The Amazon Simple Storage Service (Amazon S3) is a cloud storage platform that provides highly scalable, low-latency, and relatively affordable cloud storage. Plus, developers can use S3 to save, archive, and retrieve data anywhere on the web at any time with a user-friendly web interface.
Amazon S3 is a simple key-based object store you can use to store any type of data, structured or unstructured. You can also move any quantity of data to it and access it as frequently, or as infrequently, as you need to.
Ultimately, Amazon S3 aims to be a low-cost cloud storage service. Yet, many users still struggle to manage their S3 costs, and instead end up accruing thousands of dollars in unnecessary charges. Understanding what drives S3 costs is the first step to getting them under control.
If you are struggling with high storage costs, we’ve compiled over a dozen Amazon S3 cost optimization best practices to help you improve your Amazon S3 costs.
Table of Contents
But first, a brief background.
What Is Amazon S3 Cost Optimization?
S3 cost optimization is a set of best practices you can use to minimize your Amazon S3 costs while getting the most return from your object-level storage resources.
Cost optimization for Amazon S3 is not necessarily the same thing as reducing S3 costs. Reducing costs is one part of it. Here’s the difference.
Reducing costs may involve slashing some aspects of Amazon S3 indiscriminately to see your S3 storage bill reduce as soon as possible. That’s not always the best approach because it can compromise your application’s reliability in the hot pursuit of savings.
A proper cost optimization strategy involves finding out what specific cost drivers are influencing your S3 costs, so you can tell exactly what to do next without compromising your application’s performance, availability, and even security.
It also involves understanding how Amazon S3 pricing works. Let’s dive into that briefly.

Research Report
FinOps In The AI Era: A Critical Recalibration
What 475 executives told us about AI and cloud efficiency.
How Are Amazon S3 Costs Calculated?
Like most AWS services, Amazon S3 uses a pay-as-you-go pricing model. No minimum fee, upfront payment, or other commitments are required.
By leasing the storage infrastructure on AWS, you pay a monthly fee instead of purchasing all the storage capacity your application requires upfront.
This also means you can take up as much storage as you need (on-demand) on a low budget. Over time, your application can increase or decrease usage without penalties or capacity limitations.
In addition, S3’s pricing is usage-based, so you only pay for the resources you’ve already used.
Yet, a lot of variables factor into Amazon S3 billing. That includes which of its six storage classes you use.

Amazon S3 storage classes
How many requests and retrievals you make and the costs of moving the data around also matter.

