
Amazon Athena is heralded for its simplicity, pay-per-query pricing, and speed — making it a popular choice for big data analytics on AWS. Others say Athena has its fair share of limitations, which could affect your overall analytics experience and quality of analyses. So, what is what?
In this post, we’ll share what AWS Athena does, compare it to Amazon Redshift, and share how to understand and control your Athena costs in AWS (with just one tool).
What Does Amazon Athena Do?
AWS Athena is best described as an interactive query service that can seamlessly use standard Structured Query Language (SQL) to analyze data stored in Amazon Simple Storage Service (Amazon S3) — functioning as a core tool for data lake querying without requiring any infrastructure setup.
Picture this:
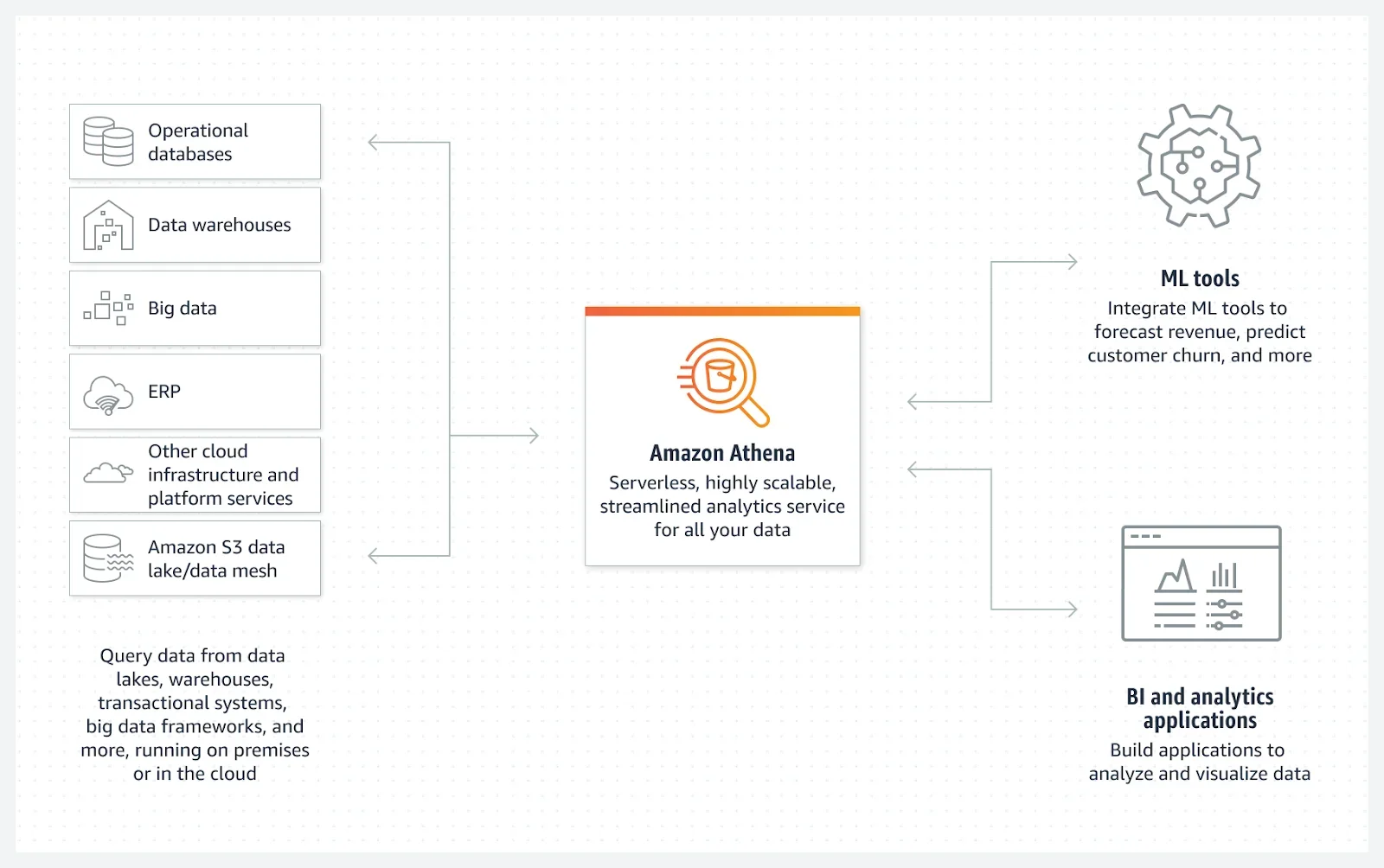
Credit: How Amazon Athena works
Amazon Web Services (AWS) introduced Athena to simplify the process of analyzing large volumes of raw Amazon S3 data. You do not have to load Amazon S3 data into Amazon Athena and then transform it for analysis. And that makes the service ideal for teams that want to perform ad hoc, quick, or complex data analyses.
