

Quick Answer
Amazon Comprehend pricing is based on a per-unit model, where one unit equals 100 characters of processed text. Standard NLP APIs start at $0.0001 per unit with a 300-character minimum per request. Custom model endpoints bill by the second — idle or not — at $0.0005 per inference unit per second, which makes them the most common source of runaway spend. This guide covers every billing dimension, from PII screening to topic modeling, and how to keep costs predictable at scale.
Most AWS-managed AI services follow the same arc: low entry cost, fast adoption, then a bill nobody fully anticipated.
Amazon Comprehend is no different. At $0.0001 per unit (per 100 characters) for standard NLP, it’s easy to treat as effectively free, until a real-time endpoint runs idle for a month, or event detection runs across a high-volume pipeline extracting multiple event types per document.
This CloudZero guide covers every billing dimension in Amazon Comprehend pricing, what it actually costs at different usage levels, and the specific decisions that most often drive unexpected spend.
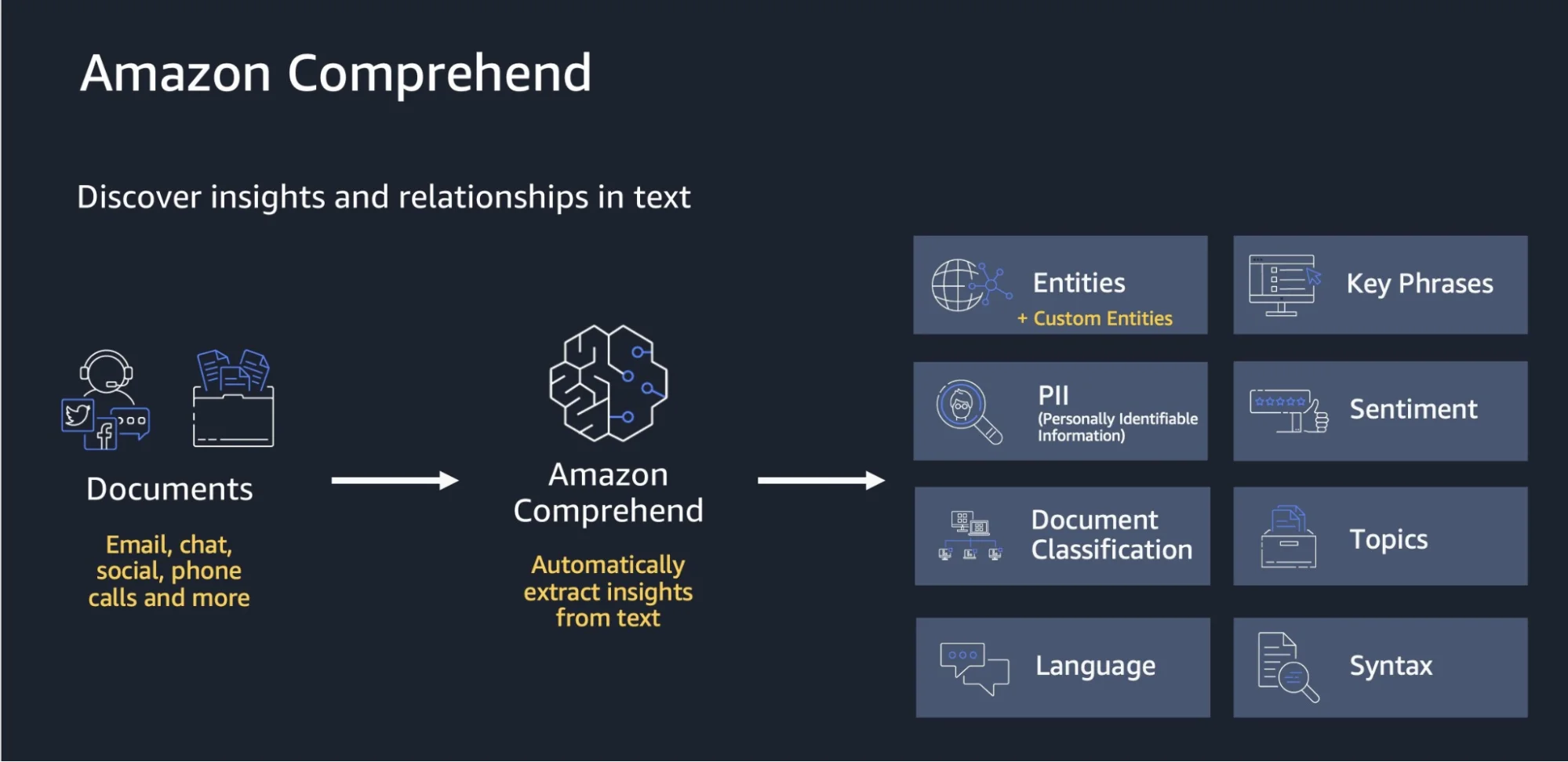
What Is Amazon Comprehend?
