Kubernetes began as a tool to help teams keep thousands of microservices running without falling apart. It gave them a way to schedule workloads, recover from failures, and scale services without constant firefighting.
Now, AI has brought back the same chaos, only magnified. Training jobs sprawl across GPUs. Inference traffic spikes without warning. Pipelines stretch across clusters, clouds, and compliance boundaries.
Left unchecked, it can break both your workload and cloud budget.
But it turns out the very qualities Kubernetes was designed for (orchestration, elasticity, automation, and resilience) are exactly what modern AI needs.
So, can K8s give your team a fighting chance at balancing performance with cost?
In this guide, we’ll share how leading teams are using Kubernetes to power AI today, highlight the pitfalls to avoid, and explore the trends shaping the future. And because technology never exists in a vacuum, we’ll also examine the financial and security implications of running AI at scale and how to keep both under control.
Here’s Why Engineers Are Choosing Kubernetes For AI Workloads Right Now
We’re talking about massive language models with billions of parameters, multimodal systems that blend text, image, and audio, and inference services that need to scale from zero to thousands of requests in seconds.
Running this kind of infrastructure demands efficiency. And with K8s for AI, you can:
- Orchestrate AI workloads at scale: Kubernetes can coordinate thousands of containers across clusters. You can schedule GPU-heavy jobs without wasting capacity.
- Support elasticity: Your workloads can expand and contract based on demand. And this can minimize over-provisioning during idle times.
- Improve automation: From rolling updates to self-healing pods, your Kubernetes setup can handle much of the grunt work, so your team can focus on innovative projects.
- Ensure resilience: With K8s, your long-running AI training jobs can survive node failures, checkpoint progress, and continue without starting from scratch.
- Boost portability: Teams can run workloads across public clouds, on-prem, or hybrid environments. Meaning, you can avoid the lock-in that comes with single-vendor AI platforms.
Kubernetes matters for AI because it makes workloads manageable, scalable, and, importantly, sustainable. Now let’s dig into the practical side: how teams are actually using Kubernetes to power AI in SaaS applications.

Research Report
FinOps In The AI Era: A Critical Recalibration
What 475 executives told us about AI and cloud efficiency.
6 Kubernetes Capabilities That Make AI Infrastructure Manageable
Here are some of the features that make K8s work for AI workloads.
GPU and accelerator scheduling
AI runs on specialized hardware, such as GPUs, TPUs, and custom accelerators, that require more than generic CPU scheduling. With Kubernetes device plugins (like the NVIDIA Device Plugin), you can transform your GPUs into first-class resources and allocate them to pods.
Also, features like Multi-Instance GPU (MIG) let you carve a single GPU into slices for multiple inference jobs, while topology-aware scheduling ensures that your workloads are placed near the optimal PCIe or NVLink lanes to avoid bottlenecks.
Distributed training orchestration
Training modern models means spreading the workload across dozens, or even hundreds, of nodes. Kubernetes is tightly integrated with frameworks such as Kubeflow, Horovod, and Ray. And that can help make your distributed training more reliable. Plus, built-in checkpointing and restart features ensure that a single node failure doesn’t kill your multi-day training run.
Autoscaling tuned for AI
Scaling GPU clusters isn’t the same as scaling stateless web services. Your AI team relies on Cluster Autoscaler and smart node provisioners, like Karpenter, to reduce idle GPU time. For inference, KEDA and Knative enable event-driven scaling, which is perfect for GenAI workloads that can spike from zero to thousands of requests in seconds.
Data and storage orchestration
You know this. By feeding models the right data at the right time, AI extends beyond just computing power.
Kubernetes integrates with cloud object stores via CSI drivers and supports reproducible data access through Persistent Volume Claims (PVCs). In addition, adding caching layers like Alluxio or MinIO can dramatically cut preprocessing latency in data-intensive pipelines.
Networking and service mesh
When training workloads span multiple clusters or GPUs, network throughput can make or break performance. Kubernetes supports RDMA and InfiniBand plugins for low-latency interconnects and service meshes like Istio or Linkerd for secure communication between ML services.
