The cloud has long promised limitless scalability and near-perfect uptime. But cloud outages aren’t anomalies — they’re a predictable feature of infrastructure built at this scale.
In the span of 10 days in October 2025, both Amazon Web Services (AWS) and Microsoft Azure suffered widespread outages that rippled across industries. Banks, airlines, retailers, and gaming networks went dark for hours as engineers scrambled to reroute traffic and restore connectivity.
It was a stark reminder: even the backbone of the digital economy has single points of failure. Every business that depends on these platforms — which is nearly everyone — needs a plan for when it happens again.
It was a rare one-two punch for the nearly trillion-dollar cloud industry, and a stark reminder that even the backbone of the digital economy can have single points of failure.
And for every business that depends on these platforms, the two largest providers today, hence nearly everyone, that’s a wake-up call worth heeding.
What Happened: The AWS Outage Of October 2025
Early October 20, 2025, what started as rising error rates quickly spiraled into a full-scale outage, affecting thousands of apps and services. AWS’s busiest region (69%), us-east-1 (Northern Virginia), became the internet’s biggest bottleneck.
The cause wasn’t a cyberattack or power failure but a software bug inside AWS’s internal DNS automation system (Amazon DynamoDB).
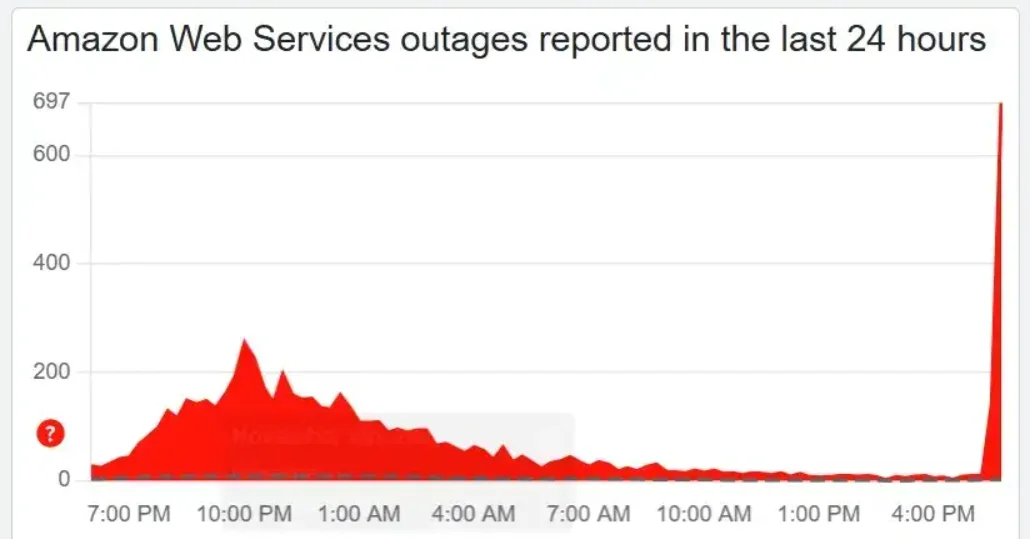
Credit: Down Detector
When the “phonebook” that helps cloud services talk to each other failed, the impact rippled, from fintech platforms to streaming and smart home apps.
AWS restored operations within hours, but of the more than 2,000 companies affected, social media platforms like Reddit were still reporting elevated error rates and access issues the entire first week of November.
Related read: When AWS Goes Down: What It Means For Your Cloud Costs

Research Report
FinOps In The AI Era: A Critical Recalibration
What 475 executives told us about AI and cloud efficiency.
What Happened: The Azure Outage 10 Days Later
Just days later, Microsoft’s Azure, the world’s second-largest cloud provider, had its own crisis that lasted a business day.
Thousands of users across the world began reporting outages. Websites couldn’t load. Cloud apps stalled. And enterprise dashboards, including Microsoft 365, went dark.
Airlines couldn’t process bookings, retailers saw payment systems fail, and collaboration tools like Teams briefly went offline. Players like Kroger, NatWest’s website, and even Minecraft had issues.
