
AI is moving fast — for most engineering and finance teams, the LLM costs are moving faster. You shipped the feature. The model is live. Now the usage meter is running. That ongoing, per-request expense is inference cost, and for organizations running AI in production, it is the number that matters most.
This guide explains what inference cost is, what drives it up at scale, how it compares to LLM training cost, and what your team can actually do to reduce it.
What Is Inference Cost?
Inference cost is the compute cost your organization pays every time an AI model generates a response — each prompt sent, each reply received. In the context of AI inference, this happens continuously in production: every user interaction, every API call, every AI-powered feature triggers a billable event. When thousands of those happen every minute, the cost curve moves sharply upward.
Inference cost is billed by:
- Input tokens: the number of tokens in the prompt and context window sent to the model
- Output tokens: the number of tokens the model generates in response
- Compute time: for self-hosted or GPU-based deployments, the raw GPU time the model runs
Cost per token varies significantly across providers and model tiers. The same underlying model can cost different amounts depending on where and how you run it.
For a deeper look at how token pricing works, see CloudZero’s guide to OpenAI API cost per token.
Report
Finance needs to prove AI’s return: CloudZero report
260 senior finance leaders (more than half CFOs) told us why the speed of seeing AI spend, not the size of it, separates who pulls ahead on AI from who gets burned.
Inference Cost Vs LLM Training Cost: Key Differences
To manage inference cost well, it helps to understand what it is not. Most AI spend falls into two categories: training and inference. They behave very differently, and they require different FinOps playbooks.
What is LLM training cost?
Training is the process of teaching a model. It involves feeding massive datasets into a system, adjusting billions of parameters, and running intensive compute jobs for days or weeks at a time.
LLM training cost characteristics:
- CapEx-like: a large, bounded investment rather than an ongoing cost
- GPU-intensive: requires large clusters of A100 or H100 GPUs running continuously
- Easier to forecast: a training run has a defined start, end, and scope
- Periodic: happens once for foundation models, or periodically for fine-tuning
For frontier models like GPT-4 or Claude, training costs are estimated to reach tens or hundreds of millions of dollars. Fine-tuning a smaller model on proprietary data can cost anywhere from thousands to tens of thousands.
What is LLM inference cost?
Inference is the operational phase. Once a model is live, it responds to real requests continuously. Every user interaction, every API call, every AI-powered feature your product ships runs on inference.
LLM inference cost characteristics:
- OpEx: recurring, per-request spend that scales with every user and feature
- Volume-driven: compounds with request volume, token count, and model complexity
- Harder to forecast: usage patterns are dynamic and often unpredictable
- Often larger than training at scale: for popular AI products, cumulative inference spend can dwarf the original training investment
Here is a quick overview of how the two compare across the dimensions that matter most for budgeting and optimization:
| Training cost | Inference cost | |
| When | One-time or periodic | Continuous |
| Primary driver | Dataset size, GPU hours, model size | Request volume, token count, model tier |
| Billing model | Time or GPU-based | Token-based or compute-based |
| Forecastability | High | Low to medium |
| Optimization levers | Fewer, larger training runs | Many: caching, routing, batching, and more |
For most organizations running AI in production, inference cost is the most dominant and fastest-growing component of total AI spend.
To understand the broader cost dynamics involved, see AI Costs In 2026: A Guide To Pricing, Implementation, And Mistakes To Avoid.
What Drives LLM Inference Cost Up?
Before your team can reduce inference spend, it helps to understand what drives it up in the first place. These are the primary factors that inflate costs in real-world deployments.
Token volume per request
Every token processed, on both the input and output side, adds to your bill. Large context windows, lengthy system prompts, and verbose responses all push token counts up. In multi-turn conversations and agentic workflows, this compounds quickly: each new message re-feeds the full conversation history back into the model, ballooning the effective input size over time.
Model size and capability tier
Frontier models such as Claude Opus or GPT-4 cost orders of magnitude more per token than smaller, faster alternatives. Running a heavyweight model for every request, including simple classification or routing tasks, is one of the most common and costly patterns in LLM cost management.
For strategies to address this, see AI API Aggregation: Managing Costs And Complexity Across Multiple LLMs.
Request volume and concurrency
At low scale, per-request costs are trivial. At production scale, even small costs compound into higher monthly spend. Concurrency spikes can also trigger retry storms, GPU autoscaling, and parallel retrieval steps that multiply cost without adding user value.