Multi-cluster networking adds another layer of flexibility for federated or cross-cloud deployments.
MLOps and pipeline integration
The MLOps lifecycle is messy without orchestration. You can use K8s to streamline MLOps workflows with tools like Kubeflow Pipelines for end-to-end workflows, Argo Workflows for DAG-based jobs, and KServe or Seldon Core for deploying inference endpoints that scale automatically.
You can also use frameworks like Ray to integrate natively and support hyperparameter search and reinforcement learning at scale.
Observability and telemetry
With AI, every idle GPU minute costs real money, so visibility matters. With Kubernetes, you can integrate Prometheus and Grafana dashboards for GPU utilization. You can also deploy OpenTelemetry for distributed tracing, and ML-specific monitoring tools like WhyLabs or Evidently AI to catch drift and anomalies before they cause damage in production.
Extensibility through CRDs and operators
Last but by no means least, Kubernetes’ extensibility is a gem. For example, you can use Custom Resource Definitions (CRDs) to define jobs like TFJob for TensorFlow, PyTorchJob for PyTorch, or Katib for automated hyperparameter tuning.
Operators often abstract away much of the cluster complexity, giving your data pros a way to run complex jobs without touching YAML.
That said, let’s now shift our focus from what Kubernetes technology can do for AI to how real-world teams are utilizing K8s for AI/ML workflows.
How Leading Teams Actually Deploy Kubernetes For AI
Consider these:
Ingesting and preprocessing data
You can run Spark on Kubernetes, or use tools like Airflow and Dask, to clean, transform, and prepare terabytes of raw data. Kubernetes helps these jobs scale elastically, so your pipelines finish on time without sitting idle afterward.
Distributed training
Training today’s models means orchestrating GPUs across dozens of nodes. Kubernetes works with frameworks like TensorFlow, PyTorch, Horovod, or DeepSpeed to spread your workload efficiently. So, your team can checkpoint progress and recover quickly if a node fails, which is a critical safeguard for multi-day runs.
Hyperparameter tuning and search
Tools like Katib on Kubeflow or Ray Tune run hundreds of experiments in parallel, each with different hyperparameters. That matters because AI models rarely get it right on the first try. And with Kubernetes, you can launch and manage these jobs without overwhelming clusters or wasting GPU cycles.
Continuous training and retraining
Here is the thing. Models drift as data changes, and that requires regular retraining. Teams are using Kubernetes to support CI/CD-style pipelines that automatically retrain and redeploy models. This helps ensure accuracy and reliability without requiring manual intervention.
Deploying models and inference
Deploying a model is often more complex than training it. So, frameworks like KServe, Seldon Core, and BentoML let teams package models as services and scale them up or down based on traffic. For your SaaS apps, this means inference endpoints that stay responsive during traffic spikes but don’t burn your budget when idle.
Edge and federated learning
With Kubernetes’ multi-cluster and edge capabilities, teams are running inference close to where data is generated. Think of IoT devices, cars, or regional data centers. This can mean reduced latency and improved compliance while still syncing back to your central clusters for coordination.
AI for cybersecurity and DevSecOps
Many teams deploy AI-powered anomaly detection or threat intelligence pipelines directly on Kubernetes. The goal is often to catch suspicious activity in real time, turning the platform (K8s) into part of their security posture.
Generative AI and burst workloads
With Generative AI workloads — and especially LLM inference — come new challenges. And that includes unpredictable demand, spiky inference requests, and latency-sensitive prompts. With Kubernetes, you can work with KEDA and Knative to scale these services from zero to thousands of requests in seconds.
But seeing Kubernetes everywhere in AI raises a bigger question. What will you actually gain from using it?
The Real ROI Of Kubernetes For AI (And What It Can’t Fix)
The payoff from making Kubernetes your go-to engine for modern AI extends beyond engineering. You can also:
1. Improve efficiency and GPU utilization
Idle GPUs are expensive GPUs — and GPU cost is one of the fastest-growing line items on any cloud bill. Using Kubernetes can help you improve utilization by scheduling jobs across resources intelligently, slicing GPUs for parallel inference, and scaling clusters up or down automatically. This can mean more experiments, faster results, and fewer wasted dollars.
