DevOps has exploded in popularity since the concept first emerged in 2009. A DevOps approach encompasses both practices and tools that engineers use to build quality software more rapidly.
Before DevOps, software development followed a “waterfall” model. Back then, developers would code first, then perform quality assurance (QA) testing, and fix any bugs or errors as necessary.
The DevOps model is much more integrated; it involves breaking down the development process into smaller parts, which are easier and faster to manage. Instead of building the entire application before testing, developers build and test continuously.
They build the entire model on a continuous improvement process involving daily collaboration. DevOps teams accomplish this with automation tools, from deployment and continuous integration to monitoring, security, and cost management.
Here are some of the best DevOps tools and products, organized by category so that you can pick the right one for your company’s needs.
DevOps Tools For Configuration Management
Red Hat defines configuration management as “a process for maintaining computer systems, servers, and software in a desired, consistent state.”
G2 Crowd defines configuration management as “tracking and conducting changes made to applications during development.
The most effective configuration management tools keep track of changes to applications and their infrastructure to ensure configurations are in a known and trusted state, and the configurations do not rely on DevOps tribal knowledge.”
The best DevOps tools for configuration management automate the process. Here are some top examples:
1. Chef
Chef is an open-source platform for automating and managing cloud infrastructure and configuration.
It uses the Ruby language to develop vital building blocks like cookbooks and recipes. With Chef, engineers can turn infrastructure into code, automating many manual processes involved in configuring and managing multiple systems.
The tool supports Linux, Windows, and mainframe platforms. The software also supports various node types, including virtual machines, servers, and containers running on platforms such as AWS, GCP, and OpenStack.
2. Puppet
Puppet is a systems automation platform that DevOps teams use to manage server configurations easily. It converts infrastructure into code, centralizes configuration management, and is open-source. By defining a state in Puppet’s declarative language, engineers can ensure their infrastructure systems remain in that state without a lot of manual effort.
3. Ansible
RedHat’s Ansible provides IT automation and configuration management for DevOps teams looking for a simpler platform than, say, Chef or Puppet.
Also open-source, it can design and provision infrastructure, deploy applications, orchestrate intra-services, and manage compliance. However, Ansible does not require additional daemons, servers, or databases to function.
4. SaltStack
Also called Salt, SaltStack provides remote execution and orchestration services for configuration management, such as app deployment and management.
Although SlatStack is not as simplified as Ansible or as complex as Puppet or Chef, it offers rapid data collection and execution, highly scalable infrastructure, data-driven orchestration, and solid performance.
5. AWS Systems Manager
Previously known as Amazon EC2 Simple System Manager (SSM), AWS Systems Manager enables engineers to view, control, and automate operations management, change management, node management, application management, and control shared resources on the AWS cloud infrastructure.
It provides access to operational data from many AWS services so that DevOps professionals can perform automated tasks across multiple AWS resources.
If you’re managing fleets of compute resources — in most cases, Amazon EC2 compute resources — and need to provision, configure, maintain, and hatch services and servers, then you’re probably going to use one of these configuration management solutions.
Report
Finance needs to prove AI’s return: CloudZero report
260 senior finance leaders (more than half CFOs) told us why the speed of seeing AI spend, not the size of it, separates who pulls ahead on AI from who gets burned.
DevOps Tools For CI/CD
Continuous integration (CI) tools automatically integrate code changes from multiple contributors into a single software application. Automated testing then verifies every change.
Continuous deployment (CD) tools automatically deploy all validated code changes to customers; only a failed test prevents new changes from being deployed.
Here are some of the best DevOps tools for CI/CD:
6. CircleCI
In CircleCI, engineers build, test, and deploy quality code efficiently and securely. It is SOC 2 Type II compliant and FedRAMP approved.
DevOps teams use it to build software their way with custom job orchestration (with workflows). Teams can also use it to run jobs on Linux, Windows, or macOS in their infrastructure or the cloud.
7. GitLab
The GitLab platform enables teams to collaborate during the DevOps lifecycle’s integration, management, configuration, and maintenance phases. It has been on the market longer than some popular tools like GitHub CI and CircleCI.
Since GitLab has both version control and CI/CD tools, it’s the perfect combination. But this combo is also available for GitHub. Teams can create a GitHub or Bitbucket repository and integrate it with CircleCI.
|
If you’ll take a closer look – you’ll notice that GitHub and CircleCI are cloud-only services, so you can’t download them and use them in your local network for learning purposes or install them in your corporate network as your DevOps tool. GitLab may be used in both ways – locally and in the cloud. The local method may be useful for projects where you have some services that will be required in your CI processes, such as:
Of course, you may call these services from your cloud CI, but it requires them to be available in a global network (internet). In this case, you’ll have to think over the way to secure access to your services and the way to store credentials for them (project environment variables, for example). So, as we can see, GitLab is a perfect solution for both local and cloud usage.
|
 Dmitrii Bormotov
Dmitrii Bormotov8. Jenkins
Jenkins is an open-source, server-based automation platform that helps DevOps teams automate tasks in building, testing, and deploying any project or software. It is written in Java, can run out-of-the-box, and offers packages for Linux, Windows, and macOS — and other Unix-like OSs.
9. Semaphore
Semaphore is a hosted CI/CD platform for all stacks. It offers one of the fastest CI tools in the industry, affordable pricing, and responsive customer support. Because it’s a hosted CI tool, engineers don’t need to manage external servers. The tool is also customizable for the pay-as-you-go model and any workflow.
10. CloudBees
CloudBees is a continuous delivery platform for large enterprises that want to leverage Jenkins CI in the cloud or on-premises. It is a former platform-as-a-service but now focuses on open-source continuous integration (and Enterprise Jenkins for software delivery).
11. AWS CodePipeline
AWS engineers can model, visualize, and automate software release pipelines for rapid, reliable infrastructure and application updates with AWS CodePipeline a fully managed CD service.
The engineers define an execution model, and CodePipeline automates the release process’s build, test, and deployment stages. It also integrates with popular services such as GitHub or a custom plugin.