Retrieval-Augmented Generation (RAG) overhead
RAG pipelines carry their own cost: embedding generation, vector search, and re-ranking all consume compute before the model ever sees your query. Poorly scoped RAG, retrieving too many documents or running too many vector queries per request, turns into a significant hidden cost center that most teams underestimate.
Caching gaps
If your application generates the same answer twice, that is pure waste. Models without prompt caching or application-layer semantic caching re-compute responses to repeated or near-identical queries, which is extremely common in high-volume assistants and search features.
For a practical breakdown of how caching interacts with cost in managed AI services, see 5 Cost Levers To Consider When Adopting Amazon Bedrock.
Engineering patterns that compound silently
Beyond pricing, inference cost is fundamentally a workflow and architecture problem. Unbounded RAG searches, verbose logging of token-level responses, open-ended retry logic, and multi-model chains that fire even when a smaller model would suffice all inflate cost quietly.
These patterns are explored in depth in CloudZero’s guide to AI Cost Optimization Strategies For AI-First Organizations.
The True Cost Of Generative AI At Scale
The true generative AI cost in production is routinely underestimated. Individual requests can seem cheap on paper. The problem is how fast they compound.
Consider a simple example: an AI-powered support assistant handling 50,000 conversations per month, with an average of 10 turns per conversation and even a modest $0.01 cost per turn.
That single feature costs $5,000 per month. Add multi-step reasoning, RAG retrieval, and longer context windows, and that figure grows quickly.
CloudZero’s State of AI Costs report found that average monthly AI spend reached $62,964 in 2024, with projections rising to $85,521 in 2025. Only 51% of organizations said they could confidently evaluate the ROI of that spend.

That gap between what organizations spend and what they can explain is an inference cost visibility problem.
The challenge compounds for a few reasons. Per-token pricing is falling, which is a positive trend. But total token consumption is rising faster than prices decline, because today’s advanced models reason, loop, and chain workflows in ways that burn far more tokens per request than earlier systems. This dynamic is covered in detail in AI’s False Efficiency Curve: How To Save And Protect Your Margins.
At the same time, AI workloads are often funded from experimentation budgets rather than production infrastructure budgets, which means they escape standard FinOps scrutiny. And inference spend is spread across multiple cloud providers, APIs, and internal infrastructure, making attribution difficult by default. For the organizational playbook to address this, see FinOps for AI: What It Is And Why AI Changes Cloud Cost Management.
How To Reduce Inference Cost: 8 Proven Strategies
Inference cost is highly optimizable. These are the highest-leverage tactics for reducing LLM and AI inference spend without compromising product quality.
1. Route requests to the right model
Not every request calls for your most capable model. Build a model routing strategy where simple tasks, such as classification, intent detection, and short-answer lookups, go to small, fast, cost-efficient models such as Claude Haiku or GPT-4o Mini. Reserve frontier models for genuinely complex tasks: long-form generation, nuanced reasoning, and multi-document synthesis.
Intelligent routing alone can reduce inference cost by 30 to 60% in mixed-workload environments.
2. Implement prompt caching
Prompt caching reuses previously computed states for repeated or near-identical prompts. For applications with stable system prompts or repeated document references, this eliminates redundant compute. When applicable, prompt caching can cut costs by 50 to 90% for cache-eligible workloads. This is particularly effective for customer support bots, document Q&A systems, and any feature that frequently re-processes the same context.
3. Compress and optimize your prompts
Verbose prompts do not produce better outputs. They produce higher bills. Audit your system prompts for redundancy. Replace full conversation histories with summarized memory buffers.
Limit RAG retrieval to the most relevant chunks rather than broad searches. Treating your token footprint like a budgeted engineering resource, rather than an unlimited byproduct, is one of the highest-leverage mindset shifts your team can make.
4. Use batch inference for async workloads
Not every AI request needs an instant response. For content generation pipelines, data enrichment jobs, offline analysis, and scheduled tasks, batch inference groups multiple requests and processes them at lower cost. Per AWS Bedrock benchmarks, batch processing can offer up to 50% lower cost compared to standard on-demand inference.
Reserve real-time inference for user-facing, latency-sensitive interactions. Route everything else to batch.
5. Add semantic caching at the application layer
Beyond provider-side caching, a semantic cache at the application layer can intercept semantically equivalent queries before they ever reach the model. Users asking “what is your refund policy?” in different phrasings should hit a cached response, not trigger a new inference call. Vector similarity caches built on Redis or purpose-built tools are practical solutions for high-volume SaaS applications.
