You know this already. Regardless of your size, you must keep up with technological developments in your industry — and, increasingly, in other industries, even those that seem unrelated. Embracing disruption can enable you to increase your market share, revenue, and profit margins.
Delegating some development and operations responsibilities to Site Reliability Engineering (SRE) experts allows developers to innovate and create new solutions faster. In addition, they allow operations teams to focus solely on managing infrastructure at scale.
Yet, SRE engineers are often mistaken as operators or developers within the DevOps pipeline. This post explores the differences between SRE and DevOps, including answers to the following questions.
Table Of Contents
What Is Site Reliability Engineering (SRE)?
SRE is an approach that uses software engineering techniques to improve the reliability of IT operations at the speed of innovation and at any scale.
By standardizing processes, applying automation, and managing change before and after software releases, site reliability engineering ensures continuous modifications to a system do not break it and cause downtime.
In a DevOpsDays Boston talk in 2018, CloudZero CEO, Erik Peterson, described reliability as the “trustworthiness of a system’s ability to delight customers”. SRE specialists ensure this by skillfully integrating software development expertise with IT operations experience.
Report
Finance needs to prove AI’s return: CloudZero report
260 senior finance leaders (more than half CFOs) told us why the speed of seeing AI spend, not the size of it, separates who pulls ahead on AI from who gets burned.
What Do Site Reliability Engineers Do?
Site reliability engineers (SREs) are the glue between “Dev” and “Ops” in a DevOps framework. SREs naturally focus on making systems more reliable, efficient, and scalable. They do this by ensuring that software engineering expertise is applied to operations and system administration (sysadmin) challenges.
