
The inevitable happened. A while back, Gartner projected that in 2026, 30–50% of all new SaaS product features would use LLM inference. That meant OpenAI-style costs would become a standard part of SaaS COGS.
Today, OpenAI has become one of the most operationally significant line items for SaaS companies. But for many teams, this creates an uncomfortable gap.
Engineering sees OpenAI as a fast path to innovation. Finance sees it as a variable cost center that doesn’t map cleanly to teams, features, or customers.
And even though everyone agrees AI is a competitive advantage, nobody wants surprise invoices that make budgeting, forecasting, and margin planning impossible.
In this guide, we’ll share exactly how its pricing works today, what drives the cost variations, and how you can track OpenAI spend with confidence.
Why Tracking OpenAI Spend Matters So Much Today
If you’re not tracking your OpenAI spend at a granular level, it’s almost impossible to see when your usage patterns, and therefore costs, drift into unsustainable territory.
But with the right visibility, you can catch the trends early and address inefficiencies before they turn into overspending.
Also, McKinsey reports that 88% of software companies now use generative AI in at least one production workflow, and nearly 40% rely on OpenAI or OpenAI-compatible models.
When so many teams and features contribute to the bill, attributing your AI costs accurately becomes essential.
Yet visibility remains limited
The FinOps Foundation shows that 71% of companies reported AI/ML cost overruns in 2025, and 48% said generative AI was their least predictable cloud category.
In addition, OpenAI invoices only show total usage and model-level token counts, not which specific customers, features, or workflows generated the spend. That’s why only 32% of companies allocate even half of their OpenAI bill, according to CloudZero data.
Yet, without AI cost visibility, tracking, and attribution, it’s tough to model marginal cost, identify expensive workloads early, or evaluate the unit economics of scaling an AI feature.
AI costs are also rising faster than revenue in many SaaS companies, so tracking OpenAI spend is now mission-critical.
Report
Finance needs to prove AI’s return: CloudZero report
260 senior finance leaders (more than half CFOs) told us why the speed of seeing AI spend, not the size of it, separates who pulls ahead on AI from who gets burned.
Understanding the OpenAI Cost and Usage Model (2026 Edition)
OpenAI charges for tokens. These are the units that represent both what you send to a model and what the model generates in return.
We’ve covered in depth how OpenAI pricing works in this guide, including the models, features, and costs to know. But here’s a quick recap.
The three components that shape OpenAI pricing are:
Input tokens
These include system instructions, user prompts, conversation history, and any retrieved context added by your application. Even small changes to prompt design or context window size can meaningfully increase your token volume.
Output tokens
Models often return more tokens than they receive, especially in tasks like summarization, rewriting, or structured outputs. OpenAI’s own documentation makes it clear that output behavior is a major driver of total cost.
System-generated tokens
When using function calling, JSON mode, or multimodal inputs, OpenAI adds metadata and structural tokens automatically. These count toward your bill even if your engineers never write them directly.
Model selection also matters.
- Lightweight models cost less per token but may require more retries or generate longer outputs.
- More capable models may cost more per token but handle tasks efficiently.
- Multimodal inputs (images, audio, or video) further increase token usage because OpenAI converts them into token representations internally.
Finally, AI applications increasingly rely on pipelines and multi-model routing, which chain several LLM calls together. That means your AI costs can multiply quickly unless you monitor your usage in real time.
Here’s how to do that automatically with cloud cost intelligence.
How to Track OpenAI Spend Accurately, In Real Time, And With Confidence
This is the same approach we used internally to uncover more than $1.7 million in annualized savings across our own infrastructure.
It’s also the approach teams at Grammarly, New Relic, Skyscanner, and others rely on every day. And it’s the same framework PicPay used to save $18.6 million in recent months.
We call this approach Cloud Cost Intelligence.
It gives you the ability to understand the who, what, and why behind your AI spend. And it’s the level of clarity that engineering, product, and finance teams already expect for the rest of their cloud environment.
Here’s how this approach applies directly to tracking your OpenAI spend, accurately, and in real time.
1. Start by enriching every OpenAI call with the metadata that matters
The first thing you’ll want is to understand your cost drivers at a granular level. For that, tag your OpenAI usage with the metadata your business actually runs on:
- Feature (such as semantic search, summarization, and AI assistant)
- Team or service owner
- Customer or tenant ID
- Environment (prod, staging, QA)
- Prompt version
- Model used
- Workflow type (such as agent step, function call, or embeddings)
With these, your LLM spend becomes immediately explainable. Instead of a single line item labeled “OpenAI,” you can see the exact people, processes, and products driving your costs.