Amazon S3 cost factors
Not to worry, though. For a step-by-step breakdown of how Amazon S3 pricing works, check out our guide here.
Our only focus in this article is on how to reduce, control, and optimize Amazon S3 costs. So, let’s dive in.
Top Amazon S3 Cost Optimization Best Practices To Implement Right Away
Try the following cost optimization tips for Amazon S3 to get your money’s worth in full.
1. See exactly how you use S3 before tweaking things
Using Amazon S3 Storage Lens will enable you to get a deep understanding of your usage, including retrieval patterns across all buckets within a specific AWS account. You can see your S3 usage by bucket.
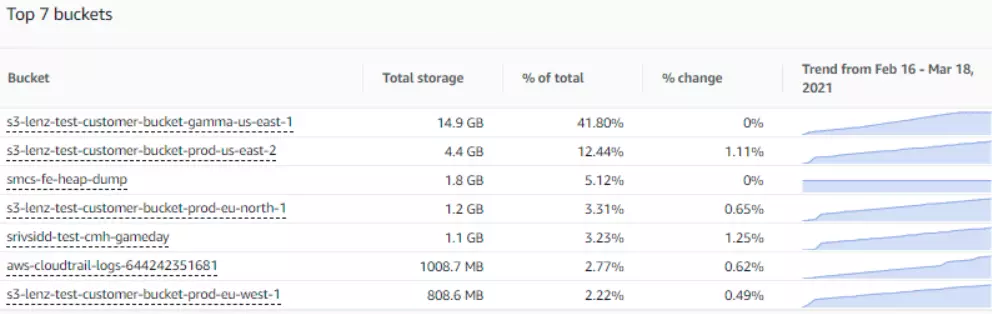
Amazon S3 Storage Lens dashboard
You can also view how well you’ve configured your S3 buckets for cost efficiency by activating cost optimization metrics.
If you want to access more detailed, activity metrics that reveal specific datasets and how frequently, infrequently, or rarely accessed they are, be sure to enable Advanced metrics through the Management Console.
Storage Lens can help you discover buckets that:
- Have incomplete multi-part uploads older than seven days
- Accumulate lots of old data versions
- Are lacking lifecycle rules to end incomplete multi-part uploads
- Have no lifecycle rules for expiring objects with noncurrent versions
- Have no lifecycle rules for transitioning objects to a cheaper storage class
The S3 Storage Lens dashboard provides several ways to optimize your storage costs using cost-optimization metrics. Here are some examples:
- Determine your largest S3 buckets
- Discover cold Amazon S3 buckets
- Track down incomplete multi-part uploads
- Identify and reduce the number of noncurrent versions that you keep
- Review lifecycle rule counts
Here’s how some of that would look with S3 Storage Lens:
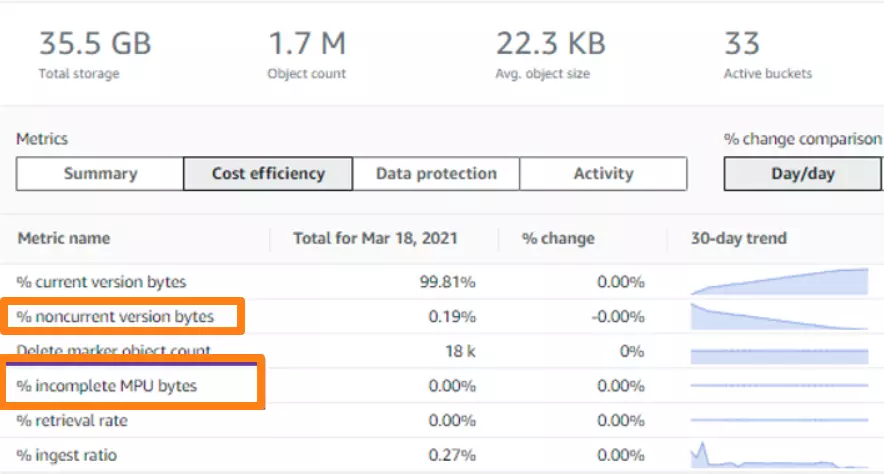
Understand S3 usage with Storage Lens
You can learn how to do all five inside the AWS Management Console here.
2. Automatically move objects to less expensive S3 storage classes
If you are still not sure when to transition data from Standard to Standard-IA, you can use Amazon S3 Storage Class Analysis to view your storage access patterns. You’ll need to set it up on a per bucket basis.
After knowing how often you access certain datasets, and which ones you can archive, use Amazon S3 Lifecycle rules to move objects automatically from the S3 Standard storage class to:
- S3 Standard-Infrequent Access
- S3 One Zone-Infrequent Access, and/or
- S3 Glacier storage classes
The rules transition the data based on its age.
To create the Lifecycle policies, use the:
- AWS Management Console
- Amazon S3 REST API
- AWS SDKs, or
- AWS Command Line Interface (CLI).
Check this out:
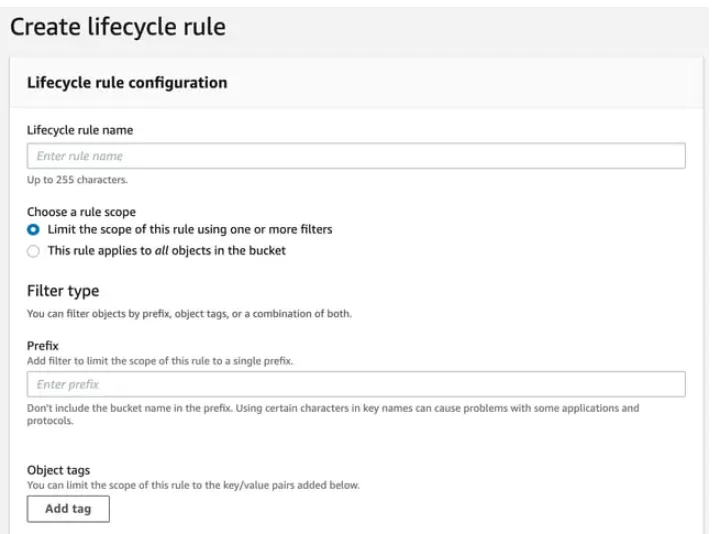
Configuring Amazon S3 Lifecycle rules
You can then define the policy at the bucket or the prefix level. Perhaps you would rather relocate objects to S3 Standard-IA class 30 days after you create them. Or, maybe you’d choose to archive objects to S3 Glacier storage 365 days after you create them.
These two S3 cost optimization techniques work best for data with predictable access patterns. Here’s how to automatically transition workloads between the cheapest S3 storage classes when access patterns are unpredictable.
3. Enable Intelligent Tiering in Amazon S3
S3’s Intelligent Tiering monitors data access patterns and automatically migrates objects to the most cost-effective storage class over time without human intervention.
Monitoring and transitioning your objects from the standard class to the Intelligent Tiering service incur additional fees.
Retrieving data you’ve stored in Infrequent Access (IA) costs $0.01 per GB.
It is still 4X cheaper than using Standard storage, which offers free retrievals. IA is particularly useful for retrieving objects once a month and for disaster recovery.
Monitoring costs $0.0025 per 1,000 data objects per month.
Here is the formula:
Monitoring costs per month = (number of objects with Intelligent Tiering/1000 objects) * $0.0025.
Transition costs per month = (number of data objects being transitioned / 1000 objects) * $0.01
So, depending on your access patterns, Intelligent Tiering may or may not save you money. In two previous steps, we’ve shared how to understand your S3 usage to help you decide whether to sign up for Intelligent Tiering.
Keep in mind that lower storage tiers have their tradeoffs, including:
- Reduced replications
- Slightly lower Service Level Agreement terms
- A longer data objects retrieval time
- A $0.01 per 1,000 objects charge for shifting data objects between two S3 storage classes.
Here’s what else you can do to lower S3 costs without compromising performance or reliability.
4. Switch out the KMS service with Amazon S3 Bucket Keys
If you use Amazon S3 with the AWS KMS service, your cloud bill will increase because each data object will require a KMS encryption operation for writing and a decryption operation for reading.
Using Amazon S3 Bucket Keys can reduce this cost by as much as 99% without making any changes to the dependent applications.
But disabled KMS keys are billable alongside active keys. If you don’t think deleting disabled keys would adversely affect your services, then it might be worth considering.
5. Speed up data transfers
Transferring data at a faster rate improves S3 performance and ensures you can access your data whenever you need it. This efficiency may also help you save money. By completing the transfers faster, you may use less compute and other billable resources.
Before implementing this on a larger scale, you’ll have to test it on a smaller scale first and decide if it makes economic sense.
To set this up, use S3 Transfer Acceleration, which leverages Amazon CloudFront’s distributed edge locations to deliver up to 10X faster data transfer speeds than traditional methods. You can set the feature up by going to Properties and scrolling down to Transfer acceleration.
6. Get only the data you need
Using S3 Select, you can retrieve only the specific data you require from an object, reducing data retrieval time and costs. You can use the find object by prefix search bar to find a specific object in a particular bucket.
For S3 Select to work, you must have your bucket’s files stored in CSV, JSON, or Parquet formats. And, to set this feature up, go to Action > Query with S3 Select.
7. Align storage with compute location
Using a different AWS region for your Amazon EC2 instance and S3 service may lower your performance overhead, but increase your data transfer costs.
EC2 instances and S3 buckets set to the same region allow free data transfers. So, if you’re looking to save money, it’s best to keep your EC2 instance and S3 bucket in the same region. That way, your data can stay where it belongs – together like peanut butter and jelly!
Replicating your S3 bucket may be the most efficient way to optimize spending if you often transfer data to other regions.
Not so fast, though. When the objects and total size of the bucket are large or there are a lot of replications, replicating the bucket could prove expensive.
Replication can also result in data inconsistency. If you have high traffic in downloads (S3 servers), you’ll want to migrate cacheable files to AWS CloudFront. It is more performant and cost-effective than S3 most of the time.
8. Set up IAM to control access
Identity and Access Management is not just a way to control access to your data. It also empowers you to specify who can access it and what changes they can make.
You can, for example, give users read-only access, preventing them from taking actions that can modify the data, and vice versa to limit data retrieval costs.
You can set up IAM by searching for it inside your AWS account. Then click on the Identity and Access Management result. Go to the User tab to add or remove permission policies for a specific person.
9. Delete unused data
When files are no longer relevant, delete them.
Also, delete any relevant files you are no longer using, but could recreate relatively easily if you need them.
Check if you have any incomplete uploads. They cost you money, so if there are any, delete them. Following on from what we discussed earlier, you can use S3 Lifecycle rules to automate this process.
Oh, and remember to empty your recycle bin.
But if you are not too sure about deleting objects forever, you can archive them at the lowest Amazon S3 storage cost with Amazon S3 Glacier Flexible Retrieval or S3 Glacier Deep Archive. Both enable you to archive vast amounts of data for months, years, or decades.
In addition, you can automate the archiving of old and not-used objects to Amazon S3 Glacier with lifecycle policies. Or, you can also do it manually if you want to be more deliberate about it. Keep in mind that once you archive objects here, you must restore them before you can use them again.
10. Upload objects to S3 in bulk
