Two years ago, a “state-of-the-art” AI model could write decent copy or summarize a meeting transcript. Today, the top AI models — and any honest LLM comparison — reveal how far we’ve come: working code generation, real-time video analysis, and multi-step reasoning.
For SaaS teams, these changes represent a strategic crossroads.
Choose the right model and you unlock new revenue streams, slash time-to-market, and wow your users.
Choose wrong, and you’re staring at ballooning GPU bills, compliance headaches, and a tech stack that can’t keep up. Not good.
In the next few minutes, we’ll share a clear view of the top AI models in 2025, their most impactful use cases for SaaS, and the emerging trends you’ll want to track to stay ahead (or at least keep up) — without overspending.
What Are The Leading AI Model Types (And Why Do They Matter For SaaS)?
GPT 5 has sharpened its reasoning, Claude 4 has closed the gap in software engineering benchmarks, and DeepSeek R1 has redefined the price-to-performance curve.
Heck, the newest releases can even run as autonomous multi-agent systems.
But not so fast, let’s step back to understand the main “species” you’ll encounter in the AI Wild West.
1. General-purpose Large Language Models (LLMs)
These models can code, write, summarize, translate, and even reason through multi-step problems. This makes LLMs ideal for embedding across multiple SaaS features, from user-facing chatbots to backend process automation.
Yet, that versatility also means token usage and multimodal inference costs add up fast, especially if you don’t have strong usage and cost monitoring in place.
See: AI Costs Climb 36% But ROI Still Unclear, Report Finds
2. Domain-specific or vertical AI models
These are trained or fine-tuned for a specific industry or problem space. Think of legal contract reviews, financial forecasting, or healthcare diagnostics. And this can mean higher accuracy in niche applications, reducing the need for complex prompt engineering or heavy post-processing.
The catch here is that training or fine-tuning for your exact domain can require significant upfront investment. However, inference costs may be lower in the long run.
3. Multimodal models
Models like Gemini and Grok 3 also handle images, video, audio, and even sensor data.
This is perfect for products that need rich media capabilities. Think of video analysis, image-based search, or voice-powered interfaces.
The thing is, multimodal inference can be a GPU-intensive beast. To keep things humming without breaking the bank, you’ll want to know your per-request costs before rolling it out to thousands of users. That way, you’ll know in advance how your costs could scale.
4. Open-weight and open-source AI models
LLaMA 4, Mistral, and DeepSeek’s open releases let you run open source AI models on your own infrastructure, tweak them for your use case, and avoid vendor lock-in. This means greater control over data privacy, model behavior, and long-term costs.
In terms of cost, you’re responsible for hosting, scaling, and securing the model, which can shift costs from API bills to infrastructure spend.
5. Agentic and multi-agent systems
This is a newer breed where multiple specialized AI agents collaborate. One might plan. Another might execute. A third might validate results. They enable complex, multi-step workflows to run without constant human oversight.
Yet, more agents often mean more model calls. And without governance, your “autonomous” system can autonomously burn through your quarterly budget in weeks — which is why understanding FinOps for AI matters before you scale.
Once you get this taxonomy right, you can stop chasing shiny-object releases and focus on finding the best large language model for your SaaS product vision, technical stack, and cost tolerance. We’ll dive into the specifics next.
Report
Finance needs to prove AI’s return: CloudZero report
260 senior finance leaders (more than half CFOs) told us why the speed of seeing AI spend, not the size of it, separates who pulls ahead on AI from who gets burned.
