
Analyzing big data enables organizations to discover new opportunities and improve existing ones. Whichever cloud data platform you choose, there are two data storage technologies you will want to understand.
The two most common solutions for storing, querying, analyzing, and reporting big data are data warehouses and data lakes.
We will define what a data warehouse and data lake are, how they work, and what the differences are. By the end, you’ll have enough information to decide which data solution to go with to extract value from your data.
What Are The Different Types Of Data?
You will probably only ever deal with four types of data, whether you are a data specialist or CTO; structured, semi-structured, unstructured, and metadata.
1. Structured data
Structured data refers to stored data in a standardized format, such as rows and columns, to be more easily understood. You can store, retrieve, and analyze it for specific purposes for that reason.
Examples of structured data include SQL databases and Excel files.
2. Unstructured data
Unstructured data is not organized as well and does not work within a defined data model. This makes the data not immediately ready for use unless you dig into it for a specific reason.
Examples of unstructured data include no-SQL databases, audio, video, PDF documents, and images.
3. Semi-structured data
Semi-structured data is not merely a combination of modeled and non-modeled data. Contrarily, it is the type of data that does not follow most data structures but uses tags or markers to define elements, fields, and records within itself.
XML and JSON are two examples of semi-structured data.
An increasing number of tools can help your organization query semi-structured data, such as Snowflake.
CloudZero provides Snowflake cost intelligence so you can understand your costs at every level of querying semi-structured data.
4. Metadata
Metadata is the type of data that describes other, specific data. Seem confusing?
Think of shooting a video with your smartphone camera. The phone saves the footage with additional information that is typically easy to understand, such as the date, time, and, sometimes, shooting location. Those details are examples of metadata.
Next, to understand how data warehousing and data lakes work, you’ll need to first tell how a database works.

What Is A Database?
Using a database, you can store, retrieve, and query structured data from a single source. There are proprietary and open-source databases, many of which are relational databases. Relational databases get their name from requiring schemas.
Schemas are a framework for structuring data to recognize and interpret patterns in that data. So relational databases are designed to work with structured data, coming from a single source — not raw data that varies in structure, format, and sources.
What Is A Data Lake?
A data lake is a large repository that houses structured, semi-structured, and unstructured data from multiple sources. A data lake also contains both raw data and information (processed data). It is truly a lake of data where all kinds of rivers (data types) converge.
Yet data lakes differ from data swamps.
A data swamp is a vast repository with little to no structure, making it unusable or of little use to data specialists as is.
How does the data lake architecture work?
A data lake will take the structure of a data lakehouse; it combines various tools, services, and techniques to help ingest, store, retrieve, analyze, and transform different types of data into useful business intelligence.
A typical data lake architecture will look like this:
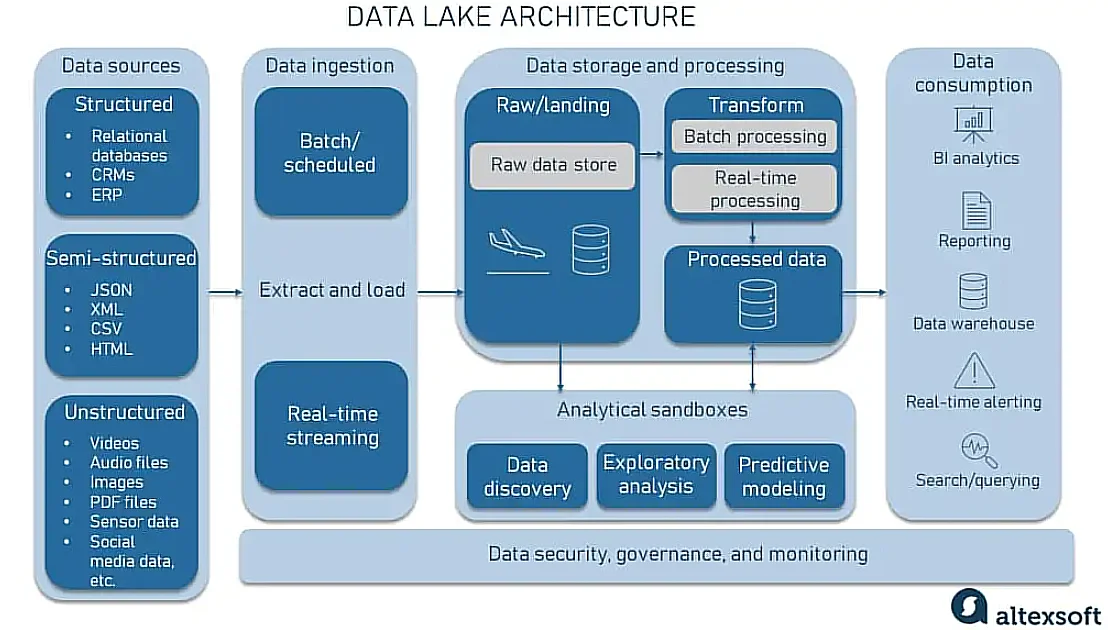
While each organization will have a unique data lake structure, the components of a data lake architecture can include:
- Resource manager – Data lakes use this to consistently allocate just the right amount of resources for a job.