It is the same way we map cloud resources to products and customers today. And inside CloudZero, you can track your OpenAI spend exactly this way, in real-time and with hourly reports for further analysis, like this:

2. Unify all your AI-related costs into one model
LLM-powered workloads often include more than just OpenAI calls. They often include:
- Embeddings generation
- RAG retrieval
- Vector database operations
- GPU inference
- Multi-model routing, and
- Agents performing multi-step tasks.
Here, use the AnyCost engine to unify all of these into a single model. It’ll help you view your AI costs holistically, not in fragmented dashboards. And this will hand you a complete, apples-to-apples view of your AI ecosystem. All in one place.
3. Attribute your OpenAI spend to specific projects, services, and customers
Once you’ve enriched and normalized your usage data with CloudZero, the next step is to break your OpenAI bill into the dimensions your business cares about.
With CloudZero, you can view your OpenAI costs at a level of granularity you’ve not seen before, including:
- Cost per AI model
- Cost per user
- Cost per customer or tenant
- Cost per SDLC stage
- Cost per AI service, and more.
Check this out:
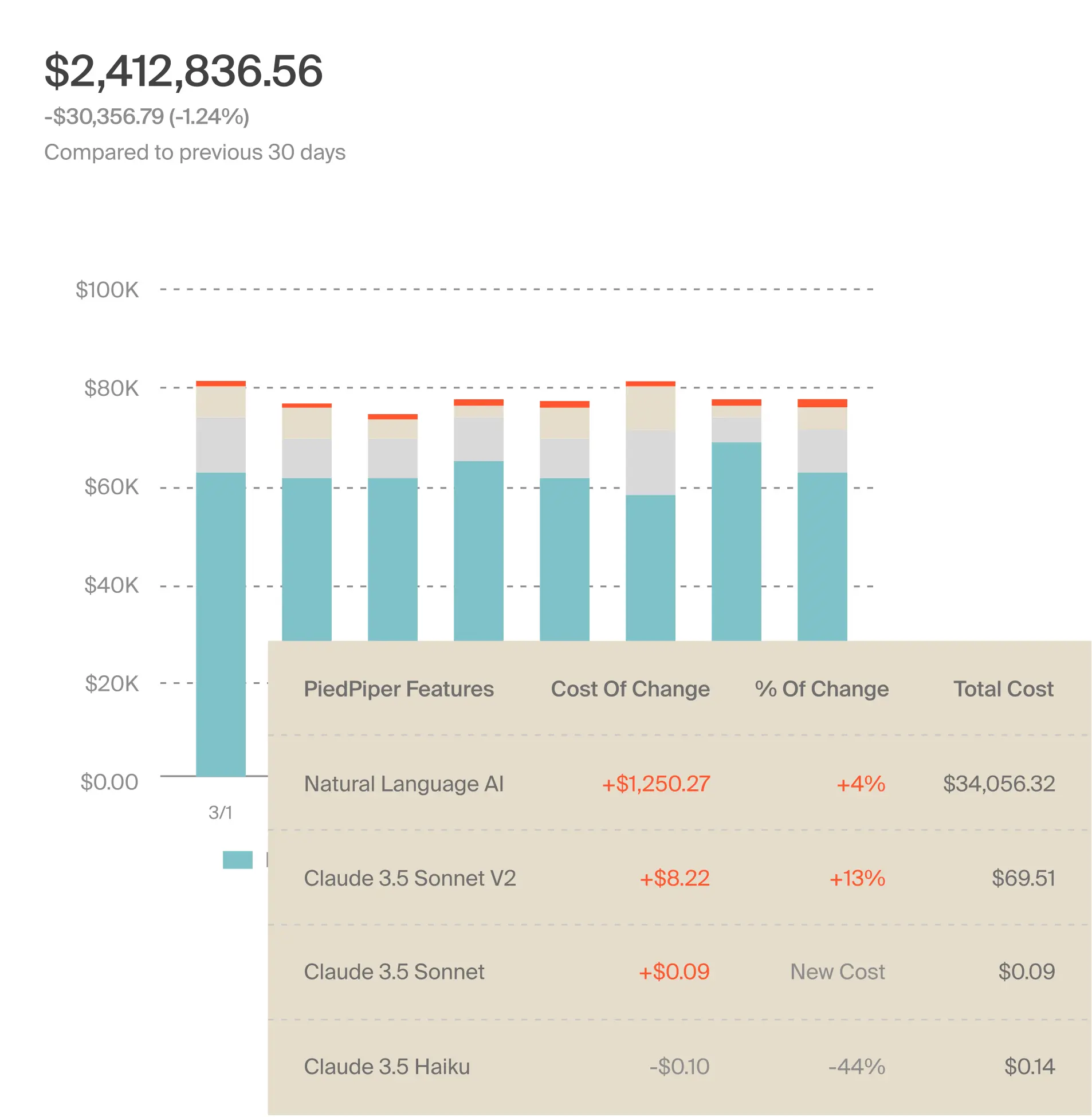
This approach instantly helps you reveal:
- Which AI features and services are trending costs up
- Which customers are consuming disproportionate AI resources
- Where margin erosion is coming from exactly
This is also where CloudZero’s unit economics capabilities really help because you get to understand the true cost-to-serve of every AI-powered experience in your product. And that means you can tell how to price the products in a way that protects your margins.