Source: AWS
Amazon Comprehend is a fully managed natural language processing (NLP) service on AWS. It uses machine learning to extract meaning from unstructured text without any model-building experience on your end.
What is Amazon Comprehend used for?
Common Amazon Comprehend use cases include:
- Sentiment analysis. Determines whether text is positive, negative, neutral, or mixed
- Entity recognition. Identifies people, places, organizations, and dates
- Key phrase extraction. Surfaces the most meaningful phrases in a document
- Language detection. Identifies which language a document is written in
- Syntax analysis. Parses grammatical structure
- PII detection and redaction. Finds and optionally removes personally identifiable information
- Topic modeling. Groups documents by dominant themes
- Custom classification and entity recognition. Trains models on your own labeled data
- Toxicity detection and prompt safety classification. Filters harmful or unsafe content in AI applications
playbook
The AI Cost Optimization Playbook
Traditional cloud cost management is broken. Here’s why — and how to make the switch to cloud cost intelligence.
How Amazon Comprehend Pricing Works
Comprehend uses a consumption-based pricing model. You pay for what you process, not for reserved capacity, with one notable exception: real-time endpoints for custom models, which bill continuously from the moment they’re started until they’re deleted.
Amazon Comprehend’s base billing unit is 100 characters of text. Every API request carries a minimum charge of three units (300 characters), regardless of input length — so processing a 50-character string costs the same as processing 300 characters.
That minimum applies across most APIs and catches a lot of teams off guard when they’re processing large numbers of short strings.
There are five main Amazon Comprehend billing categories:
- Natural language processing (NLP) APIs
- PII detection and redaction
- Custom Comprehend for training, inference, and endpoints
- Topic modeling
- Trust and safety for toxicity detection and prompt safety classification
Amazon Comprehend pricing: NLP APIs
Standard NLP APIs use tiered per-unit pricing based on monthly volume. Covered APIs include entity recognition, sentiment analysis, key phrase extraction, language detection, syntax analysis, and targeted sentiment.
Here’s how standard NLP pricing (per unit) looks like. All pricing reflects the US East (N. Virginia) region:
|
Monthly volume |
Price per unit |
|
First 10M units |
$0.0001 |
|
10M–50M units |
$0.00005 |
|
Over 50M units |
$0.000025 |
Event detection is priced differently — each request is multiplied by the number of event types you extract per request. More event types = more units billed.
Here is the event detection pricing (per unit):
|
Monthly volume |
Price per unit |
|
First 10M units |
$0.003 |
|
10M–50M units |
$0.0015 |
|
Over 50M units |
$0.00075 |
Amazon Comprehend pricing: PII Detection and Redaction
Comprehend offers two PII APIs, and choosing the right one for your use case is one of the easier ways to keep costs in check.
- Contains PII — tells you whether a document contains PII (screening only, no location or redaction)
- Detect PII — identifies the exact location of PII entities and can produce a redacted version
Contains PII pricing (per unit)
|
Monthly volume |
Price per unit |
|
0–10M units |
$0.000002 |
|
10M–50M units |
$0.000001 |
|
50M+ units |
$0.0000005 |
Detect PII pricing (per unit)
|
Monthly volume |
Price per unit |
|
0–10M units |
$0.0001 |
|
10M–50M units |
$0.00005 |
|
50M+ units |
$0.000025 |
Note: The Contains PII API costs orders of magnitude less because it only screens. If you’re running a high-volume pipeline to decide which documents need closer review, using Contains PII for triage before calling Detect PII is a direct cost reduction with no tradeoff in accuracy.
Amazon Comprehend pricing: custom models
Custom Comprehend lets you train classification and entity recognition models on your own labeled data. This is where pricing gets more layered and where costs are most likely to catch teams off guard.
Three separate charges apply.
- Model training $3.00 per hour, billed by the second. A training job that takes 90 minutes costs $4.50.
- Asynchronous inference (batch) Billed by characters processed, same structure as standard NLP:
|
Monthly volume |
Price per unit |
|
0–10M units |
$0.0005 |
|
10M–50M units |
$0.00025 |
|
50M+ units |
$0.000125 |
- Synchronous inference — real-time endpoints. This is the most consequential pricing detail for custom Comprehend. Real-time endpoints bill by inference unit (IU) per second, minimum 60 seconds, from the moment the endpoint starts until it is deleted, regardless of whether it’s processing any text.
- $0.0005 per IU per second
- One IU delivers 100 characters/second of throughput. Additional IUs cost the same rate and stack linearly.
Note: A single Amazon Comprehend endpoint running 24/7 costs more than $1,200 per month — idle or not.
