
Quick Answer
Claude Mythos is now available to the public through Claude Fable 5, released June 9, 2026. Claude Fable 5 pricing is $10 per million input tokens and $50 per million output tokens, exactly 2x Claude Opus 4.8 ($5/$25). Claude Mythos 5 (the restricted Project Glasswing version) has identical pricing. Prompt caching cuts input spend by 90%. Batch API pricing is $5/$25 (50% off).
In April 2026, Anthropic announced a model it said was too dangerous to release. Claude Mythos could find vulnerabilities in “every major operating system and every major web browser.”
Mozilla used the Claude Mythos Preview to patch 271 Firefox vulnerabilities in two weeks. Employees at Calif.io used it to create a memory corruption exploit affecting Apple M5. The NSA used it despite the Pentagon blacklisting Anthropic over a separate dispute. Access was restricted to a handful of companies through Project Glasswing at $25 per million input tokens and $125 per million output tokens.
On June 9, 2026, Anthropic released the public version. They called it Claude Fable 5. Same model. New safety classifiers. And a 60% price cut. The Claude Mythos release date for general availability was the same day: Claude Mythos 5 became the official restricted-access version at the new $10/$50 rate, while Claude Fable 5 became the public equivalent with safety guardrails for cybersecurity, biology, and chemistry queries.
For finance teams, the question is not “what can it do.” The question is “what will it cost the organization when 200 engineers start using the most expensive model on the market, and how does the team track if the premium produces a return.” That is an AI ROI question, and it is what CloudZero, The AI ROI Company, was built to answer.
This guide covers every Claude Mythos pricing tier: API rates, subscription plans, batch discounts, prompt caching math, cloud provider rates, when the 2x premium is worth the investment, and what it means for AI spend.
What is Claude Mythos?
Claude Mythos is a Mythos-class large language model developed by Anthropic for advanced reasoning, cybersecurity vulnerability detection, long-horizon agentic work, and complex coding tasks.
It ranked highest in the AISI 2026 evaluation based on early Claude Mythos benchmarks, ahead of Claude Opus 4.8, GPT-5.4, and GPT-5.3 Codex. The Anthropic Mythos AI model was first disclosed publicly on March 26, 2026 through leaked blog post drafts, then officially announced on April 7.
Anthropic Mythos exists in three versions:
- Claude Mythos Preview (April 2026). The original restricted model. Priced at $25/$125 per million tokens. Available only to approved Anthropic Project Glasswing partners. No safety classifiers. No longer the current version.
- Claude Mythos 5 (June 9, 2026). The updated restricted model. Same capabilities as the Preview but with new pricing: $10/$50 per million tokens. API model ID: claude-mythos-5. Still restricted to Project Glasswing partners. No safety classifiers on cybersecurity, biology, and chemistry queries.
- Claude Fable 5 (June 9, 2026). The public version. Same underlying model as Mythos 5 with the same pricing ($10/$50). The Claude Fable 5 API model ID is claude-fable-5. Available to everyone via the Claude API, claude.ai, AWS Bedrock, Google Vertex AI, and Microsoft Foundry. Includes safety classifiers that block high-risk responses. This is the version most teams will use.
(For anyone searching what is Claude Mythos or what is Anthropic Mythos: the short answer is that Claude Mythos AI is the model and Anthropic Fable is the brand name for its public release. Same model. Different access levels. Same price.)
Key specifications for Mythos Claude and Fable 5:
- 1-million-token context window (5x Opus 4.8’s 200K)
- 128,000 max output tokens (4x Opus 4.8’s 32K)
- Always-on adaptive thinking (extended thinking cannot be disabled)
- 30-day data retention required (not available under zero data retention)
- New tokenizer (Opus 4.7+): up to 35% more tokens for the same text vs earlier models
That tokenizer detail matters for budgeting. A prompt that runs $5 on Opus 4.8 could run $13.50 on Fable 5: the 2x rate multiplied by up to 35% more tokens. The cost optimization section below covers how to manage this.
For how Fable 5 and Mythos 5 compare to OpenAI’s models and other providers on a per-token basis, see CloudZero’s LLM API pricing comparison.
Report
Finance needs to prove AI’s return: CloudZero report
260 senior finance leaders (more than half CFOs) told us why the speed of seeing AI spend, not the size of it, separates who pulls ahead on AI from who gets burned.
