
Running workloads on Google Kubernetes Engine (GKE) delivers impressive scalability and flexibility. Yet, it can also introduce a tricky challenge: tracking GKE costs accurately.
Remember, GKE costs rarely scale linearly. Overprovisioned nodes, idle autoscalers, and orphaned workloads can quietly balloon your bill in the background. And while GKE’s native tools offer some visibility, they often miss the full picture.
This is especially true when attributing spend across teams, environments, or shared infrastructure.
That’s why we’ll unpack how GKE cost allocation works, where built-in solutions fall short, and how to gain meaningful, actionable visibility into your Kubernetes spend.
What Is Google Kubernetes Engine?
Google Kubernetes Engine (GKE) is a managed Kubernetes service within the Google Cloud ecosystem. GKE helps you automate container orchestration, scaling, and infrastructure management.
It’s built to help your team deploy, manage, and scale containerized applications without worrying about the underlying infrastructure.
With features like automatic upgrades, node auto-repair, and native integration with Google Cloud services, GKE simplifies complex Kubernetes operations.
But it also introduces cost challenges, especially when your workloads scale dynamically and resources are shared across teams or environments.
Report
Finance needs to prove AI’s return: CloudZero report
260 senior finance leaders (more than half CFOs) told us why the speed of seeing AI spend, not the size of it, separates who pulls ahead on AI from who gets burned.
How Does GKE Cost Allocation Work?
GKE cost allocation works by attributing your Kubernetes resource usage to specific workloads, namespaces, and labels. It then maps that usage to the underlying infrastructure costs in your Google Cloud bill.
At a high level, here’s how it works:
- Resource-level tracking: GKE monitors CPU, memory, and storage consumption by pods, containers, and nodes.
- Namespace and label-based attribution: You can tag workloads using Kubernetes labels (such as team=backend, env=prod), which GKE uses to group and attribute costs.
Related read: 12 Kubernetes Labels Best Practices To Apply ASAP
- Integration with Cloud Billing: These usage metrics are paired with pricing data from your Google Cloud billing account to produce cost breakdowns by workload, namespace, or label.
- BigQuery export: If enabled, detailed cost data can be exported to BigQuery, letting you run custom queries and build dashboards that reflect your organization’s structure.
For example, if your production cluster runs three services across two teams, and each service is labeled correctly, GKE can allocate the node and compute costs to those teams proportionally, based on their usage.
This setup is especially useful for multi-team environments, FinOps reporting, or enforcing budget accountability per workload.
However, accurate GKE cost allocation depends heavily on well-maintained labels and consistent namespace usage, which leads us to the next critical point.
What Are The Limitations Of GKE Cost Allocation?
GKE’s built-in cost allocation features offer a good starting point. However, they fall short when you need deeper, more actionable cost insights, especially in complex environments. Consider the following:
- Over-reliance on labels: GKE cost attribution is only as accurate as your labeling practices. If your workloads are missing labels or are inconsistently tagged, the cost data becomes fragmented or misleading.
- Lacking in business context: Native tools can show you costs by namespace or label. However, they can’t easily tell you how much you spend per customer, product feature, or engineering team. That is, unless you manually structure your labels that way.
- No real-time cost insights: GKE doesn’t offer real-time visibility into cost spikes or anomalies. You’re often looking at lagging data. That makes it hard to catch budget overruns before they happen.
- Limited shared resource breakdowns: Resources like nodes or persistent volumes used across multiple workloads are hard to split cleanly. GKE may allocate these costs equally or arbitrarily. And that can lead to skewed insights.
- Manual analysis overhead: To get anything close to detailed reporting, you typically need to export billing and usage data into BigQuery. Then you need to build your own queries or dashboards. That takes time, tooling, and expertise you may or may not have.
In short, while GKE gives you cost data, it often misses details into the “who, why, and now what”. Yet, these are critical to driving smarter cost decisions in Kubernetes environments.
How GKE Cost Allocation Differs From Cluster Usage Monitoring
Cluster usage monitoring focuses on how your GKE resources are being consumed. It details factors such as:
- CPU and memory utilization per pod or node
- Which workloads are over- or under-provisioned
- Resource saturation, bottlenecks, and idle capacity
This data is crucial for performance tuning and right-sizing workloads. However, it doesn’t explain what those resources are costing you, or who is responsible for the spend.