2. Boost portability across environments
Some teams need to keep training on-prem for compliance. Others want to take advantage of cheaper GPU capacity in the cloud. With K8s, you can abstract away these differences, enabling your team to run AI workloads across AWS, Azure, GCP, or on-prem. No need to rewrite everything either.
3. Support automation and reproducibility
Manual deployments are error-prone, especially when you’re managing dozens of pipelines and hundreds of experiments. Kubernetes can change that by automating everything from rolling updates to job restarts. And that can make it easier to reproduce your best AI workflows. Less firefighting for your team. More time for innovation.
4. Take advantage of cost optimization opportunities
K8s’ elastic scaling gives AI teams new levers to control their spending in the cloud. Paired with cost-intelligence platforms like CloudZero, you can better track:
- The cost per experiment or training run,
- The cost per deployed model, or
- Even the cost per individual customer, per feature using AI, and so on.
This can help you bridge the gap between engineering activity and business impact. And this is something that pure infrastructure tools can’t deliver on their own.
5. Improve resilience and reliability
Training jobs can run for days. And without resilience, a single node failure could wipe out your valuable progress. Kubernetes handles self-healing, checkpointing, and failover, so your workloads can survive disruptions with minimal downtime.
6. Support collaboration across teams
You’ve probably noticed this already. Data scientists, DevOps engineers, and security teams often speak different languages.
Kubernetes offers a common foundation where each group gets what it needs. Think of reproducibility for data scientists, policy enforcement for security, and efficiency levers for finance.
But adopting Kubernetes for AI isn’t all upside. The same complexity that makes it powerful can also quietly sap performance, inflate your costs, and even derail entire projects.
Where Kubernetes Falls Short: The Hidden Costs And Performance Tradeoffs Of Combining K8s And AI
We’ve covered the technical benefits of Kubernetes. But the financial picture can quickly get murky.
1. Hidden costs lurk everywhere
GPUs often sit idle between jobs, still billing at premium rates. But there’s more:
- Training data, model artifacts, and checkpoints pile up in persistent volumes, adding to your costs.
- Moving data between clusters, zones, or clouds can add latency and unexpected line items to your cloud bill.
- Telemetry pipelines (metrics, logs, and traces) cost money to run, and in large clusters, those costs can rival the workloads themselves.
2. Performance vs. budget tradeoffs
AI teams constantly face a balancing act. Provision too little and jobs fail. Provision too much and budgets evaporate. With Kubernetes, you get a lever to tune these tradeoffs, but it doesn’t tell you when you’re making the wrong call.
3. Spot and preemptible strategies
One of Kubernetes’ biggest cost levers is support for spot and preemptible instances. These can cut GPU bills dramatically. That only happens if your workloads are checkpointed and resilient to interruptions.
Not every AI pipeline can handle being preempted mid-run, which means finance and engineering must constantly weigh savings against risk.
Without granular visibility, a ballooning GPU bill is often the only signal you get. Yet, that can be your opening. You can use a platform like CloudZero to map your spend to business outcomes.
