
Serverless computing is one of the fastest-growing areas in software development, along with hybrid clouds and multi-cloud strategies.
The global serverless architecture market is experiencing rapid growth. It rose from $14.6 billion in 2024 to an estimated $17.9 billion in 2025. By 2029, it’s projected to reach $41 billion. That marks a CAGR of around 22–23% since 2021.
The serverless approach promises to help developers beat the cons of self-managed and even virtual server infrastructure.
But is serverless right for you?
In this detailed guide, we’ll explore what serverless computing is, how it works, and the advantages and disadvantages of serverless architecture. Then you can decide.
What Is Serverless?
Serverless is a cloud-based development approach that frees developers to focus solely on writing code to solve business problems, rather than managing server issues. It is also unique because it supports auto-scaling, where the computing storage and power you need to execute applications are allocated on demand.
The computing approach uses a model known as event-driven function to determine the scope of those needs. That’s why you’ll see serverless architecture, also referred to as Function-as-a-Service (FaaS).
Here’s the thing. Not too long ago, developers had to anticipate application usage to buy fixed numbers of servers or amounts of bandwidth to support such operations. That meant buying more capacity than was necessary.
Why?
Because you’d rather have more to work with than less than you need, in which case your application’s performance would suffer.
However, the redundancy approach cost more than many teams were willing to run through. Maintaining a dedicated physical server, and even a virtual one, also takes time, distracting developers from focusing on their primary coding roles.
Enter serverless architecture.
Serverless services allow you to pay for only the resources you use:
- You can utilize more bandwidth as your computing needs increase without needing to make prior reservations, unlike in a traditional setup.
- Or, you can scale down and reduce server usage when you are not serving up as many requests.
The pay-as-you-go billing model helps teams save time and money to be more agile and respond to customer needs faster.
Report
Finance needs to prove AI’s return: CloudZero report
260 senior finance leaders (more than half CFOs) told us why the speed of seeing AI spend, not the size of it, separates who pulls ahead on AI from who gets burned.
Serverless 101: How It Works
Physical servers are still involved in serverless computing. But developers do not handle infrastructure issues.
So, why is it called serverless?
In a serverless approach, a cloud service or vendor manages all the backend services. Those services are everything DevOps needs to get their application up, running, up-to-date, and up-to-the-task, and include:
- Hardware allocating
- Virtual machine management
- Capacity provisioning
- Server uptime maintenance
- Container management
- Patching a host
- Creating test environments on the servers
Your cloud service provider takes care of all that for you. This model contrasts with the Infrastructure-as-a-service (IaaS) model, where your developers also need to handle app scaling and host management tasks.
Serverless developers do not have to know anything about the infrastructure supporting their code. From their end, the servers do not exist.
They just need to focus on writing code that solves customers’ issues fast, affordably, and on flexible infrastructure.
What Is Serverless Used For?
The serverless approach is suitable for organizations that want to streamline their cloud migration or optimize the efficiency of their cloud-based applications.
Serverless is ideal for high-latency backend tasks such as multimedia and big data processes, thanks to edge computing.
Edge computing is a technology that brings data processing closer to where it is created by using localized data centers. It helps prevent the potential slowness and latency in data transfers that physical distance from a data center tends to cause.
It helps save bandwidth, boosts response times, streamlines data transfers, and supports real-time responsiveness.
Overall, the edge computing aspect of serverless helps make deploying applications faster and more cost-efficient. Serverless computing is also ideal for applications that need rapid, scalable, and efficient infrastructure to support fast growth.
Also, if you can’t predict how much server load an application might take, serverless architecture can be the most dynamic way to accommodate rapid changes.
Real Life Serverless Architecture Examples
We’ll take three examples of companies you know all too well.
Coca Cola
When the soft drinks behemoth piloted serverless computing on its vending machines, it saw significant savings and fully embraced the approach.
How it works:
Vending machines need to communicate with a headquarters, where inventory is kept. Coca-Cola realized that keeping all vending machines on at all times was wasteful.
Now, every time a person purchases a drink, the action acts as a trigger that activates the underlying Amazon Web Services (AWS) Lambda function through the machine’s payment gateway.