6. Tighten context windows
Every token in your context window costs money, including tokens from earlier in the conversation that the model may not need. Discipline around context management is one of the fastest paths to meaningful cost reduction. Summarize past turns rather than appending them in full. Set explicit maximum context lengths at the feature level.
In production systems, tighter context management reduces inference cost significantly — prompt compression techniques such as summarization, keyphrase extraction, and semantic chunking can achieve 70–94% cost savings in production AI systems, according to research published in Medium citing Stanford and ACL findings. For a practical implementation approach, see Microsoft’s open-source LLMLingua, which achieves up to 20x prompt compression with minimal performance loss.
7. Quantize self-hosted models
For organizations self-hosting models, quantization reduces model weights from FP32 or FP16 to INT8 or INT4. This dramatically lowers GPU memory requirements and inference latency.
Combined with speculative decoding and dynamic batching, quantized models can serve more requests at lower cost, while maintaining output quality for most production use cases.
8. Set concurrency limits and backpressure controls
Concurrency spikes create disproportionate cost events. Retry storms, where failed requests trigger cascading re-attempts, are particularly damaging. Implement feature-level concurrency limits, backpressure mechanisms that slow ingestion under load, and fallback routing to smaller models during peak periods.
These controls keep costs predictable and prevent individual spikes from becoming billing incidents.
For a real-world example of how teams manage inference cost across 50 or more LLMs simultaneously, see AI Cost Optimization At Scale.
From Cost Reduction To Inference Cost Intelligence
The strategies above help you cut waste. But reduction alone is not enough as AI workloads scale. The real challenge shifts from “how do we spend less?” to “how do we know what we are getting for what we spend?”
That requires moving from inference cost visibility to AI cost management at the unit level: understanding the cost of delivering a specific AI-powered outcome, whether that is one conversation, one document processed, one search result, or one generated summary, and mapping that against the revenue or value it creates. For a framework on how to approach this, see CloudZero’s guide tounit economics.
Without unit economics, the compounding problems are hard to see: optimizing the wrong features while high-cost, low-margin ones run unchecked; subsidizing unprofitable customers without knowing it; a pricing model that structurally erodes margin as usage grows.
These dynamics connect inference cost directly to gross margin. For more on that connection, see SaaS COGS: Factors To Determine Your Cost Of Goods Sold and How To Calculate And Improve Your SaaS Gross Margin.
This is also where AI cost sprawl starts. Organizations building features without cost visibility do not realize they have a margin problem until the invoice arrives.
How CloudZero Helps You Manage Inference Cost At Scale
CloudZero is built to close the gap between raw AI spend and the cloud cost optimization intelligence teams actually need to make decisions.
- Unit cost mapping. CloudZero maps your entire AI bill, across models, APIs, GPU infrastructure, and RAG pipelines, to the unit definition that matters for your product. Cost per conversation. Cost per customer. Cost per feature. This is the foundation of real AI cost optimization at scale.
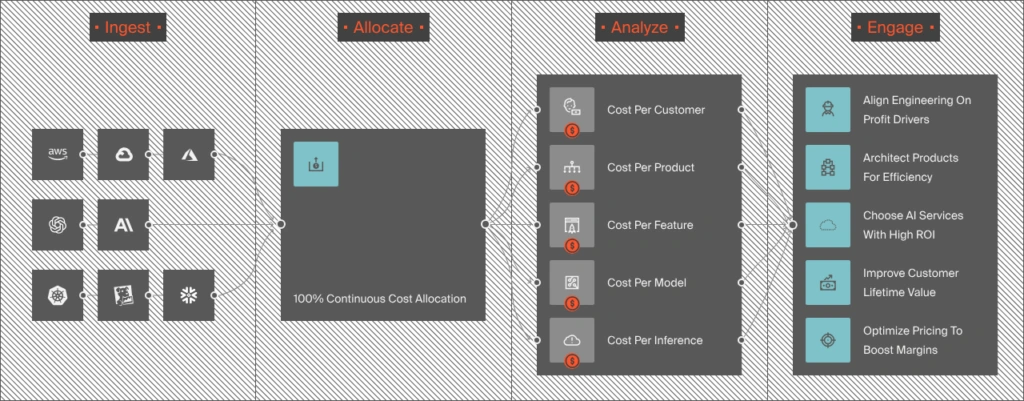
- Gross margin by feature and customer. Once unit costs are established, CloudZero compares them against revenue-per-unit. This surfaces which AI features are margin-positive, which are underwater, and which need architectural or pricing changes to become sustainable. For the broader margin framework, see How To Calculate Margin Analysis For SaaS.