For example, you can view your cost per deployed model, cost per feature delivered to customers, and beyond, like this:
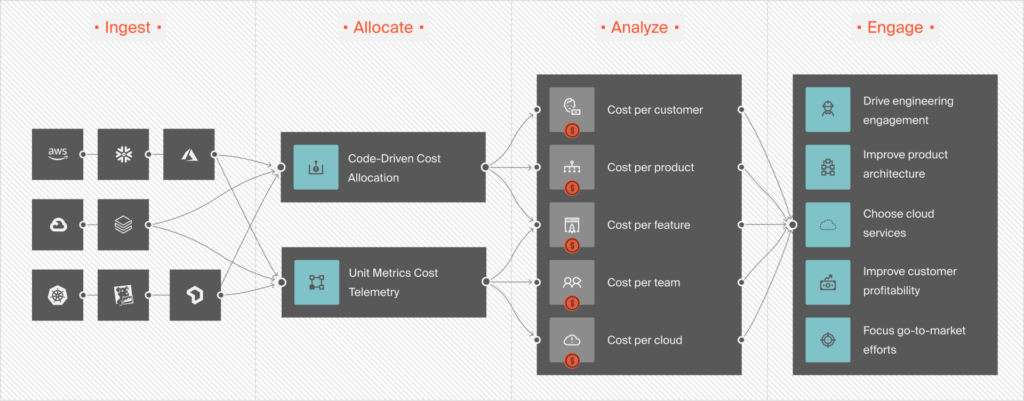
If you are using K8s, you can view your costs in CloudZero like this:
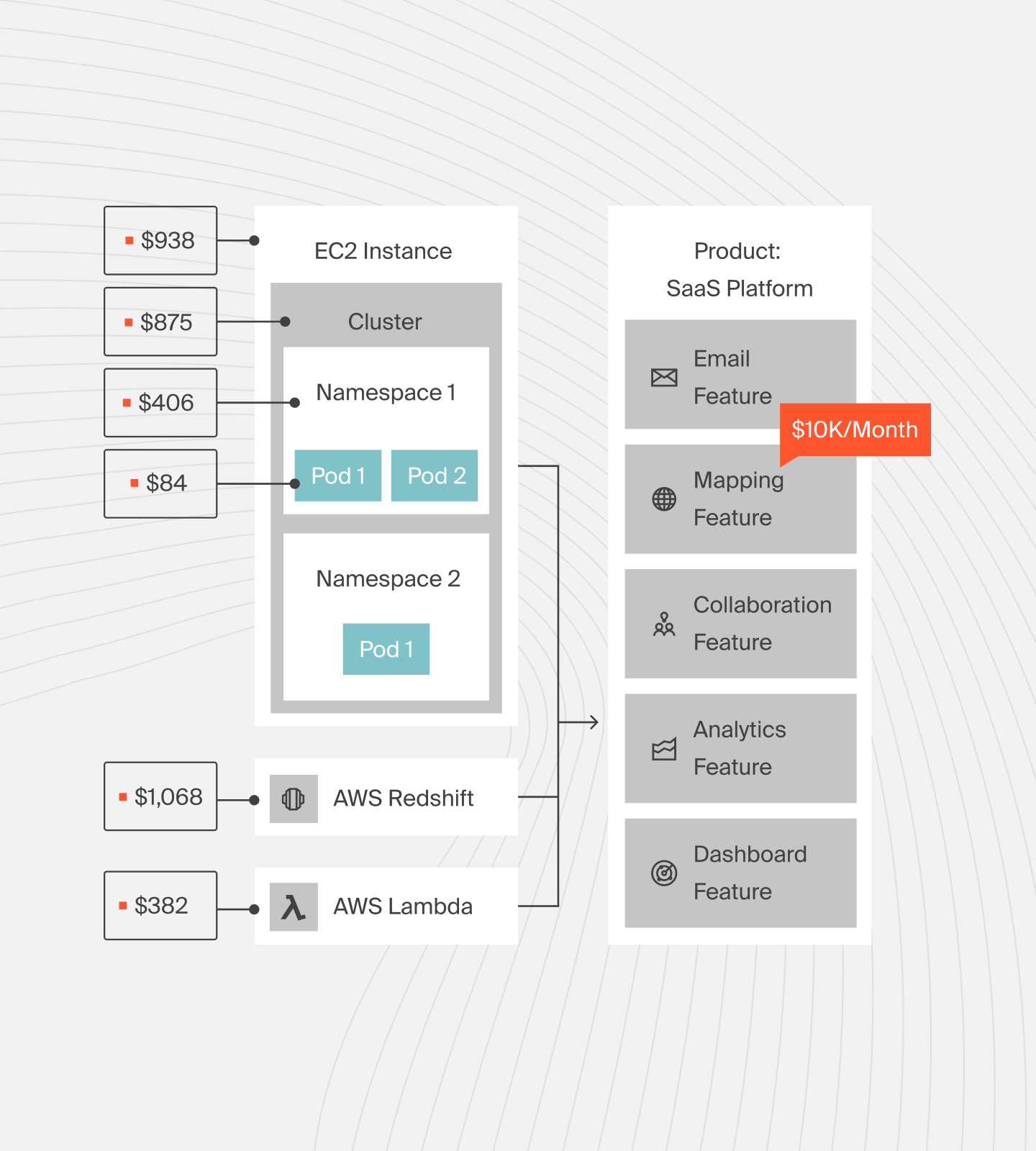
That level of K8s cost attribution turns raw spend data into actionable insight. Your finance leaders can judge whether an expensive training run delivered value. Engineering can see which experiments are profitable to continue. And SaaS leaders can defend margins while still funding innovation. See how for yourself with this free product tour.