Among the responsibilities of the SRE team are to figure out how to reliably deploy and configure code, monitor availability and latency, manage change management, respond to emergencies, and maintain the capacity of production services.
SREs also figure out how to scale a system to accommodate more users, features, and use cases without compromising uptime and resilience. They are tinkerers who analyze how development decisions impact production environments, and how production-level requirements can influence design and development.
What Is DevOps In Software Engineering?
DevOps is a combination of culture, tooling, and engineering best practices that aim to build, deploy, and sustain high-quality software at high velocity. DevOps encourages collaboration between development and operations teams by fostering continuous collaboration and feedback.
The teams apply that via a continuous workflow referred to as a DevOps lifecycle. The DevOps lifecycle emphasizes continuous improvement in the form of continuous software iterations, like updates, upgrades, and patches.
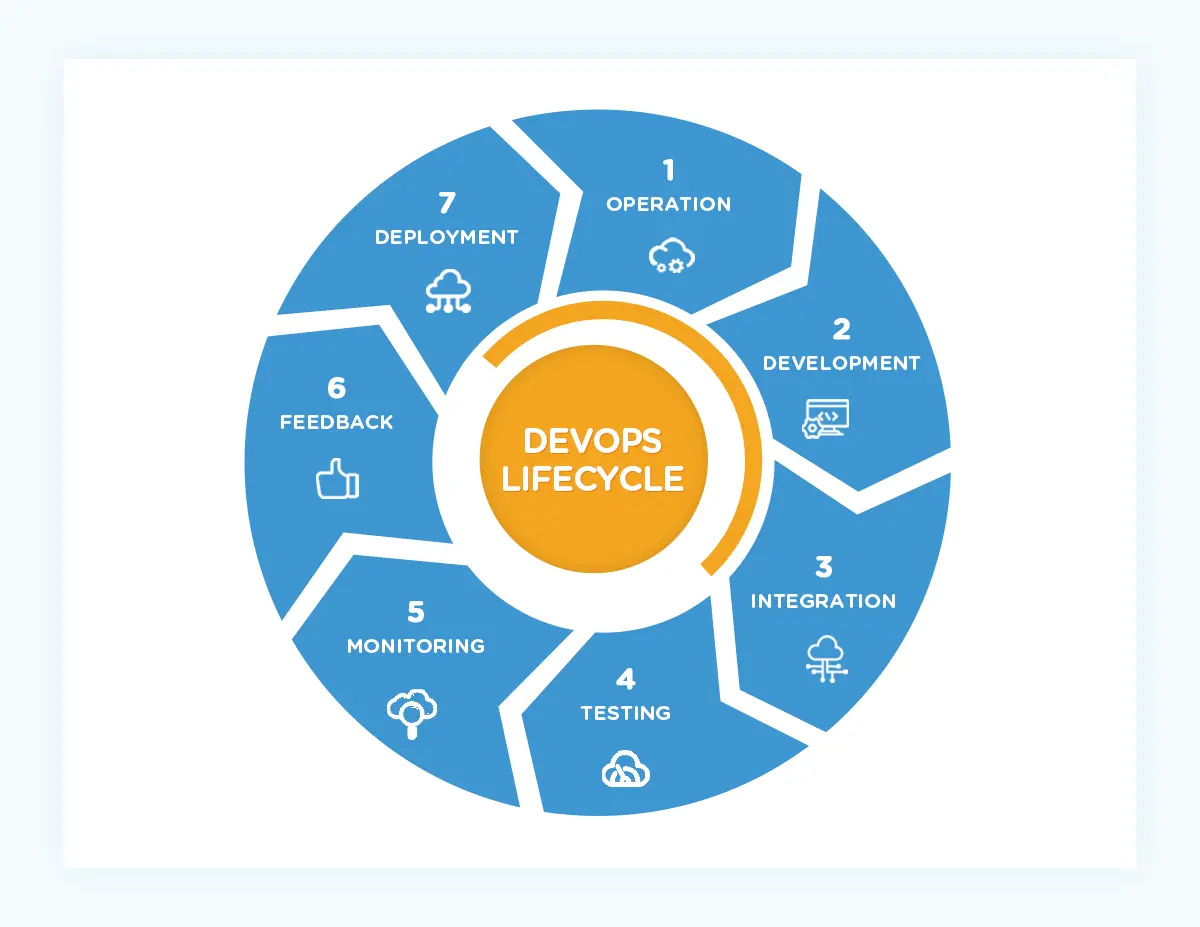
The result is a boost to engineering productivity as well as a better system for managing work, detecting and remediating software vulnerabilities, and continuously optimizing a company’s systems.
What Do DevOps Engineers Do?
A DevOps team comprises developers and operations experts that apply DevOps best practices in a repeatable process known as the DevOps pipeline.
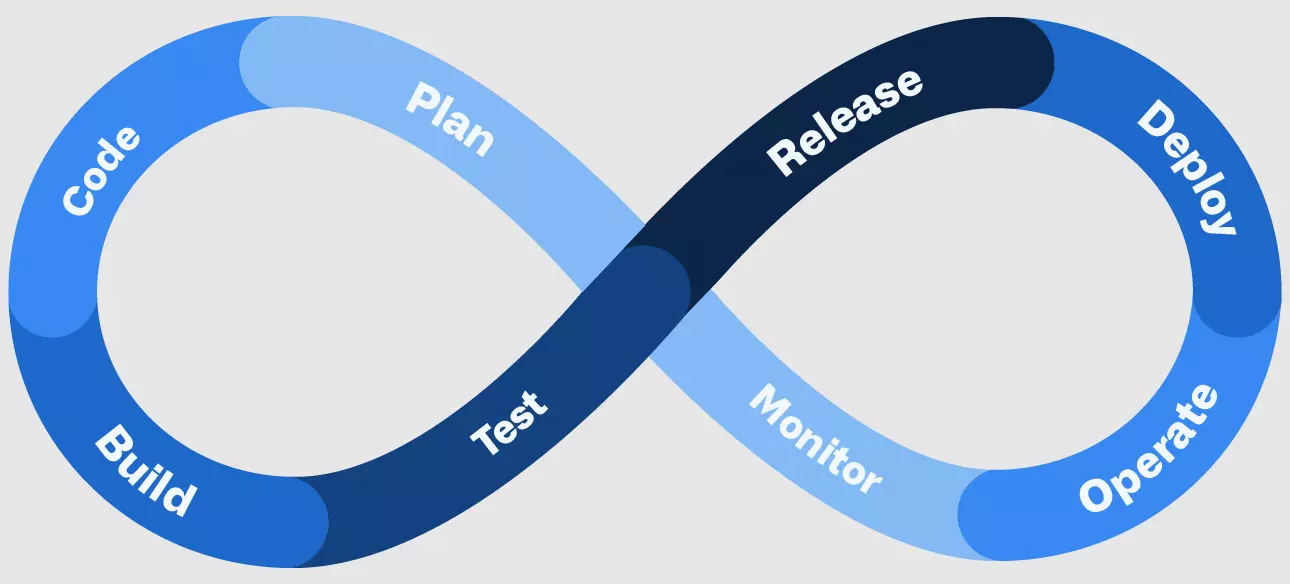
Here’s the thing. The DevOps lifecycle refers to the process of applying DevOps best practices throughout the entire software development process.
Meanwhile, DevOps pipeline is a term used to refer to the repeatable workflow DevOps teams use to plan, code, build, test, release, deploy, operate, and monitor software more frequently and reliably.
 Credit: GitHub
Credit: GitHub
DevOps engineers also leverage tools and automation to deliver better software faster. So, is site reliability engineering a part of DevOps? How are SRE and DevOps different?