- ELT – This refers to the Extract, Load, and Transform processes used to extract data from various sources and load it into the raw zone of the data lake. Data cleaning and transformation follow, enabling your apps to use the information.
- Connectors to ease access – This helps users access and share data in the form they need using a variety of workflows.
- Data classification – Supports profiling, cataloging, and archiving. These help your team track changes to content, quality, history, storage location, etc.
- Analytics service – This should be quick, highly scalable, and distributed. Additionally, it helps if it supports a variety of workload categories in multiple languages.
- Data security – Supports masking, auditing, encryption, and access control, safeguarding your data at rest or on the move.
From there, you can add any in-house or third-party lakehouse solution to extract maximum value from your data lake.
Which data do you store in a data lake?
A data lake is useful for storing all kinds of data, whether you need to analyze and report all or bits of it immediately or in the future. Data lakes are also an excellent feeding ground for big data, artificial intelligence, and machine learning programs.
However, data lakes can be tough to derive insights for everyday business needs unless you are a data specialist. This is where other types of standardized data-storing options come in.
You can also use specialized data management tools to make data more useful.
What are some example data lake use cases?
A robust data lake opens up endless possibilities for innovation in various industries, including:
- The omnichannel retailer – Today, retailers must collect, enrich, and make sense of data gathered from multiple touchpoints, including mobile, social, live chat, and walk-in/in-person. In addition to helping with marketing attribution, this can help reveal your most profitable customer segments so you can target them to improve your bottom line.
- Media streaming – A subscription-based streaming service may improve its recommendation algorithm by gathering and processing insights on customer behavior.
- Procurement and supply chain management – Organizations, such as manufacturers, can use data lakes to unify diverse sourcing, supply chain, and warehousing data (EDI systems, JSONs, XML, etc).
- Healthcare – Healthcare systems need to quickly analyze vast amounts of historical data to better personalize patient care.
- Finance – Investment firms can use a data lake to collect and process the most up-to-date market data using real-time analytics, enabling them to manage portfolio risk.
- IoT – Sensors collect enormous amounts of semi-structured to unstructured data about their surroundings. A data lake stores this information for future analysis in a centralized repository.
- Sales – Sales data engineers can use predictive models to anticipate customer behavior, improve upselling, and reduce churn.
What are the top data lake tools?
Here are some of the best data lake solutions in the market right now.
1. Amazon Web Services Data Lake
A highlight of the data lake on AWS is it is simpler to handle than most alternatives. The AWS Lake Formation service makes setting up a secure data lake quite accessible.