Also, you can use Amazon Athena to process structured, semi-structured, and unstructured sets of data.
AWS Athena is also serverless and built to scale automatically. The fact that Athena is serverless means you won’t be required to set up or manage any infrastructure.
Auto-scaling enables you to run complex queries in parallel on large data sets and quickly return results.
This serverless architecture also enables AWS to charge Athena users for only the queries they run. This makes the service a cost-effective option for organizations that leverage Amazon S3 for data research, online analytical processing, and log analysis, among other applications.
Report
Finance needs to prove AI’s return: CloudZero report
260 senior finance leaders (more than half CFOs) told us why the speed of seeing AI spend, not the size of it, separates who pulls ahead on AI from who gets burned.
What Are The Benefits Of Using Amazon Athena?
Amazon Athena features deliver powerful benefits for Amazon S3 users, including the following:
- Easy to use – Athena doesn’t require complex Extract, Transform, and Load (ETL) processes, so even users with basic SQL skills can use it. Even business analysts and other data professionals can adopt it, as standard SQL queries are very simple and straightforward.
- Flexible – Athena’s open and versatile architecture doesn’t restrict you to a specific vendor, technology, or tool. You can, for example, work with a wide range of open-source file formats, as well as switch freely between query engines without adjusting the schema.
- Highly available query service – Athena runs queries with compute resources distributed across multiple facilities as well as multiple devices within each facility.
- Built for Amazon S3 – S3 is Athena’s primary data store, a durable, highly available data store.
- Query your data almost instantly – Athena enables you to start querying your data in a few seconds. Simply point it to the data you’ve stored in S3, specify the schema, and begin querying it with Standard SQL.
- It’s serverless – You do not manage the underlying compute infrastructure, setting you free to focus on optimizing the outcomes. You won’t have to worry about setting up clusters, regulating capacity, or loading data.
- Pay your fair share – It’s pay per query, so you pay only for the queries you run — not the underlying infrastructure, etc. The service doesn’t charge you for compute instances. Instead, you only pay for the queries you’re running.
- Built on Presto and Trino – The interactive query service leverages Presto with ANSI SQL support. It also supports a variety of data formats: JSON, Apache web logs, CSV, Parquet, TSV, Text files with custom delimiters, ORC, Ion, and Avro.
- Integrated with Amazon’s Glue Data Catalog by default – This means you can create a central repository for metadata across multiple services, discover schemas across data sources, add new and updated table and partition definitions to your Catalog, and manage schema versioning.
Glue offers fully-managed ETL capabilities. That means you can use it to transform your data or restructure it into columnar formats for better performance and cost optimization.
Additionally, Athena Engine v3 introduced over 90 query performance improvements, 50 new SQL functions, and 30 new features — and as of 2026, remains the default engine for new workgroups, making the service even more useful.
What Are Some AWS Athena Limitations?
Like every service, Athena may not be ideal for every use case. Here are some limitations you may have to contend with.
- The optimization is limited to queries. For example, data you’ve already stored in Amazon S3 cannot be optimized, nor can the underlying data. Even when you try to transform the Amazon S3 data using AWS Glue, you still have to be cautious not to disadvantage other services that are accessing the same data.
- Shared resources. According to Amazon’s Service Level Agreement (SLA), all AWS Athena users across the globe share the same resources when running their queries. This multi-tenancy approach may occasionally trigger resource strain, resulting in fluctuating query performance.
- Lacks data manipulation operations. Since AWS Athena is just a query service, all you’ll find here is a query engine. It doesn’t come with a built-in Data Manipulation Language (DML) interface for inserting, deleting, and updating data.
