
Quick Answer
LLM API pricing in 2026 ranges from $0.10 per million input tokens for budget models like GPT-4.1 Nano to $30 per million input tokens for frontier reasoning models like GPT-5.4 Pro. The best value for most production workloads is GPT-5.4 at $2.50/$15 per million tokens (input/output) or Claude Sonnet 4.6 at $3/$15. The cheapest LLM API overall is DeepSeek V3.2 at $0.14/$0.28. Actual costs depend on token volume, prompt architecture, caching strategy, and whether you're tracking spend per task or just per month, a distinction that determines whether your AI investment is strategic or accidental.
This guide covers production API pricing — not free-tier playground rates or enterprise contract pricing. It assumes you’re evaluating LLM APIs for workloads processing at least 100,000 tokens per day and that cost decisions are shared between engineering and finance. If you’re exploring free options for prototyping, skip to the FAQ.
What Is An LLM API And Why Does Pricing Matter?
An LLM API (large language model application programming interface) is a service endpoint that lets developers send text prompts to an AI model and receive generated responses over HTTP. LLM API pricing (what providers charge per token for these calls) varies by more than 600x across models, making it the single most consequential variable in AI infrastructure cost.
Instead of training or hosting models yourself, you call providers like OpenAI, Anthropic, or Google and pay per use. Every major AI product built in the last two years; coding assistants, document summarizers, customer support agents or search features runs on one or more LLM APIs behind the scenes.
What you pay for is measured in tokens, which is the basic unit of LLM token pricing. A token is roughly three-quarters of an English word. Providers charge separately for input tokens (your prompt, context, and system instructions) and output tokens (the model’s response). Output tokens cost 2x to 6x more because generation demands more compute than comprehension.
This is the core of LLM token pricing: a 1,000-word document consumes approximately 1,333 tokens, but that ratio shifts for code, structured data, and non-English text. If you’ve ever wondered why your API bill doesn’t match your back-of-the-envelope estimate, token math is usually why.
The stakes are real. According to CloudZero’s State of AI Costs report, average monthly AI spend jumped from $63,000 in 2024 to $85,500 in 2025, a 36% increase. The share of companies planning to spend over $100,000 per month on AI more than doubled in the same period. A small change in prompt design, model selection, or context length can swing a monthly bill by 10x. When you hear engineers say “how much does AI cost,” the honest answer is: it depends on about six variables, and most teams are only tracking one.
That’s what makes understanding AI pricing models across providers essential, not just to find the cheapest option, but to match cost to value. The pricing page is the most important document most engineering teams never read carefully. Right after the security policy and right before the on-call rotation schedule.
Report
Finance needs to prove AI’s return: CloudZero report
260 senior finance leaders (more than half CFOs) told us why the speed of seeing AI spend, not the size of it, separates who pulls ahead on AI from who gets burned.
How Much Does Every Major LLM API Cost?
Here’s the complete pricing for every production-grade model from the six major providers, normalized to cost per million tokens in USD. All prices reflect standard (non-batch, non-cached) API rates verified against each provider’s pricing page as of 2026.
These are the numbers to compare LLM costs accurately, not last year’s rates, which are as useful as last year’s weather forecast.
1. OpenAI API pricing
The OpenAI API pricing has expanded dramatically. The GPT-5.4 family, launched March 2026, resets the cost curve at every tier. GPT-5 pricing now spans from $0.20/MTok input (Nano) to $30/MTok input (Pro), a 150x range within a single provider.