12. AWS CodeDeploy
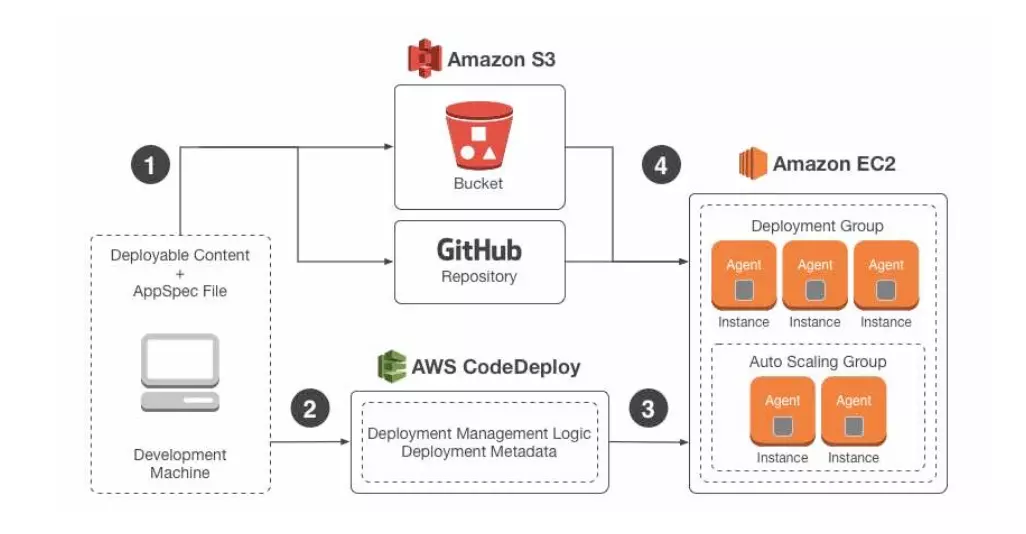
Another AWS tool, AWS CodeDeploy is a fully managed service for automating software deployment to various AWS compute services. These services include Amazon Elastic Compute Cloud (EC2), AWS Lambda, and AWS Fargate.
13. GitHub
|
GitHub Actions, is a CI/CD tool similar to Travis or Jenkins. We love it because of how tightly integrated it is into the GitHub core experience. We mainly use it for testing and will likely use it in the future for automated publishing of the command line tool we build for our customers.
|
 Brian Vallelunga
Brian VallelungaDevOps Tools For Continuous Monitoring/Observability
Continuous monitoring (CM) is the crucial last step in the DevOps pipeline. In DevOps, the pace of deployment and constant change demands that key metrics be tracked, identified, and analyzed continuously — see our guide to DevOps metrics for the KPIs that matter most.
CM also helps resolve infrastructure issues. As opposed to monitoring, observability enables engineers to evaluate the status of internal systems by observing external output.
Here’s a look at some of the top CM DevOps tools:
14. HoneyComb Observability
It is a full-stack observability service that helps DevOps teams view, analyze, and debug live production software. HoneyComb Observability ingests event data from anywhere with any data model so teams can identify issues that metrics and logs won’t reveal.
Engineers can use it to improve monitoring across microservices, platforms, and serverless applications.
15. Epsagon
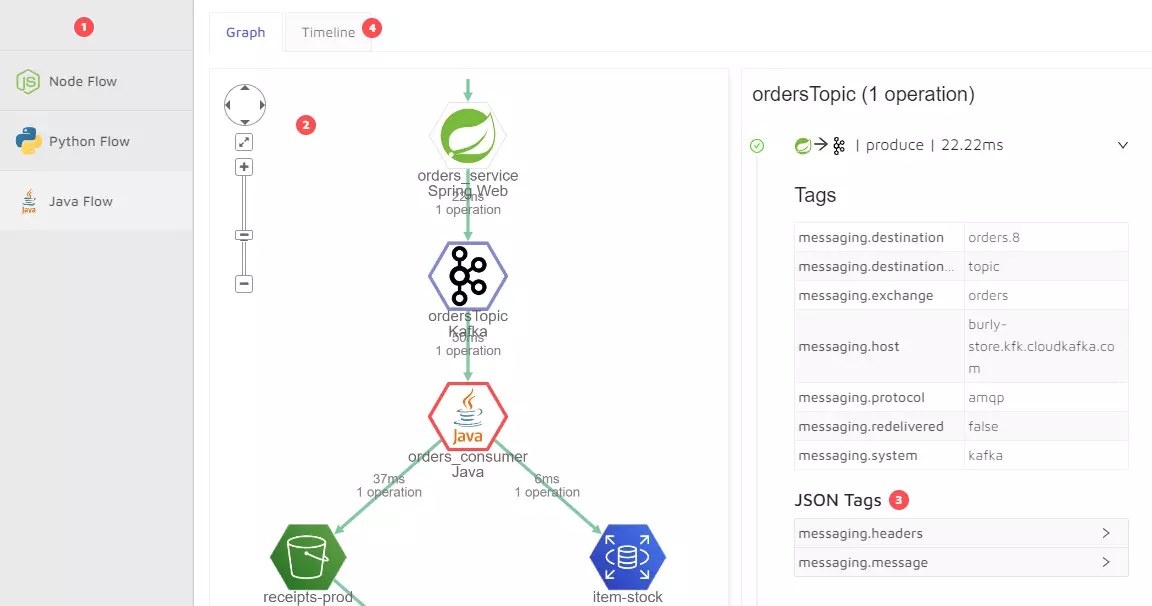
Cisco’s Epsagon is an application monitoring platform built to improve visibility into serverless and distributed applications (containers and microservices). It leverages payloads, events, and logs to help teams view, comprehend, and solve system issues.
16. DataDog
DataDog is a SaaS-based full-stack monitoring platform for application, serverless, real user, network, synthetic, and security purposes. It also offers log management. The tool provides cloud monitoring as a service, helping DevOps teams see inside any stack, app, anywhere, and at any scale.
17. SignalFX
Splunk’s SignalFX is a real-time cloud monitoring tool for DevOps teams that want to scrutinize data from any source and custom application types. It works with cloud-native technologies like microservices, containers (Kubernetes and Docker), and serverless functions.
18. New Relic
This is also a full-stack monitoring service for engineers that want to collect logs, metrics, events, and traces in one place. New Relic helps correlate issues across an entire stack so teams can visualize and debug issues faster — while paying only for the resources they use.
19. Grafana
A popular visualization tool for DevOps, Grafana is an open-source data visualization, analysis, and monitoring tool. It is best-known for its highly visual and customizable dashboards.
Grafana can also ingest data from almost any source, including databases such as Prometheus, InfluxDB, MySQL, Graphite, and Elastisearch.