Coca-Cola then only pays AWS for the actual number of transactions that happen, not on a fixed monthly/yearly fee, regardless of sales like before.
Slack
The cloud-based platform uses several bots to power successful online collaboration among teams.
How it works:
Slack’s Marbot, in particular, is the serverless bot that helps Slack developers and operations teams receive notifications from AWS through Slack.
It works with Auto-scaling Notifications, CloudWatch alarms, and CloudWatch Events to make that happen fast, dynamically, and affordably.
Netflix
When you’re everyone and their aunt’s favorite movie streaming service, you get to serve billions of hours of video to hundreds of millions of people every year.
Netflix needs to constantly encode millions of video hours from publishers before it can stream them to users. The streaming service requires the video to be encoded into 60 separate parallel streams.
How it works:
The files upload to S3, and AWS triggers an event that calls AWS Lambda to split the videos into five-minute clips. The platform then aggregates and deploys the processed video using sophisticated rules.
But there’s more.
Using serverless helps Netflix achieve a couple of gigantic needs, according to John Bennet, Senior Software Engineer at Netflix:
- Process petabytes of data daily
- Scale service provision on demand
- Discover and respond to issues such as unauthorized access in real-time
- Determine if they need to back up every modified file
Netflix completed a full migration to the AWS serverless infrastructure for those reasons.
Learn how Netflix, Slack, Lyft, and others built their cloud cost management tools to monitor and optimize their cloud costs in our article, “Cloud Cost Management Tools Used at the World’s Top Tech Companies”.
What Are The Benefits Of Using Serverless?
Picture this: A 2019 O’Reilly serverless survey showed over 60% of respondents worked in a place where serverless computing had been adopted.
The respondents also pointed to several benefits of serverless computing that they were seeing over using other software development models.
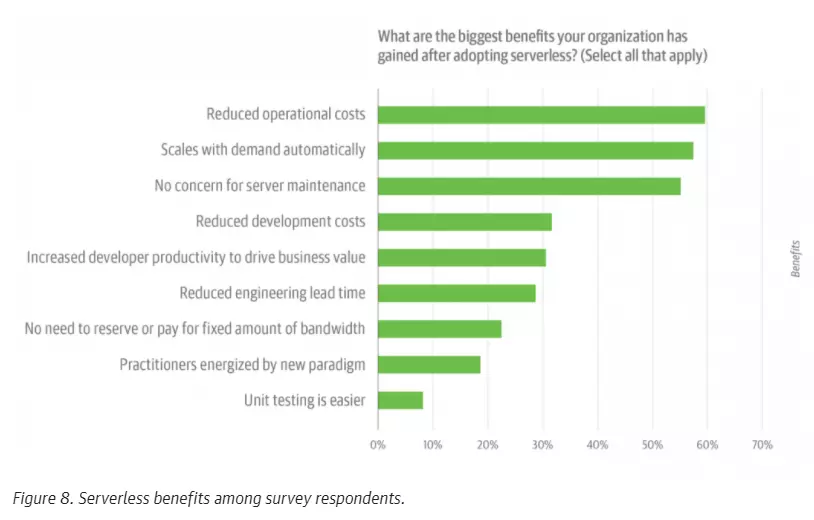
Credit: O’Reilly 2019 Serverless Survey
As of 2023–2024, over 70% of AWS customers use at least one serverless solution (Lambda, App Runner, Fargate, or CloudFront Functions).
Now, we’ve already seen some of the advantages of serverless computing. Now, let’s put them together and see several more.
1. Serverless is cost-efficient
Serverless takes a cost-first approach.
That means you do not have to spend a premium to buy, set up, and hire expert staff to manage physical or cloud-based server infrastructure. You do not have to spend money and time upgrading your code’s underlying infrastructure.
Instead, you can focus on using the platform to develop your core product so that it can reach the market as soon as possible.
Additionally, the pay-per-usage billing method allows developers to pay only for the services they use. Some vendors, such as AWS, can calculate prices based on 100-millisecond increments.
You don’t need to burn your IT budget on an expensive monthly fee, only to end up using only 15-25% of your paid capacity.
2. It is also excellent for scaling
The traditional server and cloud computing approaches require that you allocate fixed resources and hope everything goes to plan.