For a complete model-by-model breakdown with real-world SaaS cost examples, see our OpenAI API cost guide.
|
Model |
Input/1M tokens |
Output/1M tokens |
Context |
Best for |
|
GPT-5.4 Pro |
$30.00 |
$180.00 |
200K |
Mission-critical reasoning, legal, research |
|
GPT-5.5 |
$5.00 |
$30.00 |
200K |
Latest flagship generation |
|
GPT-5.4 |
$2.50 |
$15.00 |
128K |
General-purpose production |
|
GPT-4.1 |
$2.00 |
$8.00 |
1M |
Long-context, mid-tier |
|
o1 |
$15.00 |
$60.00 |
200K |
Complex reasoning, math, code |
|
GPT-5.4 Mini |
$0.75 |
$4.50 |
128K |
Cost-efficient quality tasks |
|
GPT-4.1 Mini |
$0.40 |
$1.60 |
1M |
High-volume, long-context |
|
GPT-5.4 Nano |
$0.20 |
$1.25 |
128K |
Ultra-budget, lightweight |
|
GPT-4.1 Nano |
$0.10 |
$0.40 |
1M |
Cheapest proprietary model |
Note: Batch API offers 50% discount on all models. Prompt caching discount up to 90% on cached input.
That 150x spread means model selection alone can turn a $1,200/month workload into a $100/month workload, the kind of optimization that would earn an engineer a nice Slack thread of party emojis from finance. But defaulting to the newest model without measuring whether the quality difference justifies the cost is how teams end up in quarterly reviews they’d rather skip.
2. Anthropic (Claude) API pricing
Anthropic API pricing follows a clean three-tier structure. Claude Sonnet 4.6 is the workhorse for production, strong on coding, analysis, and instruction following, priced at $3/$15 per million tokens. The newest flagship, Claude Opus 4.7 (launched April 16, 2026), keeps the same $5/$25 rate as Opus 4.6 but ships with an updated tokenizer that can produce more tokens for the same input text, meaning effective cost per request can rise even though the rate card didn’t. CloudZero integrates directly with the Anthropic API to ensure Claude AI pricing is trackable alongside every other line item in your cloud bill.
|
Model |
Input/1M tokens |
Output/1M tokens |
Context |
Best for |
|
Claude Opus 4.7 |
$5.00 |
$25.00 |
1M |
Flagship coding, agentic workflows |
|
Claude Opus 4.6 |
$5.00 |
$25.00 |
200K |
Nuanced analysis, pinned deployments |
|
Claude Sonnet 4.6 |
$3.00 |
$15.00 |
200K (1M beta) |
Production coding, general-purpose |
|
Claude Haiku 4.5 |
$1.00 |
$5.00 |
200K |
High-speed, high-volume |
Note: Prompt caching saves up to 90% on cached input tokens. Batch API offers 50% discount.
A detail worth noting for teams evaluating Claude Code pricing alongside API costs: developer usage of Claude Code adds a different cost dimension because sessions are less predictable than structured API calls. Engineers testing new prompts and stretching context windows generate spend patterns that don’t map neatly onto per-token forecasting. It’s one reason CloudZero tracks Claude costs by workspace and API key, not just by model.
Anthropic’s caching discount, 90% off repeated input prefixes, is the most aggressive in the market. For applications with static system prompts (most RAG apps, most multi-turn agents), this is often the single largest cost lever available.
3. Google (Gemini) API pricing
Google Gemini API pricing undercuts most competitors on sticker price and context window size. Gemini 2.5 Flash at $0.15/$0.60 is the cheapest high-quality option from a major U.S. provider. The free tier (15 requests per minute for Flash) is generous enough for prototyping; generous enough, in fact, that some startups have shipped MVPs without spending a dollar on inference. For per-call breakdowns, see our Gemini cost per API call analysis.
|
Model |
Input/1M tokens |
Output/1M tokens |
Context |
Best for |
|
Gemini 3.1 Pro (≤200K) |
$2.00 |
$12.00 |
1M |
Frontier multimodal, agentic |
|
Gemini 3.1 Pro (>200K) |
$4.00 |
$18.00 |
1M |
Long-context analysis |
|
Gemini 3 Flash |
$0.50 |
$3.00 |
1M |
Mid-tier production, search grounding |
|
Gemini 3.1 Flash-Lite |
$0.25 |
$1.50 |
1M |
Budget with quality |
|
Gemini 2.5 Pro (≤200K) |
$1.25 |
$10.00 |
1M |
Previous-gen analysis |
|
Gemini 2.5 Flash |
$0.30 |
$2.50 |
1M |
Previous-gen fast inference |
Note: Gemini pricing includes tiered rates on some models based on prompt length.
