
Quick Answer
This OpenAI API cost calculator (also an AI inference calculator for o3/o4-mini thinking tokens) estimates your monthly OpenAI API pricing bill from three inputs: model, request volume, and average tokens per request. Toggle between standard, batch, and cached pricing and get your number in seconds. It also shows what the same workload costs on Claude and Gemini. For the full per-model rate card, see CloudZero's OpenAI API pricing guide. For ChatGPT subscription plans, see CloudZero's ChatGPT pricing guide.
Why is your OpenAI cost estimate usually wrong?
Every finance team that has ever budgeted for OpenAI API cost has experienced the same arc: estimate, prototype, ship, invoice, silence, and then a calendar invite nobody scheduled titled “AI Spend Review.”
Across $15 billion in cloud and AI spend under management, CloudZero consistently sees production OpenAI API pricing bills landing 1.5 to 2x above initial estimates. Not because the math is wrong. Because the inputs are wrong.
Three things change between the estimate and the invoice.
- Your prompts grow. The system prompt that started at 200 tokens is 2,000 tokens by month three. Someone added few-shot examples. Someone added “consider the user’s last 10 messages.” Someone added a JSON schema for structured output. Each addition feels small. The cumulative effect is a 5 to 10x increase in input tokens per request, and a 5 to 10x increase in your bill.
- Reasoning tokens appear. If you selected o3 or o4-mini in the calculator above, you saw the thinking token multiplier. In production, those invisible thinking tokens account for 70 to 85% of the output bill on reasoning models. The calculator models this. Most spreadsheet estimates do not.
- Retries and errors compound. A failed API call retries automatically. Each retry re-sends the full input. A 5% error rate with 3 retries per failure adds 15% to your input token volume. At scale, that turns a $5,000 bill into $5,750 before you’ve changed a single line of code.
The calculator accounts for the first two. The third is why the CloudZero section at the bottom exists.
“Only 34% of organizations can attribute AI spend to specific features. The other 66% are flying blind on the single fastest-growing line item in their budget.” CloudZero, AI Era: A Critical Recalibration, 2026
Report
Finance needs to prove AI’s return: CloudZero report
260 senior finance leaders (more than half CFOs) told us why the speed of seeing AI spend, not the size of it, separates who pulls ahead on AI from who gets burned.
What does this calculator model, and what can’t it?
The OpenAI pricing calculator is a planning tool, not a billing oracle. Knowing where it stops is as useful as knowing how to use it.
What it models accurately: Per-token rates for all current OpenAI models. Standard, batch, and cached OpenAI API pricing modes. Thinking token overhead for o3 and o4-mini. Cross-provider comparison against Claude and Gemini at the same volume.
What it cannot model: Prompt growth over time. Your actual retry rate. Context window surcharges when prompts exceed the standard limit: GPT-5.4 charges 2x on input above 272K tokens. Fine-tuning inference rates (higher than base model). Audio and image input tokens, which follow separate pricing.
What this means for your finance planning: Use the calculator for your baseline month-one estimate. Apply a 1.5x to 2x buffer for anything shipping to production for six months or more. If you are forecasting annual AI spend for a board or CFO conversation, use Scenario 3 below as your template and apply the growth assumption explicitly.
5 real-world OpenAI API cost scenarios (use these to sanity-check your estimate)
The calculator gives you a custom estimate. These five scenarios give you a sanity check. If your number looks wildly different from a comparable scenario, something in your assumptions is off.
Scenario 1: SaaS customer support chatbot
This is the most common AI feature deployment. It is also the most common source of invoice shock.
| Parameter | Initial estimate | Production at month 6 |
| Daily queries | 10,000 | 10,000 |
| Average input tokens/query | 300 (user message only) | 1,800 (system prompt grew to 1,500 tokens) |
| Average output tokens/query | 300 | 300 |
| Model | GPT-5.4 Mini ($0.75/$4.50) | GPT-5.4 Mini ($0.75/$4.50) |
| Monthly AI spend | $473 | $810 |
The bill nearly doubled, a 1.7x jump, entirely from prompt growth. No model change, no usage spike. Just a system prompt that quietly tripled as the team added examples, guardrails, and context. This plays out in roughly 60% of SaaS AI features in the first six months.
Model routing opportunity: If 70% of queries are simple FAQ lookups, routing those to GPT-4.1 Nano ($0.10/$0.40) and reserving Mini for complex issues drops the month-6 bill from $810 to roughly $306 — about 38% of the un-routed cost, with no change to the user experience for most queries.
Math: 300,000 queries/month. Initial estimate at 300 input / 300 output: input 90 MTok × $0.75 = $67.50; output 90 MTok × $4.50 = $405. Total: $473. Month 6 at 1,800 input / 300 output: input 540 MTok × $0.75 = $405; output unchanged at $405. Total: $810. Batch pricing available at 50% off: $405/month.