However, a spike in usage from, say, a viral promotion that increases your server requests can lead to a slurp in your application’s performance. On the contrary, serverless would allow you to handle as many requests as possible without compromising performance.
You would just need to increase functions, which happens automatically inside the server.
3. You can make quick and real-time updates to your application
In a serverless environment, vendors provision a collection of functions. That means you can upload bits of code to help launch a “bare minimum” version of your application to market.
You can then upload updates on an ongoing basis to further improve the application. A serverless architecture would help you update the app one function at a time. Yet, you can still make changes to the whole application, add extensive features, and patch multiple security issues if you want.
4. Serverless computing boosts productivity
When server management tasks do not take your developers off their primary coding projects, they can create solutions to existing issues much faster. Or, they can focus on improving the DevOps metrics that matter so you can keep up with fast-changing software trends and user experience demands.
That also means enterprises can devote fewer people and processes to create fully scalable applications. The rest of the team can help with other vital tasks.
The Disadvantages Of Serverless Computing
Serverless is not perfect, either. So, what are some of the challenges associated with serverless computing?
1. Cold starts tend to cause latency
Picture what happens when you put your phone down for more than a minute or less.
It automatically switches to sleep mode. The goal is to save battery drain by shutting down running applications.
Serverless computing uses a similar principle, but on steroids, to produce the benefits we’ve just seen in the previous section. If your application doesn’t trigger any function for a while, a cloud provider’s system puts it to sleep so it can save resources.
That is a highlighting difference between serverless and constantly running servers.
The problem with that is the next time your application calls up the function, it’ll take a while to “wake up,” causing latency. The slight delay is what’s known as a cold start.
While the latency lasts for only milliseconds, in heavy applications, that time may mean delayed customer requests. For example, an e-commerce application needs to act fast so customers won’t feel frustrated and abandon their cart.
Top cloud providers employ tactics such as utilizing a Chrome V8 engine that can cold-start and execute JavaScript code in under five milliseconds.
2. Serverless architecture may not be ideal for some applications
Serverless cloud providers are responsible for allocating dynamic resources. Some vendors may limit the amount of their overall resources you can use, potentially restricting you if you need more.
