, join, or alter data. Its FlowFile Controller manages the resources between the components while they transfer data as FlowFiles over connected queues. Also, you can use LDAP to support role management (authorization).
19. Blendo – Self-serve ETL and ELT integration

Blendo.co is an ETL and ELT data integration and pipeline tool. The self-serve platform does not require endless configuration, scripts, or coding to integrate multiple data sources into your databases or cloud data warehouse.
It offers analytics-ready tables and schemas and optimizes them to support analysis with most BI software. You can also integrate it quickly with analysis tools like Looker, Google Data Studio, Tableau, and Power BI to make the most of your raw data.
20. Onehouse – Fully managed interoperable data lakehouse
If you are concerned about locking your data infrastructure to just one vendor and want to prevent vendor lock-in, Onehouse is an interoperable data lakehouse.
The fully managed lakehouse is powered by Apache Hudi and supports incremental streaming and modern batch processing with managed ingestion.
With its Onetable offering, you can leverage the scale, interoperability, and lower costs of Apache Hudi-based data lakehouses and still enjoy native performance accelerations in Snowflake and Databricks.
21. Google Cloud Dataflow – Serverless batch and streaming data processing
The Google Cloud Platform (GCP) offers a portfolio of ETL-enabling tools, including Dataflow, Dataproc, and Cloud Data Fusion.
Dataflow is a serverless offering that supports fast, cost-effective, and unified batch and streaming data processing. The service offers several other packs, including exactly-once processing and horizontal autoscaling of worker resources.
22. Qlik Compose – Automated data warehouse design and ETL
Qlik Compose, which acquired Attunity, provides a flexible data warehouse automation tool. It empowers you to simplify data warehousing design, development, rollout, and optimization on an enterprise scale. Qlik Compose for Data Warehouses automates the creation and operation of data warehouses.
The tool helps automate warehouse design, ETL code generation, and applying updates quickly and with low risk, thanks to using proven design patterns. It does this whether you use it on-premises or in the cloud.
23. Segment – Customer data platform with ETL and reverse ETL
Segment combines Twilio’s customer data infrastructure with reverse ETL tools to gain deeper insight into customers.
The tool supports over 400 integrations, so you can leverage the data sources and BI tools you already use. Using Twilio Segment, you can sync customer profiles directly to a data warehouse such as Redshift, BigQuery, or Snowflake.
You can then integrate your analytics and business intelligence tools. Afterward, you can sync the data back to the sources/your teams’ systems.
24. Etleap – Managed ETL for AWS data integration

You can deploy Etleap with a VPC or as a hosted service on the Amazon Web Services (AWS) platform. The managed service delivers out-of-the-box ETL infrastructure, cutting out time-consuming coding, scripting, or infrastructure management.
You can also expect an interactive data wrangler, managed dependencies when modeling your data with SQL, and pipeline orchestration and scheduling.
25. Keboola – Collaborative data integration and automation
Keboola provides data engineers, analysts, and engineers with a platform for collaborating on analytics and automation, from data extraction, transformation, and data management to reverse ETL and data integration. It supports hundreds of integrations, is a complementary Snowflake data warehouse, and runs transformations in SQL, R, and Python.
It also boasts an easy-to-use platform, no-code data pipeline automation, and version control support.
26. Rivery – Cloud-based ETL with automation
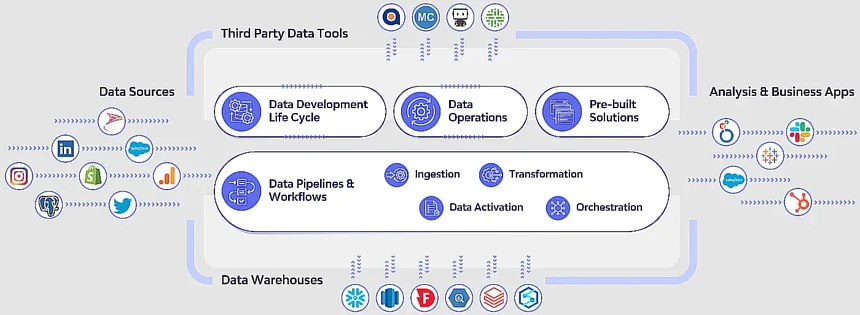
Rivery is a cloud-based ETL platform (and SaaS ELT platform). Yet you can also use custom code to make the solution work for you. It provides an end-to-end solution for ingesting, transforming, orchestrating, activating, and managing data.