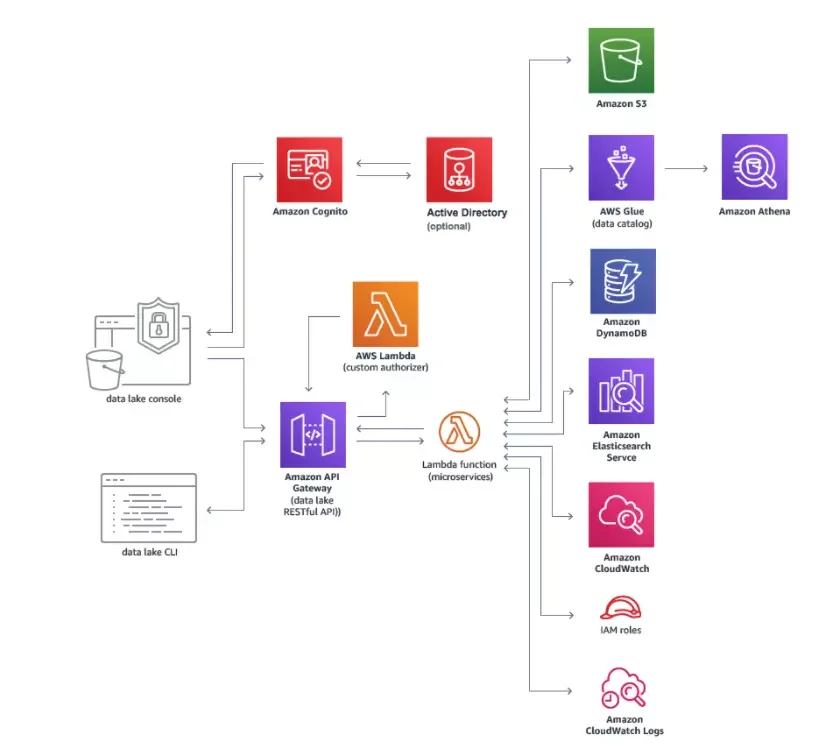
Another benefit is integrating AWS’ other solutions, such as machine learning services Amazon Redshift and Amazon EMR (for Apache Spark), with an Amazon S3 data lake that promotes convenience, data security, and centralization benefits.
2. Microsoft Azure Data Lake Storage
Another big player, Azure’s big advantage is its ability to scale to meet the most demanding workloads and maintain top performance while at it. The Azure Data Lake Storage option is also viable for its compatibility with many other data storage and querying frameworks.
3. Intelligent Data Lake by Informatica
This data lake tool is ideal if you want to harness more value from a Hadoop-based data lake. The underlying Hadoop architecture means you do not have to do much coding to query colossal amounts of data. Still, it supports other data tools such as Amazon Aurora, Microsoft Azure SQL Database, AWS Redshift, and Microsoft SQL Data Warehouse.
Other data lake solutions to look into include the open data lake solution, Qubole. There is also the infinitely scrollable data lake with a relational layer, Infor Data Lake.
What Is A Data Warehouse?
A data warehouse is a relational database that can handle, store, and bring to one place structured data sets coming from multiple sources. Data warehousing supports business decision-making by analyzing varied data sources and reporting them in an informational format.
Think of the different data sources as the various departments in your organization depositing organized data in one place. The goal is usually to help provide practical insights into an organization’s multiple operations.
Unlike a primary database, a data warehouse can handle exabytes of data and usually starts at one terabyte capacity.
Many organizations prefer to make large amounts of data accessible to employees by using a further subset of data sets known as data marts.
What are the top data warehouse solutions?
Snowflake and Amazon Redshift are some common data warehousing tools. Other top cloud data warehouse solution providers include Google BigQuery, Teradata Vantage, Oracle Autonomous Warehouse, Vertica, Microsoft Azure Synapse, Yellowbrick Data, and IBM Db2 Warehouse.
Still, some modern data solutions use a data lake architecture that can also act as a data warehouse solution.
Take Snowflake, for example.
Your organization can use Snowflake as a data lake to derive the benefits of a highly scalable and cost-efficient repository for all data types and sources with the business-ready insights of data warehousing and cloud storage. All in one place.
Alternatively, you can use a separate data lake, only employing Snowflake as a data warehouse solution for analytics and transforming your operations’ data.
What Are Data Marts?