4. Detect prompt and context drift automatically
As you’ve probably noticed, most AI cost growth isn’t caused by sudden events but by gradual drift:
- Your prompts expand
- Context windows increase
- Engineers add more examples
- Retrieval injects more data
- Outputs get longer
You can catch this in CloudZero, too. The platform automatically surfaces trends and anomalies in your token usage so you can see when a particular feature or team’s costs start behaving unexpectedly.
For example, you might see:
- A 5% daily rise in tokens for a specific endpoint
- A prompt version that suddenly generates longer outputs
- A spike in ingestion costs for embeddings
- A model switch that changes cost per request
Instead of teams discovering this at invoice time, they see it in real time, so they can fix it before overspending happens.
5. Catch spikes and anomalies before they become incidents
While most cost growth is gradual, LLM workloads are also prone to sudden, unexpected cost events. Think of agent loops, retry storms, and context window blow-ups, for example.
You can catch these events in time with a real-time anomaly detection engine, like this:
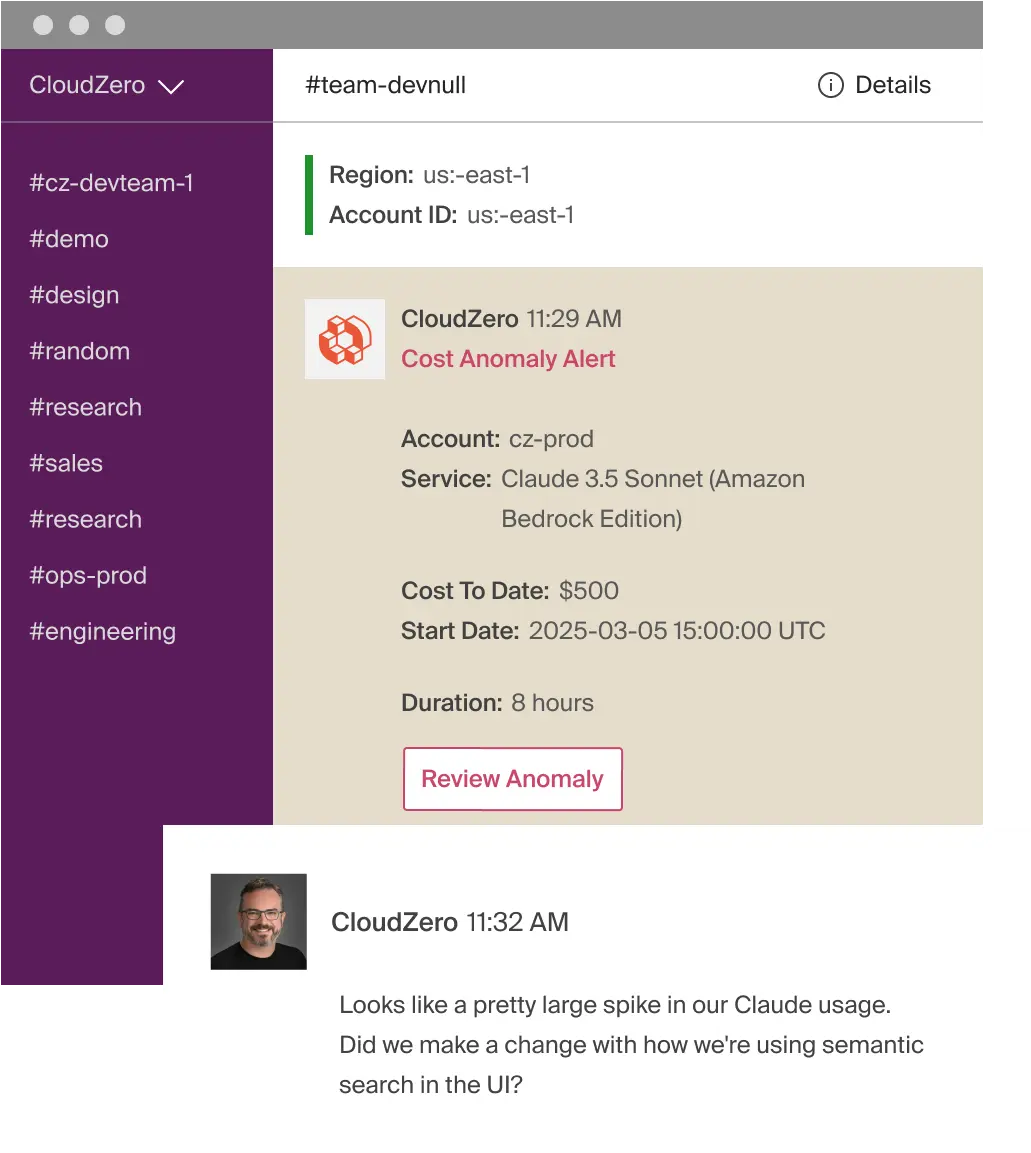
CloudZero detects these unusual OpenAI spending patterns at the model, feature, and customer level — not just at the aggregate level. And this gives your team the time to fix runaway behavior before a small issue becomes an expensive billing incident.
6. Expose cost insights to engineering where they work
CloudZero also integrates with Slack, Jira, and engineering dashboards. This gives your technical team immediate visibility into how their changes affect AI costs, right inside the tools they already use.
Take Cost per Deployment, an out-of-the-box CloudZero insight that shows you how a specific release impacts your budget.
If a deployment suddenly increases token usage or drives up OpenAI spend, your engineers will receive an alert, like this:
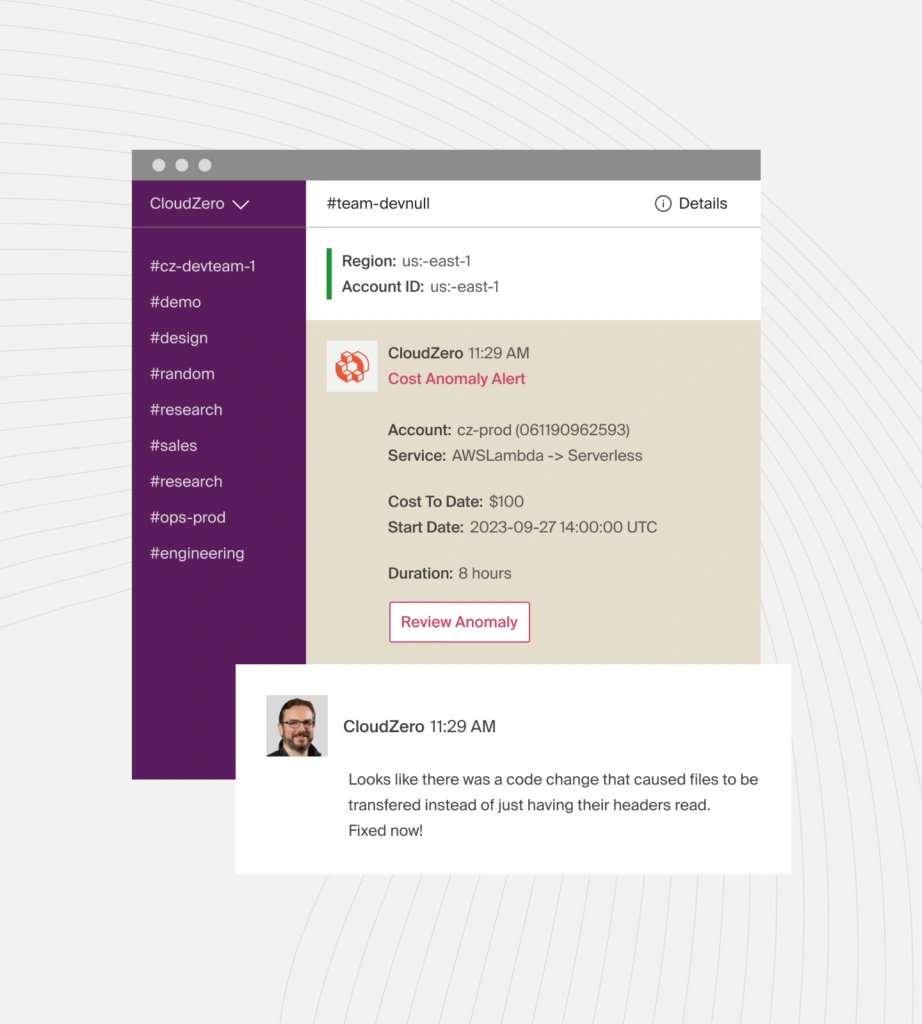
They can then investigate the code, prompt changes immediately, and architect a more efficient approach.