You can also perform reverse ETL tasks to improve your outcomes further. Its over 200 connectors are fully managed, enabling you to connect to databases, apps, data warehouses, and file storage systems with ease and speed.
27. SAS Data Management – Enterprise data integration and governance
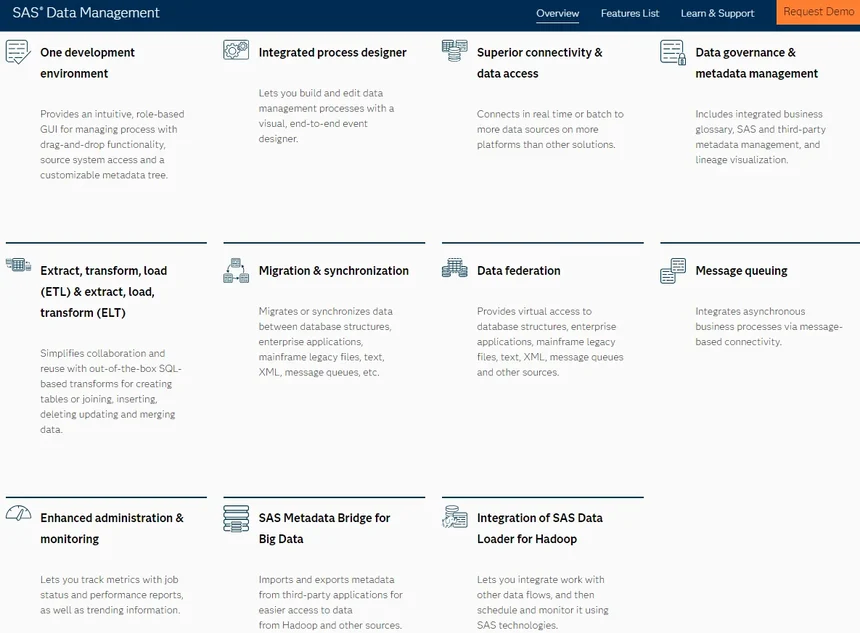
SAS Data Management helps data analysts access the data they need wherever it is, from the cloud and legacy systems to data lakes, such as Hadoop.
You can define your data management rules once and reuse them, improving and integrating your data in a standard, repeatable way –- and at no additional cost. The ETL platform is also popular for supporting a variety of computer tiers, file systems, databases, and database systems.
28. Statistica by Tibco – Advanced analytics and data management
Statistica ETL secures and simplifies managing multiple database connections for various databases, including process databases.
With Statistica Enterprise, you can store metadata specifying the nature of the tables queried, including control limits, valid data ranges, and specification limits. It automates validating and aligning multiple data sources to create a single source for automated or ad-hoc analysis.
With Statistica Enterprise, you can write data back to dedicated database tables or Statistica data tables. This means you can easily access real-time performance data without needing to preprocess or clean data before extracting actionable insights.
29. Astera Centerprise ETL – High-performance, no-code ETL platform
Astera’s ETL solution promises a high-performance yet easy-to-use platform to power your data-driven innovation.
It supports high performance with a cluster-based architecture that distributes workload across multiple nodes to speed up integration and transformation even with large datasets. It also supports all data formats, a code-free UI, defining data quality rules, process orchestration, and a library of connectors.
30. Qubole Pipelines Service – Stream processing and real-time ETL
The Pipeline Service is a Stream Processing Platform-as-a-Service (PaaS) designed to support real-time data ingestion and reporting scenarios. The service is designed with data engineers as primary users and data scientists, analysts, and developers as secondary users.
You can move data with transformations and live from sources such as Kinesis and Kafka to targets like Amazon S3, Apache HIVE, and Snowflake. But Qubole does more than ETL, including big data visualization and self-service analytics.