20. Dynatrace
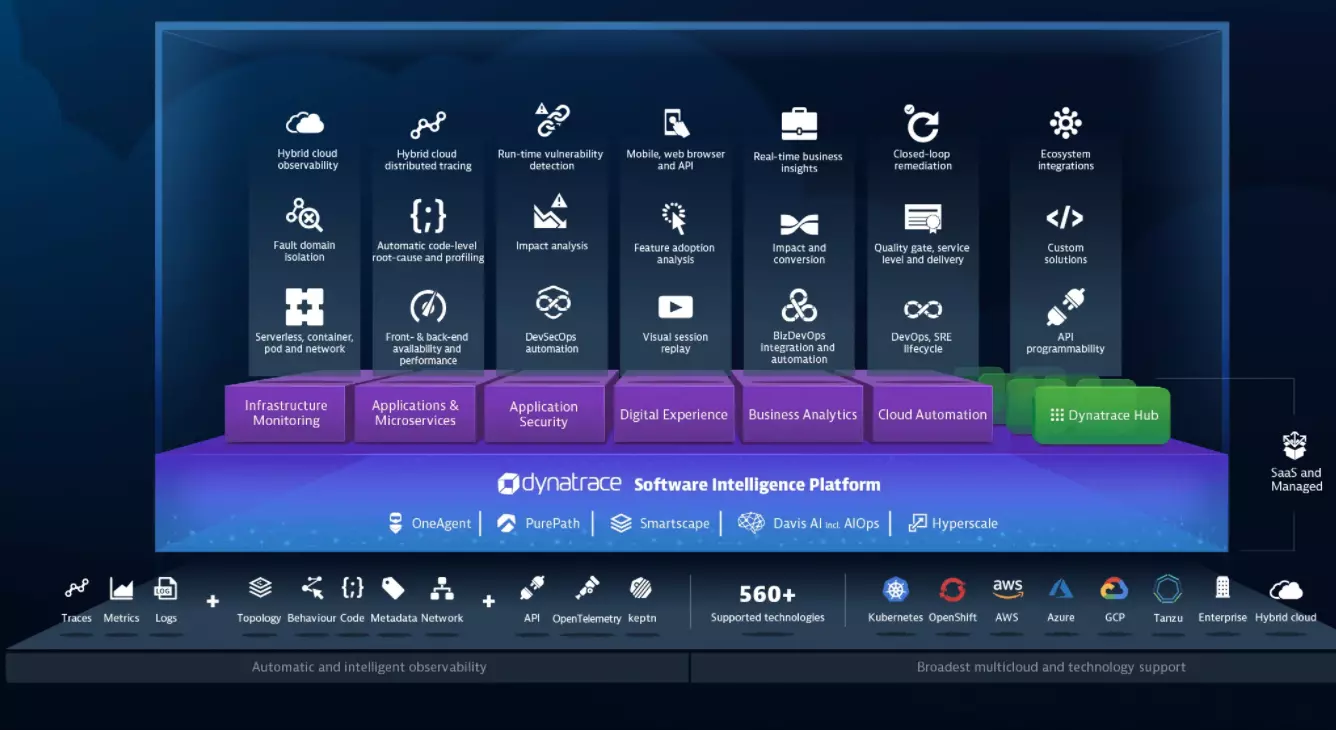
Like New Relic and DataDog, Dynatrace is an all-in-one monitoring service that automates application, infrastructure, user experience, and cloud security monitoring. It also supports all the major cloud technologies and platforms.
21. AWS CloudWatch
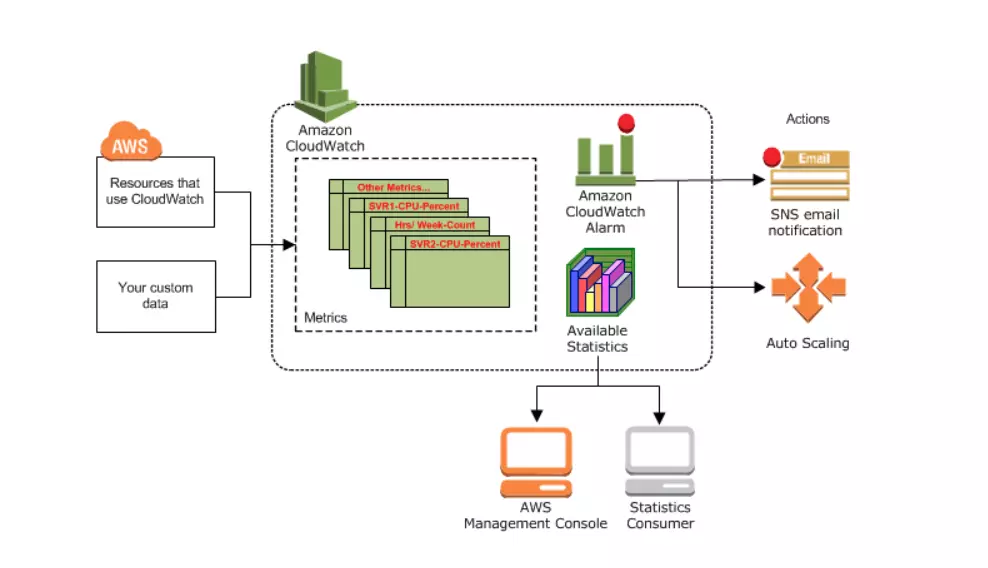
The monitoring and management tool provides insight into the AWS public cloud, hybrid cloud, and on-premises infrastructure and applications.
With AWS CloudWatch, engineers can collect and study all operational and performance data in one place instead of viewing them across various databases, servers, or networks.
Monitors ensure that bad things — such as outages or security breaches — don’t go undetected. The faster you can see problems, the quicker you can react.
DevOps Tools For Log Management
Log management comprises the processes and policies governing the generation, analysis, transmission, archiving, storing, and disposing of log data that an application generates.
Log management tools automate the process of handling such large volumes of data. Here are several DevOps tools for Log Management to consider:
22. Sumo Logic
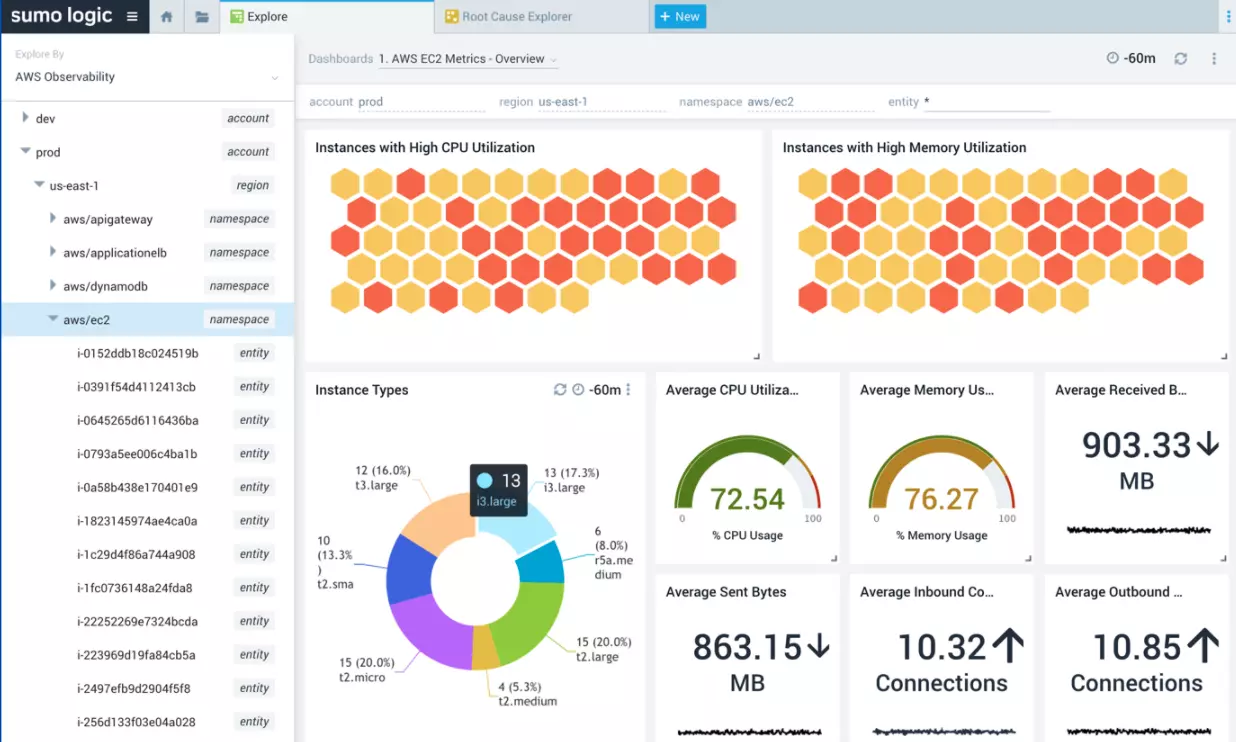
Sumo Logic is a cloud log management tool that leverages machine learning to analyze logs, metrics, and traces.
