
As a Kubernetes environment becomes more complex, it can become harder to manage. You can reduce that overwhelm by organizing your resources in a way that makes them easier to group, filter, and track.
You can do this by tagging your Kubernetes components. Kubernetes labels and annotations are two ways to accomplish this. Both are forms of Kubernetes metadata. Not sure what that is and how annotations and labels differ?
Here’s a straightforward guide to understanding Kubernetes (K8s) labels and annotations, including:
Table Of Contents
What Are Kubernetes Annotations?
Kubernetes annotations are a type of metadata that you attach to your Kubernetes objects, such as ReplicaSets and Pods. In particular, annotations are key-value maps.
Annotations let you organize your application into sets of attributes that correspond to how you think about that application. You can organize, label, and cross-index each Kubernetes resource to reflect the groups that make sense for your use case.
Annotations attach extra metadata to an object, but you cannot use that data to select an object. That’s because this metadata is non-identifying, meaning it is not necessarily meant to identify an object in Kubernetes. Yet, clients, including libraries and tools, can make use of this data.
Depending on the annotation, metadata can be large or small, structured or unstructured, and can contain diverse characters — in fact, more than are permitted by Kubernetes labels (more on this in the next section).
Now, picture this:
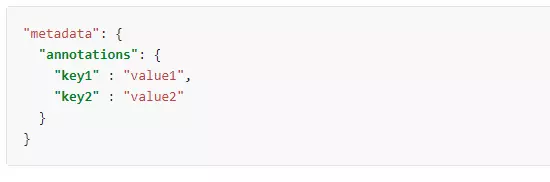
Credit: Strings in Kubernetes keys and values
Kubernetes annotations must meet the following characteristics and syntax requirements:
- An annotation comprises a key and a value. The key is a unique identifier for the annotation, and the value is the information the annotation is associated with. Annotations store additional or contextual information about the data being stored, such as descriptions.
- Even Kubernetes annotations require that your keys and values be strings. This means the keys or values cannot be numeric, boolean, list, or other types.
- Valid annotation keys have two segments: an optional prefix and name, separated by a slash (/).
- You must include the name segment, which should be 63 characters or fewer, starting and ending with an alphanumeric character ([a-z0-9A-Z]) with dashes (-), underscores (_), dots (.), and alphanumerics between.
- A prefix is optional. But if you specify it, it must be a DNS subdomain. That is, it should be a series of DNS labels separated by dots (.), with no more than 253 characters in total, followed by a slash (/). If you omit the prefix, the annotation Key is presumed private to the user.
- Automated system components, such as kubectl, kube-scheduler, kube-apiserver, kube-controller-manager, or other third-party automation, that add annotations to end-user objects must specify a prefix.
- The prefixes kubernetes.io/ and k8s.io/ are reserved for Kubernetes core components.
Want to see an example Kubernetes annotation? Here’s a manifest for a Pod that has the annotation imageregistry: https://hub.docker.com/
The following are some examples of details you can record in annotations:
- Fields that a declarative configuration layer manages. By attaching the fields as annotations, you get to differentiate them from default values that clients or servers set. This also distinguishes them from auto-generated fields and fields that auto-sizing or auto-scaling tools set.
- More information about builds, releases, images, teams, updates, etc. This includes details such as timestamps, image hashes, owner team, git branch, release IDs, registry address, and PR numbers.
- Pointers to monitoring, logging, analytics, or audit repositories.
- Data that’s usable for debugging purposes, such as the name, version, and build information of a tool.
- Provenance information about a user, tool, or system, including URLs of related objects coming from other components in the same ecosystem.
- Config, checkpoints, or other lightweight information from a rollout tool.
- Contact details of the project team, such as phone or pager numbers. Or, directory entries that point to where to find that information, like a particular website.
- End-user or customer directives and instructions to alter behavior or extend capabilities.
Now, here’s the thing. An external database or directory could store this type of information instead of in an annotation. But then again, that would make it harder to build shared client libraries and other tools, such as for deployments and management.