31. BryteFlow – Real-time data replication and integration
Formerly Bryte Systems, BryteFlow enables you to replicate and integrate enterprise-scale data in real-time, spanning transactional databases, on-premises systems, and cloud-based environments.
BryteFlow reconciles your data with the data at source and sends alerts and updates when data is incomplete or missing. It also supports direct load to Snowflake and Redshift.
32. Airbyte – No-code ETL
Airbyte’s ETL offering delivers over 300 no-code and pre-built connectors with over 30 destinations. It also offers end-to-end automation, so you don’t have to kill time managing the connectors.
Also, expect intuitive integration with tools like dbt, Dagster, Airflow, and Prefect. If you are a data analyst or engineer, Airbyte provides an intuitive UI, API, and Terraform Provider to help you run your pipelines faster.
What Next: How To Optimize Your Extract, Transform, And Load Costs With CloudZero
Using an ETL tool should be profitable. If it is not, you are probably spending a fortune on data transfer and related cloud costs. So, you need to manage these costs to protect your margins.
Yet, without complete cost visibility, optimizing data-related costs can be challenging. In other words, you may struggle to cut costs without hurting your data-driven operations if you can’t see who, what, and why your costs are what they are.
So, can you automate cost optimization without hiring more data scientists, developers, and finance professionals?
CloudZero can help you visualize, understand, and act on cloud cost insights, including data-related costs, across AWS, Kubernetes, Snowflake data cloud, Databricks, New Relic, and more.
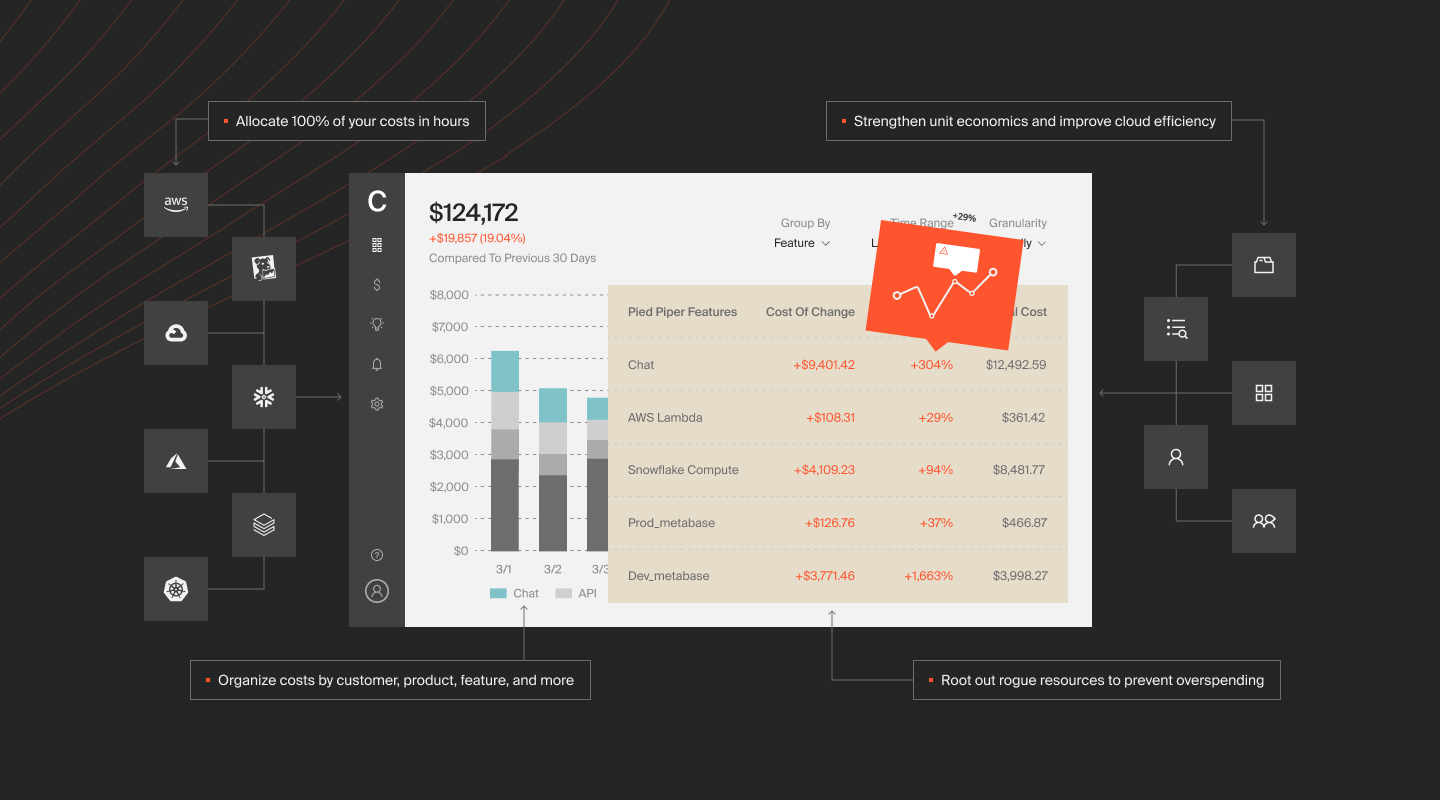
Like your favorite ELT or ETL tool, CloudZero ingests vast amounts of cloud cost data, enriches it, and prepares it for engineering, finance, and C-suite decision-making. No coding or endless tagging required.
With CloudZero, you get accurate, easy-to-digest cost information for your tagged, untagged, and untaggable resources. You also get cost information for shared resources in a multi-tenant environment. This helps you see which specific tenant(s) drive your cloud costs.
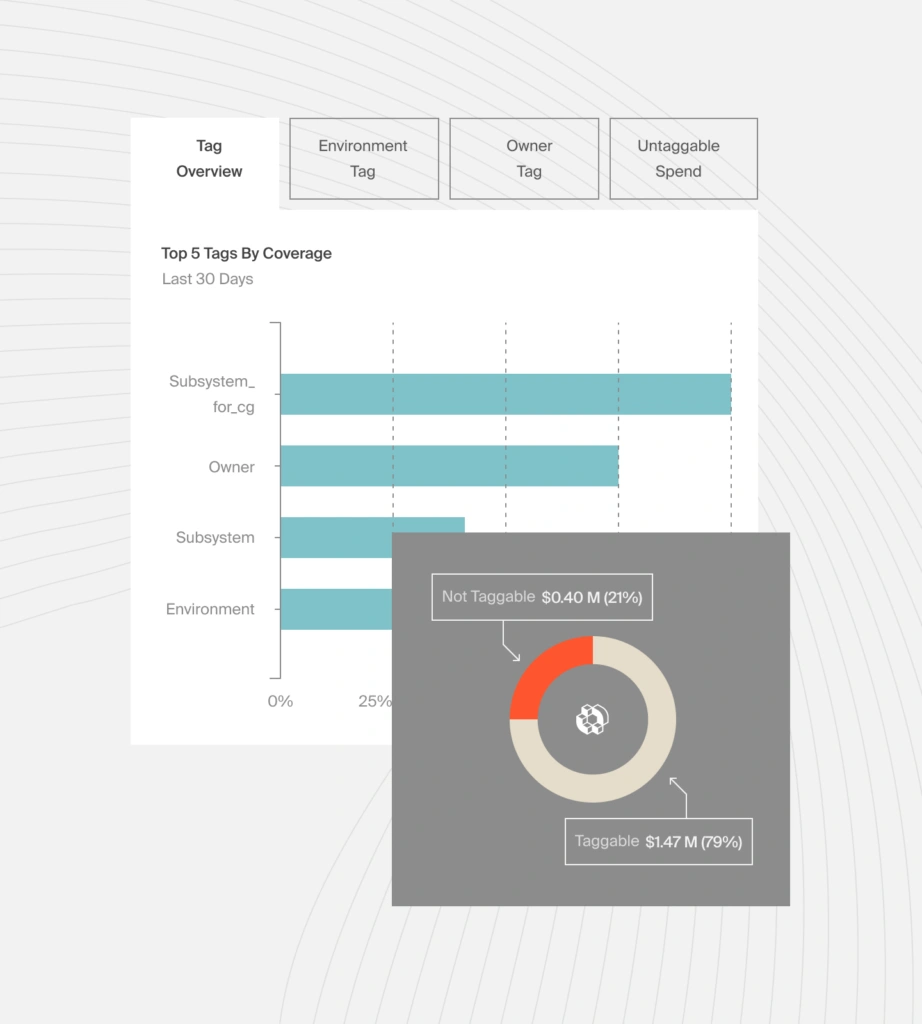
Better yet, you can sort and see the cost intel by customer/tenant, product, product feature, team, environment, department, and more business dimensions.