4. DeepSeek, Mistral, and other providers
The landscape beyond the big three is where the most aggressive pricing lives. DeepSeek AI API pricing starts at $0.14/$0.28 per million tokens for V3.2, and Mistral AI API pricing offers a GDPR-compliant budget option at $0.10/$0.30 for Mistral Small 3.2.
|
Provider |
Model |
Input/1M tokens |
Output/1M tokens |
Context |
Note |
|
DeepSeek |
deepseek-chat |
$0.27 |
$1.10 |
64K |
Default model; cache hits just $0.07 input |
|
DeepSeek |
deepseek-reasoner |
$0.55 |
$2.19 |
64K |
Chain-of-thought reasoning |
|
Mistral |
Large 3 |
$0.50 |
$1.50 |
256K |
EU data residency, cheapest frontier-class output |
|
Mistral |
Small 3.2 |
$0.10 |
$0.30 |
32K |
GDPR-compliant budget option |
|
Cohere |
Command R+ (08-2024) |
$2.50 |
$10.00 |
128K |
Built for RAG with native citation |
|
Meta |
Llama 4 (via hosts) |
$0.10–$3.00 |
$0.10–$3.00 |
128K+ |
Varies by inference provider |
Note: Llama 4 pricing varies by host; Groq, Together AI, and Fireworks AI all charge differently for the exact same model.
That Llama 4 pricing range; $0.10 to $3.00 for identical weights, captures something important about AI model cost: the model isn’t the only variable. The infrastructure underneath matters just as much. It’s the cloud cost equivalent of the same coffee being $2 at a diner and $7 at the airport. This is why tracking spend by provider and model, not just total API bill, matters for AI cost management.
For teams exploring zero-cost options: several providers offer a free LLM API tier. DeepSeek R1, Llama 3.3 70B, and Gemma 3 are available at no cost through OpenRouter with rate limits. Google’s Gemini Flash free tier handles prototyping well. These tiers are genuinely useful for development — just don’t build your production budget assumptions around them.
How Do LLM API Costs Compare Side By Side?
For engineers evaluating providers or finance teams modeling budgets, here’s the full AI API pricing comparison sorted by output cost per million tokens. This is the table you bookmark, and the one that answers the “which one is cheaper” question your PM will inevitably ask in standup.
|
Provider |
Model |
Input/1M |
Output/1M |
Context |
|
Mistral |
Small 3.2 |
$0.10 |
$0.30 |
32K |
|
OpenAI |
GPT-4.1 Nano |
$0.10 |
$0.40 |
1M |
|
OpenAI |
GPT-5.4 Nano |
$0.20 |
$1.25 |
128K |
|
DeepSeek |
deepseek-chat |
$0.27 |
$1.10 |
64K |
|
|
Gemini 3.1 Flash-Lite |
$0.25 |
$1.50 |
1M |
|
|
Gemini 2.5 Flash |
$0.30 |
$2.50 |
1M |
|
Mistral |
Large 3 |
$0.50 |
$1.50 |
256K |
|
OpenAI |
GPT-4.1 Mini |
$0.40 |
$1.60 |
1M |
|
DeepSeek |
deepseek-reasoner |
$0.55 |
$2.19 |
64K |
|
|
Gemini 3 Flash |
$0.50 |
$3.00 |
1M |
|
OpenAI |
GPT-5.4 Mini |
$0.75 |
$4.50 |
128K |
|
Anthropic |
Haiku 4.5 |
$1.00 |
$5.00 |
200K |
|
OpenAI |
GPT-4.1 |
$2.00 |
$8.00 |
1M |
|
Cohere |
Command R+ |
$2.50 |
$10.00 |
128K |
|
|
Gemini 2.5 Pro (≤200K) |
$1.25 |
$10.00 |
1M |
|
|
Gemini 3.1 Pro (≤200K) |
$2.00 |
$12.00 |
1M |
|
OpenAI |
GPT-5.4 |
$2.50 |
$15.00 |
128K |
|
Anthropic |
Sonnet 4.6 |
$3.00 |
$15.00 |
200K |
|
Anthropic |
Opus 4.6 |
$5.00 |
$25.00 |
200K |
|
Anthropic |
Opus 4.7 |
$5.00 |
$25.00 |
1M |
|
OpenAI |
GPT-5.5 |
$5.00 |
$30.00 |
200K |
|
OpenAI |
o3 |
$15.00 |
$60.00 |
200K |
|
OpenAI |
GPT-5.4 Pro |
$30.00 |
$180.00 |
200K |
The price per token is just the start. CloudZero shows you cost per customer, per feature, per model — so you know if the spend was worth it.  .