The Leading AI Models Today: An Overview
First, a quick lineup of the leaders before we dive deeper:
|
AI Model |
Key Strengths |
Pricing |
Licensing |
Ideal SaaS Use Cases |
Potential Cost Gotchas |
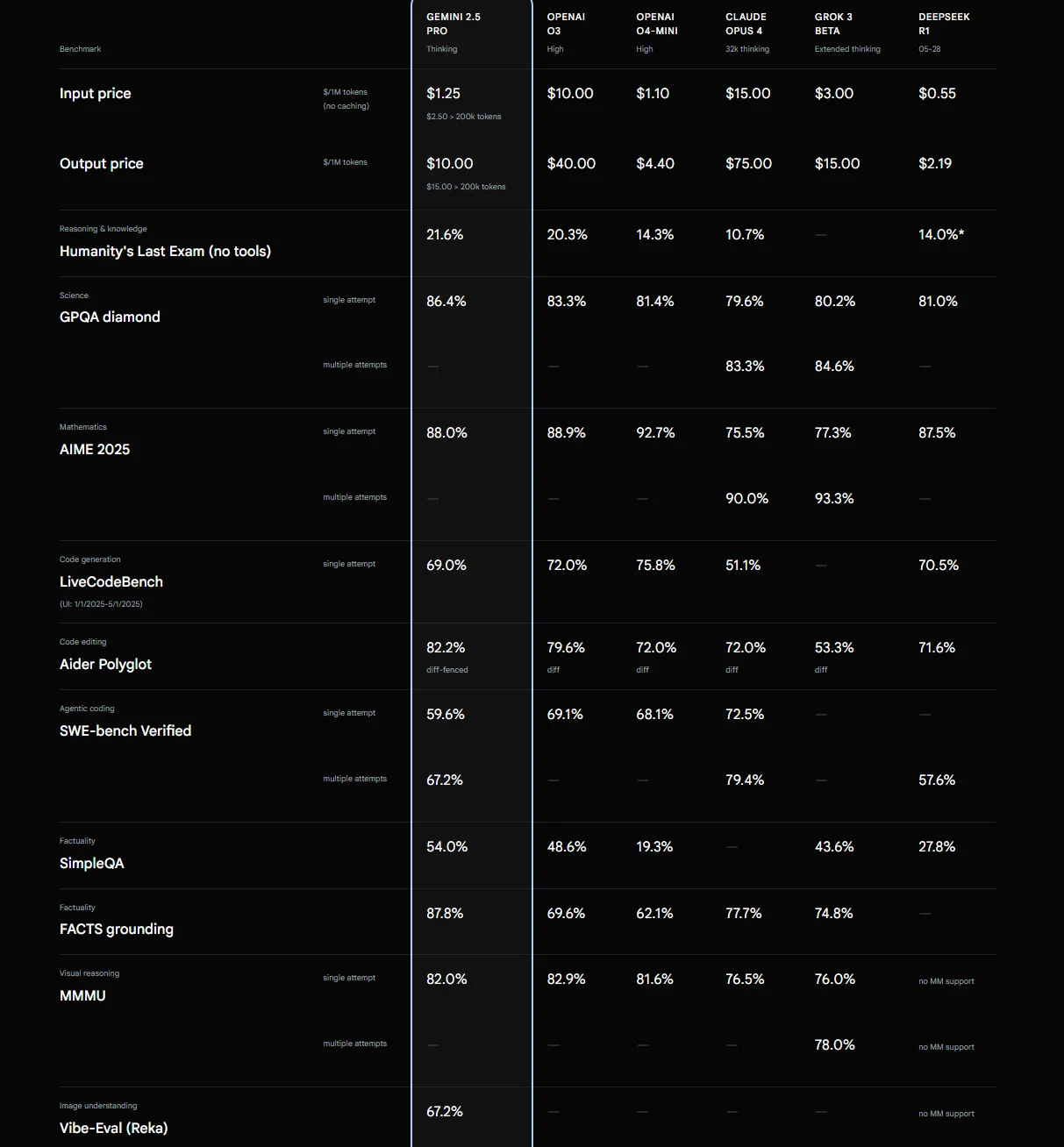
OpenAI GPT 5 | Exceptional reasoning, strong code generation, broad general-purpose capabilitie s, factual accuracy | Premium: $1.25 per 1M input tokens, $10 per 1M output tokens |
Proprietary API |
Complex chatbots, code assistants, advanced analytics |
High token costs, especially for long-context tasks |
|
Anthropic Claude 4 (Opus 4) |
Strong reasoning, great at brainstorming & summarization, high SWE-bench score |
About $15 per 1M input tokens, about $75 output |
Proprietary API |
Documentation, long-form content, product strategy assistants |
Slower availability of new features vs OpenAI |
|
Google Gemini 2.5 Pro / Flash |
Multimodal (text, image, video, audio), long context, “Deep Think” reasoning |
About $20–$40 per 1M tokens (varies by tier) |
Proprietary API |
Video analysis, multimodal search, customer engagement tools |
GPU-heavy inference costs |
|
DeepSeek R1 |
Disruptive low-cost model with competitive reasoning |
Free tier + <$2 per 1M tokens |
Open weight |
Budget-friendly chatbots, internal tools, bulk text processing |
Lower multimodal capabilities |
|
xAI Grok 3 |
Real-time search reasoning, “Think” mode for deep reasoning |
About $3 per 1M input tokens, about $15 output |
Proprietary API |
AI assistants with live data, knowledge workers |
Limited enterprise integrations so far |
|
Meta LLaMA 4 |
Open-source, high multimodal support, customizable |
Free (self-host) |
Open weight |
Privacy-sensitive SaaS features, edge deployment |
Infrastructure, maintenance costs |
|
Mistral AI (Small 3.1, Mixtral, Magistral) |
Compact, fast, and open-weight; strong for reasoning & low-latency use cases |
Free/low hosting cost |
Open weight |
Real-time tools, embedded AI, cost-sensitive apps |
