
Quick Answer
Claude API pricing is per million tokens (MTok), billed separately for input and output. Haiku 4.5 costs $1.00 input / $5.00 output. Sonnet 4.6 costs $3.00 / $15.00. Opus 4.7 costs $5.00 / $25.00. Output tokens cost 5x input across all current-generation models. Prompt caching cuts cached input by 90%. Batch processing is 50% off. Model routing creates a 5–25x cost spread between tiers.
The Anthropic API pricing rate card tells you what a single token costs. It doesn’t tell you what your team is actually paying, or if that spend is justified by the output it produces. That’s a different question, and it’s the one most organizations can’t answer.
CloudZero tracks AI API costs across thousands of production workloads, including Claude; broken down by team, product, feature, and customer. Not just a monthly invoice with a number and a shrug.
This guide covers every model rate, every cost lever, real-world spend scenarios, and how to manage Claude API pricing 2026 at organizational scale. Whether you are a developer building on the Messages API, a platform engineer managing inference costs across teams, or a FinOps practitioner trying to allocate AI spend to business units, this is the definitive Anthropic Claude API pricing 2026 resource.
What Is Claude API Pricing?
Anthropic Claude API pricing is the cost developers and organizations pay for programmatic access to Claude models. Rates are charged per token through the Messages API, with input and output billed separately in millions of tokens (MTok).
Input tokens (your prompts, system instructions, and context) and output tokens (Claude’s responses) are billed separately in millions of tokens (MTok). This is a different product from Claude subscription pricing; the Free, Pro, Max, Team, and Enterprise plans for end-user chat access.
If you’re looking for Anthropic Claude Pro pricing specifically, that’s the $20/month subscription tier, not the API. API pricing is for developers building applications: chatbots, RAG systems, document processing pipelines, coding agents, and agentic workflows.
Anthropic offers three current-generation model tiers — Haiku, Sonnet, and Opus — at price points that span a 5x range. On top of those base rates, five cost levers (prompt caching, batch processing, model routing, context management, and inference routing) can compress effective costs by 30–95% below headline rates.
The gap between what you could pay and what you actually pay is enormous. Two teams running the same workload on the same model can see invoices that differ by an order of magnitude. The variable isn’t the rate card. It’s visibility into which cost levers are engaged, which are ignored, and whether the spend is delivering proportional value. That’s why CloudZero built its Anthropic integration to track effective cost-per-request, not just the sticker price.
Report
Finance needs to prove AI’s return: CloudZero report
260 senior finance leaders (more than half CFOs) told us why the speed of seeing AI spend, not the size of it, separates who pulls ahead on AI from who gets burned.
How Much Does Each Claude Model Cost Per Million Tokens?
Every Claude AI pricing guide has a pricing table. Most stop there. This one includes model IDs for your API calls, caching multipliers your finance team will want, and the full model lineage so you can calculate what migrating off legacy models actually saves.
Current-generation models:
| Model | Model ID | Input / MTok | Output / MTok | Cache write (5-min) | Cache read | Context |
| Claude Opus 4.7 | claude-opus-4-7 | $5.00 | $25.00 | $6.25 | $0.50 | 1M tokens |
| Claude Opus 4.6 | claude-opus-4-6 | $5.00 | $25.00 | $6.25 | $0.50 | 1M tokens |
| Claude Sonnet 4.6 | claude-sonnet-4-6 | $3.00 | $15.00 | $3.75 | $0.30 | 1M tokens |
| Claude Haiku 4.5 | claude-haiku-4-5-20251001 | $1.00 | $5.00 | $1.25 | $0.10 | 200K tokens |
Three patterns worth calling out. The entire Opus line from 4.5 onward sits at $5/$25, a 67% reduction from the Claude 3 Opus API pricing era at $15/$75. That migration, from Opus 3 to Opus 4.7, is the single highest-ROI line item on this page. The model your codebase inherited six months ago is probably not the model your budget should be paying for.