Complete Claude Mythos pricing breakdown
Here’s the API pricing (per million tokens):
| Model | Base input | 5-min cache write | 1-hour cache write | Cache hit | Output | Batch input | Batch output |
| Claude Fable 5 | $10.00 | $12.50 | $20.00 | $1.00 | $50.00 | $5.00 | $25.00 |
| Claude Mythos 5 | $10.00 | $12.50 | $20.00 | $1.00 | $50.00 | $5.00 | $25.00 |
| Claude Opus 4.8 | $5.00 | $6.25 | $10.00 | $0.50 | $25.00 | $2.50 | $12.50 |
| Claude Sonnet 4.6 | $3.00 | $3.75 | $6.00 | $0.30 | $15.00 | $1.50 | $7.50 |
| Claude Haiku 4.5 | $1.00 | $1.25 | $2.00 | $0.10 | $5.00 | $0.50 | $2.50 |
Three other things stand out. Fable 5 and Mythos 5 are identically priced (Anthropic charges no premium for the safety classifiers and no discount for their absence). The cache hit rate ($1.00/MTok) is 90% cheaper than the base input ($10.00/MTok), which makes caching the single biggest lever on any Fable 5 bill. And the batch API (50% off) drops Fable 5 to Opus-equivalent pricing ($5/$25) for any workload that does not need real-time responses.
Those are the API rates. Subscription plans tell a different story, and one with a deadline attached.
Subscription plan pricing
| Plan | Fable 5 access | After June 23 | Notes |
| Pro ($20/month) | Included through June 22 | Credits required | Fable 5 counts as 2x usage |
| Max 5x ($100/month | Included through June 22 | Credits required | Fable 5 counts as 2x usage |
| Max 20x ($200/month) | Included through June 22 | Credits required | Fable 5 counts as 2x usage |
| Team Standard ($25-30/seat/month | Included through June 22 | Credits required | Fable 5 counts as 2x usage; min 5 seats |
| Team Premium ($100-125/seat/month) | Included through June 22 | Credits required | Includes Claude Code; min 5 seats |
| Enterprise (custom) | Included through June 22 | Credits required | Fable 5 counts as 2x usage |
| API (consumption) | Available now | No change | $10/$50 per MTok, straight billing |
The June 22, 2026 deadline matters. After that date, every Fable 5 interaction on a subscription plan draws from a credit pool that Anthropic has not yet fully detailed. For teams running production workloads, the API (consumption-based) is more predictable.
The subscription table also explains why AI spend on Anthropic models is about to shift. Every engineer on a Pro or Max plan currently has unlimited Fable 5 access. In 12 days, that changes. Teams that do not track which developers use Fable 5 (vs Opus or Sonnet) will discover the shift on the next invoice, not before it.
Cloud provider availability
| Provider | Model ID | Pricing | Notes |
| Claude API (direct) | claude-fable-5 | $10/$50 per MTok | Primary access path |
| AWS Bedrock | Available | Bedrock rates | Regional endpoint: 10% premium |
| Google Vertex AI | Available | Vertex rates | Regional vs global options |
| Microsoft Foundry | Available | Foundry rates | Newest integration |
| GitHub Copilot | Rolling out | Copilot plans | Pro+, Max, Business, Enterprise |
For teams running inference on multiple cloud providers, the same prompt can produce different bills on Bedrock vs Vertex vs direct API due to regional pricing and platform margins.
CloudZero, The AI ROI Company, normalizes these costs across providers. That normalization also covers the full Anthropic API pricing and Claude API pricing model alongside OpenAI and every other provider in the stack.
As Anthropic warned when expanding Project Glasswing, the advantage will belong to the side that can get the most out of these tools.
For finance teams, getting the most out of Fable 5 means understanding the spend before it scales. These five tactics determine which price your team actually pays.
5 ways to reduce Claude Mythos / Fable 5 AI spend without downgrading
Fable 5 at $10/$50 per million tokens is the most expensive publicly available LLM. But cost per token is the wrong unit for evaluating AI spend. What matters is cost per finished task. On complex, multi-step work, Fable 5 often finishes in fewer turns and fewer total tokens than Opus, which means the effective spend gap narrows or inverts.
Here are the five levers that control the actual bill.
- Prompt caching (biggest lever, 90% savings on repeated context). Fable 5’s cache hit rate is $1.00/MTok vs $10.00/MTok base input. For agentic sessions that reuse a system prompt and tool definitions across many turns, this single setting cuts the input bill by 80-90%. On a 4-hour Claude Code session, the difference between caching on and caching off is roughly $25 vs $80. CloudZero’s Claude Code Plugin tracks spend for these sessions in real time. For Claude Code agentic workflows, Fable 5’s reasoning often justifies the premium, but only if caching is active.
- Batch API (50% off for async work). Fable 5 batch pricing is $5/$25, identical to Opus 4.8 real-time pricing. For workloads that do not need instant responses (data processing, document analysis, code review at scale), batch Fable 5 delivers the most powerful model at Opus prices.
- Model routing (use Fable 5 only when it earns the premium). Not every prompt needs the most expensive model. Route complex, long-context, multi-step tasks to Fable 5. Route simple classification, extraction, and short-context tasks to Sonnet 4.6 ($3/$15) or Haiku 4.5 ($1/$5). If the task fits in 10K tokens and has a clear right answer, Sonnet handles it at one-third the spend.