- There are no indexing options available. In the absence of indexing, Athena’s operation load increases, potentially affecting its performance. For example, you can expect challenges in operations such as consolidating large tables.
- Partitioning is essential for efficient queries. Not only do you have to partition the data, but you must also manage the partitions to meet your optimal performance requirements. For instance, scanning every 500 partitions will increase your querying time by a second.
- It doesn’t support Presto federated connectors, stored procedures, or parameterized queries. You’ll need Amazon Athena Federated Query to connect to data sources.
- Time-outs. An Athena query can time out when the table has thousands of partitions.
- Hidden files. It treats source files that begin with a dot or with an underscore as hidden.
- 32 megabytes is the maximum row and column size.
- There is no support for querying data in S3 Glacier and S3 Glacier Deep Archive storage classes in Athena.
- It doesn’t support functions such as CREATE TABLE LIKE, EXECUTE … USING, DESCRIBE INPUT, DESCRIBE OUTPUT, MERGE, and UPDATE.
Next, we’ll compare how Amazon Athena stacks up against alternatives. But first…
Amazon Athena Pricing: How Much Does Athena Cost?
Consider this.
Pricing for Amazon Athena SQL queries is pay per query (per-query billing). The cost starts at $5 per TB of data scanned. You are charged only for the number of data bytes scanned by the queries you execute, rounded to the nearest megabyte (MB). A minimum charge of 10 MB per query is required.
Pricing for Amazon Athena SQL Queries with Provisioned Capacity is a little different. The cost starts at $0.30 per DPU hour, calculated per minute. You pay for Data Processing Units (DPU). The DPUs determine the combination of resources needed to run queries and assign them to workloads. A DPU offers 4 vCPUs and 16 GB of memory.
Also:
- The service charges you for the capacity you need and the duration it is active in your account.
- There’s an 8-hour minimum requirement.
- There are no charges for scanning data.
- You can start with 24 DPUs and, when your needs change, scale up or down in increments of 4 DPUs.
- Your capacity will be held until you no longer require it, and you are free to cancel it at any time.
Athena’s Apache Spark pricing also follows the per DPU-hour billing approach, billed per minute. It starts at $0.30 per DPU-hour, calculated per minute. Billing is based on the duration the Apache Spark application takes to run, in 1-second increments, rounded up to the nearest second.
Oh, another thing. There are additional charges, such as Standard Amazon S3 charges for reading, storing, and transferring data.
Also, expect separate charges for data not stored in S3 (running SQL queries on federated data sources) and standard Glue Data Catalog pricing for using the Amazon Glue service.
How Does Amazon Athena Compare To AWS Redshift, Microsoft SQL Server, And AWS Glue?
AWS Athena vs. AWS Redshift
There are many factors that come into play when comparing Amazon Athena to Redshift.
|
Amazon Athena |
Amazon Redshift | |
|
Description |
Serverless, interactive query service. |
Data warehousing platform on the AWS public cloud |
|
Use Cases |
Simplifies analyzing petabyte-scale data sets where it lives |
Helps analyze exabyte-scale data sets using Massively Parallel Processing (MPP) to support fast querying |
|
Types of Data Supported |
Structured, semi-structured, unstructured |
Structured, semi-structured |
|
Data Formats Supported |
CSV, TSV, Ion, JSON, Text file with custom delimiters, Apache web logs, Parquet, Avro, ORC You can convert results to columnar format to optimize performance and costs |
Various data types for Redshift tables, including numeric, character, Boolean, datetime, VARBYTE, HLLSKETCH, Super data types Columnar data store |
|
Compatibility With Open-Source Frameworks |
Presto with ANSI SQL, Trino |
PostgreSQL 8.0.2 Supports User Defined Functions (UDFs) with scalar and aggregate functions |
|
Working With Amazon S3 Data Sets |
Creates separate tables, minimizing the impact on raw S3 data sets No ETL processes required |
You need first to create a cluster for uploading data and creating tables before querying data sets Requires ETL processes before querying |
|
Start-Up Speed |
Almost instant (seconds) |
Minutes (15 to 60 minutes) |
|
Pricing |
Starts from $5 per TB of data scanned | Starts at $2.00/hour (dc2.large) — see our Redshift pricing guide |
Table: A quick side-by-side comparison of Amazon Athena vs Redshift
What does this mean?