SRE Vs. DevOps: 7 Major Differences
While DevOps focuses on building and releasing better software features more frequently, SRE ensures those upgrades, patches, and updates do not disrupt operations and user experience.
Notice how developing and delivering services faster and more reliably are central to both DevOps and SRE. However, DevOps engineers and SREs differ in their approach to achieving this objective. Here’s a quick overview of those differences.
|
Site Reliability Engineering (SRE) |
DevOps | |
|
Beginnings |
2003 |
2007 – 2008 |
|
Roles |
Tasks that improve system reliability, including standardizing releases, infrastructure configuration and provisioning, performance monitoring, and root cause analysis |
Multiple roles by different engineers to serve the plan, code, build, test, release, deploy, operate, and monitor phases of a DevOps pipeline |
|
Focus |
Ensure system availability, robustness, and scalability at the speed of developers’ innovation and operations’ stability requirements |
Deliver better software faster |
|
Workflow |
Use software development expertise to solve operational challenges, and vice versa |
Left to right on a DevOps pipeline |
|
Tooling |
Custom scripts and various tools |
Various open-source and third-party tools at different stages of the pipeline |
|
Incident management |
Proactive through chaos engineering and root cause analysis |
Reactive and addresses it after it happens |
|
Measurement method |
SLAs, SLIs, SLOs, etc |
Deployment frequency, failure rate, etc |
Now here’s a deeper dive into the differences between DevOps and SRE.
1. DevOps vs. SRE: Beginnings
Ben Treynor Sloss, the Vice President of Engineering at Google, confined the concept of Site Reliability Engineering in 2003. He famously said in an interview that “SRE is what happens when you ask a software engineer to design an operations team.”
According to Ben, Google hires half of its SRE engineers if they have more of a software background, and another half if they have more of a systems engineering background.
At the time, Ben’s team wanted to ensure their software solutions offered high availability and optimal performance, all without disrupting development and operations work.
To achieve this, the SRE team would automate repetitive tasks, set up new environments, and facilitate infrastructure configuration between developers and system administrators.
The DevOps concept emerged around 2007 to transform the traditional software development model. Before then, engineers who wrote code were functionally and organizationally separate from those who deployed and supported that code in production environments — even when using the agile development method.
By emphasizing continuous collaboration between Dev and Ops, the concept aims to help organizations design, build, deploy, and maintain high-quality software incrementally following a continuous, highly automated, and standardized workflow (DevOps pipeline).
2. SRE vs. DevOps: Roles and focus
SRE primarily concentrates on optimizing system availability (uptime) and reliability (meeting Service Level Agreements). Meanwhile, DevOps emphasizes software development and delivery speed through incremental improvement.
Typically, an SRE team consists of engineers with both development and operations backgrounds. However, a DevOps team includes various roles, such as developers, security engineers, testers/QA experts, cost optimization engineers, SREs, and others.
SREs also write code to automate tasks that transfer development work into operators’ domains. They can also tweak code from development to more seamlessly align with production-level requirements so that,
- The code does not break things in production, which could cause downtime
- Rather than regressing code back to development for tweaks, SREs can manage it themselves so that developers can keep innovating and creating other updates, upgrades, or patches.
One more thing. While “Dev”, SRE, and “Ops” teams all collaborate and work across teams of engineers, they have different roles. Developers mostly write the code that iterates the main application. Operators are the main system administrators in production.
3. DevOps vs. SRE: Principles
Each approach has unique principles and best practices. As an example, while DevOps emphasizes continuous change, SRE ensures that those incremental changes don’t introduce errors, bugs, and other problems that could compromise the otherwise stable system.
Site reliability engineering (SRE) principles include:
- Service Level Indicators (SLIs) – These are parameters SREs use to measure customer experience. SLI is calculated using the formula: SLI = Good Events * 100 / Valid Events. These “four golden signals” include, latency, traffic, error rate, and saturation.
- Service Level Objectives (SLO) – SLOs refers to the agree-upon means of measuring service level indicators.
- Service Level Agreements (SLAs) – A legal agreement between a service provider and a customer on an acceptable level of system performance and risk to expect, such as 99.999% uptime.
- Error budget – The maximum period during which a system can malfunction, fail, or underperform without breaching the contractual terms of an SLA. The team can experiment and release new features if they are running within the error budget. If not, they first work with the operations team to reduce these errors or outages to an acceptably low level.
- Automation – SRE strives to minimize repetitive tasks with automated systems that don’t add additional complexity to the process.
- Monitoring – SREs monitor their systems to discover a root cause of an issue, notify stakeholders when a concern requires immediate action, analyze the data to use in long-term planning, and assess the system’s behavior before and after modifications.