Furthermore, their service may require clients to use specific protocols to interact with their platform. That means you may need to give up some customization options and surrender to what they have on offer.
So, you’ll want to work with a vendor who understands your needs and can help you achieve them without having to make significant sacrifices.
3. Finding technical glitches and debugging them might be tricky
First, serverless computing breaks monolithic stacks into smaller, independent functions. Finding the specific problem area can be tricky.
Second, your DevOps team doesn’t see how their code works on the server-side, making testing and debugging even trickier. Like Netflix, you would need to work closely with your vendor to identify and patch any glitches before they become a major issue for your application’s end users.
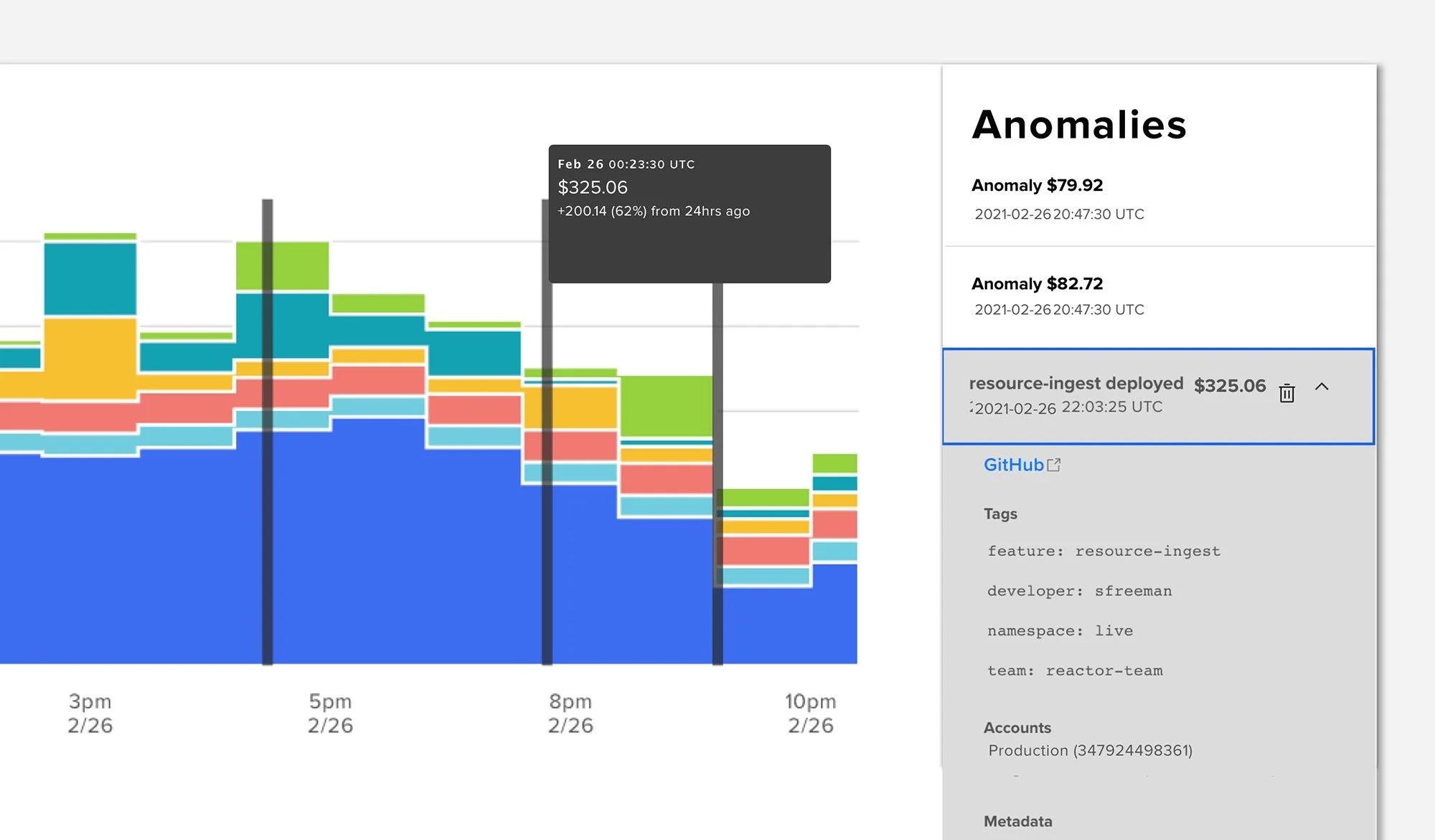
4. Security might be a concern
When you cede control of your code’s infrastructure to a third-party provider, you trust them to keep the service foolproof.
Yet, serverless computing handles several customers’ code on the same server simultaneously. That scenario is referred to as multitenancy in cloud computing, where several customers share server resources.
Depending on your cloud provider, any mix-ups can lead to data leaks. That’s a big problem if you handle sensitive data, such as health, financial, or other personal information.
Also, if you decide to migrate a legacy application to the cloud without first modernizing it to work securely in the cloud, you may expose yourself to hacking. One way to prevent these issues from ruining your application’s performance is to work with a vendor that hosts each serverless function in its sandbox.
5. Switching serverless providers can be a challenge
There are several cloud providers right now, each offering slightly different advantages and workflows. In reality, though, switching vendors is not always practical.
Here’s why.
Successfully using a serverless approach requires that your vendor customizes the infrastructure to your specific needs.
When your core application’s functions are so intertwined with a particular vendor, leaving would mean making some major changes to your application’s architecture before and after the transition, a costly and time-consuming affair.
That catch-22 situation has a name: vendor lock-in.
Some vendors attempt to solve this by writing code in an easier-to-migrate language, such as JavaScript, instead of through the service workers API.
How Does Serverless Compare To Other Cloud Computing Models?
How does the Function-as-a-Service model in serverless computing compare to other backend approaches?
Platform-as-a-Service
PaaS is a cloud computing approach where developers rent pretty much every essential tool they need to develop and run an application.
The difference between PaaS and serverless is that the former does not always run applications at the cloud’s edge, is slower, and is not easily scalable.