Well, AWS Athena is a serverless service that doesn’t require any additional infrastructure to scale, manage, and build data sets. It runs directly over Amazon S3 data sets as a read-only service, setting up external tables without manipulating the S3 data sources.
Amazon Redshift, on the other hand, is a petabyte-scale data warehouse service that’s based on PostgreSQL. The queries here don’t just run directly. Instead, Redshift relies on clusters, for which you’ll be required to bring in the data extracts and create tables before proceeding with your query.
As such, you could say that AWS Athena is best reserved for instances when you need to use Presto and ANSI SQL to launch ad-hoc queries on Amazon S3 data sets. It should be able to work on structured, semi-structured, and unstructured data formats.
Then AWS Redshift, contrastingly, is ideal for analyzing large structured data sets, as it’s capable of generating results much faster than Athena. This means you can, for instance, apply it in real-time data analysis, clickstream events, and log analysis.
Keep in mind, though, that Redshift is costlier since it charges for both compute and storage.
AWS Athena vs. AWS Glue
Here’s a side-by-side comparison of Amazon Glue vs. Athena:
|
Amazon Athena |
Amazon Glue | |
|
Description |
A serverless, interactive query service for large-scale data sets |
A serverless data integration service that supports full-on Extract, Transform, and Load (ETL) operations at scale |
|
Use Cases |
Simplifies analyzing petabyte-scale data sets where it lives for big data analytics |
Helps create, edit, and retrieve tables to perform analytics tasks Also support batch ELT and streaming data processing methods |
|
Data File Types Supported |
CSV, TSV, Ion, JSON, Text file with custom delimiters, Apache web logs, Parquet, Avro, ORC |
CSV, MS Excel, Parquet, JSON, ORC |
|
Pricing |
Starts at $5 per TB of data scanned |
Starts at $0.44 per DPU-hour billed per second |
Table: A comparison of Amazon Athena vs. Glue
Since its initial release in August 2017, AWS Glue has been operating as a fully-managed Extract, Transform, and Load (ETL) service. It comes with three primary components:
- A flexible scheduler for handling job monitoring
- An ETL engine that’s capable of generating Scala or Python code
- A data catalog that acts as the central metadata repository
With these tools, AWS Glue helps you discover datasets, as well as transform and prepare them for search and querying.
So, you should be able to use AWS Athena along with AWS Glue. The latter’s Data Catalogue will create, store, and retrieve table metadata (or schema) to be queried by Athena.
Amazon Athena Vs. Microsoft SQL Server
Here’s a quick overview of the differences between Microsoft’s SQL Server service and Amazon Athena.
|
Amazon Athena |
Microsoft SQL Server | |
|
Description |
A serverless, interactive query service for large-scale data sets |
A relational database management system for a wide variety of purposes |
|
Use Cases |
Simplifies analyzing petabyte-scale data sets where it lives for big data analytics DCL, TCL, DDL, and DML operations |
Supports a variety of applications, including Business Intelligence (BI), Analytics, and transaction processing DatabaseDML operations |
|
Framework |
Presto with ANSI SQL support |
Transact-SQL (SQL) on top of standard SQL |
|
Data File Types Supported |
CSV, TSV, Ion, JSON, Text file with custom delimiters, Apache web logs, Parquet, Avro, ORC |
XML, Non-XML |
|
Pricing |
Starts at $5 per TB of data scanned |
Free for Express to $15,123 for Enterprise SQL Server 2022 |
Table: A side-by-side comparison of Athena vs. Microsoft SQL Server
How To Optimize AWS Athena Costs Quickly And Accurately
Despite Athena’s favorable pricing, its billing process isn’t as straightforward as you’d expect. AWS Athena cost optimization requires more than just watching your bill — you need to know what’s driving spend and why, which is harder than it looks.
One-time and short-term AWS users may be okay with that. But the stakes rise when it comes to long-term usage. If you intend to adopt the service for the long haul, you need a proper cloud cost management platform.
Enter CloudZero.
CloudZero’s AI-powered engine works like a comprehensive observability platform rather than a mere cost tool.
With CloudZero, you can capture, analyze, and automatically map your cost data to the people, products, and processes that incurred them.
