

Quick Answer
Groq pricing follows a pay-as-you-go, tokens-as-a-service model. Input token prices range from $0.05 per million tokens (Llama 3.1 8B) to $0.59 per million tokens (Llama 3.3 70B), with output tokens at $0.08 to $0.79 per million. A free tier includes every model with no credit card required. The Batch API and prompt caching each cut rates by 50%, and can be stacked for an effective rate of roughly 25% of on-demand pricing. Following NVIDIA's $20 billion licensing deal in December 2025, GroqCloud continues to operate independently under new CEO Simon Edwards.
If you’ve been evaluating Groq API pricing for a production workload, or just noticed the Groq news cycle has been unusually loud since Christmas 2025, you’re in the right place. NVIDIA’s $20 billion deal reshaped the Groq company’s future, but the GroqCloud platform is still live, the pricing page hasn’t changed, and those LPU-powered AI inference speeds remain among the fastest in the industry.
What has changed is the question you should be asking. It’s no longer just “how much does a Groq token cost?” It’s “how much does my Groq-powered feature cost per customer, and is that going up or down?” Because token prices are one line on a very long receipt.
This guide covers Groq API pricing 2026 for every model, every tier, every discount, and the one question most pricing pages hope you never ask: what happens to your inference cost when it’s scattered across five providers and nobody owns the bill?
What Is Groq And Why Does Its Pricing Matter?
Groq AI is an inference company that designs custom chips called Language Processing Units (Groq LPU) for running large language models at speeds that make GPU-based providers look like they’re buffering a YouTube video in 2012.
Where a standard GPU-based provider delivers 50 to 150 tokens per second, the Groq LPU pushes 394 to 1,000 tokens per second depending on model size. The result is low latency inference, output speeds three to 10 times faster than GPU-based alternatives, that opens up use cases from conversational AI assistants to real-time voice interfaces. When your Groq models respond before a user finishes reading the loading indicator, that’s a UX advantage with real business value.
The speed comes from a deliberate architectural trade-off. Groq’s LPU eliminates branch prediction, caches, and out-of-order execution, features GPUs need for general-purpose workloads but that add latency for the sequential token generation LLMs need. Every transistor focuses on Groq inference. Nothing else.
Three constraints follow from that focus. Groq is inference-only, no training, no fine-tuning. It runs exclusively open-source AI models (Meta’s Llama, OpenAI’s GPT-OSS, Alibaba’s Qwen), no GPT-5.4, no Claude, no Gemini. And each chip contains only 220MB of SRAM, so large models get distributed across hundreds of chips.
For Groq AI pricing, this matters because Groq isn’t competing with OpenAI or Anthropic on model quality. It’s competing on speed-adjusted cost for organizations that have already chosen open-source models and need them to run fast. That’s a narrower market than the “pick any model” flexibility of Amazon Bedrock or a direct API, but within that lane, the economics are hard to beat.
One more thing to clear up before we get to numbers: the Groq vs. Grok confusion. Groq (the inference hardware company, founded in 2016 by former Google TPU engineer Jonathan Ross) is not Grok (xAI’s chatbot, built by Elon Musk’s team). They share a sound. That’s it. Your Groq bill will not include tweets.
playbook
The AI Cost Optimization Playbook
Traditional cloud cost management is broken. Here’s why — and how to make the switch to cloud cost intelligence.
What Happened With The NVIDIA Deal — And Does It Affect Groq Pricing?
Before diving into the pricing tables, let’s address the elephant wearing a leather jacket at GTC.
On December 24, 2025, NVIDIA signed a $20 billion non-exclusive licensing agreement for Groq’s inference technology, the biggest Groq news event since the company emerged from stealth. Groq’s founder and CEO Jonathan Ross, president Sunny Madra, and roughly 90% of the engineering team moved to NVIDIA. The deal was structured to avoid triggering a formal merger review, a move that has since drawn Senate scrutiny and FTC attention.