Meanwhile, DevOps principles include:
- Incremental release – Different developers work on different portions of the whole application concurrently, integrate all of it via a source code management platform, and then test/QA and operators evaluate the code further before it is released to end users, which speeds up the release process.
- Automation – To improve efficiency, error-free, and fast development, DevOps engineers use a variety of tools linked together in a pipeline.
- Continuous integration and continuous delivery – The CI/CD pipeline facilitates the rapid coding, building, testing, and deployment of code.
- Continuous monitoring – In this process, various monitoring aspects are considered, such as infrastructure and application performance, network health, as well as cost monitoring before and after delivery. In addition, this step collects and relays customer feedback.
- Collaboration – Developers and operations must continually share insights and discuss best practices to ensure minimal errors or bugs leak through to end users, as one example.
The two teams also differ in their workflow.
4. SRE vs. DevOps: Workflow
The DevOps lifecycle often operates in a “left to right” pipeline, as in an assembly line. Engineers check the code for quality and errors at each “checkpoint” before approving it for the next step, stage, or phase of DevOps.
In contrast, SRE teams manage how code deployment, configuration, and monitoring happens, as well as a service’s uptime, change management, latency, incident response, and capacity management in production.
This means SREs often work “right to left”, using production-level requirements to influence development and even design decisions.
5. DevOps vs. SRE: Tools
In the DevOps role, the most widely used tools include Integrated Development Environment (IDEs), code editing platforms like Maven, Git as a source code repository, GitHub, BitBucket, or GitLab for version control, Jenkins for Continuous Integration and Development (CI/CD), change management tools like JIRA, CloudZero for unit cost monitoring and cloud cost optimization, as well as Splunk for log monitoring.
In contrast, SREs prefer to script custom automation solutions with languages such as Bash or Python. This enables them to scale them up and down as needed. However, they use other SaaS tools for tasks like incident response and management (Slack, PagerDuty, ServiceNow, etc).
6. SRE vs. DevOps: Incident response management
Testing and quality assurance engineers continuously test code throughout the DevOps pipeline to detect errors, bugs, and bottlenecks. Once they receive an alert, they start working on the issue.
SREs goes further by using chaos engineering to test how a program would behave in the event of a failure. By reviewing the results, they can improve the reliability of the system before a similar issue occurs in production — this time, in reality, with potentially dire consequences.
7. DevOps vs. SRE: Metrics for measurement
SREs use error budgets, service level objectives (SLOs), service level indicators (SLIs), and service level agreements (SLAs) to gauge performance. DevOps engineers usually assess success with metrics like deployment frequency and deployment failure rate.
Those are some of the major differences between site reliability engineering and DevOps.
What’s Next: Become A Financially Conscious DevOps Or Site Reliability Engineer With CloudZero
SREs and DevOps engineers have historically had difficulty accessing cloud cost data. That’s likely because finance teams and the CFO have traditionally handled cloud costs.
An unexpectedly high cloud bill may prompt finance to bring it up. But, it will often be a month after a technical event happened, such as a new feature deployment, testing project, error, or onboarding a new customer. In that case, there is nothing you can do to stop the cost overrun because that window is already closed.
After that, finance may have announced budget cuts for experimental projects, new feature releases, or something else you deem crucial to maintaining engineering velocity and SLAs. As an SRE, a DevOps engineer, or the CTO, you likely felt that finance doesn’t get what it takes to ensure reliable service delivery.
It would be great if you two spoke the same language. A cost-conscious engineer would realize that their technical decisions affect the bottom line of the entire company. You’d then be able to create more cost-effective solutions at the architectural level to help finance price the service more competitively.
Enter CloudZero. With CloudZero, you get the industry’s first code-driven approach to collecting, enriching, analyzing, and acting on cloud cost data as an engineer. By shifting cloud cost left, CloudZero empowers you to:
- Speak the same financial language as finance, such as which features to prioritize and when to defend your engineering spend because it will benefit adoption or customer experience, hence retainment.
- Know how technical decisions will impact your company, including projecting how costs will change as adoption and new features expand.
- Correlate costs with events, including testing and deployments, so you can discover what’s causing cost changes — and manage it at the technical source.
- View costs of the aspects you actually care about, such as cost per feature, cost per deployment, cost per environment, cost per dev team, cost per project, etc. No endless tagging in AWS, Azure, or GCP required.
- Automatically detect cost anomalies caused by technical issues before they affect end users and compromise your SLAs.
- Get alerts straight to your favorite incident management tool, such as Slack, PagerDuty, or ServiceNow, or good old email and text. CloudZero anomaly alerts are never noisy.
 to see all of this and more!
to see all of this and more!