Scenario 2: AI coding assistant (Codex CLI)
| Parameter | Value |
| Developers | 12 |
| Sessions/dev/day | 5 |
| Average input tokens/session | 150,000 (codebase context across multiple agent turns) |
| Average output tokens/session | 55,000 (code generation across turns) |
| Model | GPT-5.3 Codex ($1.75/$14.00) |
| Monthly estimate | $1,859 |
| Per developer | $155/month |
| Same workload on Claude Code (Sonnet 4.6, $3/$15) | $2,295 |
| Same workload on Gemini CLI (3.5 Flash, $1.50/$9) | $1,296 |
| Same workload on Gemini CLI (free tier) | $0 (within 1,000 req/day limit) |
Math: 1,800 sessions/month.
Input: 270 MTok × $1.75 = $472.50.
Output: 99 MTok × $14 = $1,386.
Total: $1,858.50.
The cross-provider gap is a real finance decision. $155/dev/month on Codex vs. $0 on Gemini’s free tier looks obvious until you factor in whether your team ships the same quality output. Engineering time is more expensive than the token bill. Usually.
Scenario 3: Multi-model SaaS inference budget (annual planning)
Finance teams planning AI spend for a full year face a compounding problem: models change, volumes grow, and “we’ll monitor it” is not a budget line.
| Model tier | Use case | Month 1 spend | Month 12 spend (20% MoM growth) | Annual total |
| GPT-4.1 Nano ($0.10/$0.40) | Classification, routing | $90 | $559 | $3,760 |
| GPT-5.4 Mini ($0.75/$4.50) | Chat, summarization | $225 | $1,398 | $9,408 |
| GPT-5.4 ($2.50/$15.00) | Complex reasoning | $240 | $1,490 | $10,022 |
| o3 ($2.00/$8.00) | Analytics, deep research | $120 | $745 | $5,010 |
| Total | $675/month | $4,192/month | $28,200 |
At 20% monthly token volume growth (typical for year-one AI features), your annual OpenAI API cost is $28,200, not the $8,100 a straight-line estimate suggests. This is the slide your CFO needs in Q1, not Q4.
The calculator generates this breakdown for your actual workload. Run it before your next budget cycle, then run it again with a 15 to 20% growth assumption to show the range.
Scenario 4: Reasoning-heavy analytics (o3)
| Parameter | Value |
| Daily requests | 1,000 |
| Average input tokens/request | 2,000 |
| Average visible output tokens/request | 500 |
| Average thinking tokens/request | 2,000 (billed as output at full output rate) |
| Model | o3 ($2.00/$8.00) |
| Monthly estimate without thinking tokens | $240 |
| Monthly estimate with thinking tokens | $720 |
| Same workload on o4-mini ($1.10/$4.40) | $396 |
Math: 30K requests/month. Input: 60 MTok × $2 = $120. Output without thinking: 15 MTok × $8 = $120. Total without: $240. Output with thinking: 75 MTok × $8 = $600. Total with: $720.
The 3x gap between the estimate without thinking tokens and with them is the single most common o3 invoice surprise. The OpenAI API pricing for thinking tokens is identical to regular output: $8/MTok for o3, $4.40/MTok for o4-mini. o4-mini saves 45% and is accurate enough for most reasoning tasks. Worth testing before defaulting to o3.
Scenario 5: High-volume classification at scale
| Parameter | Value |
| Daily classifications | 250,000 |
| Average input tokens/request | 200 |
| Average output tokens/request | 10 |
| Model | GPT-4.1 Nano ($0.10/$0.40) |
| Processing mode | Batch (-50%) |
| Monthly estimate | $90 |
| Same volume on GPT-5.4 standard | $4,875 |
$90 vs. $4,875 for the same task. The 54x difference is entirely model selection. GPT-4.1 Nano handles binary classification, sentiment tagging, and content routing at 95%+ accuracy for tasks that do not need frontier reasoning.
If your classification pipeline is running on GPT-5.4 because “that is what we started with,” fixing it is the easiest AI spend optimization available.
How do you estimate your OpenAI API cost accurately?
The OpenAI API pricing calculator multiplies three numbers. Getting those numbers right is harder than it looks.
Step 1: Count your requests honestly. Not “how many queries does the app handle today” but “how many API calls does each query generate.” A chatbot with a 5-message conversation history sends 5x the input tokens of a single-turn query. An agent that retries on failure adds 5 to 15% to total calls. A RAG pipeline that retrieves, re-ranks, and generates makes 3 calls per user query.
Step 2: Measure your tokens, do not guess. OpenAI’s tokenizer tool counts exact tokens for any text. Run 100 real prompts through it. Average the result. Then add your system prompt length (constant per call) and your conversation history (grows per turn). Most teams underestimate by 30 to 50% because they forget the system prompt entirely.
Step 3: Pick the right processing mode. The calculator offers three toggles. Standard is the default. Batch saves 50% on any workload that can wait 24 hours. Cached inputs save up to 90% on repeated system prompts, which applies to almost every production application. If you did not toggle cached, go back and do it. Your estimate probably just dropped 30 to 40%.