That said, cost isn’t the only blind spot when scaling AI on Kubernetes. Security and compliance add another layer of complexity, and ignoring them can be even more expensive.
Securing AI On Kubernetes (What Your CISO Needs To Know Before You Dive In)
Running AI on Kubernetes introduces a new set of AI infrastructure security and compliance challenges. Here’s the short version. Stay tuned for our upcoming full-length guide.
- AI-specific threat models: Watch out for model poisoning (malicious data in training sets), inference-time attacks that extract sensitive information, and model theft when artifacts aren’t properly secured.
- Network security and isolation: East–west traffic inside clusters is a soft target without strict policies. Service meshes like Istio or Linkerd secure communication, while RBAC ensures only the right teams have access to sensitive workloads.
- Multi-tenancy and compliance: In shared clusters, one team’s mistake can compromise another’s workload. Without namespace isolation and quotas, industries under GDPR, HIPAA, or SOC2 risk non-compliance.
- Policy enforcement and provenance: Tools like OPA/Gatekeeper and Kyverno enforce guardrails, while provenance and artifact lineage tracking preserve model integrity by recording when, how, and with what data models were trained.
Protecting AI workloads today is critical, but it’s also where Kubernetes is heading, and how it’s evolving to meet tomorrow’s challenges.
Consider These 6 Kubernetes + AI Trends CTOs Are Watching In 2026
The next wave of Kubernetes innovation is already reshaping how AI workloads will be built, secured, and made cost-efficient in the future. Here is what’s happening so you can prepare.
AI-native Kubernetes distributions
Vendors like NVIDIA (AI Enterprise) and Red Hat (OpenShift AI) are tailoring Kubernetes to run AI workloads out of the box. Expect more AI-focused distributions that come prepackaged with GPU scheduling, model deployment frameworks, and compliance tooling.
Predictive autoscaling
Traditional autoscaling reacts after demand spikes. Emerging approaches are using AI to forecast demand and scale clusters ahead of time. And that’s cutting latency for inference workloads and improving cost efficiency.
AI managing Kubernetes itself
Research projects like KubeIntellect are experimenting with LLMs as cluster co-pilots. Think of automatically tuning workloads, scaling policies, or even suggesting architecture changes. We are seeing that the idea of “AI managing AI infrastructure” is moving from theory to reality.
Edge and federated learning
Kubernetes is increasingly being used to orchestrate inference at the edge, such as in vehicles and IoT devices. Then, it coordinates with central clusters for retraining and synchronization.
FinOps and AIOps convergence
As AI workloads scale, expect FinOps, AIOps, and MLOps to converge. Kubernetes will serve as the control plane, holding it all together. So, if managing Kubernetes or AI costs separately has felt tricky, this next phase will demand even more diligence to keep innovation profitable.
When your board asks why AI infrastructure costs doubled last quarter, can you show:
- Which models drove the increase?
- Which experiments were worth the spend?
- Where would optimization have the biggest impact?
Without these answers (and this level of cost attribution), you’re defending line items, not business decisions. But with CloudZero’s AI + Kubernetes cost intelligence, you can view, track, and report the spend down to the AI model, service, job, feature, and beyond.