For context on the Groq valuation trajectory: the company had raised $3.3 billion in total venture funding since 2016, including a $750 million round in September 2025 at a $6.9 billion post-money valuation. NVIDIA paid nearly 2.9x that figure. If you’ve been watching Groq stock chatter in investment forums, Groq is private, so there is no public stock, the $20 billion number is what drove that conversation.
What does this mean for Groq cloud pricing right now?
GroqCloud continues operating independently under new CEO Simon Edwards (previously Groq’s CFO). Groq confirmed that “GroqCloud will continue to operate without interruption.” The pricing page is current. The Groq API works. The platform’s two million-plus developers can still build.
What it means longer-term is genuinely uncertain. The core engineering talent that built the LPU architecture now sits inside NVIDIA’s AI infrastructure division. At GTC 2026, the NVIDIA Groq partnership produced its first chip, the Groq 3 LPU, part of NVIDIA’s Vera Rubin platform. Whether GroqCloud evolves into a long-term inference platform or gradually fades depends on how aggressively the remaining team invests in the product.
For teams evaluating Groq today, the practical advice is: use it if the speed and price fit your workload, but don’t build a single-vendor dependency. Which, honestly, is advice that applies to every AI cost management decision in 2026, not just Groq.
How Much Does Every Groq Model Cost?
Here is the complete Groq model pricing table for every Groq supported model on GroqCloud, pulled directly from Groq’s pricing page as of April 2026.
Large language models
|
Model |
Parameters |
Context |
Speed (TPS) |
Input ($ / 1M tokens) |
Output ($ / 1M tokens) |
|
Llama 3.1 8B Instant |
8B |
128K |
~840 |
$0.05 |
$0.08 |
|
GPT-OSS 20B |
20B |
128K |
~1,000 |
$0.075 |
$0.30 |
|
GPT-OSS Safeguard 20B |
20B |
— |
~1,000 |
$0.075 |
$0.30 |
|
Llama 4 Scout (MoE) |
17Bx16E |
128K |
~594 |
$0.11 |
$0.34 |
|
GPT-OSS 120B |
120B |
128K |
~500 |
$0.15 |
$0.60 |
|
Qwen3 32B |
32B |
128K |
~662 |
$0.29 |
$0.59 |
|
Llama 3.3 70B Versatile |
70B |
128K |
~394 |
$0.59 |
$0.79 |
At the floor, Groq Llama 3.1 8B pricing gets you 20 million input tokens per dollar, the kind of rate that makes you briefly wonder if there’s a catch. (There isn’t, unless you count the 8B-parameter ceiling as a catch. Which, for anything beyond basic classification, you probably should.)
At the ceiling, Groq Llama 3.3 70B pricing sits at $0.59 input and $0.79 output per million tokens. For a 70B-parameter model running at nearly 400 tokens per second, that’s aggressively cheap compared to proprietary alternatives, which we’ll quantify in the comparison section.
Groq also lists Moonshot AI’s Kimi K2 in its prompt caching table at $1.00 input / $3.00 output per million tokens, the priciest model on the platform but also the strongest reasoning option.
Speech and audio models
|
Model |
Speed |
Price |
|
Whisper V3 Large |
217x real-time |
$0.111/hr transcribed |
|
Whisper Large v3 Turbo |
228x real-time |
$0.04/hr transcribed |
|
Canopy Labs Orpheus English |
100 char/s |
$22.00/M characters |
|
Canopy Labs Orpheus Arabic Saudi |
100 char/s |
$40.00/M characters |
Groq Whisper pricing and speech recognition performance deserve a double-take. Whisper v3 Turbo at $0.04 per hour is roughly 89% cheaper than OpenAI’s Whisper API at $0.006 per minute ($0.36 per hour). At 228x real-time speed, a 60-minute audio file processes in under 16 seconds. For teams transcribing thousands of hours of customer calls monthly, that’s the kind of savings that makes a finance director smile for the first time since the last cloud bill review.