.
Output pricing varies by more than 640x across this table, from $0.28 (DeepSeek V3.2) to $180 (GPT-5.4 Pro). That range is exactly why an AI model pricing comparison based purely on sticker price leads teams astray. The cheapest model per token isn’t the cheapest model per task; that’s a distinction the table above can’t capture but your production metrics can.
Which LLM API Is Cheapest For Production Use?
Three workload categories, three different answers. Getting this right is the highest-leverage cost decision most teams make once and revisit never, which is a shame, because the landscape shifts quarterly.
- High-volume, latency-tolerant tasks (classification, extraction, routing). GPT-4.1 Nano and Mistral Small 3.2 are the cheapest proprietary options. DeepSeek V3.2 offers better reasoning at nearly the same price. For a SaaS chatbot routing 10,000 queries per day, switching from GPT-5.4 to GPT-4.1 Nano can cut monthly GPT API pricing costs by over 90%. That’s the kind of savings that upgrades your team’s coffee from the office Keurig to actual beans.
- Balanced cost and quality (chatbots, content generation, code assistance). GPT-5.4 Mini and Claude Haiku 4.5 compete closely. Mini wins on raw input price; Haiku tends to need fewer retries on nuanced tasks, which can offset the per-token premium. Measuring cost per completed task, not cost per token, is what separates teams that optimize from teams that just economize.
- Complex reasoning and agentic workflows (multi-step code generation, research synthesis, legal analysis). DeepSeek R1 ($0.55/$2.19) delivers reasoning at roughly 1/27th the output cost of o3 ($2.19 vs. $60 per million output tokens). For most production reasoning, Claude Sonnet 4.6 ($3/$15) or GPT-5.4 ($2.50/$15) hit the right balance of AI inference pricing and output quality. Reserve the premium tier for problems where errors cascade and the cost of correction exceeds the model premium.
But sticker price only gets you partway to a real answer. The costs that actually blow budgets live below the pricing page. They live in the architectural decisions teams make without realizing they’re also making financial ones.
What Hidden Costs Affect Your Actual LLM API Spend?
Five cost drivers consistently surprise teams that budget based on per-token rates alone. Understanding them is the difference between an AI inference cost you planned for and one that triggers an emergency Slack thread.
Token overhead from prompts and context
Every API call ships system instructions, conversation history, RAG documents, and function definitions alongside the user’s actual question. For a typical retrieval-augmented generation app, the full input payload might look like this:
|
Payload component |
Typical token count |
% of total input |
|
System prompt |
1,500–3,000 |
35–50% |
|
RAG context documents |
1,500–4,000 |
30–45% |
|
Conversation history |
500–2,000 |
10–20% |
|
User query |
30–100 |
1–3% |
For a typical retrieval-augmented app, the user query might be 50 tokens while the full input payload tops 4,000. That 80x overhead means your per-request cost is dominated by context you wrote once and send on every call — a cost structure that makes prompt caching not just a nice optimization but a financial imperative.
Rate limits that don’t scale with your ambitions
Free and standard tiers have rate limits that feel fine during development, a polite way of saying they were never tested at production traffic. OpenAI gates throughput by cumulative spend ($50, $100, $500, $1,000+ thresholds). Anthropic gates by plan tier. Google requires billing setup for production limits. The cost of hitting rate limits is either queuing delay your users feel or over-provisioning your finance team feels.