GKE cost allocation, on the other hand, is about assigning actual dollar amounts to specific workloads, teams, environments, or applications based on your resource usage.
Good cost allocation in GKE bridges the gap between technical resource consumption and financial accountability. And, as you’ve likely noticed, the real power comes from combining both. You get to see what’s happening and also what it’s costing you.
Related reads:
Now, if that’s something you want, here’s how to start taking advantage of it.
Enable GKE Cost Allocation With These Steps
While it takes some initial setup, Google Cloud provides native support to get you started. Here’s how to enable and configure GKE cost allocation to work efficiently:
1. Enable GKE cost allocation in your cluster
When creating or updating your cluster, set the –enable-cost-allocation flag via the Google Cloud CLI or enable it in the Console. This activates resource usage tracking that maps to GCP billing data.
2. Label your Kubernetes workloads
GKE uses Kubernetes labels to group resource usage by team, app, or environment. Apply consistent labels such as team=frontend, env=prod, or service=checkout. Also, consider enforcing label standards using policies or admission controllers to prevent missing or inconsistent tags.
3. Export billing data to BigQuery (it’s optional but recommended)
Set up BigQuery export to access detailed billing data and run SQL queries that break down spend by label, service, or resource type. You can build custom dashboards in Looker Studio (formerly Data Studio) or plug into tools like Grafana for visualization.
Now consider this:
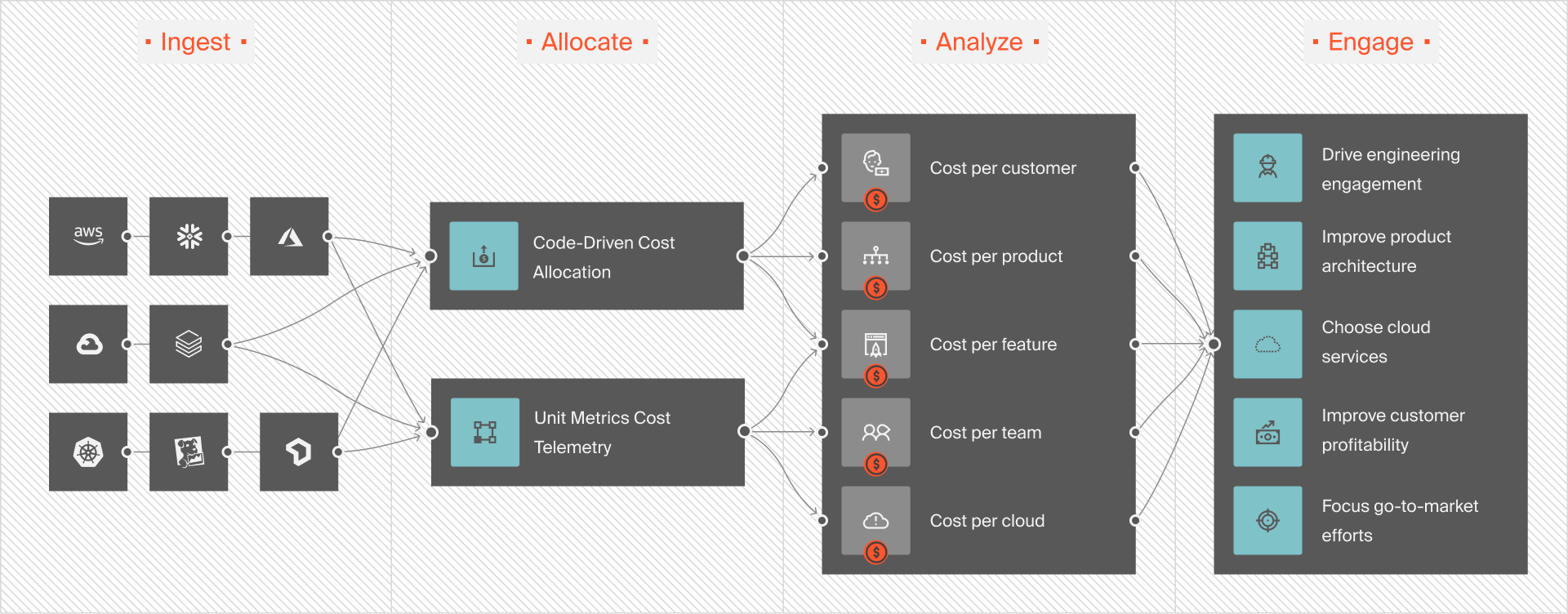
For deeper, more actionable insights, such as cost per service, team, or even individual customer, integrate CloudZero directly with Google Cloud.
4. Use Budgets and Alerts
Create budgets per project or service and set up automated alerts in the GCP Billing console. This won’t stop runaway spend. However, it will give you early warnings if costs exceed expectations. What can help you stop runaway spending is…
5. Integrating with robust cost visibility tools for GKE (when native tools fall short)
If you need deeper insights, like cost per customer, real-time K8s cost data, or cost per deployment metrics, consider integrating a tool like CloudZero (take the free product tour here). Or, you can build a custom FinOps dashboard.
Overall, enabling GKE cost allocation sets the foundation. But extracting real value requires discipline with tagging, consistent monitoring, and supplementing with tools that bring business context to your Kubernetes costs.
Here’s what else you can do to improve your cost allocations in GKE.
Apply These Tips To Improve GKE Cost Visibility and Control
To truly understand and control your GKE spend, especially in large or multi-tenant environments, you need to go beyond the basics.
Consider these battle-tested tips:
Standardize and enforce labeling
Create a company-wide label taxonomy for Kubernetes workloads. Think of team, environment, customer, application, etc. Additionally, use automated policies or admission controllers to ensure compliance and avoid unlabeled workloads slipping through.
Related reads:
Break down costs by business dimension
Don’t limit yourself to viewing your GKE usage by namespace. Also, align your GKE cost allocation with how your organization operates, such as per project, per team, or per customer. This granularity adds clarity for both engineering and finance stakeholders.
Also see: 3 Common GCP Billing Challenges — And How CloudZero Overcomes Them
Track idle and overprovisioned resources
Use usage metrics (such as from Prometheus) alongside cost data to identify inefficient workloads. That includes budget killers like pods with allocated CPU far above actual usage.
Set cost alerts by label or namespace
Instead of only watching the total bill, set budget alerts that trigger when individual workloads, teams, or environments go over a defined threshold. This will help you catch anomalies before they show up on your GKE bill.
Establish a regular Kubernetes cost review rhythm
Treat GKE cost visibility as part of your engineering and FinOps cadence. Regular reviews can reveal trends, justify resource requests, or highlight areas for optimization. You can start with this free cost assessment.
Related read: 8 GKE Monitoring Best Practices To Apply ASAP
Combine cost and performance data
Overlay cost insights with performance metrics to make smarter tradeoffs. For example, you can use the data to decide whether to downsize an overprovisioned service — without impacting user experience.
Use chargeback or showback models
Share cost data with internal teams or departments based on their actual resource usage. This fosters accountability and encourages more cost-aware engineering decisions. Over time, it will help your team build cost-efficient systems from the start, turning cloud cost optimization into a core part of your architecture — not an afterthought.
Related read: Engineering-Led Optimization: How To Proactively Manage Cloud Costs Without Slowing Down Innovation
Ultimately, cost visibility is power. The more clearly your team can see how their Kubernetes usage translates into dollars, the more likely they are to optimize it. You can start by getting the GKE cost data that native and conventional cost tools miss. Here’s how.
Get Granular Spending Insights To Inform Your Resource Allocation
Native GKE cost allocation tools are a solid starting point. But when managing multiple teams, tenants, or dynamic workloads, you need more than basic cost breakdowns and post-hoc reports.
CloudZero, trusted by innovative teams at Wise, Moody’s, and Malwarebytes, is built to help you do exactly that.
CloudZero connects directly to your GKE and Google Cloud environments. That means accurate, real-time, and granular cost insights for you.
No relying solely on labels here. Whether you need to see cost per team, environment, feature, or individual customer, CloudZero maps your GKE spend to the dimensions that matter most to your business. This lets you pinpoint exactly who’s driving costs, what’s causing changes, and why. Then you can take the right action without slowing down engineering, compromising user experience, or hurting system performance.
And when unexpected spikes hit? You get proactive anomaly alerts before they show up in your GCP billing report.
Ready to stop guessing where your GKE budget is going?  and get immediately actionable GKE costs insights — even if you have messy tags.
and get immediately actionable GKE costs insights — even if you have messy tags.