Needs fine-tuning for niche accuracy |
|
Alibaba Qwen 3 |
Strong multilingual support, open weight |
Free (self-host) |
Open weight |
Global SaaS products, multilingual agents |
Fewer Western-language fine-tunes |
Table: A side-by-side look at the top AI models in 2025
Top AI Models In Depth: Strengths, Limits, And Trade-Offs
Let’s unpack each model in more detail so you can see the capabilities and limitations you’ll want to weigh before choosing one.
OpenAI’s GPT 5
GPT-5, released on August 7, 2025, is OpenAI’s most advanced model yet. It builds on GPT-4.5 with smarter reasoning, better accuracy, and faster performance.
It’s also multimodal, meaning it works with text and images together.
Its core strengths include:
- Deeper reasoning: Handles complex, multi-step problems better than previous models. Great for strategy, analytics, and technical workflows.
- Massive context window: Supports up to 400K tokens, perfect for long documents, research, or codebases.
- Multimodal capabilities: Understands text and images together, making it useful for design, healthcare, and coding.
- Accuracy and reliability: Reduces hallucinations and now says “I don’t know” when unsure. More trustworthy for high-stakes tasks.
- Personalization: Enables users to adjust tone and style. Pro users can even customize voices and integrate tools such as Gmail or Calendar.
Enterprise power: Adopted by major companies for structured thinking, planning, and coding.
See also: How CloudZero’s OpenAI Integration Provides Unprecedented AI Unit Economic Insights
Anthropic’s Claude Opus 4.1 and Sonnet 4
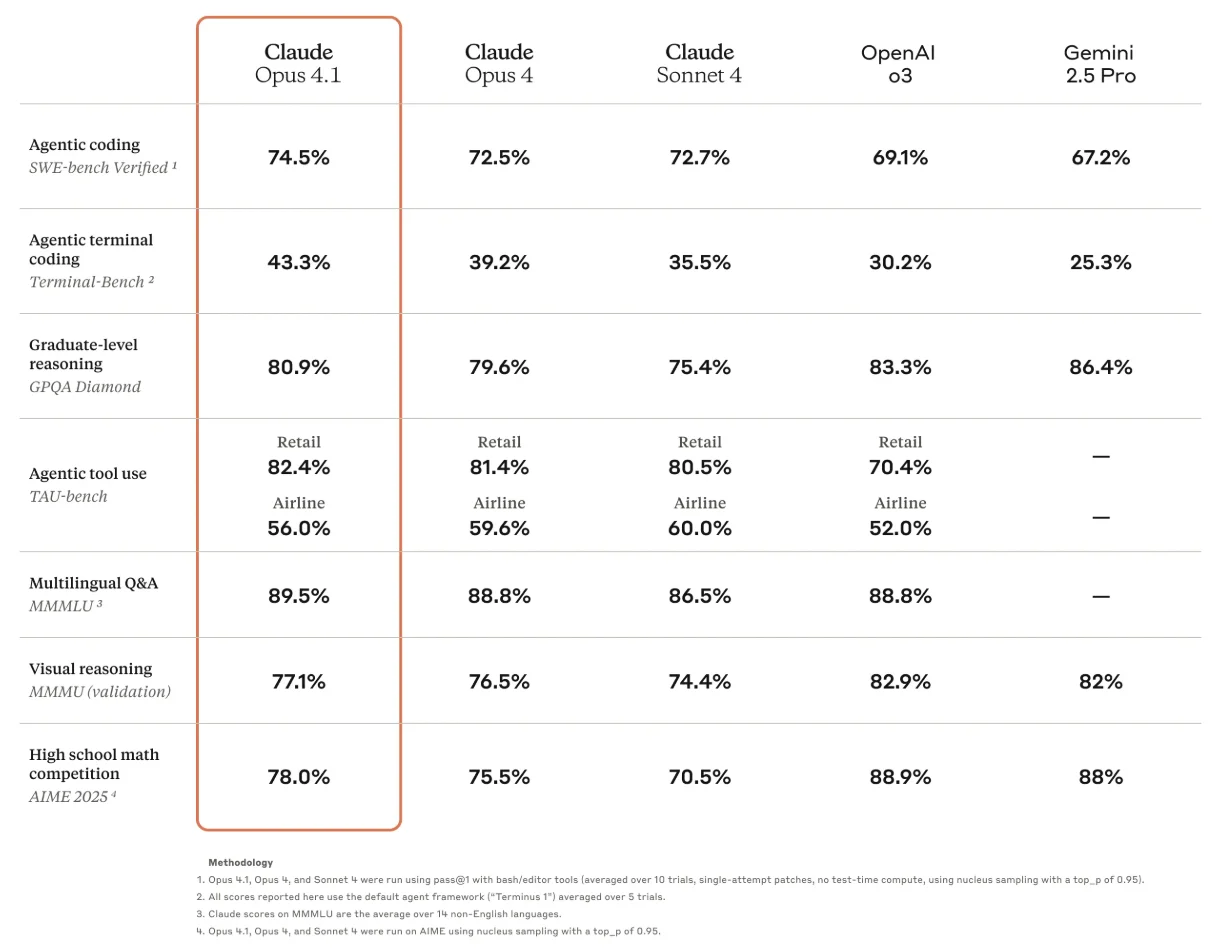
Claude Opus 4.1 has established itself as one of the most capable reasoning models available, with a SWE-bench score hovering around 74.5%.
It offers nuanced, multi-step reasoning. This means it can be particularly effective for engineering problem-solving, RFP drafting, and high-level technical documentation.