What Are Kubernetes Labels?
Labels in Kubernetes are key-value pairs containing metadata and are used to identify objects. An object can have its own key-value labels. In addition, you can attach labels to a K8s object when creating it. You can then add or modify the label as needed over time.
You can use labels in a variety of ways, including:
- Identify objects by properties users can understand (Kubernetes itself does not use labels).
- Group objects into subsets by defining and organizing them.
- Identify objects within a cluster.
- More easily modify configurations in bulk.
- Track, allocate, and manage Kubernetes costs.
Kubernetes labels must meet the following characteristics and syntax requirements:
- A key must be unique for a specific object.
- The segment must have up to 63 characters, while the prefix can have up to 253 characters.
- Unless its length is 0, it must have alphanumeric characters [a-z0-9A-Z] at the start and at the end.
- Characters like dot (.), dashes (-), and underscore (_) are allowed (internally).
- The prefix should be a sequence of DNS labels that are separated by a dot and preceded by a slash.
Using the prefix enables you and automatic system components, such as kube-scheduler, as well as third-party tools, to manage resources.
What Are The Differences Between Labels And Annotations In Kubernetes?
The biggest difference between annotations and labels in Kubernetes is this: while labels attach identifying metadata to a K8s object, annotations attach additional information that is not identifying.
As you’ve probably already noticed in the definition sections previously, there are several other differences, including the number of characters an annotation can have vs. a label and use cases.
But just to recap, here’s a quick side-by-side comparison of Kubernetes labels vs. annotations:
Kubernetes Labels | Kubernetes Annotations | |
Primary use case | Attach identifying metadata to objects. Help select, group, or filter Kubernetes objects | Hold non-identifying metadata that third-party tools and clients can retrieve |
Metadata type | Short and unstructured | Short, long, structured, and unstructured |
Used in operating? | Yes | No |
Character set and syntax | Both the name (up to 63 characters long) and prefix (up to 253 characters long) are required | Name is required and must be 63 characters or less. Prefix is optional |
What Are Some Best Practices For Using Kubernetes Labels And Annotations?
By labeling or annotating your Kubernetes resources, you can keep track of specific components in your rapidly expanding K8s environment.
If you want to select, group, or filter specific K8s objects, you can use labels. You can also use annotations to provide more information about a particular object.
However, this is not always the case, particularly if you miss a couple of crucial best practices for tagging.
Below is a quick list of Kubernetes annotations and labels best practices to always keep in mind when tagging your K8s components.
- You can refine your visibility into your Kubernetes objects by attaching labels and annotations to more of your Kubernetes components.
- Maintain a consistent labeling convention to avoid mixups, duplications, and a lot of rework.
- Keeping your labels and annotations short will prevent complexity, particularly for labels, which K8s uses internally for operations.
- Simplify tagging by using Kubernetes-recommended labels and annotations as early as possible. This includes details about the object’s name, owner, environment, and version.
- Build consensus by following the correct character set and syntax for each type.
- Do not add confidential metadata to annotations or labels.
- As a backup, use labels and annotations with other Kubernetes tagging methods.
- Organize resources in a way that makes sense for object queries. This way, your team can more easily detect and troubleshoot issues in bulk.
Track, Understand, And Control Your Kubernetes Costs With a Robust Platform
Tags and tag management can be endless, complicated, and tedious. Yet, if your cost allocation tags aren’t perfect, it’s hard to figure out who, what, and why your Kubernetes costs are changing. Well, not if you’ve got CloudZero.

If your labels and annotations aren’t perfect, we get it. So we built CloudZero from scratch to deliver accurate and actionable Kubernetes cost intelligence. With CloudZero, you can collect cost data from tagged, untagged, and untaggable Kubernetes resources hassle-free.

Besides breaking down your Kubernetes costs by individual customer, team, product, feature, and more granularity, CloudZero also delivers your cost insights by various K8s concepts, such as per pod, cluster, namespace, environment, service, etc, — down to the hour.
And did we mention that tags are not required?
Reading about CloudZero features is nothing like seeing it in action for yourself.  to start organizing your Kubernetes costs without perfect tags.
to start organizing your Kubernetes costs without perfect tags.


The Cloud Cost Playbook
The step-by-step guide to cost maturity