Cloud provider markups
Running LLM APIs through AWS Bedrock, Azure OpenAI, or Google Vertex AI adds convenience — VPC peering, unified billing, compliance controls — at a premium. As a benchmark, the same Claude Sonnet 4.6 call that costs $3/$15 per million tokens via Anthropic’s direct API can cost 10–20% more when routed through a cloud marketplace, depending on the provider and commitment tier.
The markup varies by model and provider but compounds meaningfully at millions of tokens monthly, the cloud cost equivalent of resort minibar pricing. The convenience is real; so is the bill. For teams processing at scale, comparing direct API rates against cloud provider rates is worth the 30 minutes it takes.
Teams managing multi-provider LLM stacks increasingly use cost observability platforms such as CloudZero for full-stack cost attribution, Helicone for per-call logging, or provider-native dashboards to reconcile what they’re billed across direct API, marketplace, and self-hosted endpoints.
Reasoning model token traps
Reasoning models (o3, DeepSeek R1, Claude Opus on agentic tasks) generate internal “thinking” tokens billed at the output rate. A single o3 call can burn 50,000 output tokens of chain-of-thought before producing a one-paragraph answer. We’ve all had colleagues like that. At $60 per million output tokens, that’s $3 per complex call; negligible in testing, devastating at 10,000 calls per day.
The visibility gap itself
Here’s the hidden cost nobody puts on a pricing page: not knowing where your money goes. CloudZero’s research with Benchmarkit found that only 43% of organizations track AI spend by customer and just 22% track it by transaction. The other 78% are making LLM cost optimization decisions; model selection, caching strategy or routing rules, without data on whether those decisions are working. That’s not a pricing problem. That’s a visibility problem, and it’s the most expensive one on this list.
How Should You Compare LLM API Costs Accurately?
Most AI model pricing comparisons answer the wrong question. They tell you what a million tokens costs. They don’t tell you what a completed task costs. Here’s a five-step framework that does.
- Define your unit of work. A customer support resolution. A code review. A document summary. Whatever your application does, name one unit. This becomes your cost denominator, the thing that transforms LLM pricing from an abstraction into business economics.
- Measure tokens per unit across models. The same task consumes different token counts on different models. Tokenizers differ. Response verbosity varies. GPT-5.4 tends to produce slightly more verbose output than Claude Sonnet 4.6 for equivalent tasks, more output tokens billed at the same per-token rate.
- Factor in retry rates. A cheaper model that requires human review on 15% of outputs costs more per completed task than an expensive model with a 3% review rate. Quality determines total cost, not just token price.
- Model the full request payload. Include system prompts (often 2,000–4,000 tokens), conversation history, RAG context, and function definitions. For most production applications, input tokens outnumber the user’s actual query by 10–50x.
- Track cost per business outcome. Your cost per customer interaction, per transaction, or per inference call is what the business cares about. Not cost per token. The organizations that answer “was it worth it?” with data, rather than with a shrug and a hope, are the ones whose AI investments survive budget season.
How Can You Reduce LLM API Costs?
Knowing the pricing is step one. Reducing what you pay is where the leverage lives. These are the strategies that actually move production invoices, ordered by typical impact.
1. Route by task complexity (typical savings: 70–90% on qualifying requests)
Not every request needs a flagship model. Build a routing layer that sends simple tasks to budget models and reserves expensive models for complex work.
CloudZero’s analysis of SaaS chatbot costs shows that matching FAQ-style requests to Nano-class models instead of flagship models can reduce per-request costs by an order of magnitude. Model routing is the highest-leverage optimization available because it compounds across every request.
Tools like OpenRouter, Martian, and Unify automate model routing across providers, selecting the cheapest model that meets a quality threshold for each request. On the observability side, platforms like Helicone, LangSmith, and Braintrust let teams monitor cost per call in real time — essential for validating that routing rules actually reduce spend rather than just shifting it.