Data size does not determine Amazon S3 API costs. The type of call does. The cost is the same whether you upload a large or small file.
Yet, uploading multiple small files can become expensive pretty fast. A way that works is to use tar to batch multiple small objects into a single file. You can then upload them in bulk instead of in chunks to reduce S3 API calls, and thus costs.
11. Use Parquet format
Object compression improves performance, reduces storage requirements, and, therefore, lowers costs.
There are several compression methods, such as LZ4, GZIP, and even ZSTD, that provide excellent performance and take up little space, depending, of course, on the use case. Parquet is also more cost-effective than, say, CSV.
12. Partition the data before you query it
Reading S3 data often requires SQL queries. Services like Amazon Athena, Redshift Spectrum, and AWS EMR (while using EMRFS) link their tables to Amazon S3 folders and buckets. The Queries must scan many files in the target bucket when the data files in them lack common partitioning, say by date or time.
This can generate lots of unnecessary GET requests, so whenever applicable, always partition the data before querying it.
13. Empower your engineers to optimize Amazon S3 costs
You’ve probably done it yourself. You spawn a demo instance but forget to turn it off after use. Several engineers doing this could lead to unexpectedly high costs later on.
Setting up and following procedures when working with cloud infrastructure can promote a culture of cost ownership among your engineers.
Establish clear guidelines for when to turn off or delete resources, such as during specific work hours, whenever they are not using them, and when a resource has been idle for a certain number of minutes.
You can do better than that:
- Specify and continually use monitoring metrics to provide data-backed insights
- Track those metrics often to avoid surprises
- Provide cost data in a language that engineers understand
- Train your engineers to treat S3 storage costs as a first metric so they can balance application performance, security, and cost optimization.
- Set up alerts and get billing alarms in time to block overspending
How do you do all that without pulling your hair, you ask?
Set up CloudWatch alerts to detect usage anomalies. AWS Cost Explorer is another option for viewing high-level S3 cost data and visualizing spend trends over time. Alternatively, you can download AWS Cost and Usage Reports to an S3 bucket and manually search through thousands of raw line items.
Or, you can skip the manual frustration, view Amazon S3 costs in full context, and take advantage of real-time cost anomaly detection with CloudZero.
How To Better Understand, Control, And Optimize Your Amazon S3 Costs
CloudZero’s unique code-driven approach gives you complete cost intelligence across your infrastructure and applications. This applies whether your Amazon S3 buckets have messy or perfect cost allocation tags.
The CloudZero platform also tracks the costs of resources each tenant in a multi-tenant environment uses, so you can charge them profitably.
Better yet, you can analyze Amazon S3 costs by individual cost drivers, including cost per customer, product, software, environment, etc.
Engineering-friendly perspectives are available, including cost per dev team, per environment, per feature, per deployment, and more. You also get noise-free cost alerts via Slack, email, etc.

You can even see how costs change in near real-time when you make architectural changes. This cost awareness empowers your engineers to build more cost-effective products that compete favorably in your market.
The finance team can also see the cost of supporting an individual customer, COGS, gross margin insights, and more.

Then you can determine the cost of onboarding and supporting similar customers. Also, you can figure out if you are making a healthy margin off a certain client and if you need to renew their contract terms to remain profitable.
Yet, reading about CloudZero is nothing like seeing it for yourself. We are already saving customers like Drift $2.4 million annually on AWS alone. You can too.  to see how.
to see how.


FinOps In The AI Era: A Critical Recalibration
What 475 executives told us about AI and cloud efficiency.






![Amazon RDS Instance Types Explained [Classes, Sizes, Costs, and Tradeoffs]](https://www.cloudzero.com/wp-content/uploads/2026/01/rds-instances.webp)