This helps you shift AI cost awareness from a finance afterthought to an engineering habit.
Engineers get clear, actionable cost context without needing to become FinOps experts. And because everyone can see the financial impact of their work, alignment between Engineering and Finance becomes natural.
Resources:
7. Build AI unit economics and forecasting models that actually work
Traditional cloud forecasting doesn’t work for token-based AI billing. With CloudZero, you can use your actual usage patterns to model:
- Cost per token
- Cost per inference
- Cost per user session
- Marginal cost per customer
- Expected AI cost growth based on adoption
- Scenario planning for new features
This gives your finance folks and FP&A realistic models rooted in real engineering behavior, not guesswork.
CloudZero Turns OpenAI Cost Tracking Into A Real-Time Intelligence System
When you can tie your OpenAI usage and costs to the specific customers, features, and engineering decisions that drive it, everything else becomes easier.
Engineering experiment with cost confidence. And your product team scales AI with intention.
CloudZero’s Cloud Cost Intelligence empowers you to turn every OpenAI call into an insight, every feature into a measurable cost center, and your AI spend into something you can track, explain, and optimize — all in real time.
Industry leaders like Duolingo, Drift, and Moody’s already use CloudZero to get ahead of cloud cost complexity.
Ready to get ahead of your OpenAI spend and build AI features that scale profitably?It’s free.  to see how you can also bring clarity and profitability to your AI costs.
to see how you can also bring clarity and profitability to your AI costs.
Frequently Asked Questions About Tracking OpenAI Spend
What is CloudZero’s Cloud Cost Intelligence for OpenAI cost analysis?
It is a unified approach to understanding your OpenAI spend in real time. It enriches every API call with the business context behind it (like AI features, customer, team, environment, model, and the workflow), so you can see exactly where your LLM budget is going and why.
Why is my OpenAI bill growing faster than my usage?
Factors like expanding prompts, larger context windows, and longer model outputs can inflate your OpenAI costs even when call volume stays flat. LLM workloads also tend to compound when moved into production.
What’s the best way to track OpenAI spend in real time?
You need to enrich each request with metadata such as customer, feature, team, environment, model, and prompt version. CloudZero does this automatically, so you can see exactly who or what is contributing to your costs and why.
How do I know which features or customers are driving most of my LLM costs?
View your OpenAI costs in granular views, such as per service, AI model, SDLC stage, user, feature, and more. This way, you’ll understand the true cost-to-serve of your AI services.
How do I reduce OpenAI costs without harming product quality?
Also, most teams find that meaningful savings come from fixing specific cost drivers (targeted optimizations). So, treat each driver like a lever you can pull based on its impact on your product’s quality, margins, budget, etc.
How can engineering and finance stay aligned on OpenAI costs?
Provide them with a shared, real-time source of truth. In CloudZero, both teams can see cost insights directly in Slack, Jira, and engineering dashboards, meaning they see the same signals at the same time.
How do I forecast OpenAI costs reliably?
Start by understanding your unit costs, like cost per workflow, cost per customer, and your marginal cost curves. CloudZero, in particular, uses your actual usage patterns to build realistic forecasts grounded in real engineering behavior, not averages or assumptions.
How does CloudZero handle multimodal or agent-based workloads?
We normalize all your AI-related spend (OpenAI calls, embeddings, vector database operations, GPU inference, and multi-step agent pipelines) into a single, unified model. This gives you a complete picture of costs across your entire AI architecture.
Why can’t I just use OpenAI’s usage dashboard?
OpenAI’s dashboard is helpful for seeing aggregate token counts and model usage, but it doesn’t answer critical business questions like:
- Which customers are expensive to serve?
- Which features are causing margin erosion?
- How did yesterday’s deployment affect spend?
- Which prompts or models are drifting upward?
For that, you need a platform that ties token usage to business context.
How quickly can I see ROI from CloudZero?
While every organization is different, many CloudZero customers begin identifying optimization opportunities within the first 14 days — sometimes even in the first few hours. See for yourself .