The culprit this time wasn’t deep in the data center, although it was still a similar issue to AWS, but at the edge. A misconfiguration in Azure Front Door (AFD), to be precise. That is Microsoft’s global routing and content delivery service, and it disrupted traffic flow across multiple regions.
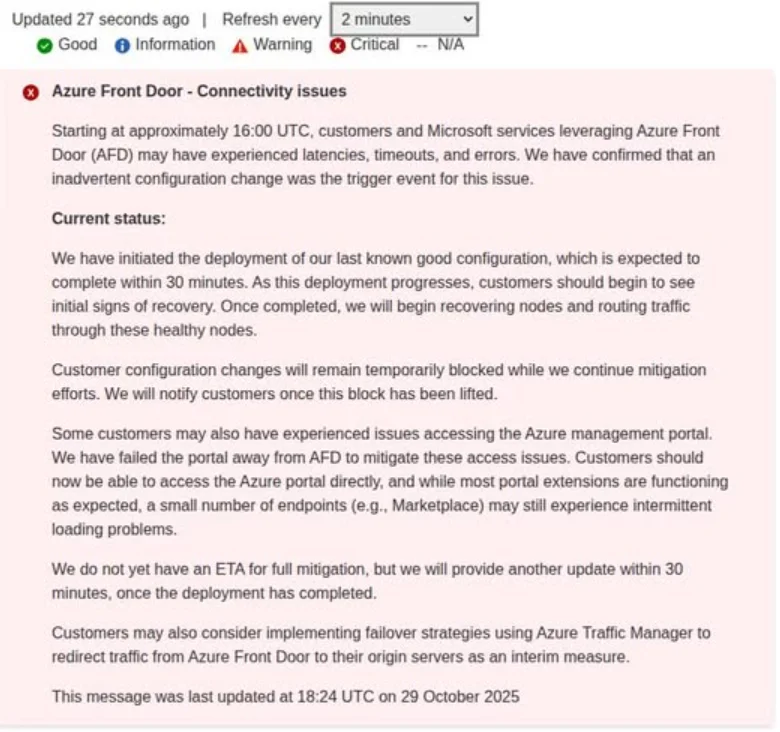
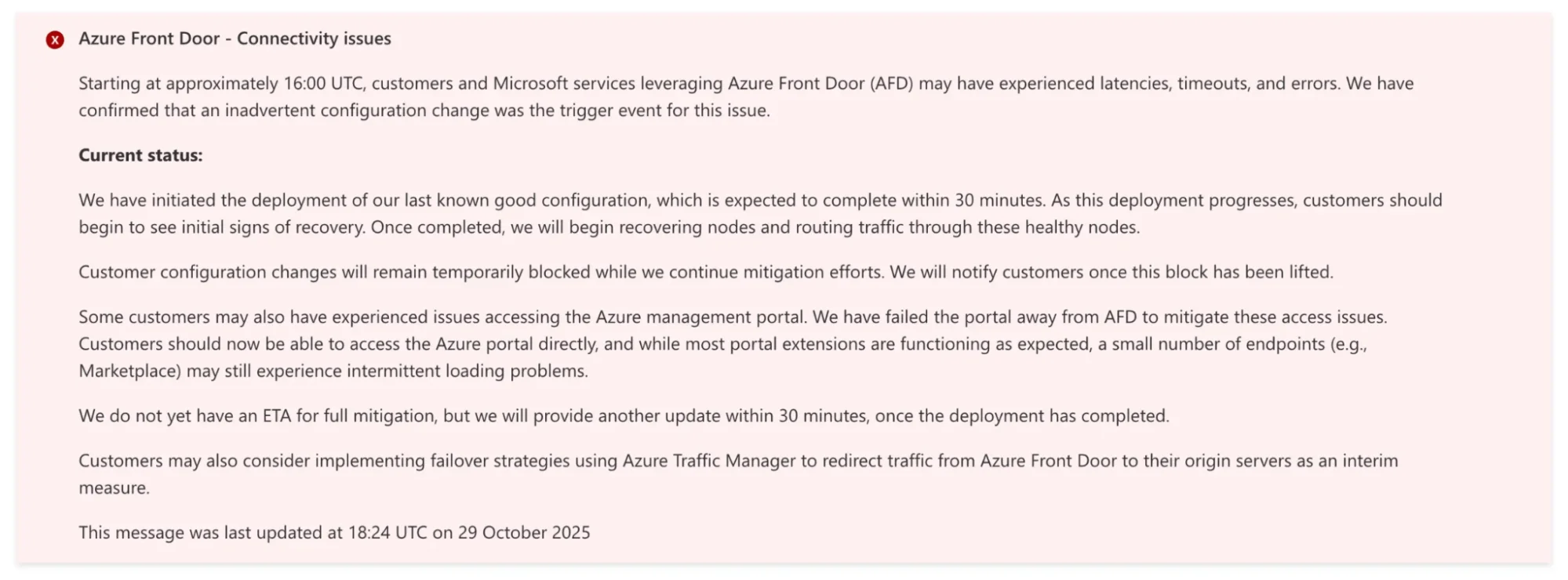
Credit: Down Detector
By the time Azure engineers rolled out a fix, the damage to uptime charts and customer confidence was already taking in water across continents.