How Does Groq’s Tier Structure And API Pricing Work?
The per-token rates above tell you what Groq charges. The tier structure tells you how, and the constraints you’ll actually hit in production.
Groq API cost follows a tokens-as-a-service model with no idle infrastructure charges, no reserved instance commitments, and no surge pricing during peak demand. Your cost scales linearly with token volume. If your cloud provider’s pricing page makes you feel like you need a law degree, Groq’s is refreshingly legible.
Three tiers govern access and rates:
- Groq free tier. Every model, no credit card. Rate-limited to 30 requests per minute, 6,000 tokens per minute, and 14,400 requests per day. Limits apply at the organization level, multiple API keys don’t help. Enough for prototyping. Nowhere near enough for production. To get started, generate a Groq API key at console.groq.com/keys; it takes about 30 seconds and an email address.
- Developer tier. Add a credit card (zero minimum spend) to unlock up to 10x the Groq API free tier rate limits and a 25% discount on all token costs. For teams evaluating Groq API pricing free tier options, this is the sweet spot, free to access, meaningfully cheaper per token, and enough headroom for early production.
- Enterprise tier. Custom rate limits, SLAs, dedicated support, volume pricing. Contact Groq sales.
The subtlety most teams miss: rate limits, not token price, are usually the binding constraint. A free tier with 6,000 tokens per minute means a single long prompt can consume half your per-minute budget in one request. The Developer tier’s 10x lift is the real unlock.
The pattern is familiar to anyone who’s watched AI costs escalate: a developer prototypes on the free tier, moves to Developer, hits rate limits at scale, and suddenly “cheap per token” meets “expensive in aggregate.” Groq LLM pricing is competitive at every tier, but token volume matters more than token rate.
How Do Batch Processing And Prompt Caching Lower Your Groq Bill?
Two mechanisms cut your effective Groq cost per token without touching application logic — and they stack.
1. Groq Batch API: 50% off every rate
The Groq Batch API lets you submit thousands of requests as an asynchronous job. Groq processes them within 24 hours to seven days and charges half the on-demand rate. Batch processing at this scale is where Groq’s already-low rates become genuinely difficult to beat.
Llama 3.3 70B drops from $0.59/$0.79 to roughly $0.30/$0.40 per million tokens. Llama 3.1 8B drops to $0.025/$0.04. If you’re running nightly classification, bulk summarization, document enrichment, or test suite evaluation, batch should be the default. (If you’re running batch jobs and not using the Batch API, you’re voluntarily paying double. Don’t do that.)
2. Prompt caching: 50% off repeated input tokens
Most production applications send the same system prompt or context with every request. Groq caches it and charges half the input rate on cache hits. No configuration fee, no setup overhead.
GPT-OSS 120B input drops from $0.15 to $0.075 per million cached tokens. GPT-OSS 20B drops from $0.075 to $0.0375. If your cache hit rate is 60%+, input costs drop 30-50% automatically.
Stack both: a cached batch request on Llama 3.3 70B costs roughly 25% of the listed on-demand rate. That’s approximately $0.15/$0.40 effective Groq API pricing per million tokens on a 70B model running at 394 tokens per second. Finding a better speed-to-cost ratio in 2026 is genuinely difficult.
For more on how these levers fit into a broader AI cost optimization strategy, see our full guide to AI cost optimization.
Groq Vs. OpenAI Pricing — And How Claude And Gemini Compare
Here’s the table most organizations are actually looking for. The Groq vs. OpenAI pricing comparison, along with Anthropic and Google, at comparable capability tiers.