If you landed here searching for Anthropic Claude 3.5 Sonnet API pricing, or the related Claude 3.5 Sonnet API pricing variant, the short answer is that Sonnet 3.5 has been superseded by the 4.x line. Anthropic Claude pricing for Sonnet 4.6 matches the old $3/$15 rate but with substantially better performance and a 1M-token context window. Same price, more capability. It’s one of the few model migrations that costs nothing on the rate card.
Opus 4.7 and Sonnet 4.6 both include the full 1M-token context window at standard pricing with no surcharge. That’s unique. A 900K-token request costs the same per-token rate as a 9K-token request. In the cross-provider comparison below, this matters.
For Claude Code API pricing, the developer coding tool that burns API tokens under the hood like a teenager with a credit card, CloudZero has a dedicated Claude Code pricing guide.
Anthropic Claude Code pricing is technically just API pricing, but the usage patterns are different enough to warrant their own analysis.
Rate cards are tables. But the actual bill depends on five levers that most teams have only partially engaged, if they’ve engaged them at all.
What Are The 5 Cost Levers That Reduce Your Claude API Bill?
The Claude API cost you see on the rate card is a maximum, not a target. These five levers determine what you actually pay, and most can be engaged in under a day of engineering work. The teams that engage all five spend a fraction of what teams using none of them spend. The difference isn’t marginal. It’s the kind of gap that makes FinOps practitioners earn their salary.
1. How does prompt caching reduce claude API costs?
Anthropic prompt caching pricing follows a simple multiplier system. Cache reads cost 10% of the standard input price , a 90% discount. Five-minute cache writes cost 1.25x the base input rate. One-hour cache writes cost 2x. The five-minute cache pays for itself after one read. The one-hour cache pays for itself after two.
At scale, the savings get absurd. A RAG application with a 50,000-token system prompt processing 500 requests per day: without caching, that’s 25M input tokens daily in system prompts alone, $75/day at Claude Sonnet 4.6 pricing. With Claude prompt caching, the first request writes at $0.19, and the remaining 499 read at $0.015 each. Daily cost collapses from $75 to ~$7.69. Annually: ~$24,500 saved from one system prompt.
If your team hasn’t enabled caching, start there. A typical implementation takes 15–30 minutes: add a cache_control block to your system prompt and set the TTL. If you don’t know if your team has enabled caching, that’s the kind of blind spot that CloudZero’s Anthropic integration was built to illuminate, it tracks cache hit rates by workspace, so you can see exactly where the 90% discount is landing and where it’s being left on the floor.
Caching helps with repeated context. For work that doesn’t need a real-time response at all, there’s an even blunter instrument.
2. How much does Anthropic Batch Processing save?
The Anthropic batch API (Message Batches API) processes requests asynchronously within 24 hours at exactly 50% off all Anthropic Claude API pricing tokens. No quality difference. No model restrictions. Just half price.
It also supports up to 300K output tokens per request on Opus 4.7, Opus 4.6, and Sonnet 4.6, more than double the synchronous limits. For long-form generation at scale, batch isn’t just cheaper; it’s more capable.
Best for: document processing pipelines, nightly analytics, evaluation sweeps, content generation queues. A team processing 50,000 documents monthly at Claude Haiku 4.5 pricing: $200/month standard, $100/month batch. Same outputs. Half the invoice. The only cost is patience, which, if your finance team has seen the AI line item lately, they may be running short on.
3. How does model routing affect Claude API pricing?
Claude Haiku pricing at $1/$5 per MTok is 5x cheaper than Claude Sonnet pricing at $3/$15, and 25x cheaper than Claude Opus pricing at $5/$25. Against legacy Opus 4.1 at $15/$75, Haiku is 15x cheaper on both input and output.
The routing logic: classification, extraction, routing, and summarization go to Haiku 4.5. General-purpose coding, analysis, and content tasks go to Sonnet 4.6. Complex multi-step reasoning, agentic workflows, and tasks where quality differences are measurable go to Opus 4.7. Many teams default everything to Opus the way people default to first-class on expense reports, technically available, rarely justified.