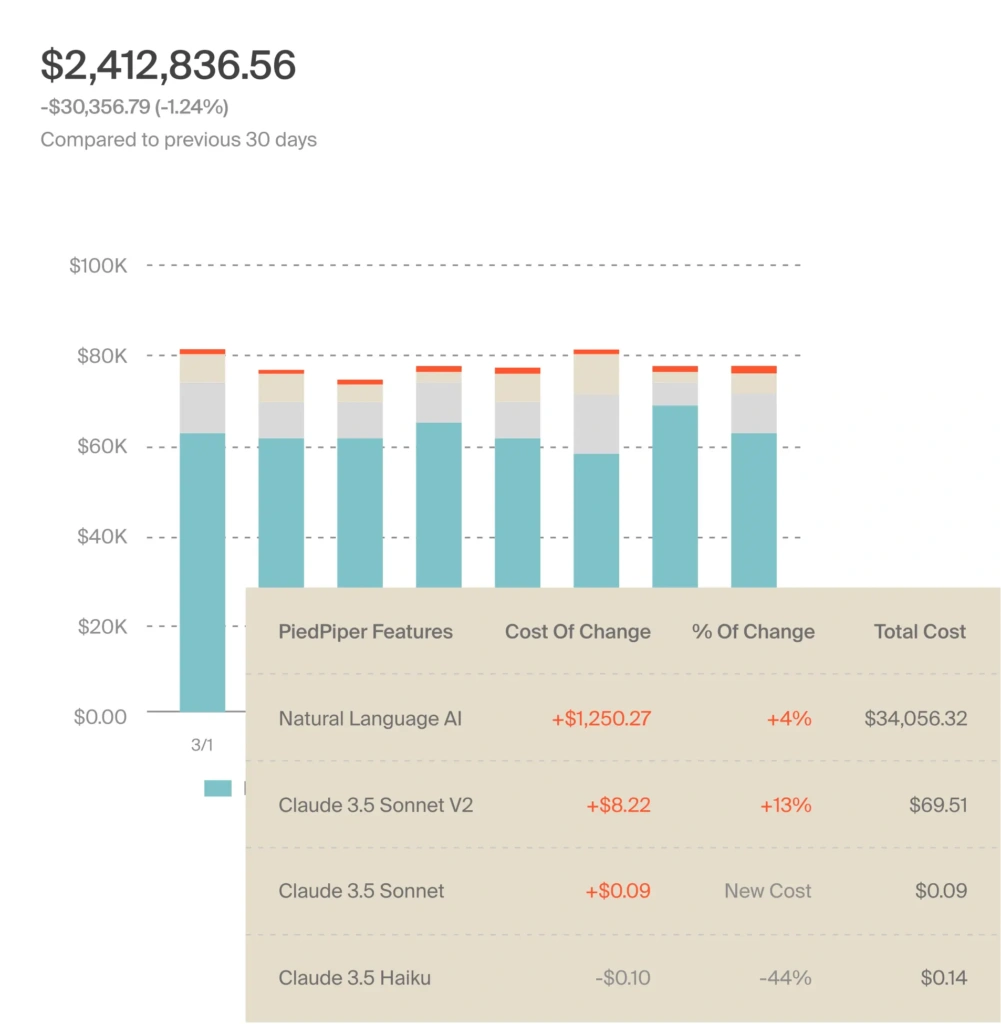
This ensures your teams innovate without losing control of the budget.