Flagship / large models
|
Provider |
Model |
Input ($ / 1M tokens) |
Output ($ / 1M tokens) |
|
Groq |
Llama 3.3 70B |
$0.59 |
$0.79 |
|
Groq |
GPT-OSS 120B |
$0.15 |
$0.60 |
|
OpenAI |
GPT-5.4 (Standard) |
$2.50 |
$15.00 |
|
Anthropic |
Claude Sonnet 4.6 |
$3.00 |
$15.00 |
|
|
Gemini (Pro tier) |
~$2.00 |
~$12.00 |
Mid-tier / efficient models
|
Provider |
Model |
Input ($ / 1M tokens) |
Output ($ / 1M tokens) |
|
Groq |
Llama 4 Scout |
$0.11 |
$0.34 |
|
Groq |
Qwen3 32B |
$0.29 |
$0.59 |
|
OpenAI |
GPT-5.4 Mini |
$0.75 |
$4.50 |
|
Anthropic |
Claude Haiku (latest) |
~$1.00 |
~$5.00 |
|
|
Gemini Flash |
~$0.50 |
~$3.00 |
Budget / small models
|
Provider |
Model |
Input ($ / 1M tokens) |
Output ($ / 1M tokens) |
|
Groq |
Llama 3.1 8B |
$0.05 |
$0.08 |
|
Groq |
GPT-OSS 20B |
$0.075 |
$0.30 |
|
OpenAI |
GPT-5.4 Nano |
$0.20 |
$1.25 |
Note: Google Gemini pricing varies by model, modality, and deployment (e.g., Vertex AI vs. API). Values shown represent typical text-based pricing ranges.
On raw tokens, Groq is 3x to 19x cheaper at comparable tiers. Groq’s Llama 3.3 70B charges $0.79 per million output tokens. GPT-5.4 Standard charges $15.00 — a 19x difference. Since output tokens represent the majority of production spend in most architectures, that gap is where real savings live.
But three factors prevent this from being a clean win:
- Model quality isn’t identical. GPT-5.4, Claude Sonnet 4.6, and Gemini 3.1 Pro are proprietary models with different capabilities. Llama 3.3 70B is strong on many benchmarks but isn’t a universal replacement. A model that costs 2x more per token but solves the problem in one pass is cheaper than one that takes three attempts. Cost per outcome beats cost per token. This is the core principle behind CloudZero’s unit economics approach.
- Speed has economic value that doesn’t appear in a pricing table. If your conversational AI chatbot responds in 200ms instead of two seconds, that’s a UX improvement with measurable conversion impact. Groq’s low-latency advantage is real and monetizable, but only if you’re measuring at the feature level.
- Open-source only means Groq is additive, not a replacement. Many production architectures split traffic: Groq for real-time user-facing requests, a proprietary model for complex reasoning. That multi-provider split is also where cost visibility breaks down. Your Groq bill tracks tokens. Your OpenAI bill tracks different tokens. Your cloud GPU costs track compute hours. Finance wants one number. Nobody has it. This is the AI cost sprawl problem, and it doesn’t solve itself.
When Does Groq Pricing Make Financial Sense?
Strong fit:
- Latency-sensitive, user-facing applications. Chatbots, coding assistants, voice AI, conversational AI interfaces, anywhere a user watches a cursor blink. Groq’s 394-1,000 TPS delivers sub-second responses on tasks that take two to five seconds on GPU-based AI infrastructure.
- High-volume open-source inference. If Llama 3.3 70B, Llama 4 Scout, or Qwen3 32B meet your quality bar, Groq inference rates are among the lowest available, and the speed is unmatched.
- Large-scale batch workloads. The 50% batch discount on already-low rates makes Groq compelling for bulk classification, summarization, and data enrichment.
- Affordable speech-to-text at scale. Groq Whisper v3 Turbo at $0.04/hour, 89% less than OpenAI’s speech recognition API at $0.36/hour, at 228x real-time speed.
Weaker fit:
- Proprietary model requirements (no GPT-5.4, Claude, or Gemini). Training and fine-tuning (inference-only). Tight compliance environments (younger platform than Bedrock or Azure OpenAI). Long-term platform bets (the NVIDIA deal creates genuine uncertainty about GroqCloud’s trajectory, build for portability).