It is ideal for centralizing large log volumes in AWS, GCP, or Azure. Engineers can also use it to catch system issues because it offers continuous log management with real-time alerting and dashboards.
23. Splunk Log Observer
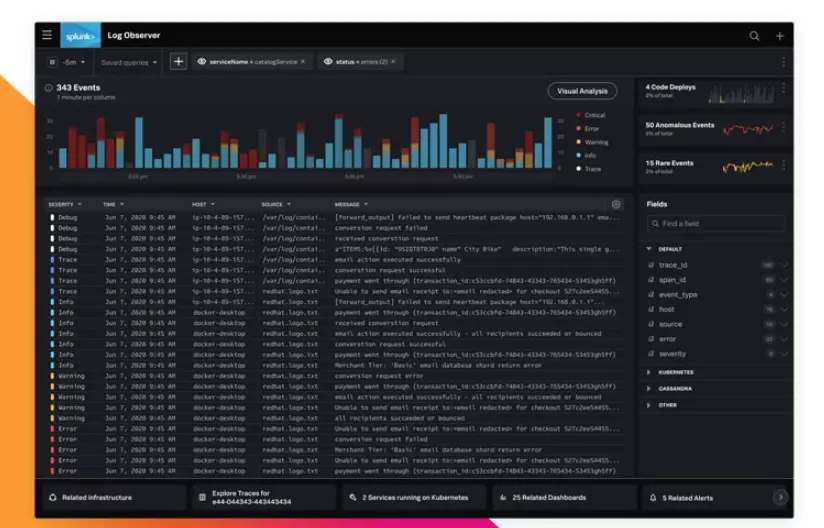
Splunk Log Observer is a log analysis platform for machine-generated SRE-oriented or developer logs.
It centralizes structured, unstructured, and multi-line data so the DevOps team can monitor requests at all levels in both on-premises and cloud environments. This allows them to identify areas for improvement.
24. ChaosSearch
This cloud log analysis tool offers several powerful features, including ease-of-use, quick integrations, and unlimited scalability.
That makes ChaosSearch ideal for monitoring logs in any stack at any scale — from multiple AWS services to Kubernetes and Kafka. It also supports open standard Kibana and its alerting features to help improve system visibility.
25. Logz.io
Using a combination of several open-source log monitoring platforms, Logz.io provides a modern, scalable, and easy-to-use SaaS platform for log analysis.
Those platforms include Prometheus, Jaeger, and ELK. It helps track and surface system errors and sends alerts via various endpoints, such as Gmail, Slack, and PagerDuty, to help engineers catch problems early.
26. Loggly
Loggly is SolarWind’s log data management solution. Centralizing logs from an entire infrastructure makes them easier to analyze and derive insight from.
Everyone, from developers to product managers, can access the insight. It also offers alerting, transaction tracing, and troubleshooting server and app issues.
27. AWS CloudWatch Logs
AWS CloudWatch Logs enable DevOps teams to aggregate all log data from their apps, systems, and AWS services in one, highly scalable place. They can then view, analyze, filter, store, archive, or query specific error patterns and codes, and much more.
DevOps Tools For Containers And Kubernetes
In From Pots and Vats To Programs and Apps by Gordon Haff and William Henry of Red Hat, Haff defines Kubernetes as follows:
“Kubernetes, or k8s, is an open-source platform that automates Linux container operations. It eliminates many of the manual processes involved in deploying and scaling containerized applications. In other words, you can cluster together groups of hosts running Linux containers, and Kubernetes helps you easily and efficiently manage those clusters.”
Automated tools for container management do the work of orchestrating containerized resources efficiently.
Here are some of the best DevOps tools for containers and Kubernetes:
28. Docker
Docker is a framework for building, running, and managing containers for both cloud and server environments. It provides a set of tools, such as APIs, UIs, and CLIs, to automate many tasks throughout the end-to-end application delivery lifecycle.
Docker is also lightweight, clean, doesn’t require complex orchestration, and eases application portability and sharing.
29. Kubernetes
Kubernetes is the most popular open-source platform for deploying, scaling, networking, and maintaining containerized applications. It is beneficial for orchestrating these tasks on a large scale. Understanding horizontal vs. vertical scaling trade-offs is essential for configuring Kubernetes efficiently.
The Kubernetes architecture can also run all major types of workloads including, monolithic, stateless, microservices, stateful, services, and batch jobs.
Check out our comparison of Kubernetes and Docker here: “Kubernetes Vs. Docker (Vs. OpenShift): The Ultimate Comparison”
30. CloudZero Kubernetes Cost Monitoring And Analysis

Moving to Kubernetes can obscure key COGS metrics, leaving you with a sudden cost blindspot. CloudZero’s Kubernetes cost monitoring provides visibility into your cloud cost — containerized, or not — providing you with seamless visibility into your cloud spend, while you embrace Kubernetes.
Schedule a demo here to explore Kubernetes cost monitoring and management with CloudZero.
|
My favorite DevOps tool is Kubernetes. As a professional in the cloud computing space, I appreciate that Kubernetes opens up multiple possibilities with multi-cloud and hybrid cloud implementations. It also facilitates the building of cloud-native applications with agility and speed. The majority of the software developers I have worked with on various projects agree that the container orchestration and management that Kubernetes offers
|
 Reuben Yonatan
Reuben Yonatan 31. Rancher Labs
Rancher Labs runs a Kubernetes distribution, enabling engineers to unify Kubernetes cluster management, including user management, updates, cluster provisioning, and policy management. It also offers enterprise Kubernetes support, whether on-premises or hosted.
32. Fairwinds
Fairwinds offers Kubernetes governance and security for DevSecOps who need an automated way to monitor and enforce Kubernetes compliance, security, and performance. In addition, it helps detect Kubernetes misconfiguration across multiple clusters, tenancies, and teams.