A 1-IU endpoint running around the clock for a month costs over $1,200. If that endpoint is idle overnight and on weekends, a large portion of that spend produces nothing. This is the most common source of runaway Comprehend spend.
Custom model management $0.50 per model per month — a flat fee to store a trained model, whether or not it’s actively in use.
Amazon Comprehend pricing: Topic Modeling
Topic modeling is billed on total document size per job, not by character unit.

Amazon Comprehend pricing: Trust and Safety APIs
Toxicity detection and prompt safety classification follow the same tiered structure as standard NLP:
|
Monthly volume |
Price per unit |
|
0–10M units |
$0.0001 |
|
10M–50M units |
$0.00005 |
|
50M+ units |
$0.000025 |
These APIs are increasingly relevant for organizations building generative AI products. Prompt safety classification, in particular, is used to catch unsafe inputs before they hit a model — a lightweight and relatively inexpensive guardrail for AI cost optimization pipelines.
Amazon Comprehend Free Tier
Comprehend includes a free tier for the first 12 months from your first API call, available to both new and existing AWS customers.
Free tier at a glance:
|
Offering |
Free amount |
|
Standard NLP APIs |
50K units (5M characters) per API, per month |
|
Topic modeling |
5 jobs up to 1 MB each, per month |
Eligible APIs: Key Phrase Extraction, Sentiment, Targeted Sentiment, Entity Recognition, Language Detection, Event Detection, Syntax Analysis, Detect PII, Contains PII, and Prompt Safety Classification.
Importantly: Custom Comprehend has no free tier. Model training, inference, and model management are billed from the first request.
Amazon Comprehend Medical pricing
Amazon Comprehend Medical is a separate service built for extracting information from clinical text, medical named entity recognition (NERe), protected health information (PHI) detection, and ontology linking (ICD-10-CM, RxNorm, SNOMED CT).
It uses a 100-character minimum per request rather than the 300-character minimum in standard Comprehend, and rates are higher given the specialized model requirements. See the Comprehend Medical pricing page for complete rates.
How to Control Amazon Comprehend Costs
Most Amazon Comprehend cost overruns are preventable. Here are six practical strategies to control cost:
- Use asynchronous batch processing where latency allows. Real-time endpoints bill by the second whether or not they’re processing text. Asynchronous batch jobs bill only for characters processed, eliminating idle-time charges entirely for non-time-sensitive workloads.
- Delete endpoints when not in use, not pause, delete. Custom model endpoints accrue charges from start to deletion, regardless of traffic. For dev, test, or low-frequency workloads, automate endpoint shutdown when inactive. This is the single highest-impact action for teams running custom Comprehend models on AWS.
- Use Contains PII as a triage layer before Detect PII. At $0.000002/unit, Contains PII costs 50× less than Detect PII ($0.0001/unit). Screen your full document volume first, then call Detect PII only on flagged records. At scale, the cost difference is material.
- Batch short texts into fewer, larger requests. Every Comprehend API request carries a 300-character (3-unit) minimum charge. Sending large volumes of short strings individually multiplies that minimum across every call. Grouping them reduces per-request overhead and directly lowers your AWS bill.
- Extract only the event types your pipeline needs. Event detection billing multiplies your unit count by the number of event types extracted per request. Extracting three event types costs three times more than extracting one for the same document set, so trim to what you actually use.
- Get cost visibility at the API and workload level, not just the service level. Native AWS cost tools report Amazon Comprehend as a single line item. If you’re running PII screening, custom classification, and sentiment analysis in parallel, that aggregation tells you nothing about which workload, team, or feature is driving spend or whether it’s justified. CloudZero can help with this.
Your Comprehend Bill Is Only Half the Picture — CloudZero Shows the Rest
Knowing what Comprehend charges per unit is table stakes. Knowing why it cost what it did — and whether it was worth it — is where most teams fall short.
The FinOps Foundation’s State of FinOps 2026 report found that 98% of practitioners now actively manage AI spend (up from 63% in 2025 and 31% in 2024), yet visibility into AI-related usage remains one of the discipline’s top unsolved challenges.
CloudZero’s State of AI Costs report puts a number on the gap: 54% of companies report AI budget variance of 11–25%, and one in five are missing budgets by 50% or more. That’s not a forecasting problem. It’s a visibility problem.
The right question isn’t “how much did Comprehend cost this month.” It’s “what is my cost per sentiment analysis, per compliance check, per processed document — and is that number improving?”
CloudZero makes that question answerable, by allocating Comprehend spend to the specific teams, features, and workloads driving it, continuously and without manual tagging.
 to see how CloudZero handles AI and ML cost allocation.
to see how CloudZero handles AI and ML cost allocation.
Amazon Comprehend FAQs