2. Maximize prompt caching (typical savings: 50–90% on input tokens)
Structure system prompts as static prefixes that trigger cache hits. Anthropic’s 90% cache discount means a 4,000-token system prompt costs 400 tokens on repeat calls. OpenAI’s automatic caching offers up to 90% on matching prefixes. For high-volume applications such as customer support, document processing or code review, caching often delivers the single largest per-call savings.
3. Batch everything that isn’t real-time (typical savings: 50% flat)
OpenAI and Anthropic both offer 50% batch API discounts. Nightly document processing, weekly reports, content pipelines, bulk classification or anything tolerating hours instead of milliseconds costs half in batch mode. Stack batch with caching and a complex call drops to roughly 25% of standard rate. That’s not a typo.
4. Compress context aggressively (typical savings: 30–50% on input costs)
Trim conversation history to the last N relevant turns. Summarize RAG documents before injection. Remove redundant function definitions. Every token you don’t send is a token you don’t pay for. Most teams find that cutting input payload by 40–60% has minimal quality impact because the trimmed context was redundant anyway.
5. Evaluate open-source for stable workloads (typical savings: 5–20x vs. proprietary)
Meta’s Llama 4 on Groq, Together AI, or Fireworks AI can undercut commercial APIs substantially. DeepSeek V3.2 at $0.14/$0.28 rivals models 10x its price on many benchmarks. For well-defined, stable workloads where the prompt is mature and the task is predictable, open-source economics are hard to argue with.
6. Set budget guardrails before you need them (typical savings: prevents 5–10x overruns)
A misconfigured batch job or runaway prompt loop can turn a $5,000 monthly bill into $50,000 overnight. Set alerts at 80% of expected spend and per-day maximums that cap worst-case scenarios. Every major provider supports spend caps — but most teams configure them after the first surprise invoice, which is a bit like buying a fire extinguisher after the kitchen is already on fire.
7. Track cost per unit of work, not just total spend (typical savings: 20–40% through attribution-driven optimization)
Knowing you spent $47,000 on API calls last month tells you nothing actionable. Knowing your document pipeline costs $0.12 per document, your support agent costs $0.03 per resolution, and your code review tool costs $1.40 per pull request, and that code review spiked 3x this week because a new prompt template doubled output tokens, that is actionable. That’s the difference between cost reporting and cost intelligence.
Which brings us to the question the pricing table can’t answer.
How Does CloudZero Turn LLM API Spend Into Cost Intelligence?
Every strategy above depends on one capability: seeing AI costs at a granularity that connects spend to business value. Most organizations don’t have it. CloudZero’s research found that only 51% of organizations strongly agree they can accurately track AI ROI, even though 91% feel confident in their ability to evaluate it. That gap between confidence and capability is where budgets quietly disappear.
CloudZero closes it by connecting LLM API spend to the business context that makes it meaningful. Not “we spent X on OpenAI this month” but “our document processing feature costs $0.12 per document for Customer A and $0.31 for Customer B, and the difference is because B’s documents trigger the long-context pricing tier.”
Direct integrations across every major AI provider
CloudZero was the first cloud cost platform to integrate directly with Anthropic’s Usage and Cost API, pulling Claude token consumption, model usage, and caching efficiency into the same platform used for AWS, Azure, and GCP. The platform also integrates directly with OpenAI, ingesting cost and usage data by model, workspace, and API key.