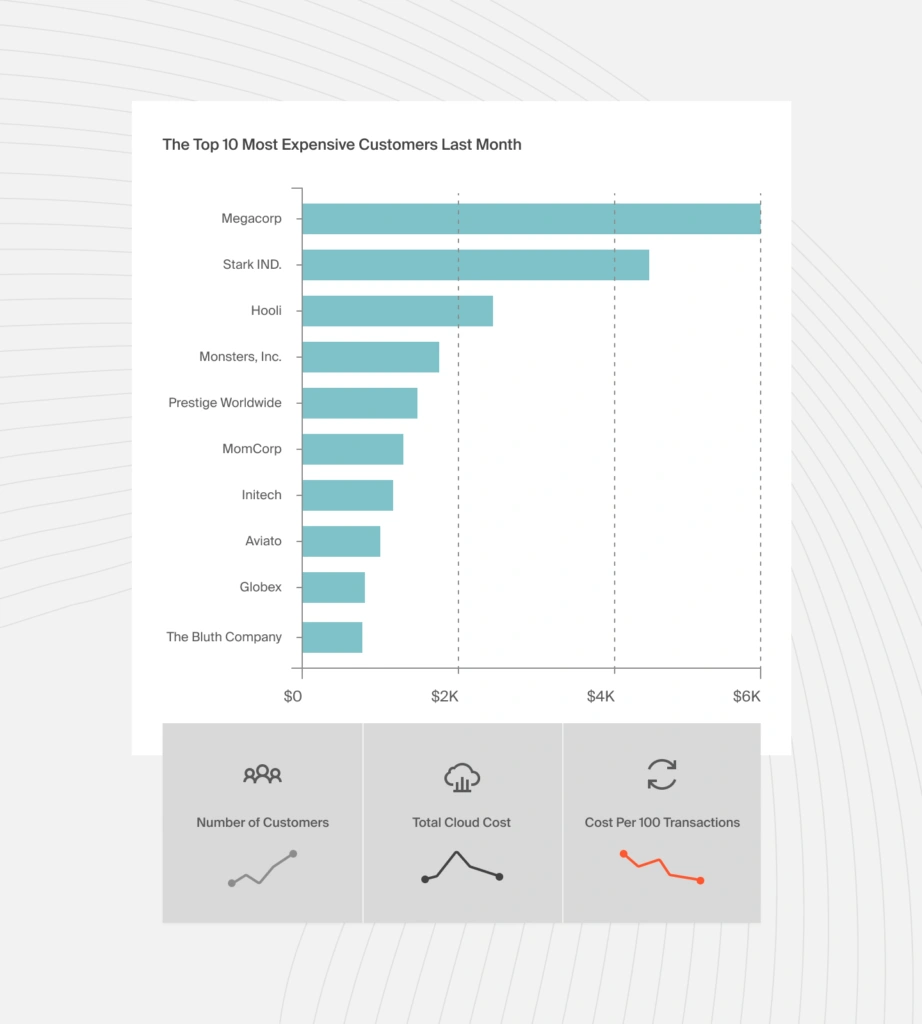
You’ll more easily determine where to cut costs or invest more to earn higher returns. For example, you can tell which customer’s subscription contract to review at renewal to protect your margins. Or, identify the most profitable customer segments, then target them more to boost profits.
Want to see how CloudZero does that?  . It’s free, and we’ll provide a CloudZero Cost Analyst to help you get started.
. It’s free, and we’ll provide a CloudZero Cost Analyst to help you get started.