Consider this:
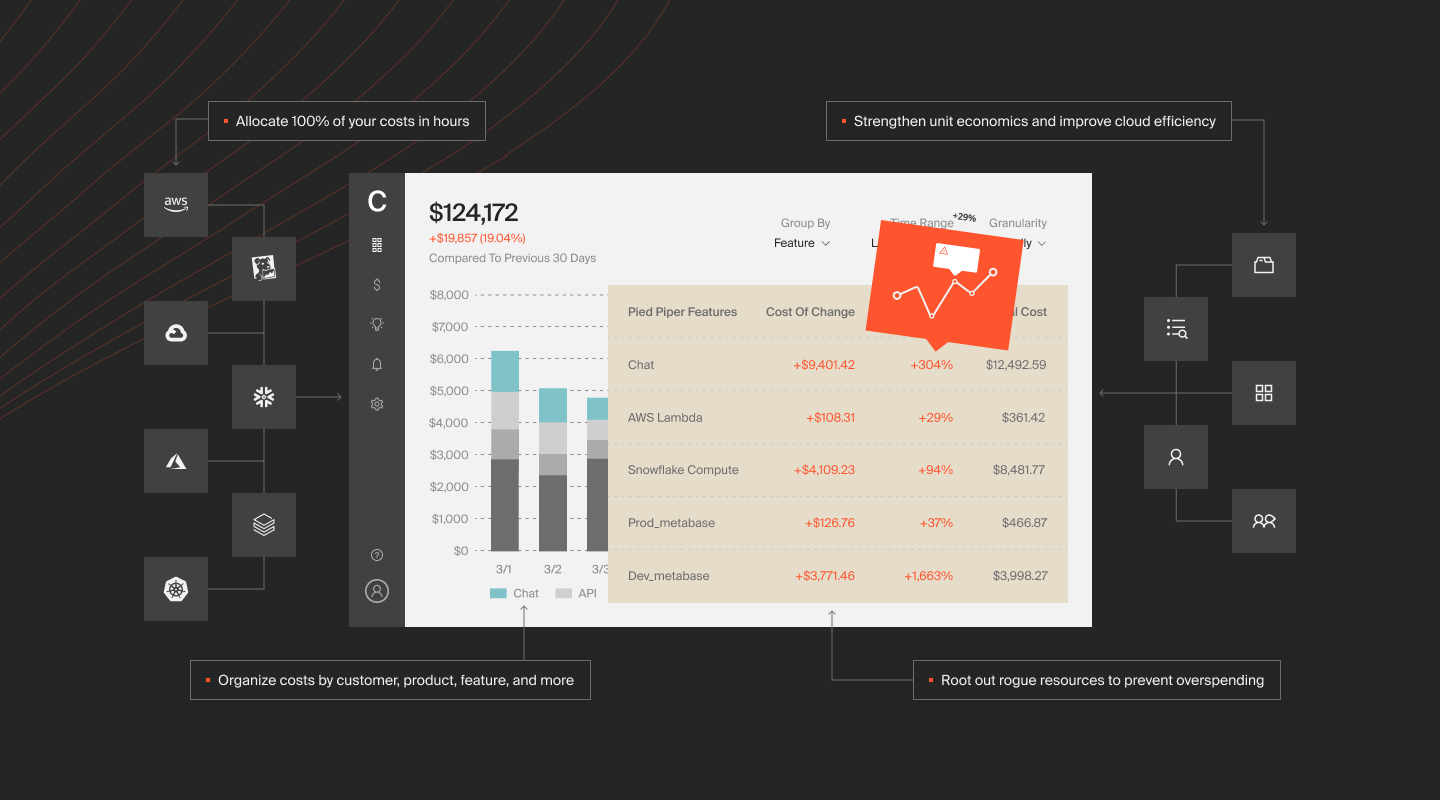
That means you can accurately pinpoint your unit costs, such as cost per individual customer, per team, per product, per environment, per project, and more. You can also drill down to hourly granularity to ensure you not only see the big picture but also the fine details that make a huge difference.