You can even automate spending alerts for each of your projects, like this:
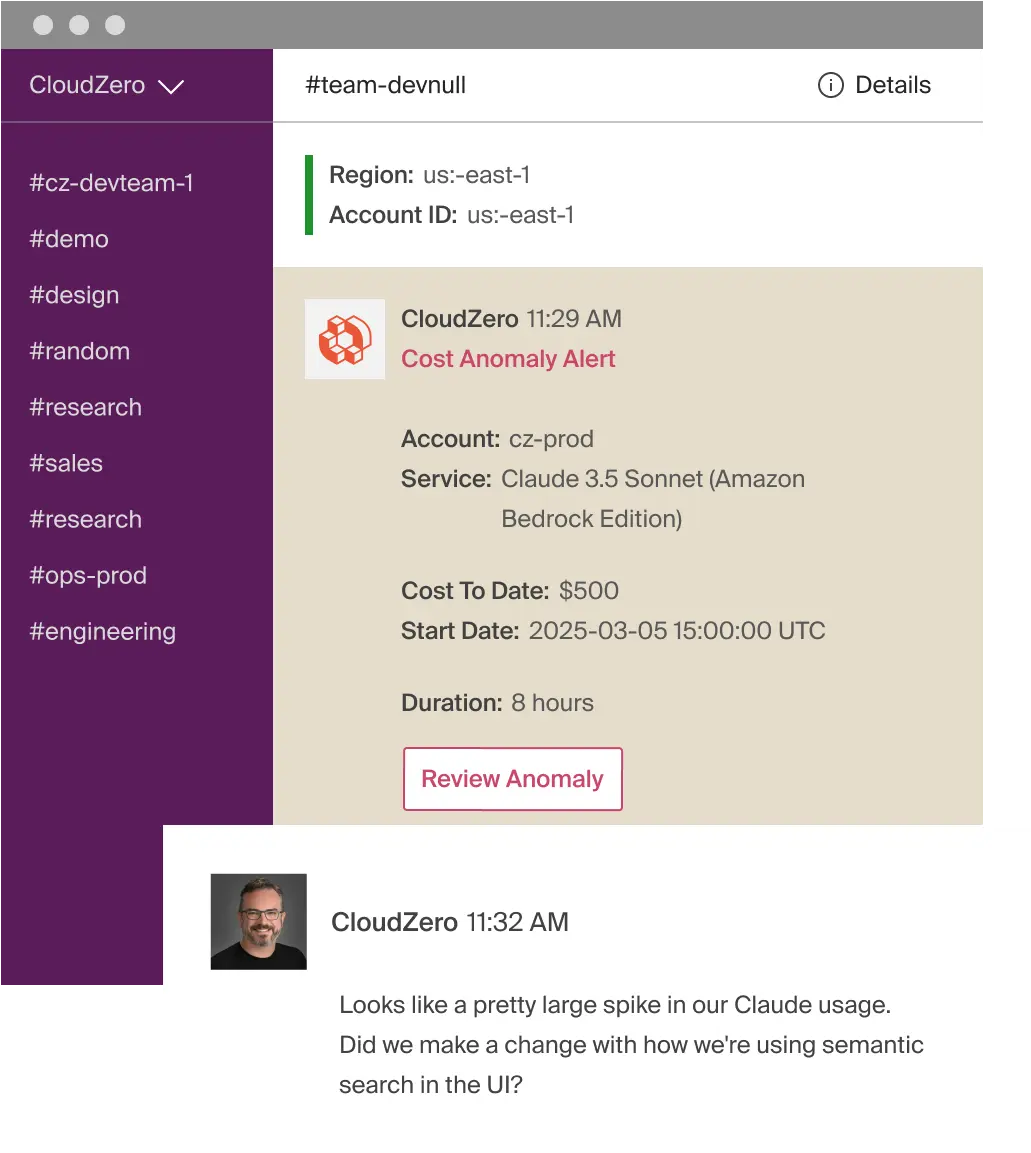
Security through churn
Building on ephemeral pod strategies, some teams are experimenting with automated infrastructure rotation (AIR), which continuously moves workloads to deny attackers persistence. Expect Kubernetes security to grow more dynamic.
Future-facing innovations are exciting, but if you’re like us, you don’t have the luxury of waiting for tomorrow’s Kubernetes. You need a path to use AI on Kubernetes today, without breaking your budget.
Run AI On Kubernetes Without Breaking The Cluster — Or Your Budget
Kubernetes delivers the elasticity, automation, and orchestration engineers need to handle unpredictable AI workloads. But those same workloads can just as easily overwhelm your clusters and cloud budget if left unchecked.