33. AWS ECS
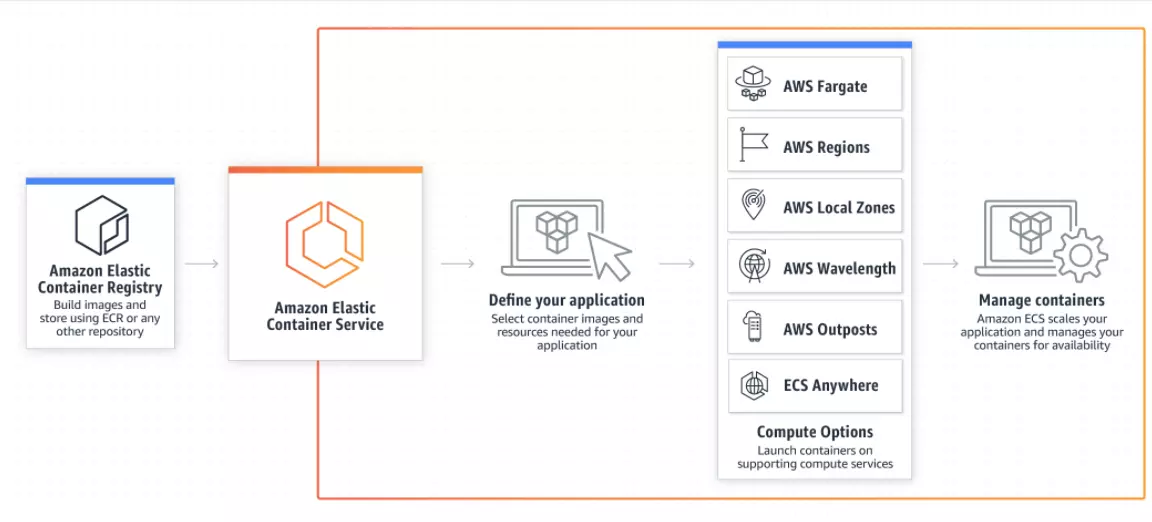
Amazon Elastic Container Service (AWS ECS) empowers teams to quickly deploy, scale, and manage containerized apps using a fully managed container orchestration service. In particular, it is ideal for projects requiring a highly scalable, secure, and reliable platform.
34. AWS EKS
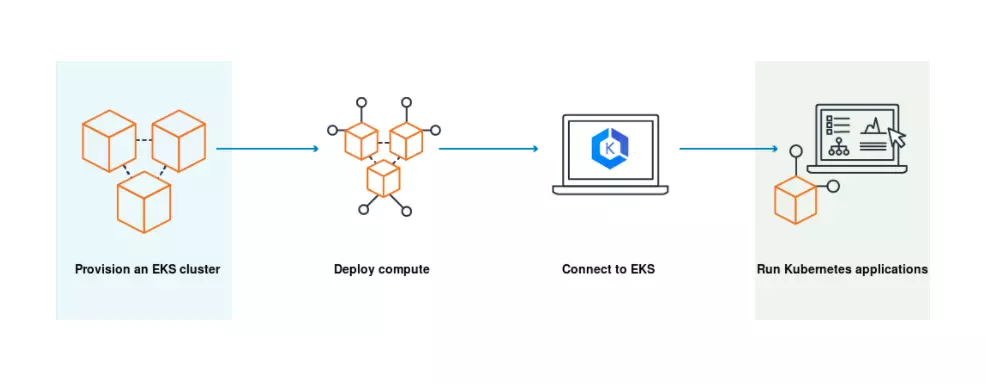
Amazon Elastic Kubernetes Service (AWS EKS) offers a highly scalable, reliable, and secure way to run Kubernetes both on-premises and in the AWS public cloud. It is compatible with apps that operate on upstream Kubernetes as well.
Teams also use EKS to run Kubernetes apps on Amazon EC2 and AWS Fargate resources — via a highly available and managed Kubernetes control plane.
35. Arkade
Arkade is a portable Kubernetes marketplace that speeds up downloading DevOps CLIs (like kubectx, kubectl, and kind) and helm charts as easy as executing a single command in seconds.
| Arkade is an open-source DevOps tool that allows you to spin up various Kubernetes services, without having to remember dozens of configuration options or paths. It’s reducing the options to the bare minimum by setting sensible defaults. A real-time saver for day-to-day DevOps work. 
|
DevOps Tools For Incident Response And Management
Incident response and management involves detecting, responding, resolving, and analyzing incidents to prevent them from repeating frequently.
Incident response and management tools automate the process of detecting incidents and alerting the right people to them.
Here are a few of the top DevOps tools for incident response and management:
36. PagerDuty
By enabling quick major incident learning, PagerDuty automates end-to-end incident response. It does that through postmortems, activity timelines, and continuous learning.
This way, teams can mobilize cross-functional teams to respond, involve stakeholders, and communicate status updates. For mission-critical services, the response triggers automatically. Otherwise, a team member can activate it with a single tap.
37. Splunk On-Call (formerly VictorOps)
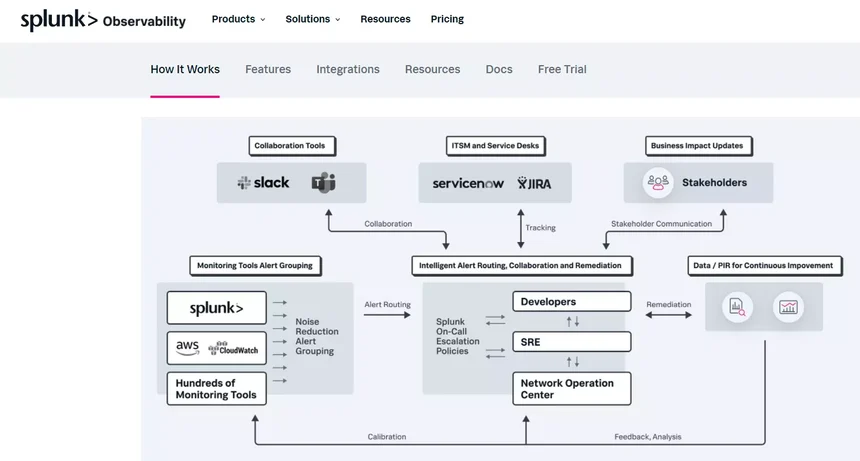
Splunk On-Call incident response software helps DevOps teams automate the time-sensitive aspects of incident response to improve mean time to acknowledge, remediate, and resolve issues.
Those aspects include escalation policies, on-call schedules, war room, identifying similar incidents, and conducting post-incident reviews.
DevOps Tools For Infrastructure As Code
DigitalOcean defines infrastructure as code (IaC) as “the approach of automating infrastructure deployment and changes by defining the desired resource states and their mutual relationships in code.” IaC tools automate infrastructure configuration.
See, AWS Console is not the best place to be defining infrastructure. Instead, you’ll want to define it in code, checking it in, versioning it, and maintaining it. Following an infrastructure-as-code pattern can benefit any healthy DevOps tool or cloud strategy.