Amazon Bedrock offers intelligent prompt routing across Claude models natively. Even a basic routing layer based on prompt length and task type drops blended cost per request by 40–60%. CloudZero tracks model mix across your workspaces, so you can see when teams are reaching for Opus on Haiku-level tasks, and quantify what that over-indexing actually costs.
4. Why does context management matter for Claude API costs?
Claude AI API pricing scales linearly with context length. Sending 200K tokens when 20K would suffice costs 10x more per request. System prompts grow over time as teams add guardrails and examples without removing obsolete ones, like a Dockerfile that only gets longer.
Practical moves: summarize long conversations instead of passing full history. Strip metadata from documents before injection. Use focused retrieval. Audit production prompts quarterly. The same discipline applies to OpenAI API costs and Gemini API pricing.
Token discipline is provider-agnostic. Token waste is also provider-agnostic. CloudZero’s cost-per-request tracking across workspaces makes bloated prompts visible, when one team’s average request costs 3x another’s on the same model, the conversation about context hygiene starts itself.
The last lever is the smallest, but it’s also the easiest to engage.
5. How does data residency affect Anthropic API pricing?
Default routing is global. US-only inference adds a 1.1x multiplier on all Anthropic pricing categories; input, output, cache writes, cache reads. Regional endpoints on AWS Bedrock and Google Vertex AI carry an additional 10% premium over global endpoints.
Unless compliance demands it, global routing saves 10% with zero quality difference. CloudZero flags when workspaces are configured for regional routing so you can verify the compliance requirement actually exists, and aren’t just paying a 10% tax because someone checked a box during setup and forgot about it.
How do these levers compound?
Sonnet 4.6 + aggressive caching + batch processing = effective input costs below $0.15 per MTok. That’s 97% below the headline Claude Opus 4.7 pricing rate. But engaging all five levers across every workspace, every team, every prompt chain requires the kind of cost visibility Anthropic’s console doesn’t provide. That’s where FinOps for Claude becomes the difference between optimized spend and educated guessing, and it’s exactly what CloudZero’s Anthropic integration delivers.
Which raises the practical question: what do these numbers look like on an actual invoice?
What Does The Claude API Actually Cost For Real Workloads?
Claude API token cost math is abstract. Monthly invoices are not. These estimates translate token rates into dollar-per-month figures based on Anthropic’s published pricing and common production patterns.
| Workload | Model | Monthly tokens (in/out) | Standard cost | Optimized (cache + batch) | Annual savings |
| Customer support chatbot (10K conversations/mo) | Sonnet 4.6 | 20M / 10M | $210/mo | $30–$60/mo | ~$1,800–$2,160 |
| Document pipeline (50K docs/mo) | Haiku 4.5 | 100M / 20M | $200/mo | $55–$100/mo | ~$1,200–$1,740 |
| Code generation agent (daily heavy use) | Opus 4.7 | 50M / 15M | $625/mo | $100–$200/mo | ~$5,100–$6,300 |
| RAG application (enterprise search) | Sonnet 4.6 | 200M / 30M | $1,050/mo | $150–$300/mo | ~$9,000–$10,800 |
| Multi-agent system (agentic workflows) | Mixed | 500M / 100M | $2,000–$3,500/mo | $400–$800/mo | ~$14,400–$32,400 |
Optimized column assumes 80%+ cache hit rates on system prompts and batch processing for non-real-time work. Actual costs vary with prompt design and model selection.
That Annual savings column is the conversation most teams haven’t had. A mid-scale RAG deployment saving $10K/year on one provider might not sound like a boardroom number, until you multiply it across every AI API and cloud service in your stack. One provider is a line item. Six providers is a budget category that nobody owns. Suddenly someone should probably know where it’s going.
CloudZero’s cost-per-customer and cost-per-feature attribution makes that calculation automatic. Not just “what did we spend on Claude?” but “what did Customer A’s support chatbot cost vs. Customer B’s document pipeline?”, and if either is worth the spend. That’s the unit economics lens that turns AI cost from a line item into a managed business input.
But before you can optimize across providers, you need to know how they compare.
Is Claude API Cheaper Than OpenAI And Google Gemini?