The Cost Question Groq’s Pricing Page Can’t Answer
Every pricing guide in this SERP, including Groq’s own, gives you a table of token rates. That’s the beginning of understanding your Groq inference cost, not the end.
What a pricing table can’t tell you: What does a customer conversation cost? What’s your cost per inference call on the chatbot that’s growing 40% month-over-month? Is your Groq bill scaling with revenue (healthy) or with unoptimized prompts (fixable)?
CloudZero’s FinOps in the AI Era research, drawn from 475 senior leaders, found that 49% of organizations aren’t confident they can calculate AI ROI. The barrier isn’t math, it’s that AI spending is fragmented across providers, each with its own billing format and token definition.
The FinOps Foundation’s 2026 State of FinOps confirms the same pattern: organizations rank visibility over optimization as their most urgent AI priority, because you can’t optimize what you can’t see.
The real question behind every pricing page isn’t “how much does a token cost?” It’s the question CloudZero’s entire platform is built around: was it worth it?
How CloudZero Provides AI Inference Cost Visibility Across providers
CloudZero gives engineering and finance teams a single view of AI spend; cost per inference, per customer, per feature, and per model, across every provider in the stack. OpenAI, Anthropic, AWS, Azure, GCP, Snowflake, Datadog, all normalized into one attribution engine.
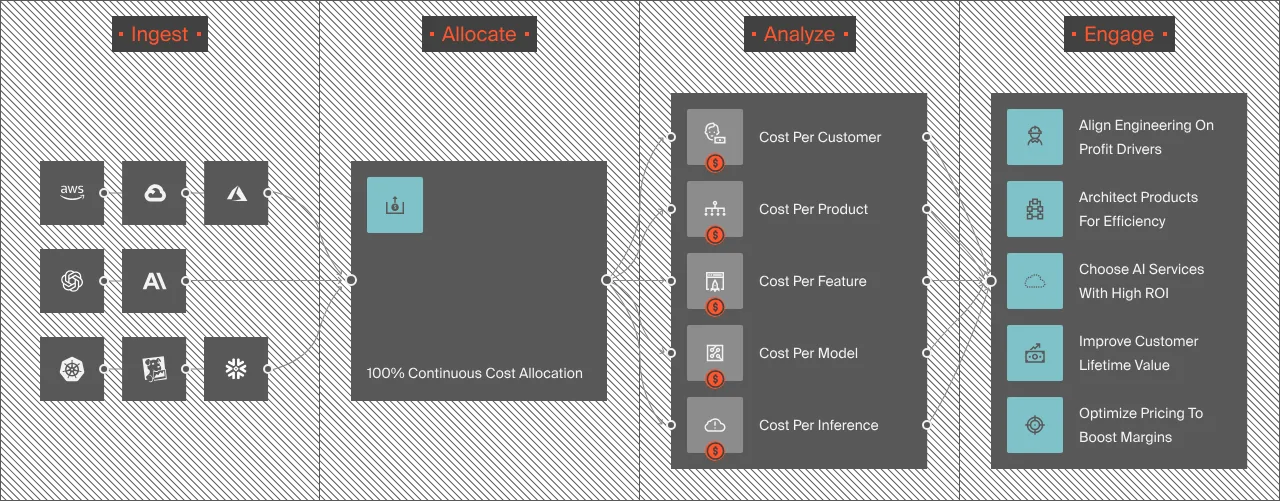
If your AI spend spikes, from a prompt regression, a traffic surge, or a runaway feature, CloudZero alerts the owning engineering team within the hour. Not at month-end reconciliation. Not in a quarterly review where everyone politely pretends they knew about it.