Data marts are databases that hold a limited amount of structured data for one purpose in a single line of business.
Here is an example. A data mart can be a database of organized data for your sales and marketing department that does not exceed 100 Gigabytes (GB).
The data in a mart usually comes from a data warehouse, which makes marts widely considered a subset of data warehousing.
Comparing The Similarities And Differences Between Data Lakes And Data Warehouses
Some similarities between data lakes and data warehouses include:
- Both store large amounts of data for analysis and deriving business intelligence.
- Both store current and historical data.
But these two have more differences than they have similarities.
The most significant difference is that while data lakes hold all manner of data, processed or not, data warehouses keep only structured data. Data lakes also keep the data in a flat architecture instead of the structured database environment in a data warehouse.
Data warehousing focuses on transforming raw data into information that businesses can use for decision-making.
Warehouse data is the core of business intelligence, relying on data analysis and reporting techniques to derive meaningful insights from operations data.
Instead, data lakes form the core of Big data, AI, and ML applications for the vast amounts of data they hold from multiple sources.
When Should You Use A Data Lake Or Data Warehouse?
Data lakes are not as accessible to employees as they are to data specialists. One reason is traditional data processors do not render the data a lake contains in a way most people can understand.
However, the data in lakes does not demand as many compute resources as it takes to organize warehouse data. So data specialists find data lakes easy to access. That also makes data lakes cost-friendlier for storing vast amounts of data than data warehouses.
Data specialists can also decide when and how to model the data collected in a lake. So they can prioritize which data goes through analysis first to save costs. They can also collect data as they come up with new data modeling ideas.
Will Data Lakes Replace Data Warehouses?
If your organization produces mountains of data that you do not need to transform into insights right away, a data lake can be a good option.
But you would still need to translate that raw data into valuable and understandable information to remove the guesswork from your decision-making. That’s where data warehousing comes in.
While data lakes are the most scalable in terms of data holding capacity, a modern data warehouse can handle incredible amounts of data ready to transform it into business intelligence on-demand.
Data lake and data warehousing are not direct competitors. They are not designed to be alternatives. They complement each other. Data lakes empower data warehouses and vice versa.
That means you’ll want to look into picking the best data lake solution along with a top data warehouse solution.
Here’s How To Build Cost-Effective Data Solutions
Data lakes are ideal for organizations that have data specialists who can handle large-scale data mining and analysis. Additionally, they are suitable for organizations that want to automate pattern identification in their data using big data technologies such as machine learning and artificial intelligence.
Data lakes also help keep far-reaching data you do not need to transform right away or lack the resources to analyze immediately. Think of a data lake as a scalable online archive. On the other hand, a data warehouse makes identifying patterns in your operations so easy, that anyone with some knowledge of the topic can tell what it means.
But processing raw data to that point takes a significant investment, from the right skills and experience to having a deep understanding of the best use cases for each data storage technology.
This is why high-performing data engineering teams use CloudZero. CloudZero helps you leverage a variety of data engineering solutions, enabling you to gain a competitive advantage through business intelligence.
With CloudZero, you can:
- Understand your data cloud costs, from egress to compute to storage. Supports Snowflake, Databricks, MongoDB, Datadog, New Relic, and more platforms.
- Unify cloud provider cost data with cost insights from your data solutions. See the complete picture in a single platform — no need to create different dashboards.
- View your data platform costs in an immediately actionable format, such as Cost per Customer, per Feature, per Service, per Project, per Environment, and other cost dimensions.
- Map cloud data costs to specific products, processes, and people in your organization to uncover otherwise hidden costs. This way you can cut the unnecessary cost centers and invest more in areas that improve your bottom line.
Learn more about our Snowflake Cost Intelligence here and how it can help your team gain a more complete view of your cloud data costs.
 to see how CloudZero works like an observability tool to continuously deliver real-time cost allocation cost insights in your environment!
to see how CloudZero works like an observability tool to continuously deliver real-time cost allocation cost insights in your environment!


The Cloud Cost Playbook
The step-by-step guide to cost maturity