On raw Anthropic token cost, OpenAI is generally cheaper at equivalent tiers. GPT-5.4 at $2.50/$15.00 undercuts Sonnet 4.6 at $3.00/$15.00 on input. The newer GPT-5.5, launched April 2026 at $5.00/$30.00, matches Opus 4.7 on input but costs 20% more on output. GPT-5.4 Nano at $0.20 has no Anthropic equivalent — a gap that matters if you’re running classification tasks at volumes that would make a CDN nervous. At the budget end, OpenAI wins on price alone.
But three factors complicate the headline comparison.
- Caching convergence. Both providers now offer ~90% caching discounts on flagship models. For cache-heavy workloads, and most production apps should be cache-heavy, effective input costs converge. Claude gives finer cache control with both 5-minute and 1-hour TTL options.
- Flat-rate long context. Claude Opus 4.7 and Sonnet 4.6 offer 1M-token context at flat rates with no surcharge. Some OpenAI models apply long-context surcharges above certain thresholds. For legal review, codebase analysis, or any workload feeding large documents into the context window, flat-rate pricing matters.
- Cost-per-useful-output. A model that costs 20% more per token but requires 40% fewer retries is cheaper in practice. Measuring that delta requires unit economics at the feature level, not just Claude API pricing per token counts, exactly what AI cost optimization platforms like CloudZero track.
For the full breakdown, see CloudZero’s OpenAI API cost guide. For consumer plan comparisons, CloudZero’s ChatGPT pricing guide covers that.
The practical conclusion: most teams will run both Claude and OpenAI. The question isn’t “which is cheapest?” It’s “what’s my total AI spend across all providers, and where is it going?”, a question that requires unified visibility across every provider, which is CloudZero’s core capability.
Speaking of hidden costs, there’s one in the current Opus lineup that most teams don’t discover until the invoice arrives.
Why Does Claude Opus 4.7 Cost More Than The Rate Card Suggests?
Claude Opus 4.7 pricing lists at $5/$25 per MTok, the same as Opus 4.6. Same headline. Different bill.
Opus 4.7 ships with a new tokenizer that, per Anthropic’s documentation, “may use up to 35% more tokens for the same fixed text.” The same prompt, the same document, the same conversation history, tokenized by Opus 4.7, it produces up to 35% more tokens. “Anthropic Claude pricing change” is a phrase that usually refers to explicit rate adjustments. This one is implicit. The per-token price didn’t change. The number of tokens per request did.
A request that cost $0.10 on Opus 4.6 could cost up to $0.135 on Opus 4.7 for identical input. The impact is worst on code, structured data (JSON, XML), and non-English text. CloudZero’s Opus 4.7 pricing deep dive covers the tokenizer math across content types.
Anthropic notes the new tokenizer “contributes to improved performance”, fair enough. But you should benchmark on your own traffic before migrating. For many workloads, Claude Sonnet 4.6 pricing at $3/$15 with a stable tokenizer delivers better cost-per-useful-output than Opus 4.7 at an effective $5–$6.75 input rate. Opus 4.6 also remains available with Fast Mode at $30/$150 per MTok (6x standard) for latency-sensitive workloads.
This is the kind of cost drift that goes unnoticed for weeks, or until whoever approved the migration has moved on to a new Jira epic. CloudZero tracks effective cost-per-request through its Anthropic integration, so a tokenizer-driven cost increase shows up in real time: in the dashboard, in Slack, in the anomaly alert that fires before finance opens a ticket.
Which raises the broader question: how do you actually track Anthropic costs at scale?