Latency is in the 5–7 second range for complex reasoning. Its sibling, Claude Sonnet 4, matches the reasoning scores but delivers significantly faster responses (averaging three seconds) at roughly one-fifth the cost ($3 per million input tokens and $15 per million output).
For SaaS teams processing high chat volumes or running multi-turn customer support workflows, Sonnet offers a better price-performance balance without sacrificing too much accuracy.
The trade-off is that Sonnet lacks some advanced memory and orchestration features you’ll find in Opus, and that can limit its utility for persistent agentic systems.
Gemini 2.5 Pro and Flash
This is Google DeepMind’s latest multimodal flagship. Gemini 2.5 Pro is capable of ingesting and reasoning over text, images, audio, and video within the same query.
Its “Deep Think” mode supports structured, multi-step reasoning over extended contexts of up to 1 million tokens. However, in practice, latency increases considerably on such large prompts, with processing times reaching 8–10 seconds for multimodal tasks.
The Flash variant is optimized for lower latency (2–4 seconds) with smaller context limits. And that makes it suitable for real-time SaaS applications like visual search, voice interfaces, and customer interaction analysis.
While Gemini lags slightly behind Claude and GPT 5 in SWE-bench coding benchmarks, its multimodal capabilities and tight Google Workspace integration make it attractive for SaaS products that rely on diverse media inputs.
That said, watch out for GPU-heavy inference costs and potentially higher bills when handling high-resolution video or image workloads without pre-processing.
DeepSeek R1

DeepSeek R1 made waves at the start of 2025 when it offered competitive reasoning performance at a fraction of the cost of Western models. It cost just $5.6 million, compared to GPT-5’s projected $500 million training budget.