The solution isn’t to innovate less. It’s to innovate with cost confidence. And that means gaining visibility into how each job, experiment, and deployment impacts your Kubernetes costs, and vice versa.
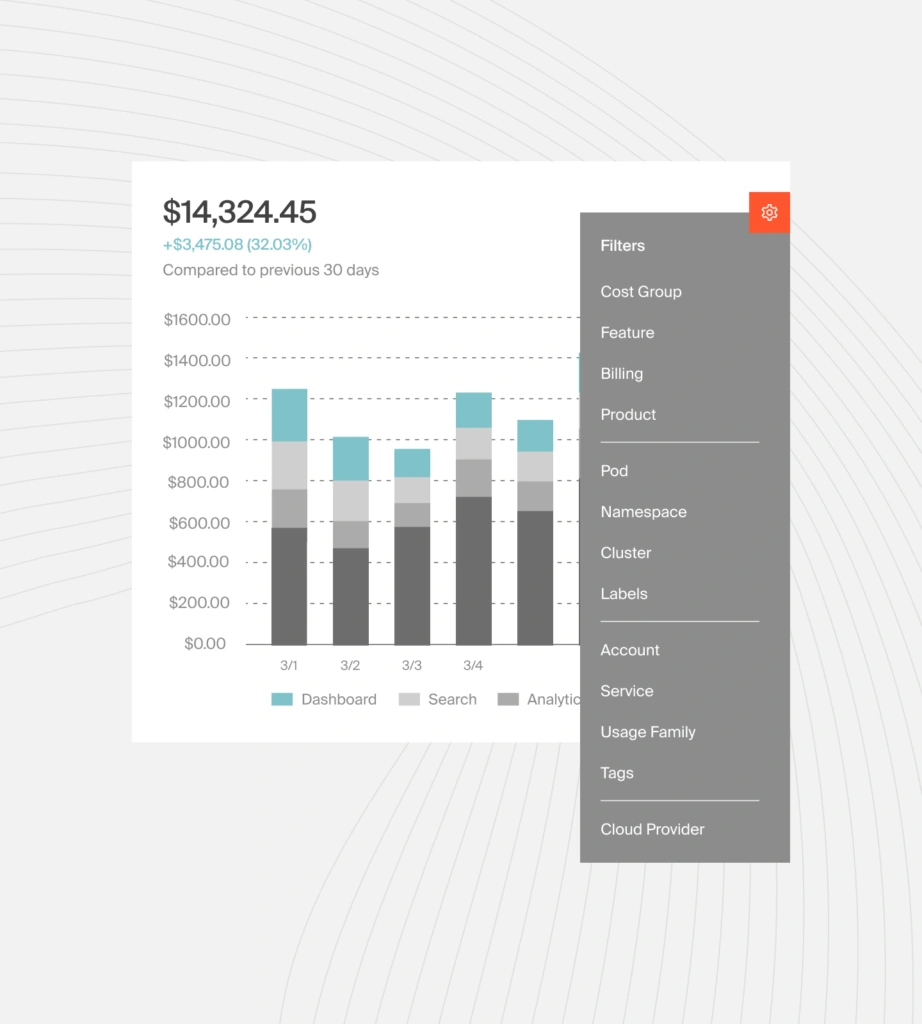
Your infrastructure is already generating this data. You’re just not seeing it yet — because conventional cost tools don’t deliver that cost intelligence.
The teams winning at Kubernetes + AI aren’t spending less, and they’re not struggling to explain costs to their boards either. They’re proving what their spending delivers and getting approvals to experiment, innovate, and scale faster. That level of visibility is how Grammarly, Helm.ai, and Coinbase (all CloudZero customers) are turning AI infrastructure from a cost center into a competitive advantage. You can, too.  and start scaling AI on Kubernetes with cost confidence.
and start scaling AI on Kubernetes with cost confidence.


FinOps In The AI Era: A Critical Recalibration
What 475 executives told us about AI and cloud efficiency.