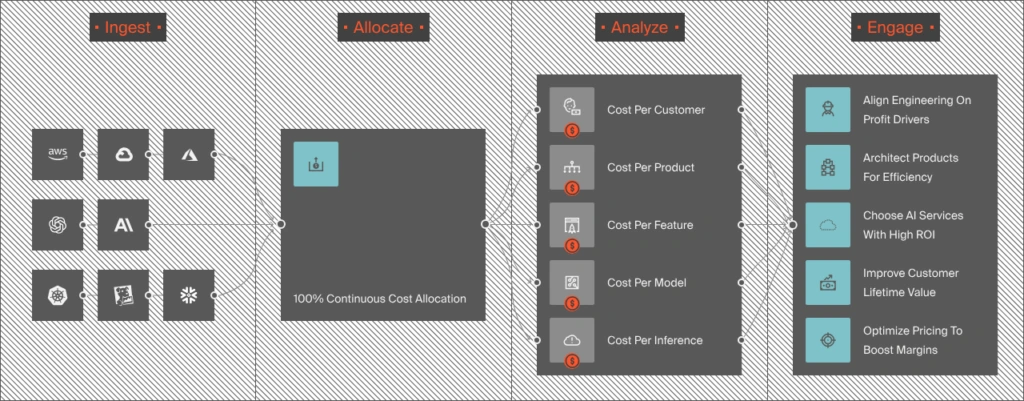
How Does CloudZero Manage And Optimize Anthropic API Costs?
Anthropic provides a Usage API and Console dashboard for basic tracking. For a solo developer, that works. For an organization running Claude alongside OpenAI, AWS Bedrock, GCP, Oracle Cloud, or SaaS platforms, and the three services somebody onboarded during a hackathon, Anthropic’s console shows one slice of a much larger cost picture. It doesn’t allocate by team, project, feature, or customer. It can’t answer “was it worth it?”
That’s the gap CloudZero fills, and it fills it as the first cloud cost platform to integrate directly with Anthropic’s Usage and Cost Admin API.
Here’s what that integration delivers:
- Token-level spend attribution. CloudZero ingests uncached input, cache hits, output tokens, and tool usage from Anthropic’s API, broken down by model, workspace, and API key. The allocation engine maps that to business dimensions: team, product, feature, customer, environment. Instead of “$12,000 in Claude API usage,” you see which features and which customer accounts generated that spend. The FinOps for Claude approach means AI spend becomes traceable to the engineering decisions that produced it.
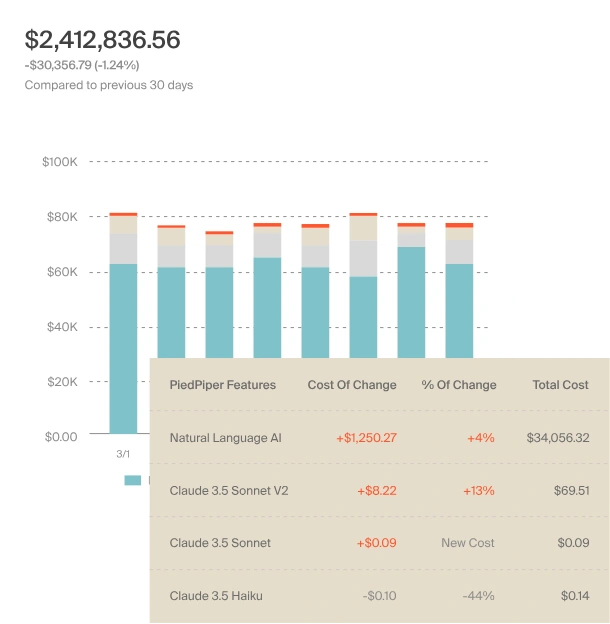
- Cost per customer, per feature, per inference. CloudZero’s unit economics engine calculates cost-per-conversation, cost-per-inference, or cost-per-customer for any Claude-powered feature. If Customer A’s support chatbot costs $0.04/conversation on Sonnet but $0.18 on Opus with no quality delta, that’s a routing fix worth $1,680/year on that customer alone. Scale that across hundreds of customers and the math gets interesting fast. That’s the “was it worth it?” question answered with data, not vibes.