- Output token limits (cap the verbose responses). Fable 5 will happily produce a 30,000-token response if uncapped. At $50/MTok, that single response costs $1.50. Most tasks do not need 30K tokens. Set max_tokens to the minimum that maintains quality. The savings compound across thousands of API calls.
- Context management (avoid the 1M-token trap). Fable 5’s 1-million-token context window is five times larger than Opus 4.8. That does not mean every prompt should fill it. Larger contexts mean more input tokens, which means higher spend per request. Feed only the context the model needs. For how these tactics fit into a broader AI spend optimization strategy, see CloudZero’s guide.
When the 2x premium is worth the investment (and when it is not)
The spend optimization tactics above control the bill. This section answers the question behind the bill: is paying 2x the Opus rate a good investment? This is where Claude Mythos pricing connects to AI ROI.
| Scenario | Fable 5 justified? | Why |
| Complex multi-step agentic workflows | Yes | Fable 5 completes in fewer turns, often costing less than Opus total |
| Long-context analysis (100K+ tokens) | Yes | 1M context window eliminates chunking. Opus cannot process above 200K. |
| Cybersecurity code review | Yes | Mythos-class vulnerability detection. No other model matches this capability. |
| Short-context classification or extraction | No | Sonnet 4.6 at $3/$15 handles this at 70% less with comparable accuracy |
| High-volume, predictable tasks | No | Batch API with Opus ($2.50/$12.50) is 75% cheaper than real-time Fable 5 |
| Rapid prototyping or experimentation | No | Use Sonnet 4.6 for iteration, Fable 5 for final runs only |
The pattern: Fable 5 earns the premium when the task is hard enough that a cheaper model takes more attempts or more tokens to finish. On simple tasks, the premium is pure waste.
That task-level decision helps individual developers. Finance leaders need a different view: what does Mythos-class spend mean for the organization’s AI spend as a whole?
What Claude Mythos means for your AI spend
A developer evaluating Fable 5 sees the per-token rate and makes a model selection decision.
A finance leader managing AI spend across 200 developers sees something else entirely: the most expensive AI model on the market is now available to every engineer in the company, and the free subscription window closes June 23. After that date, every Fable 5 prompt generates charges at 2x the rate the team was spending on Opus. That is not a model selection question. It is a budget question. And it connects directly to AI ROI: is the premium producing value that justifies the AI investment?
CloudZero tracks AI spend at the level where this becomes answerable: per developer, per team, per model, per feature, and per customer. CloudZero was the first cloud cost platform to integrate with Anthropic and provides real-time visibility into Fable 5 spend alongside OpenAI, AWS, GCP, Azure, and 30+ other providers.
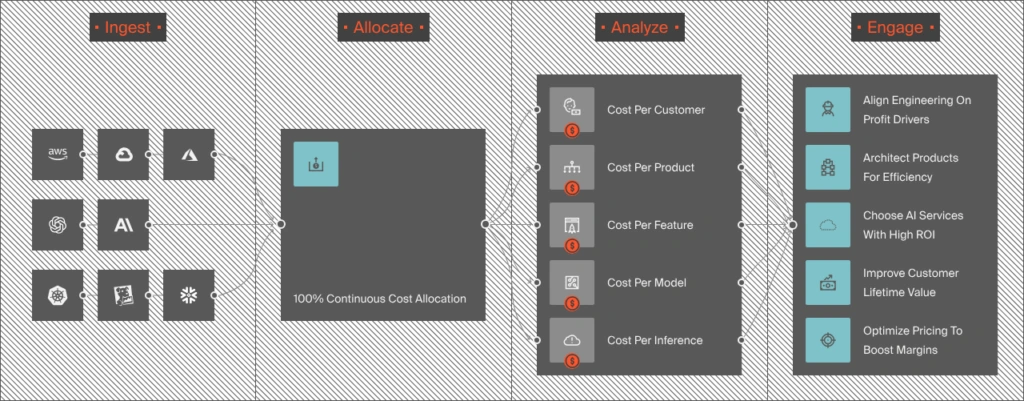
Here is what that visibility looks like in practice. Without it: “AI spend went up 40% this month.” With it: “The product team’s AI search feature switched to Fable 5 and costs $0.12 per query instead of $0.04 on Opus. Enterprise search generates $0.85 in margin per query, so the AI ROI improved. Free-tier search generates $0 and should route back to Sonnet.” That kind of analysis requires AI spend per customer visibility. CloudZero provides it through CostFormation dimensions that map every token to a team, feature, product, and customer segment. For the full framework, see CloudZero’s guide to AI spend management.
Claude Mythos is the most powerful and most expensive AI model available today. The question is not if the organization should use it. The question is which tasks justify the premium and which do not. CloudZero, The AI ROI Company, answers that with AI spend data mapped to teams, features, and customers. Schedule a demo and ask to see Fable 5 spend alongside the rest of your AI and cloud investment.
Frequently Asked Questions about Claude Mythos pricing