Yet, it delivers strong results in math and logic tasks.
Current rates hover around $0.55 per million input tokens and $2.19 per million output. This means it is ideal for budget-sensitive SaaS deployments or high-throughput internal tools.
Its context window sits at 128K tokens, with latencies averaging 3–5 seconds for reasoning workloads.
Now, while it lacks robust multimodal features, R1’s open-weight availability means your team can host and fine-tune it in their own environments. And that can further drive down your long-term operating costs.
One caution, though. U.S. policymakers have flagged potential data-security risks, so if you are handling regulated or sensitive information, you’ll want to assess compliance implications before adopting it.
xAI Grok 3 and Grok 4
Grok is designed with real-time information retrieval in mind. The models integrate live search data into their reasoning process, which is handy for SaaS products that require up-to-the-minute responses.
Grok 3 offers a 256K token context window with average latencies of 2–4 seconds. Meanwhile, Grok 4 improves reasoning depth and factual recall.
Grok pricing is competitive at $3–$6 per million input tokens and $15–$30 per million output. But because Grok’s primary differentiator is its access to real-time web data, your costs can scale quickly if agents are making frequent, large context calls.
However, you can use a caching layer or intelligent request routing (say, sending static knowledge questions to a cheaper open-weight model) to keep your budget under control.
Meta LLaMA 4
Meta’s latest open-weight release offers improved multilingual and multimodal capabilities. Also, expect a more compact architecture that enables edge deployment.
Its context window extends to 128K tokens, with latencies of 1–3 seconds depending on hosting hardware. For SaaS companies prioritizing data privacy or operating in low-latency environments, self-hosting LLaMA 4 on dedicated infrastructure can eliminate per-token API costs entirely.
However, infrastructure expenses (GPUs, storage, MLOps tooling) become your responsibility. And for teams without in-house AI operations expertise, the total cost of ownership may outweigh API savings, well, unless your usage volumes are consistently high.
Mistral AI (Small 3.1, Mixtral, Magistral)
Mistral’s open-weight models are known for their speed and efficiency. Small 3.1 is optimized for low-latency inference (often under one second) and lightweight multimodal tasks, while Mixtral and Magistral deliver stronger reasoning and multilingual capabilities.
Their context windows range from 32K to 64K tokens. That may be smaller than some proprietary competitors, but it is often sufficient for embedded SaaS applications, like real-time chat assistants or customer onboarding flows.
Self-hosting is straightforward. The smaller model sizes also make Mistral especially attractive for edge or hybrid cloud deployments where minimizing GPU footprint is a priority.
Fine-tuning is often required for high-accuracy domain tasks. However, the open licensing and low operational overhead make it a cost-efficient choice for many SaaS scenarios.
Qwen 3
This is Alibaba’s multilingual model series. Qwen 3 is tuned for high accuracy in languages beyond English. Its 128K context window and reasonable latency (2–4 seconds) also make it competitive for global SaaS offerings.
That is especially strong for those serving Asian, European, and African markets, where English is not the primary language.
Also, Qwen is open-weight, so you can fine-tune it to reflect industry-specific terminology and regulatory requirements.
The cost benefits mirror those of other self-hosted models, but as with LLaMA 4 and Mistral, your success will depend on having the infrastructure and operational processes to run it efficiently.
That’s the current playbook. Next, let’s look ahead at the trends shaping the next generation of AI in SaaS — and what they’ll mean for your budget and roadmap.
AI Models For SaaS: High-Impact Use Cases You Can Put To Work Today
Here’s what’s powering the next wave, so you can rethink, retool, and reshape in time to ride the momentum (not get swamped by it).
Agentic AI is on the rise
We’re moving beyond single, monolithic models to multi-agent systems that can plan, execute, and validate in loops — without constant human prompts.
In practice, workflows start to resemble autonomous business units: one agent drafts the plan, another does the work, and a third checks the output against your SaaS KPIs.
The upside is speed and scalability. The potential risk is that multiple agents calling multiple models can quietly multiply your inference bill if you’re not tracking usage at the agent level. Most cloud cost management tools can’t do this well (but we’ll show you how to later).
Meanwhile, CloudZero’s founding engineer, Adam Tankanow, shares lessons SaaS teams can use right now in his guide to building systems for AI.