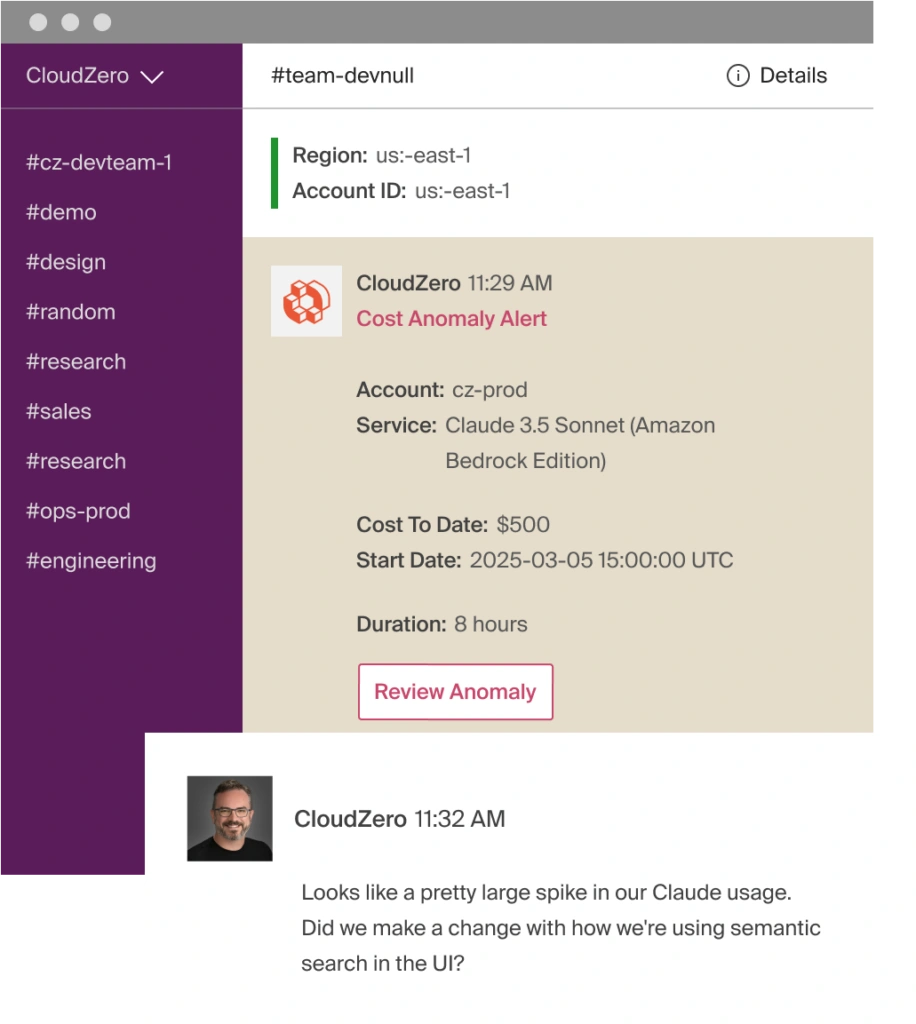
- Real-time anomaly detection. A context-window change, a prompt regression, a tokenizer surprise, an agent that went full Opus on a classification task, CloudZero sends alerts to the team that owns the affected workspace at hour-level granularity. Engineering catches the spike before finance does. That’s better for everyone.
- Caching and model mix visibility. CloudZero tracks prompt caching hit rates across workspaces. If the 90% caching discount is being captured in staging but missed in production, you see it. It also surfaces model mix, showing which teams are sending Haiku-level tasks to Opus, and quantifies what that over-indexing costs in dollars, not assumptions.
- Multi-provider, multi-cloud unification. CloudZero also integrates natively with OpenAI, AWS, Azure, GCP, and Oracle Cloud, plus SaaS platforms like Databricks, Snowflake, New Relic, and Datadog, and any source through its AnyCost API. Claude token pricing, Bedrock inference, Azure OpenAI, self-hosted GPU costs, all in one dashboard. Same business dimensions. Same unit economics. Same anomaly detection.
Organizations like Toyota, Grammarly, Skyscanner, and Coinbase trust CloudZero to manage their cloud and AI costs. The same platform tracking $15 billion+ in cloud and AI spend now brings that rigor to Anthropic Claude API pricing, with the only native Anthropic integration in the FinOps market. Schedule a demo to see CloudZero in action.
Frequently Asked Questions About Anthropic Claude API Pricing