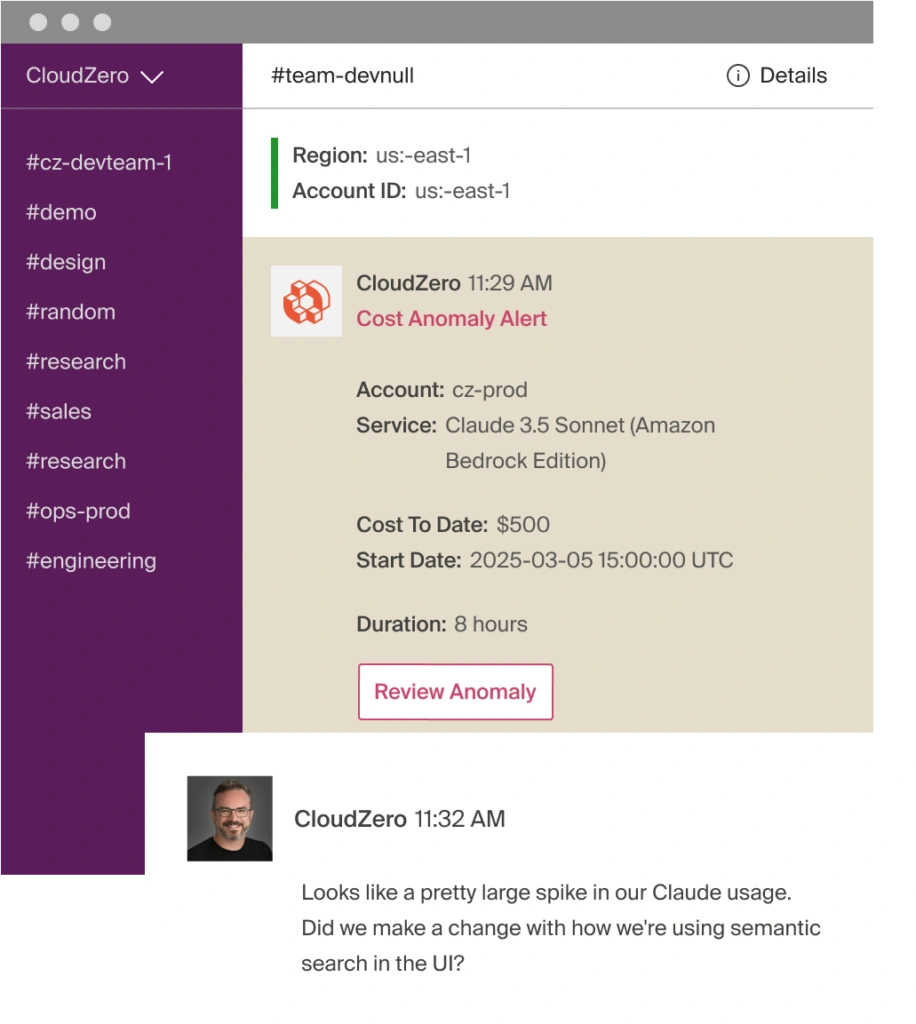
- Real-time anomaly detection. When inference spend drifts, whether a model starts processing more tokens, a feature’s call volume spikes, or a RAG pipeline starts over-retrieving, CloudZero alerts your team immediately. It points directly to the service or feature responsible so engineers can investigate and correct the behavior before it becomes an expensive billing incident. For more on how this works with specific AI providers, see Track OpenAI Spend and FinOps for Claude.
- One shared view for engineering, product, and finance. Engineers see workload-level detail. Product sees feature-level margin. Finance sees customer-level COGS. Everyone works from the same data. That alignment is what makes inference cost manageable at scale, rather than a number that surprises everyone at the end of the month.
Organizations such as PicPay ($18.6M saved) and a global SaaS platform running 50+ LLMs ($1M+ in immediate inference savings) have already used CloudZero to turn AI cost chaos into margin control. If your team is ready to do the same, schedule a demo, take a self-guided product tour, or take a free cloud cost assessment to see where you stand today.
Frequently Asked Questions About Inference Cost
Related Reading:











