

AI adoption is exploding, but margins aren’t. In fact, an MIT analysis reports that 95% of organizations have yet to see measurable ROI from GenAI. This gap becomes obvious as soon as teams push a model into production and usage begins to scale.
For most workloads, the pressure comes after training. Every message, call, query, completion, or retrieval triggers compute behind the scenes. That real-time execution is what AI inference is all about. And when thousands of these happen every minute, the cost curve moves sharply upward.
This guide explains why inference cost now drives most AI spend and why it rises as workloads scale. You’ll also learn how you can turn your everyday model usage into a margin advantage instead of a silent drain on profitability.
What Is Inference Cost Really?
Inference cost is the amount you pay every time a model produces an output in production. It’s the per-request cost of running your AI, whether the model is answering a question, ranking results, generating text, or calling a retrieval pipeline. This cost continues for as long as the model is serving users.
Inference cost comes from the compute and systems activated during each call. This includes GPU or CPU time, memory footprint, token processing, context window size, concurrency, and any supporting components such as vector databases, embeddings, or orchestration layers.
Unlike training, inference is metered per interaction.
A simple way to think about it:
Training costs help you build the model once. Inference costs charge you every time someone uses it.
And since inference cost scales per interaction, it becomes a margin threat at scale.

Why Inference Is The New Margin Killer
Here is the thing. When the scale is big enough, inference doesn’t just eat budgets. It devours entire margins.
Nothing illustrates this more accurately than the number that leaked from Microsoft. OpenAI burned roughly $8.7 billion on Azure inference in the first three quarters of 2025.
That’s not training. That’s not R&D. That’s not experimentation. That’s serving model outputs, the operational cost of everyday usage.
And the logic is clear: inference cost grows in direct proportion to adoption. The more people use your AI product, the more you spend. Unlike training, which is expensive but finite, inference never stops billing.
For most teams, this becomes obvious the moment a model moves from demo to workload. A chatbot that cost a few hundred dollars during testing quietly turns into a five-figure monthly line item once it hits production traffic. Each prompt, message, or retrieval triggers a forward pass, accesses storage, initiates network transfers, expands context windows, or fans out to vector databases. At scale, these “invisible” compute steps become a financial engine you can’t turn off.
The economic reason inference breaks margins
Inference is a variable cost that increases every time a user interacts with your product. Revenue, on the other hand, is usually fixed per plan or per customer. When usage expands faster than pricing, margins fall.
The math is straightforward:
- Revenue grows when you add customers
- Inference cost grows when those customers use your product
Here’s an example: If a customer pays $29 per month but creates $44 of inference usage, that feature is already unprofitable even if the customer looks healthy on paper. We see this pattern often when teams examine cost per customer and discover that certain users cost far more to serve than they generate.
Inference also scales unpredictably. A single action rarely triggers a single model call. Modern AI workflows typically include:
- 2 to 5 LLM calls
- 3 to 7 vector database lookups
- 1 to 3 embedding operations
- 1 to 2 moderation checks
- Additional retries
- Expanding context windows across turns
This means the true cost of a resolved AI task is often 10 to 50 times higher than the posted “per call” price. A $0.01 model call can become a $0.40 to $0.70 workflow when vector search, memory, concurrency, and moderation are included.
Note: If inference is only one part of your cost picture, our guide to marginal cost explains how to measure the entire economic impact of scale.
Related read: AI’s false efficiency curve is worth considering as well — just because tokens are cheaper doesn’t mean overall inference costs will come down.
Where do inference costs really come from?
Across dozens of AI workloads we’ve analyzed, the biggest inference overruns never come from the model price itself. They come from engineering patterns:
- Oversized context windows force the model to process far more tokens than necessary
- Unbounded RAG searches fan out into multiple vector queries and embedding lookups
- Retry storms during peak usage multiply GPU cycles
- Verbose responses inflate tokens, logs, and storage
- Embedding stores grow endlessly when no cleanup policies exist
- Multi-model chains run even when a smaller, cheaper model would have answered
Once you see how these engineering patterns inflate inference usage, the next question is why the cost rises on every layer of the stack.
See more: Marginal Cost for Engineers: 10 Architecture Decisions That Secretly Inflate Your Costs
The Dynamics Of Inference Pricing
At a glance, inference pricing looks simple. A few cents per million tokens, a small per-request fee, maybe a flat rate for embeddings. But once your workload runs in production, each of those “small” units multiplies across tokens, context windows, concurrency, logging, orchestration, and retries. That’s why inference pricing behaves very differently from traditional cloud pricing.
At its core, inference pricing is driven by token volume, model complexity, and the supporting systems around the model. The larger the model and the longer the prompt or output, the more tokens you pay for.
Models such as GPT-4o, Claude Sonnet, and Gemini charge more per million tokens than their smaller siblings, and the gap widens as context windows expand.
All major vendors price inference by tokens processed, not by request count:
This means your cost is determined by input and output sizes, model family, context window expansion, and concurrency and throughput.
When any of these increase voluntarily or accidentally, your cost rises instantly.
Here’s a breakdown of inference pricing:
|
Cost driver |
What it includes |
Why it gets expensive |
|
Token pricing |
Input tokens, output tokens, context window usage |
Larger models + longer prompts = more compute & token billing |
|
RAG pipeline costs |
Vector reads, embedding generation, index scans, reranking, storage, network egress |
Each lookup/embedding is billed separately; high traffic multiplies costs |
|
Concurrency and throughput |
Autoscaling, overlapping requests, GPU bursts, retry storms |
Bursts trigger GPU autoscaling + parallel RAG calls lead to cost spikes |
|
Logging and observability |
Model logs, token traces, moderation logs, metadata ingestion |
Every GB into observability platforms is billable; verbose LLM outputs create massive logs |
|
Orchestration and workflow Overhead |
LangChain/chain-of-thought, memory stores, workflow fan-outs |
Chains trigger multiple hidden model calls; memory systems read/write continuously |
|
Region-based pricing differences |
US vs. EU vs. APAC pricing, Azure multipliers, Gemini region tiers |
Serving traffic in an expensive region raises costs without a workload change |
|
Egress and networking |
RAG retrieval, cross-region inference, logging export |
RAG and multi-region architectures increase cross-AZ and cross-region charges |
|
Hidden multipliers stacking effects |
Token inflation, expanded context windows, retries, RAG depth, caching misses |
Each layer multiplies the next; for example, a $0.003 call becomes a $0.40 interaction when multiplied across workflow steps. |
How Can You Reduce Inference Costs Without Stifling Innovation?
Many organizations try to cut inference costs by “using a smaller model” or “adding budgets,” but that never solves the structural problem.
We’ve seen it above, inference cost isn’t just a pricing issue, it’s a workflow, architecture, and behavior issue. The goal is not to slow teams down, but to design AI systems that stay economically healthy as usage grows.
Here’s how leading teams reduce inference cost without sacrificing product velocity.
Make context windows work for you, not against you
According to Anthropic, context is a “finite resource,” and unnecessary tokens directly increase compute and reduce model efficiency. Keeping windows tight by summarizing past turns, using short memory buffers, limiting RAG to relevant chunks, and clearing stale embeddings routinely cuts inference cost 20–60% in production systems.
Related read: CloudZero’s Anthropic integration helps teams track Claude usage and cost with real cloud metrics.
Put RAG on a budget
RAG becomes costly because each vector search and embedding operation is billed. Set limits by reducing search depth, lowering embedding size where acceptable, caching repeated results, and filtering out low-relevance documents. These controls usually produce fast, meaningful savings.
Control concurrency before it inflates spend
Concurrency spikes trigger retry storms, GPU autoscaling, and parallel RAG steps that multiply cost. Set feature-level concurrency limits, use backpressure to stop retries, fall back to smaller models when overloaded, and throttle RAG activity during peak periods.
Cache everything that repeats
Caching identical prompts, embedding vectors, search results, and common model outputs removes repeated inference work. Production workloads show significant reductions in inference volume once caching is applied.
Reduce output tokens
Output tokens are billed at the same per-token rates as input tokens across major providers such as OpenAI, Anthropic, and Google. Enforcing concise responses, using function calls, trimming templates, and avoiding long explanations reduces inference costs and improves latency.
Log less verbosely (your future self will thank you)
LLM workloads generate large log volumes, and most platforms charge by the gigabyte for log ingestion. Removing token-level logs, reducing stored responses, using sampling, and turning off verbose debugging can significantly reduce log costs in production.
Use a cost feedback loop
Teams can only control inference cost when they can see what each model call, workflow, and customer actually costs. Cloud and AI platforms surface usage, but they do not break spend down by feature or customer. This makes it challenging to understand which parts of the product drive cost or where efficiency gains matter most.
CloudZero can help with this and much more.
How CloudZero Turns Inference Cost Into Margin Control
Organizations using AI only see model invoices and GPU bills. At CloudZero, we convert that raw spend into units you can actually price. Think of cost per customer, token, request, conversation, and feature. This is the baseline needed for accurate margin analysis.

Once you decide what “one unit of AI work” means for your product, such as one chat message or one search, we map your entire AI bill to that unit definition and show exactly where each dollar of inference COGS came from.
COGS is the real cost of delivering your product, and your margin comes from revenue minus COGS.
Revenue − COGS = Gross Margin
With CloudZero, instead of one big number, you see which feature, which user group, and which part of your AI workflow actually created the spend. So you move from “our AI bill went up” to “this specific feature and users increased inference COGS.”
Related read: See how CloudZero helps SaaS companies calculate their COGS.
We then convert those units into real margin metrics. CloudZero compares cost-per-unit against revenue-per-unit, surfacing gross margin for each feature, product, and customer. Teams can finally see which AI experiences are profitable, which segments are underwater, and which workloads need architectural or pricing changes.
We continuously monitor inference cost drift and immediately alert your team when something changes. If a model starts spending more, CloudZero points directly to the service or feature behind it. Engineers can investigate the change immediately, correct the behavior, and avoid unnecessary inference COGS without affecting product performance.
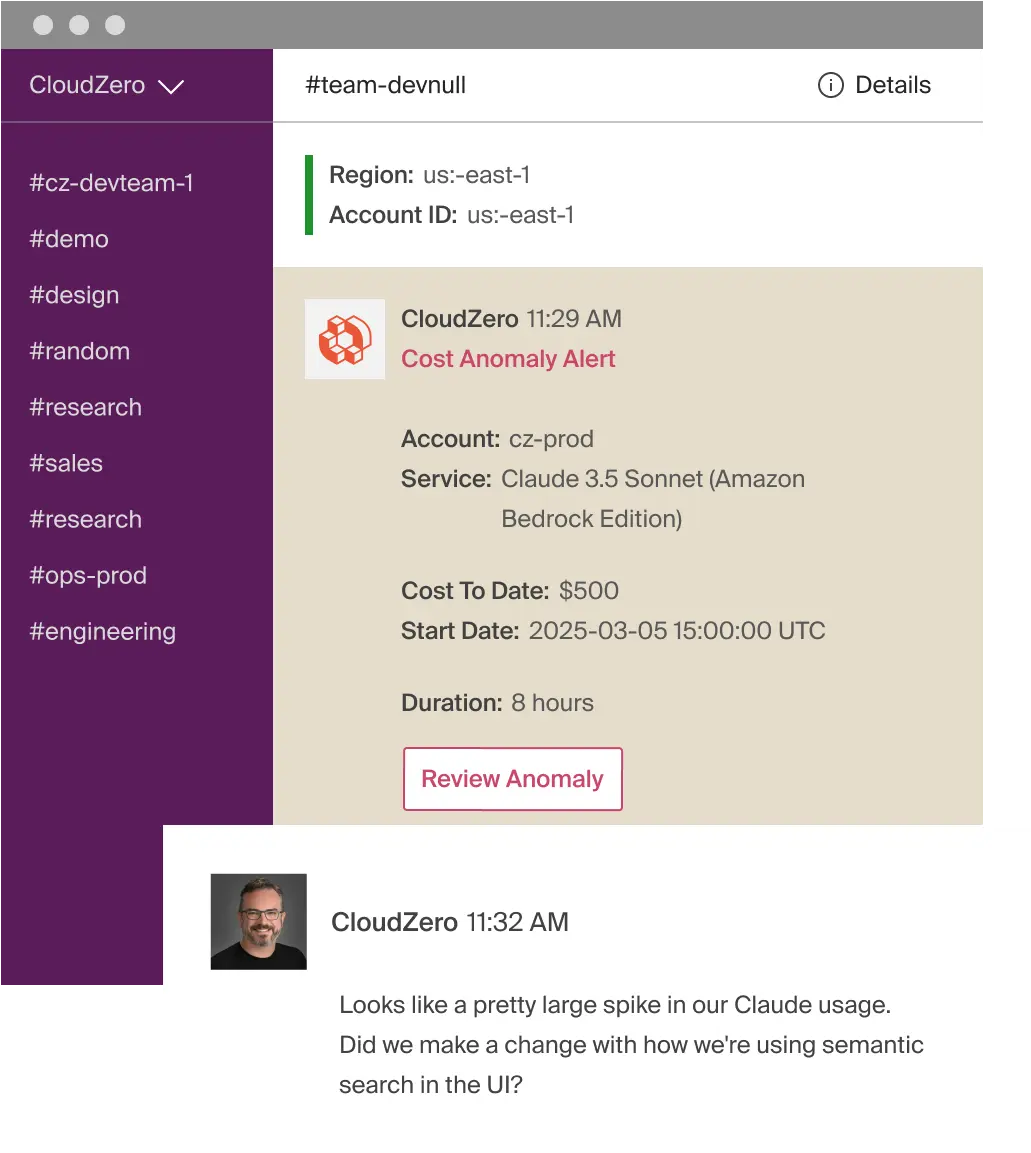
And we also bring engineering, product, and finance into one shared view. Engineers see workload-level detail, product sees feature-level margin, and finance sees customer-level COGS. Everyone works from the same truth, making decisions about limits, pricing, and optimization that are aligned and margin-positive.
Grammarly, Rapid7, and other ambitious brands already use CloudZero to control their AI infrastructure costs and protect margin as usage grows. You can, too.  and see how CloudZero in action.
and see how CloudZero in action.
FAQs
What is inference cost?
It’s the cost of producing each AI output, every message, search, or retrieval triggers compute and token usage that gets billed per interaction.
Why is inference so expensive?
Because each request can trigger multiple hidden steps such as model calls, context expansion, retries and more. This makes cost scale with user activity.
How can teams lower inference cost?
By shrinking context windows, using smaller models for minortasks, limiting RAG depth, throttling concurrency, and caching repeated work.
How does CloudZero help?
CloudZero breaks your AI bill into units such as cost per token, request, conversation, and feature. This enables you to see which workloads are profitable and which need optimization.


The Cloud Cost Playbook
The step-by-step guide to cost maturity