Here are a few of the best DevOps tools IaC:
38. Terraform by HashiCorp
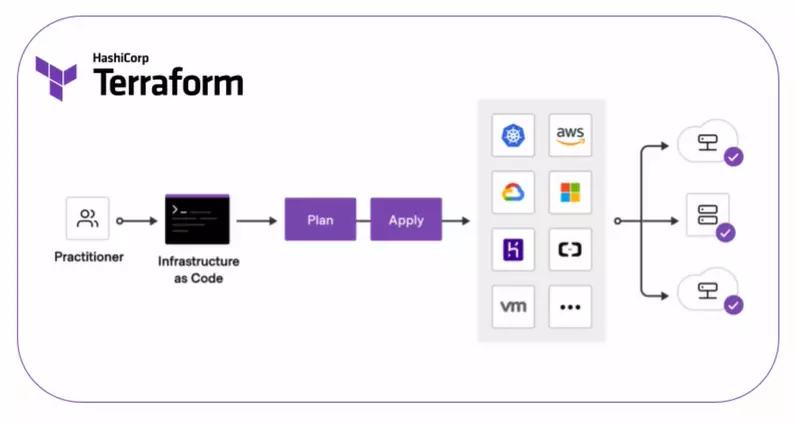
HashiCorp provides several services for managing infrastructure, but is widely known for Terraform. Terraform and Confirmation are two ways to use a declarative approach to defining cloud infrastructure, making them a key part of cloud DevOps.
39. AWS CloudFormation
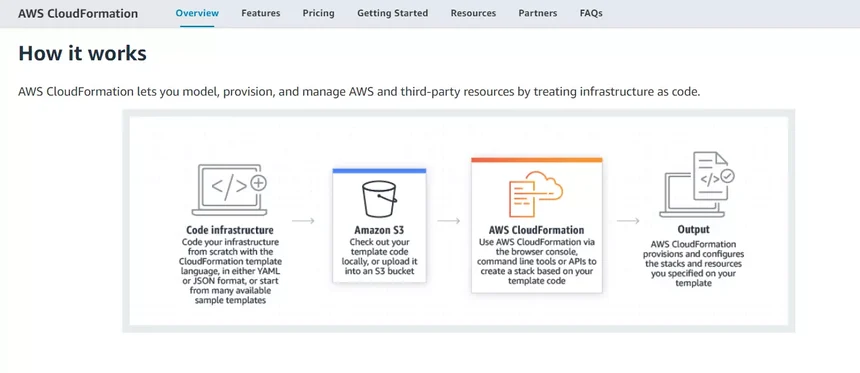
Amazon Web Services offers AWS CloudFormation to DevOps teams that want to use the CloudFormation template language (JSON or YAML) to code their infrastructure from scratch. But it provides many other sample templates to get started.
Using continuous integration and continuous delivery (CI/CD) automations, teams can then automate, test, and deploy the templates.
DevOps Tools For Chaos Engineering
Gremlin defines chaos engineering as “a disciplined approach to identifying failures before they become outages.” Chaos engineering tools run automated “what if?” experiments to help developers build resiliency into their systems.
The tools are designed on the premise that everything within a cloud computing environment will eventually fail. Many emerging properties are challenging to test.
Chaos engineering involves introducing failure into systems during working hours when engineers and resources are available to observe the impact of that failure and then fix it.
If you have an extensive, complicated system, chaos engineering is something you’ll want to do regularly. Some of the largest cloud software companies in the world use it to help predict where things might go wrong. For teams newer to DevOps practices, our DevOps best practices guide covers the foundational principles that make chaos engineering worth the investment.
Here are some of the best DevOps tools for Chaos engineering:
40. Gremlin
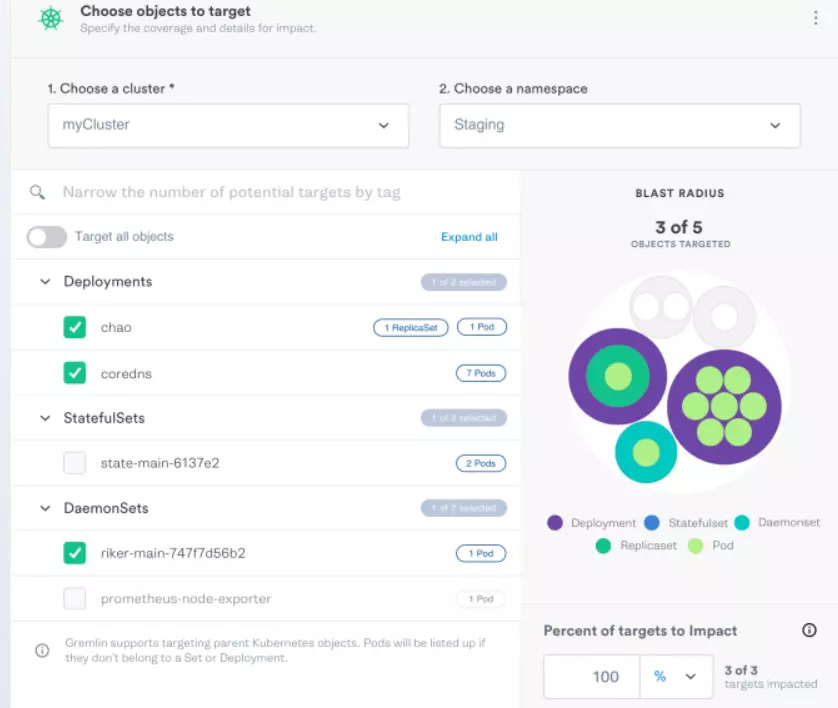
Gremlin’s chaos engineering tool enables teams to test how their systems react to failure by conducting targeted attacks on them. CPU spikes, process killers, server shutdowns, blocked DNS access, and latency injections are some of the attacks and experiments it offers.
Users can also apply it to chaos engineering in Kubernetes. Engineers can follow the testing process graphically. Gremlin also includes a kill switch to prevent experiments from getting out of control.
41. Chaos Monkey
Chaos toolkit is a software testing tool that Netflix engineers developed to test software well beyond the testing carried out during development.
In Chaos Monkey, engineers intentionally terminate containers and virtual machine instances so they can see how their systems perform during failure, pinpoint, and fix issues quickly, so they can learn how to build resilient systems, to begin with.
42. Chaos Toolkit
As with other solutions in this category, Chaos Toolkit enables you to manage chaos experiments and understand the blast radius of failures within your organization.
Engineers can embed it in their CI/CD chains as well as declare and save experiments in YAML or JSON files to orchestrate them like any other script (chaos as code).
DevOps Tools For Security
End-to-end security is a shared responsibility in DevOps. A DevOps security tool helps keep workflow from slowing down by automating some security gates. Here are several platforms to consider.