Step 4: Add the thinking token multiplier for reasoning models. The calculator does this automatically for o3 and o4-mini. If you are building your own spreadsheet, multiply visible output tokens by 5 to 10x for reasoning models. That is the range CloudZero observes across production deployments.
Step 5: Model growth. Your month-one estimate is your floor, not your ceiling. A conservative growth model adds 15 to 20% monthly to token volume for the first 6 months of a new AI feature. Build that into your AI spend forecast before you present it to finance.
How big is the gap between your OpenAI estimate and your actual bill?
The OpenAI cost calculator gives an estimate. Production gives a bill. Here is what happens in between.
The average gap is 1.5 to 2x. A team that estimates $3,000/month typically lands at $4,500 to $6,000. The gap follows predictable patterns, which means it is preventable.
Pattern 1: Prompt bloat. Most organizations track total AI expenses. Only a few can attribute that spend to specific features. Without per-feature attribution, nobody notices when a feature’s prompt grows from 500 to 5,000 tokens. It looks fine in aggregate. Until the invoice lands.
Pattern 2: Model drift. A developer switches from GPT-4.1 to GPT-5.4 “just to test” and forgets to switch back. At 50,000 daily requests, that test costs an extra $2,000/month. Without per-model spend tracking, it is invisible until it isn’t.
Pattern 3: Shadow AI spend. Engineers use the API key for side projects, experiments, and one-off scripts. None of these appear in the original estimate. All of them appear on the invoice. Finance notices. Nobody else does, until finance asks.
The difference between AI spend that drives AI ROI and AI spend that drives awkward meetings is attribution. That is what CloudZero tracks.
How CloudZero’s OpenAI integration works
- Direct API ingestion. CloudZero connects to OpenAI’s API and pulls both spend and usage data in real time. Input tokens, output tokens, cached tokens, and reasoning tokens appear as separate line items. Not through cloud billing. Not through CSV exports.
- Multi-provider normalization. Most teams run OpenAI alongside Claude, Gemini, Amazon Bedrock, and Azure OpenAI. CloudZero is the first cloud management platform to integrate directly with both OpenAI and Anthropic, normalizing AI spend across all providers alongside AWS, Google Cloud, and other cloud service providers.
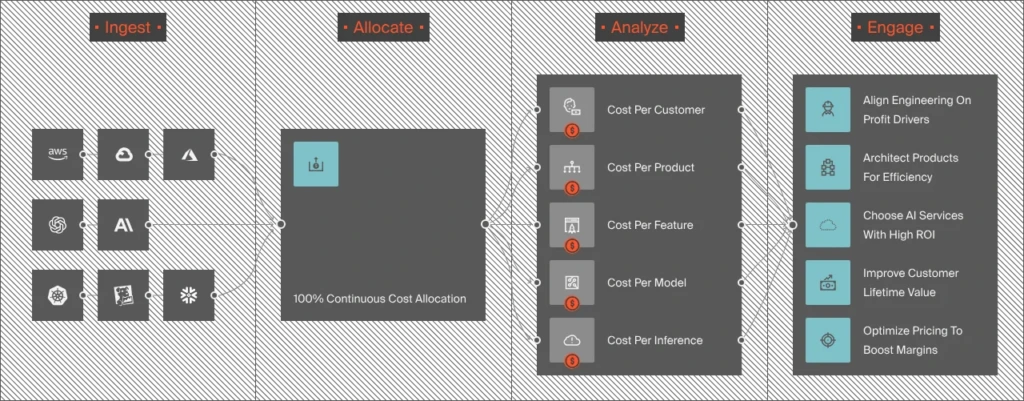
- Attribution without tags. OpenAI has no tagging system. CloudZero’s CostFormation allocates every token to a team, product, feature, and customer using metadata and context. “OpenAI charged $14,000 this month” becomes four lines: search feature $5,200, coding assistant $3,800, chatbot $2,100, unauthorized experimental branch $2,900.
- Anomaly detection at the model level. CloudZero’s anomaly detection catches reasoning token spikes, prompt regressions, and retry loops at the model, feature, and customer level. Alerts go to the team that owns the code in Slack, not to next month’s finance report.
- Forecasting from actual patterns. The calculator uses assumptions. CloudZero uses actual consumption data to project next month’s bill with prompt growth, model changes, and seasonal patterns already factored in.
Organizations like Toyota, Duolingo, Coinbase, Shutterstock, Klaviyo, and Upstart track AI spend through CloudZero at this granularity. Upstart saved $20 million. Drift saved $2.4 million annually. 90% of companies tracking AI spend in platforms like CloudZero report high confidence in calculating AI ROI. CloudZero holds a Visionary position in the Gartner Magic Quadrant for cloud cost intelligence.  and ask to see your AI spend the way your finance team needs to see it.
and ask to see your AI spend the way your finance team needs to see it.
Frequently asked questions about OpenAI API pricing