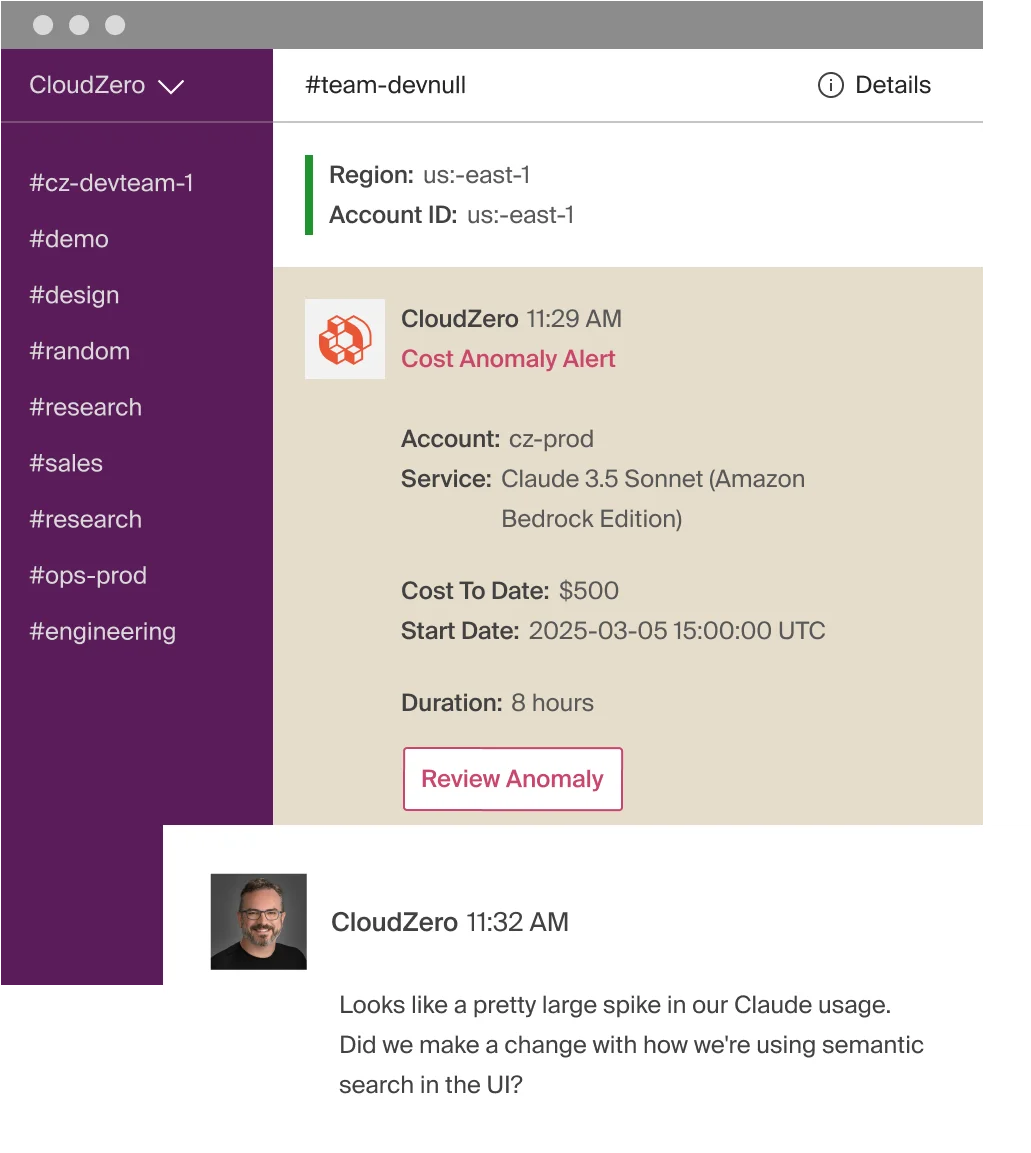
Organizations like PicPay ($18.6M saved) and Upstart ($20M saved) use CloudZero to turn cost visibility into engineering action. One customer running 50+ LLMs identified $1 million in immediate inference savings after connecting.  showing how AI cost intelligence works in CloudZero.
showing how AI cost intelligence works in CloudZero.
Frequently Asked Questions About Groq Pricing