The Real Cost Of Cloud Downtime (And Why It’s Bigger Than You Think)
When AWS or Azure goes down, it doesn’t matter how solid your internal codebase is. If your foundation wobbles, everything above it shakes.
Yet, downtime means lost revenue, missed transactions, and frustrated customers. SaaS platforms scrambled to explain outages they didn’t cause. And the invisible costs often run deeper.
Many organizations discovered that even if their workloads weren’t hosted on the affected provider, their vendors and partners were. A payment API here, a data analytics service there, all built atop the same cloud.
When one link broke, the chain stalled.
Also, failing over to another region or spinning up redundant capacity mid-crisis often means double infrastructure costs for that period. Cross-region data transfers and replication also spike egress fees, which can balloon during recovery.
Related Read: Here’s How The Different AWS Regions Affect Your Cloud Costs
In the end, businesses with multi-region or multi-cloud architectures weathered the storm better, a finding echoed by analysts at INE and others. Those that didn’t are now left tallying the cost of ‘putting all their data eggs in one cloud basket.’
How To Build Cloud Resilience: 6 Strategies That Work
The back-to-back outages have sparked an uncomfortable but necessary question for many IT and business leaders, “What’s our Plan B when the cloud goes dark?”
It turns out, resilience goes beyond better uptime into smarter architecture.
1. Adopt a multi-cloud or hybrid architecture
Instead of relying on a single provider, more teams are adopting hybrid or multi-cloud management models. They are blending AWS, Azure, Google Cloud, DigitalOcean, among others, and even on-prem systems. The goal is to ensure if one fails, another can take over.
It’s not cheap, but it’s a lot less expensive than hours of global downtime.
2. Deploy across multiple regions
Running workloads in at least two separate regions, say, US-EAST-1 and US-WEST-2 on AWS, can prevent a regional issue from becoming a company-wide outage.
3. Use chaos engineering to test before an outage does
Many teams are also leaning into chaos engineering. This is the practice of intentionally breaking things in controlled environments to see how their systems respond, so real incidents don’t become hours-long customer churn and revenue losses.
4. Map your third-party dependencies
You can’t protect what you don’t understand. So, knowing every third-party service, SaaS vendor, and API that touches your environment helps you pinpoint where single-provider risk hides.
5. Build cost visibility into your resilience plan
Of course, building for resilience doesn’t mean losing grip on your costs. In fact, one of the biggest concerns we see in hybrid, multi-cloud, and multi-service setups is understanding what that resilience actually costs. So, you’ll want to architect your systems to fail over intelligently while still tracking and managing the cost impact of doing so.
Related read: How To Combine Multi-Cloud Spend Into One Single View (And Make It Make Sense)
6. Review your SLAs — and plan around their limits
Even Service Level Agreements (SLAs) deserve a closer look. They define what you can expect, and what you can’t, when outages strike. Knowing those limits helps you plan backup coverage and response priorities more effectively.