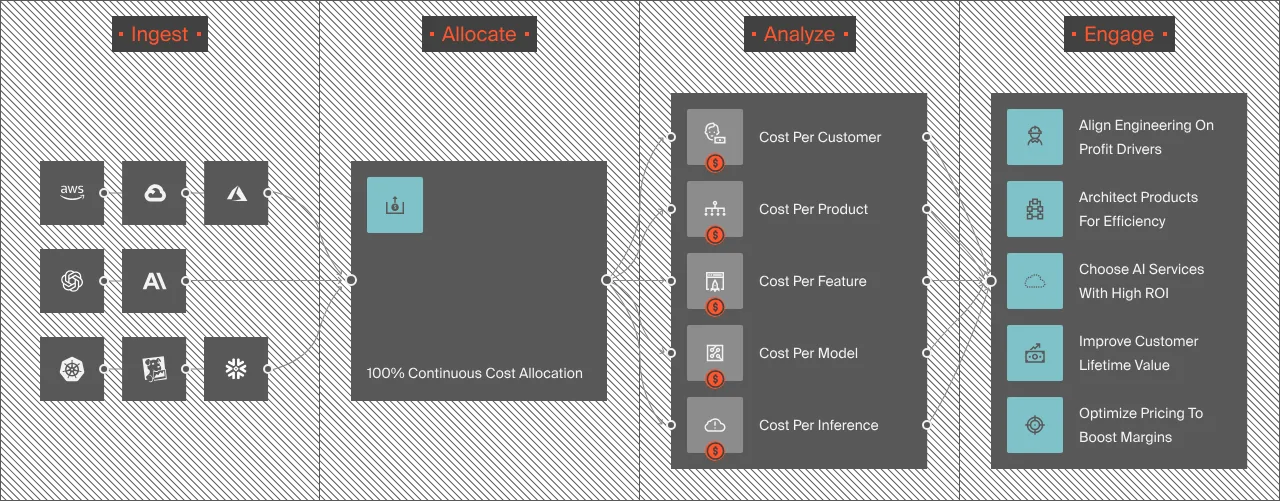
Beyond direct LLM integrations, CloudZero normalizes AI spend across your entire stack: AWS (including Bedrock), Azure (including Azure OpenAI), GCP (including Vertex AI), Oracle Cloud, Snowflake, Datadog, Databricks, and any custom source through the AnyCost ingestion framework. AI costs appear in the same dashboards as every other infrastructure cost, not siloed in a separate tool that only one team checks.
Cost per customer, per feature, per model
CloudZero attributes LLM spend to the business dimensions that matter: which customer generated the cost, which feature consumed the tokens, which model handled the request, which team owns the pipeline. That cost per customer visibility transforms architectural decisions (compress long documents before injection), pricing decisions (adjust SaaS tiers based on actual cost-to-serve), and product decisions (this feature costs more to run than it earns, is it worth it?).
That question, was it worth it?, is the one at the center of every AI investment. No pricing table answers it. Unit economics does.
Anomaly detection and budget forecasting
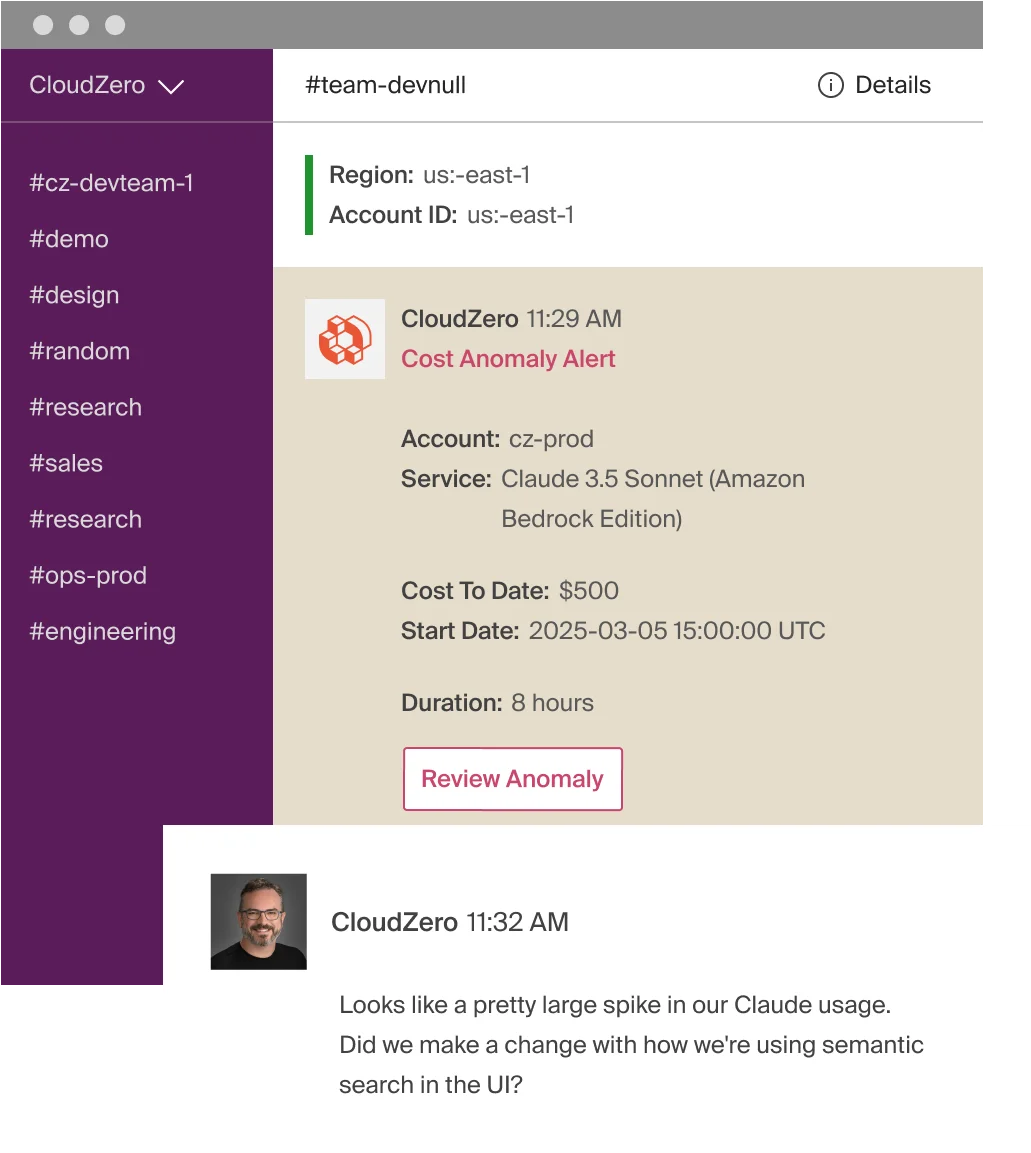
CloudZero surfaces unexpected cost spikes such as prompt regressions, context window creep, traffic surges or misconfigured jobs, with alerts that reach the owning engineering team within the hour. Not at month-end. Not in a quarterly review where everyone politely pretends they saw it coming. Engineers get the alert in Slack, with direct attribution to the model, workspace, or API key responsible.