Vertical and domain-specific models are gaining ground
Regulation, data sensitivity, and customer expectations are driving demand for models fine-tuned on industry-specific datasets. Think of finance, healthcare, legal, manufacturing, and more.
These models often outperform general-purpose LLMs in their niche. And this can reduce the need for heavy prompt engineering.
But specialized training can be expensive, which is why many teams are building hybrid stacks. They are using a domain-specific model for high-stakes queries, paired with a cheaper general-purpose or open-weight model for everything else.
See: AI On A Budget: Low-Cost Strategies For Running AI In The Cloud
Open-weight and hybrid deployments are more accessible
With LLaMA 4, DeepSeek R1, and Qwen 3 lowering the barrier to self-hosted AI, more SaaS companies are running models on their own infrastructure — either fully on-prem for compliance or in hybrid setups to balance latency, privacy, and cost.
This shift changes the cost equation entirely. You swap per-token API fees for GPU, storage, and ops expenses — and AI inference costs become your new operating burden. That makes cost attribution and resource utilization tracking non-negotiable.
See: AI Cost Optimization Strategies For AI-First Organizations
Multimodal expansion is unlocking new features
Models that can process text, audio, video, and images in a single query are opening the door to entirely new SaaS experiences. We are talking real-time video feedback, audio-driven analytics, and image-based onboarding flows.
The challenge here is that multimodal inference is GPU-hungry, and without optimization, your compute costs can triple. However, teams are fighting this with batching, compression, and partial offline processing.
Usage-based and outcome-driven pricing is rising
SaaS pricing is evolving to mirror AI consumption patterns. Flat monthly rates are giving way to per-request, per-token, or outcome-based billing. The goal here is to align customer spend with actual compute usage.
For CFOs, it complicates forecasting but creates opportunities to tie AI costs directly to value delivered (ROI). Again, we’ll share how to do that below.
Related read: AI Costs In 2025: A Guide To Pricing, Implementation, And Mistakes To Avoid
AI governance is becoming a selling point
The EU AI Act and similar regulations are pushing SaaS vendors to document model provenance, training data, and risk mitigation measures.
Voluntary codes of practice for general-purpose AI providers are already in motion, and if you integrate these models, you’ll be expected to keep pace.