And finally, resilience is not a one-time project, but a living discipline. So, ensure regular failover tests, updated runbooks, and recovery drills. These can be the difference between a headline-making outage and a quick, quiet recovery.
Related read: The Outage Anxiety Test: Can You Answer These 3 Questions In Under 10 Minutes?
FAQs About Cloud Outages And Resilience
What causes AWS and Azure outages?
Most major cloud outages aren’t caused by hardware failure or cyberattacks — they stem from configuration errors, software bugs, or failures in core internal systems like DNS routing and content delivery networks.
The October 2025 AWS outage was triggered by a DNS automation bug inside DynamoDB. The Azure outage that followed was caused by a misconfiguration in Azure Front Door, its global routing and CDN layer. In both cases, a single internal failure cascaded across dependent services globally.
How much does cloud downtime cost?
The cost of cloud downtime varies by industry and workload, but industry benchmarks put enterprise downtime at between $5,600 and $9,000 per minute. For large-scale outages affecting thousands of companies simultaneously — like the CrowdStrike incident in July 2024 — total losses across Fortune 500 companies reached an estimated $5 billion.
Beyond direct revenue loss, downtime generates indirect costs: emergency infrastructure failover, egress fee spikes from cross-region data transfers, SLA credits, and the reputational cost of customer-facing outages you didn’t cause.
What is multi-cloud resilience?
Multi-cloud resilience is the practice of distributing workloads across two or more cloud providers — such as AWS, Azure, and Google Cloud — so that a failure at one provider doesn’t take down your entire operation.
It’s more complex and typically more expensive than single-provider architectures, but it significantly reduces single-provider risk. The trade-off is worth it for mission-critical workloads; less critical services can often remain single-cloud to control cost and complexity.
What is chaos engineering?
Chaos engineering is the practice of deliberately introducing failures into your infrastructure in controlled conditions — simulating an outage, killing a service, or severing a network path — to test how your systems respond before a real incident forces the question.
It’s one of the most effective ways to validate that your failover plans actually work. Organizations that had tested their recovery procedures before the October 2025 outages recovered significantly faster than those that hadn’t.
How do you manage cloud costs during an outage?
Outages don’t just cost you in downtime — they can spike your cloud bill. Failing over to another region or spinning up redundant capacity mid-crisis often means running double infrastructure temporarily. Cross-region data transfers and replication also drive up egress fees during recovery.
The best way to manage this is to have cost visibility built into your resilience architecture before an outage hits — so you know exactly what failover costs, can model it in advance, and aren’t discovering the bill after the fact.
Does CloudZero help with multi-cloud cost visibility?
Yes. CloudZero aggregates spend across AWS, Azure, GCP, Kubernetes, Snowflake, and on-premises environments into a single view, so you can track what your resilience architecture is actually costing across providers. Real-time anomaly alerts also surface unexpected cost spikes during incidents — including the kind of egress and failover costs that tend to balloon during and after outages.
How To Manage Cloud Costs During And After An Outage
Building resilience across clouds and regions doesn’t have to force you to choose between resilience and cost visibility.
Yet, for most companies, that’s often the trade-off. Pay more for uptime, or risk being offline when it matters most.
But it doesn’t have to be a blind trade.
With CloudZero, you can see and manage your cloud spend across major clouds, platforms like Kubernetes and Snowflake, as well as on-premises environments. All in one place.
If you’re considering a hybrid or multi-cloud strategy to spread risk across providers, CloudZero can help you keep all that complexity under control.
From migrations and data egress to Kubernetes clusters and Snowflake workloads, CloudZero surfaces every cost driver in a single pane of glass, complete with immediately actionable insights like cost per service, per deployment, per feature, and beyond. Plus, you get real-time anomaly alerts delivered straight to your inbox.
So when the next outage inevitably hits, you’ll be online and in control.  to experience CloudZero yourself (like the leading teams at Toyota, Duolingo, Skyscanner, MalwareBytes, and Grammarly already do).
to experience CloudZero yourself (like the leading teams at Toyota, Duolingo, Skyscanner, MalwareBytes, and Grammarly already do).


FinOps In The AI Era: A Critical Recalibration
What 475 executives told us about AI and cloud efficiency.