For budgeting, CloudZero uses actual token consumption patterns to project future spend by model, feature, customer, or team. More precise than multiplying last month’s total by 1.15 and hoping, which, based on our conversations with hundreds of engineering teams, is roughly how 100% of them start.
CloudZero manages $15 billion in cloud and AI spend across global organizations such as Toyota, Duolingo, Skyscanner, Coinbase and more. An AI-native search company discovered OpenAI spend consumed 25% of their entire cloud bill with zero visibility, within minutes of connecting CloudZero, they had full allocation by token type and live trends across every provider.
to see how CloudZero maps LLM API costs to business outcomes. You can also get a free cloud cost assessment to find where your AI spend is going today. Or take a self-guided product tour to explore cost-per-customer dashboards and AI cost allocation in action.
Key takeaways
- LLM API pricing in 2026 spans a 600x range, from $0.10/MTok (GPT-4.1 Nano) to $60/MTok output (o3). Model selection alone can swing monthly costs by 10x or more.
- Output tokens cost two to six times more than input tokens across all providers. Optimizing output length has higher ROI than negotiating input rates.
- Prompt caching (up to 90% off at Anthropic and OpenAI) and batch processing (50% off) stack — reducing effective per-call cost to roughly 25% of standard rates.
- The cheapest model per token is not the cheapest model per task. Retry rates, output quality, and context overhead determine true cost per unit of work.
- Only 22% of organizations track AI spend by transaction. The visibility gap is the most expensive hidden cost in LLM API economics.
Frequently Asked Questions About LLM API Pricing