Done right, compliance will be part of your competitive advantage, not just a legal checkbox. See how leading companies are connecting AI cost optimization strategies to governance workflows.
Sustainability will shape buying decisions
Training and running large AI models consume serious energy. With carbon accounting and ESG reporting now part of the conversation, tracking the environmental footprint of your AI workloads is no longer optional.
Instead, forward-thinking teams are baking carbon-cost metrics into their FinOps dashboards, like this:
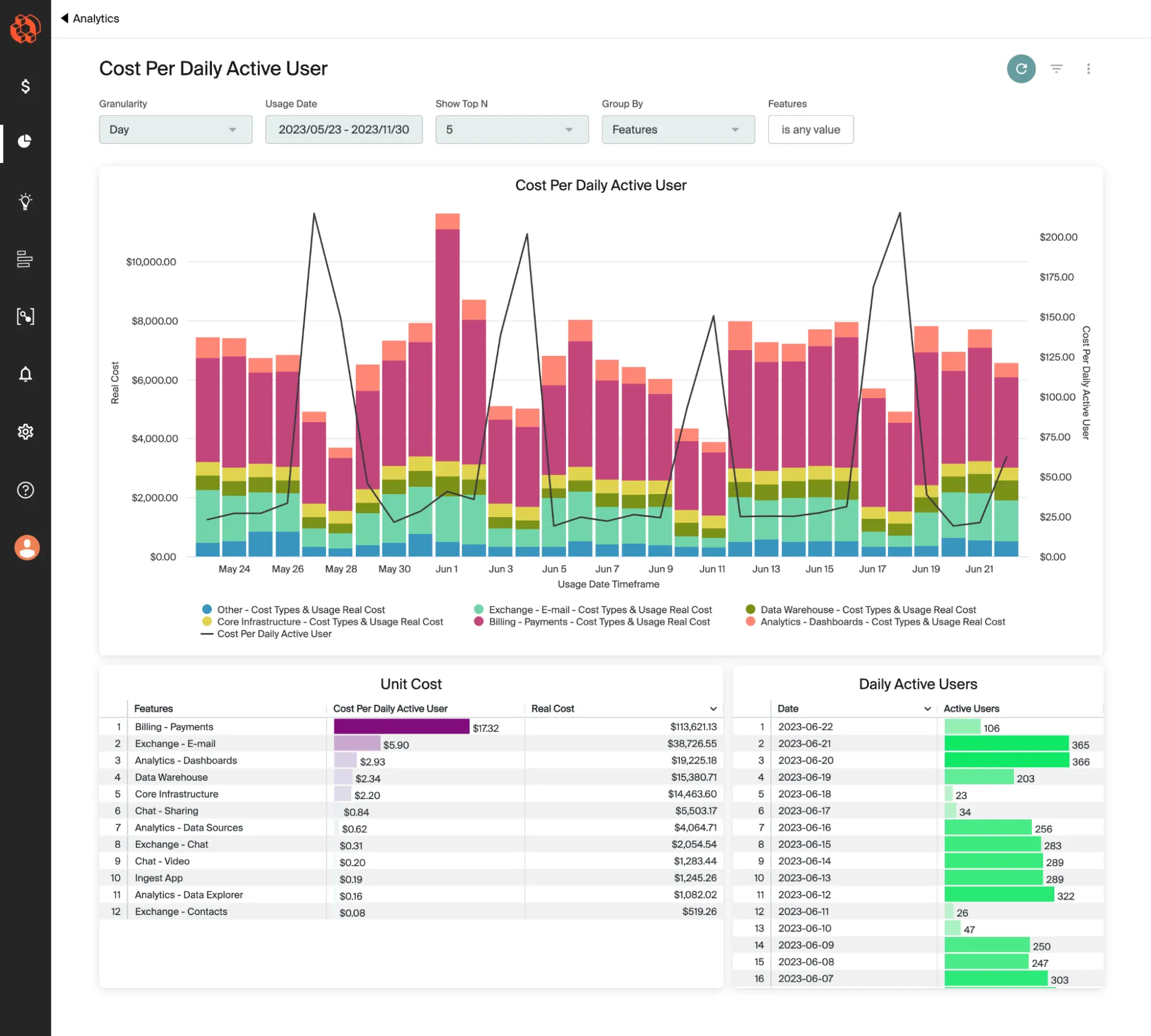
Image: CloudZero Cost per Daily Active User dashboard
The visibility provides customers and investors with data-backed insight into sustainability performance alongside spend and performance metrics.
AI Can Drive Your SaaS Growth, Or It Can Drain Your Budget
Skipping AI isn’t really an option anymore. The right AI model can turbocharge your growth, differentiate your offering, and open new revenue streams.
Yet, every query, training run, and multimodal inference call contributes to your total AI model cost — and that cost is anything but static. AI spend maps to prompts, tokens, agent activity, and experimentation, all of which shift constantly — making AI inference cost tracking a core requirement, not an afterthought.
Without granular visibility, AI-driven innovation can turn into a line item that balloons faster than your customer base.
Turn cost blind spots to AI-driven growth
AI is powering the fastest-growing SaaS companies in 2025. But every prompt, training run, and inference call eats into your budget. And without visibility, those costs spike before you see them coming.
CloudZero gives you real-time answers to the AI questions that keep CFOs and CTOs awake:
- Which customers, features, and teams are driving AI spend?
- Are we paying premium rates for work that cheaper models could handle?
- Can we forecast and control AI costs as easily as infrastructure spend?
- How do we attribute costs down to the prompt, feature, or customer level?
If you can’t answer these now, your next invoice will.
That’s why companies like Duolingo, Moody’s, and Skyscanner use CloudZero to align costs with business value. They’re innovating at full speed, without losing control of their budgets.
 and start getting control before your next billing cycle hits. The sooner you see what you’re running and what it’s costing, the sooner you can turn AI from a wild card into a growth engine.
and start getting control before your next billing cycle hits. The sooner you see what you’re running and what it’s costing, the sooner you can turn AI from a wild card into a growth engine.