Here are a few of the best DevOps tools for security:
43. Lacework

With Lacework, enterprises get end-to-end threat detection, behavioral anomaly detection, and compliance in the cloud. In addition to infrastructure-as-code security, posture, and compliance, this cloud-native platform offers vulnerability management as a service.
It also supports all the major cloud providers. Teams can also deploy Lacework across multi-cloud environments, accounts, containers, workloads, and Kubernetes.
44. Snyk
Snyk is a DevOps tool for analyzing code as part of a CI/CD process. It continuously scans security threats by weaving its code into existing repositories, IDEs, and workflows throughout the software development lifecycle.
Teams can also use it to secure their containers, open-source dependencies, and Infrastructure-as-Code.
45. Threat Stack
Threat Stack is a cloud security observability tool that leverages machine learning with continuous monitoring best practices to surface anomalous behavior in entire infrastructure and application stacks. Teams like its easy-to-use yet powerful host detection capabilities.
46. Fugue

Like its alternatives here, Fugue automates cloud compliance as well as Infrastructure-as-Code, containers, cloud-native, and Kubernetes security. The platform boasts a single policy engine that empowers teams to optimize security both pre-and post-deployment.
47. Secure Code Warrior

Secure Code Warrior focuses on application security, though it also offers an excellent learning and development program for enterprise security strategists.
Training teaches developers to write code in real-time without introducing security vulnerabilities that usually slow down DevOps teams past release deadlines.
DevOps Tools For Cloud Cost Optimization, Intelligence, And Solutions
Cloud cost optimization is about optimizing cloud resources to reduce waste and maximize value. However, cloud cost intelligence goes beyond just cost optimization to connect cloud costs to the engineering activities that generate them.
Several basic and advanced tools have emerged to help developers manage cloud costs.
Here are a few of the best DevOps tools for cloud cost optimization:
48. AWS Cost Explorer
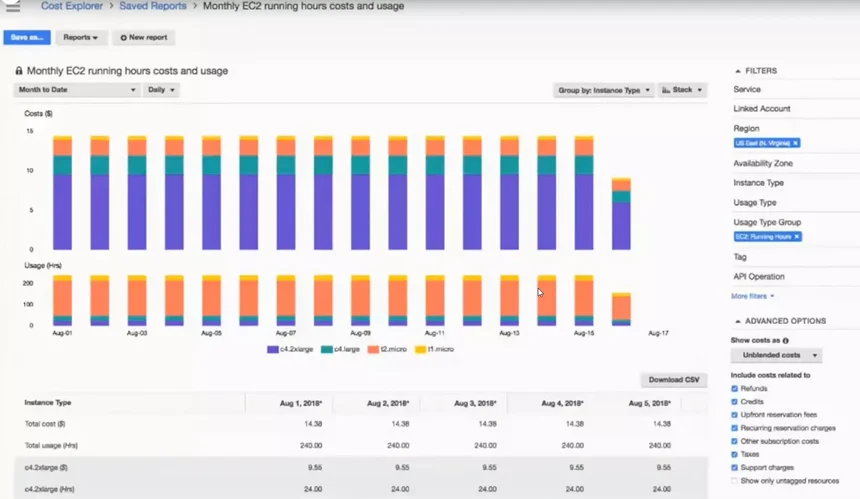
AWS Cost Explorer is native AWS cost tool enables engineers running workloads on the AWS public cloud to visualize, analyze, and manage costs and usage data to find cost optimization opportunities.
49. AWS Cost Anomaly Detection
AWS Cost Anomaly Detection is a free tool that uses advanced machine learning to identify and alert team members when unusual spending patterns occur in their AWS public cloud. It aims to help teams act quickly to prevent trending costs from spiraling out of budget or causing cloud waste.
50. Spot.io

Spot.io focuses on improving visibility, automation, and continuous cost optimization for FinOps teams in infrastructure, desktop, and container environments. The tool uses a traditional cost optimization approach, including identifying savings opportunities for on-demand, spot, and reserved instances.
51. Opsani
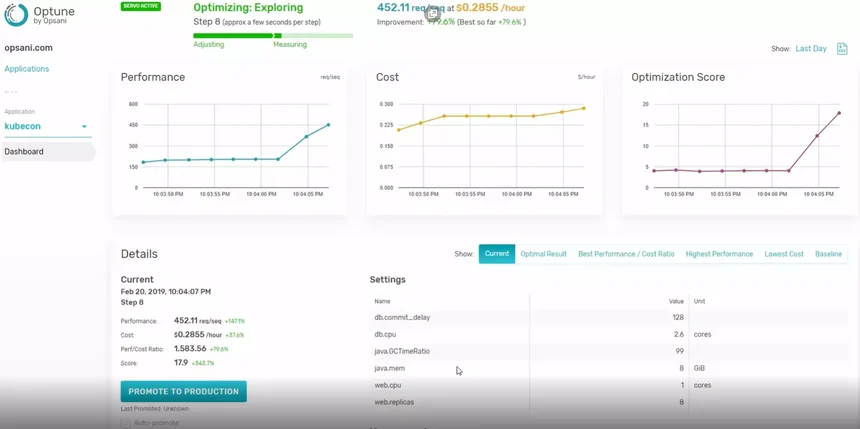
Opsani uses AI and ML to continuously reconfigure and optimize cloud workloads with every new code release, infrastructure upgrade, and load profile change. DevOps can utilize it for single application optimizations or tuning entire runtime environments.
52. ProsperOps

ProsperOps offers continuous optimization as a service by helping teams find opportunities to reduce their AWS bill. It does this by blending its algorithm with AWS Reserved Instances and Savings Plans, revealing where to minimize waste.
53. Kubecost
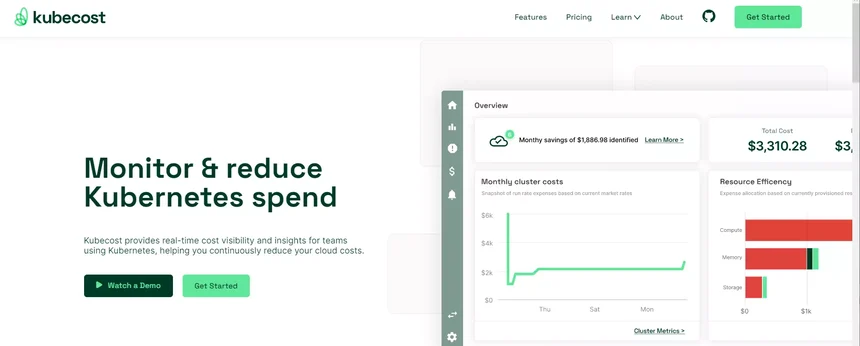
Kubecost, a cost monitoring and governance platform for Kubernetes, is a good choice for DevOps teams that want to reduce infrastructure outage risks. It also offers suggestions for cost optimization and sends alerts when costs rise. Teams can also leverage Kubecost for Kubernetes cost allocation because it breaks down Kubernetes costs by several Kubernetes concepts, such as service, deployment, and namespace label.