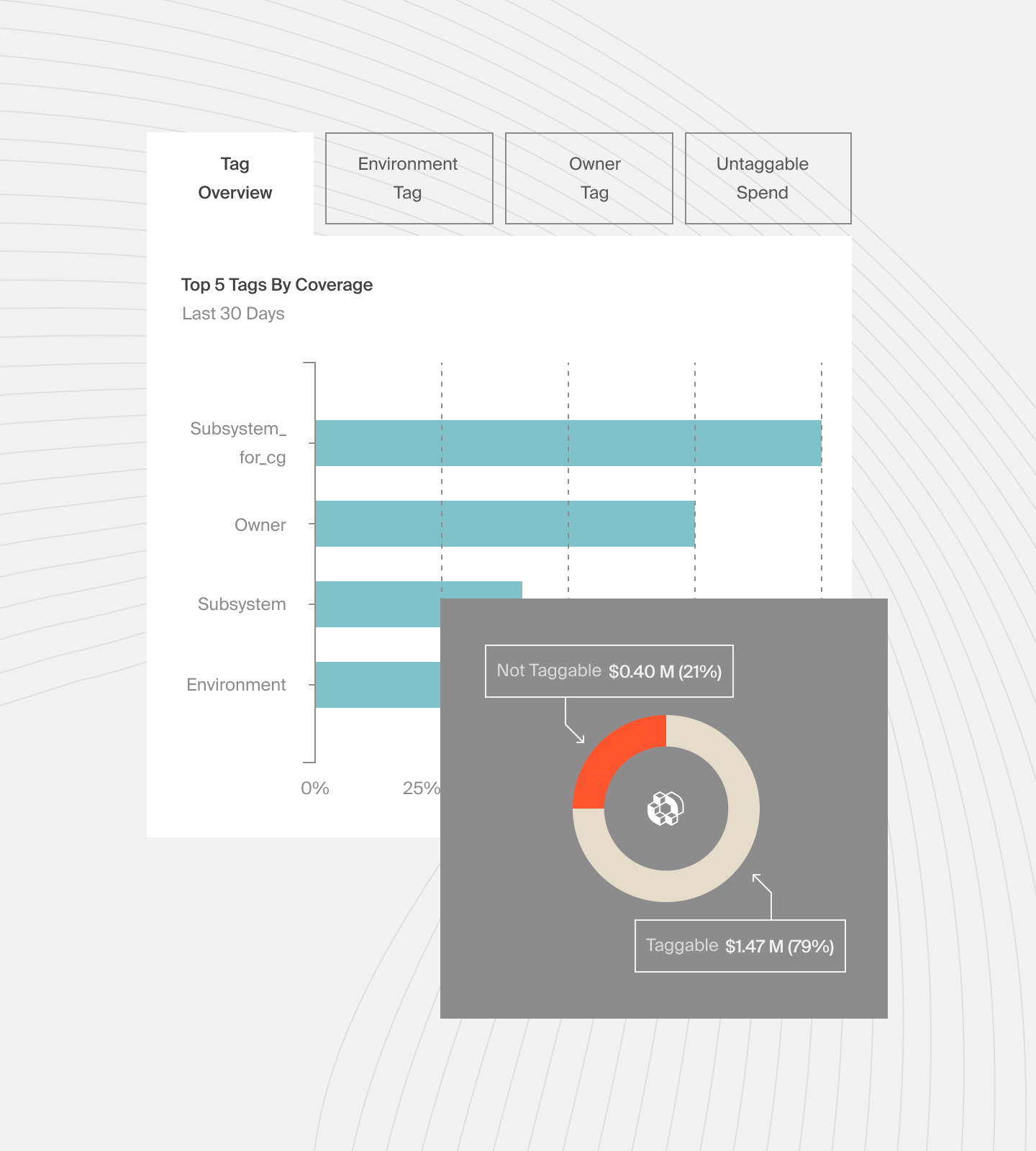
Also, while other tools will demand that you have perfect tags, CloudZero works even if you have messy tags. Yet, you’ll be able to view accurate costs across tagged, untagged, and untaggable resources — and cost per individual cost center in shared environments.
CloudZero also empowers you with real-time cost anomaly detection. Whenever your costs are trending, we’ll send you timely, noise-free, and context-rich alerts so you can identify and correct any overspending.
These are just a few of the CloudZero benefits that Drift has used to save over $4 million on AWS. And, LawnStarter recently used CloudZero to reduce its cloud storage costs by 55%.
You’ll also be joining Remitly, MalwareBytes, and Skyscanner in taking control of your cloud costs within days — not months.  to experience CloudZero for yourself.
to experience CloudZero for yourself.