Backend-as-a-Service
Like serverless, BaaS is a computing model where a vendor provides backend services, allowing developers to focus on improving frontend functions. But unlike serverless, the BaaS approach does not necessarily run applications at the edge of cloud computing or use event-driven triggers.
5 Top Serverless Architecture Tools
As you can see, you can mitigate most of the downsides of serverless computing. Furthermore, your competition may already be taking advantage of the architecture’s benefits.
If you are considering implementing a serverless architecture for your needs, you have several cloud providers to choose from.
- AWS Lambda Functions
- Google Cloud Functions
- Microsoft Azure Functions
- IBM Cloud Functions
But you can use several tools to make your serverless implementation simpler.
Those tools include:
CloudZero
CloudZero provides cloud cost intelligence for engineering teams that want to better understand their cloud costs (including COGS and unit costs, such as cost per customer), shift engineering decisions left, and optimize AWS spend.
The platform provides real-time insights that help engineering map AWS, Kubernetes, and Snowflake costs to products, people, and features. Learn more about how CloudZero puts engineering in control of cloud spend here.
AWS CodeBuild + CodePipeline
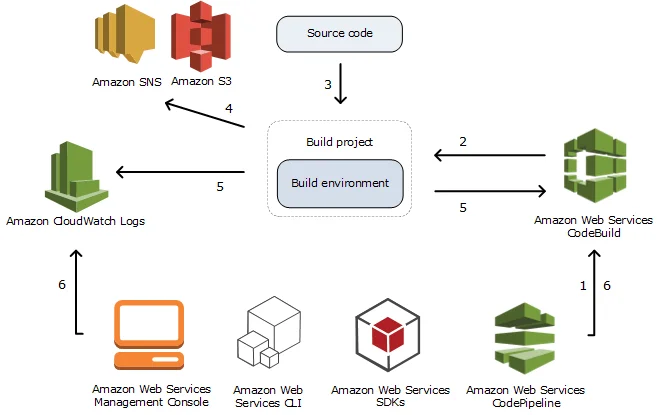
AWS CodeBuild and CodePipeline form a fully managed, serverless CI/CD solution that integrates seamlessly with Lambda. CodeBuild compiles your code, runs tests, and produces build artifacts. CodePipeline, on the other hand, automates the release process from commit to deployment.
This configuration eliminates the need for managing custom CI environments. You only pay for the build time used, and it scales automatically without pre-provisioned capacity. CodeBuild supports multiple runtimes, longer build durations, and fine-grained IAM control. This makes it more flexible and better supported than legacy tools such as Jenkins or LambCI.
Gordon
Gordon uses CloudFormation to help developers build, wire, and apply AWS Lambda functions.
It reduces the number of steps required to ready your functions for Lambda from up to seven to just two. That makes applying new changes fast and easier.
Gordon is an open-source platform.
Node Lambda
Node Lambda is a command-line tool that helps JavaScript developers share code in packaged modules.
They can then use it locally to run and deploy a Node.js application to AWS Lambda. Node.js is lightweight, handles thousands of simultaneous requests fast, and offers a bunch of node package modules.
Also, a single command can create a Lambda function — even without opening the AWS console.
Kappa
Kappa is an open-source command-line tool for developers to deploy, push updates, and test functions on AWS Lambda.
It simplifies AWS function deployments in several ways, including creating and associating IAM policies and roles.
These services can help you transition to serverless with minimal disruptions, security issues, or fear of the unknown.
Optimize Your Serverless Approach With Cloud Cost Visibility
If you are a large organization, implementing serverless architecture can have significant cost, personnel, scalability, and security benefits.
If you are a nimbler startup, the serverless approach can help you get to market fast. You can then push updates as you test, debug, and collect user feedback. Next, you can add features that align with your customers’ aspirations to retain them longer.
However, migrating to the serverless architecture requires more than just “lifting and shifting” your applications. Without cost visibility, it’s impossible to ensure you’re making effective architectural decisions to optimize.
With CloudZero, you can make migration costs clear and predictable — for you and your finance team. Our approach provides real-time visibility into cloud costs during migration and maps these costs to specific products, features, and teams.
 to see how you can use cloud cost intelligence to help you switch to serverless architecture.
to see how you can use cloud cost intelligence to help you switch to serverless architecture.