54. GitLab (Cluster Cost Optimization Project)
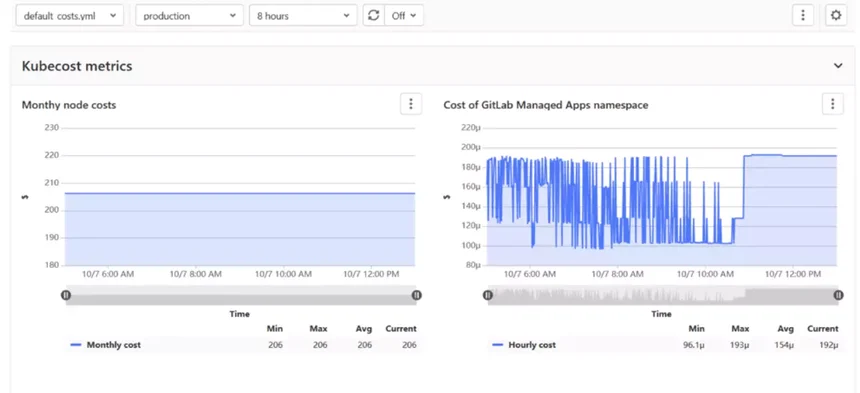
GitLab (cluster cost optimization project) provides information about cluster resource utilization. Keep in mind that this feature was deprecated in GitLab 14.5, so it is only helpful for teams with an earlier version.
55. Replex.io
Cisco’s Replex.io promises to help DevOps teams enhance their FinOps programs with showback, chargeback, and shameback features. This can help engineers and finance professionals to connect Kubernetes costs to departments, teams, and applications.
56. CloudZero
CloudZero is the cloud cost intelligence platform that empowers DevOps engineers, finance, and executives to understand the cost of the systems they are building — as they are building them.
Cloud cost intelligence goes beyond cloud cost management and optimization by correlating costs with the processes that generate them. Such processes include deployments and testing projects. Notice how CloudZero marks cost spikes with a black bar line in the image below:
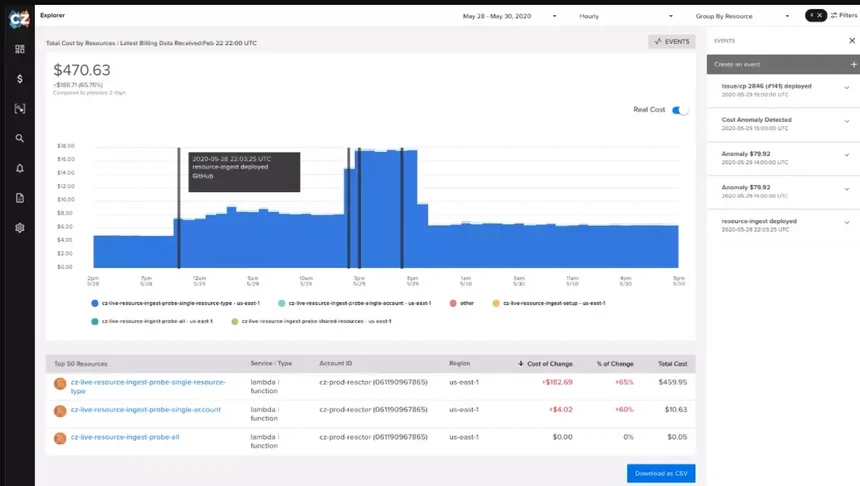
Engineers and DevOps teams love CloudZero because it presents cost data as cost per feature, cost per deployment, cost per product, cost per Kubernetes cluster, cost per dev project, and even cost per team.
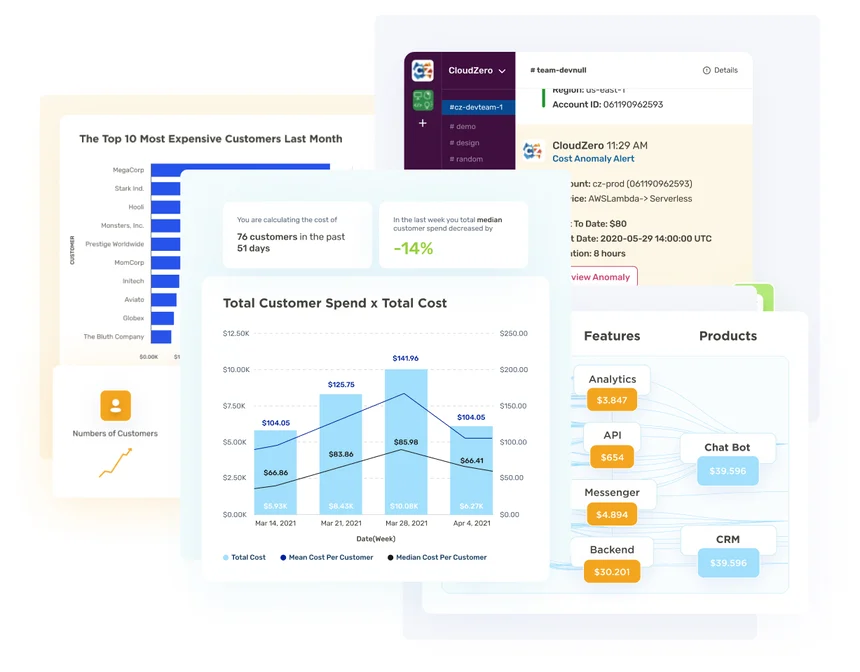 This granular cost insight helps make cost a priority metric in the software development process — along with security and other critical metrics. Analyzing and correlating processes and costs gives DevOps teams greater control over managing costs, resulting in more profitable software applications.
This granular cost insight helps make cost a priority metric in the software development process — along with security and other critical metrics. Analyzing and correlating processes and costs gives DevOps teams greater control over managing costs, resulting in more profitable software applications.
DevOps Teams Love CloudZero’s Cloud Cost Intelligence
CloudZero covers the full spectrum of cloud costs, analyzing complex workloads — including Kubernetes cost analysis — to provide engineers with the necessary data to build cost-efficient software.
CloudZero empowers DevOps teams by helping them:
- See all the features and products you care about without endless tagging in AWS.
- Correlate cost with DevOps events like deployments.
- Detect cost spikes in product features, teams, projects, and more with our cost anomaly engine.
- Only receive the most relevant alerts once or twice a week — or only when truly necessary.
- Drill down to unit cost, such as cost at the Kubernetes pod, or zoom out to see the bigger picture.
- Receive automatic and quick cost alerts via Slack and email to prevent overspending.
- Alert teams to cost anomalies and identify the source of the issue, so teams can address them quickly to limit waste.
- Use cost mapping to see how your cloud spend aligns with your business strategy and objectives — and how to align it with what matters most for your company.
Schedule a demo today to see CloudZero in action.











