
Amazon Redshift processes petabytes of data, making it one of the most popular data warehousing solutions on the market.
It uses Massively Parallel Processing (MPP) technology to process massive volumes of data at lightning speeds. Plus, Redshift costs a fraction of the cost of other data platforms.
This guide will provide a deeper understanding of Redshift to help you determine whether it’s the best data warehouse solution for your organization.
What Is AWS Redshift?
AWS Redshift is a data warehousing database from Amazon Web Services. Redshift shines in its ability to handle huge volumes of data — capable of processing structured and unstructured data in the range of exabytes (1018 bytes). However, the service can also be used for large-scale data migrations.
Similar to many other AWS services, it can be deployed with just a few clicks and provides a plethora of options to import data. Additionally, the data in Redshift is always encrypted for added security.
Redshift helps to gather valuable insights from a large amount of data. With the easy-to-use interface of AWS, you can start a new cluster in a couple of minutes, and you don’t have to worry about managing infrastructure.

Research Report
FinOps In The AI Era: A Critical Recalibration
What 475 executives told us about AI and cloud efficiency.
How Does Redshift Work?
Redshift organizes data in a columnar format. Each column contains data of a specific type, such as integers, text, or dates. This approach is different from traditional row-based databases, where all values for a row are stored together.
Now look at this:
Credit: AWS
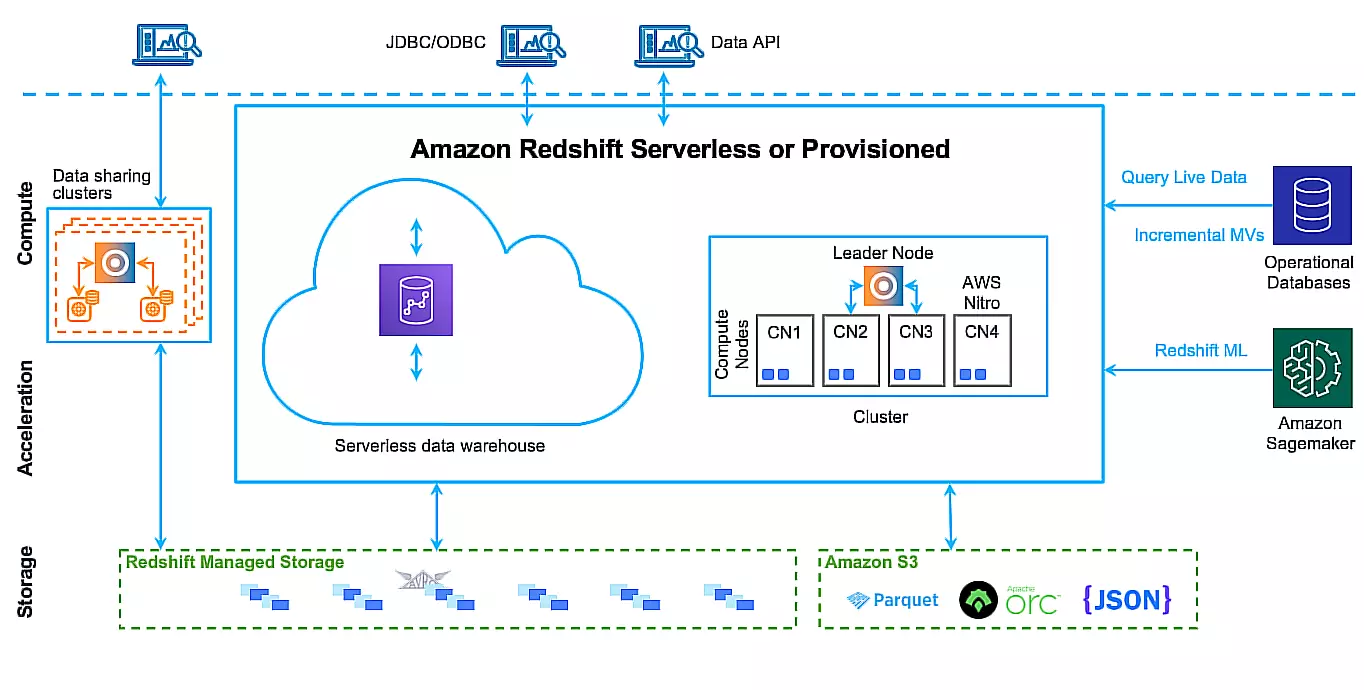
Redshift pulls data from sources like Amazon S3 using formats such as Parquet, ORC, or JSON, storing it in Redshift Managed Storage. This integration with S3 enables Redshift to handle vast amounts of data with efficient storage.
For compute, Redshift can be deployed in two modes: serverless or provisioned. In provisioned mode, Redshift clusters use a Leader Node. This coordinates query processing across Compute Nodes (CN1-CN4), which handle parallel execution. Serverless mode dynamically allocates compute resources based on query demand, enabling you to scale without managing the underlying infrastructure.
Users can also interact with Redshift through JDBC/ODBC or the Data API, which supports querying and reporting. Redshift processes queries using its MPP technology to split workloads across multiple nodes.
Redshift ML also enables predictive analytics by integrating with Amazon SageMaker. This enables users to embed machine learning models into their queries. Redshift can also query real-time data from operational databases using incremental materialized views, combining historical and live data for in-depth analysis.
What Is Unique About Redshift?
Redshift is an OLAP-style (Online Analytical Processing) column-oriented database. It is based on PostgreSQL version 8.0.2. This means regular Redshift SQL queries can be run natively without learning a new query language. But this is not what separates it from other services. The fast delivery to queries made on a large database with exabytes of data is what helps Redshift stand out.
Fast querying is made possible by Massively Parallel Processing design, or MPP. ParAccel developed the technology. With MPP, a large number of computer processors work in parallel to deliver the required computations. Sometimes, processors situated across multiple servers can be used to deliver a process.
Unlike most MPP vendors, ParAccel does not sell MPP devices. Their software can be used on any hardware to harness the power of multiple processors. AWS Redshift uses the MPP technology of ParAccel. In fact, Redshift was started following capital investment by AWS in ParAccel and using MPP technology from ParAccel. Now the company is part of Actian.
What Is Redshift Used For? When Would You Want To Use Amazon Redshift?
Amazon Redshift is used when the data to be analyzed is humongous. For Redshift to be a viable solution, the data has to be at least a petabyte-scale (1015 bytes). The MPP technology used by Redshift can be leveraged only at that scale. Beyond the size of the data, there are some specific use cases that warrant its use.
Real-time analytics
Many companies need to make decisions based on real-time data and implement solutions quickly. Take Uber, for example.
Based on historical and current data, Uber has to make decisions quickly. It has to decide surge pricing, where to send drivers, what route to take, expected traffic, and a whole host of data.
For a company like Uber with operations worldwide, thousands of such decisions have to be made every minute. The current stream of data and historical data have to be processed to make those decisions and ensure smooth operations. Such instances can use Redshift as the MPP technology to access and process data faster.
Combining multiple data sources
There are occasions where structured data, semi-structured data, and/or unstructured data have to be processed to gain insights. Traditional business intelligence tools lack the capability to handle the varied structures of data from different sources. Amazon Redshift is a potent tool in such use cases.
Business intelligence
An organization’s data needs to be handled by many different people. Not all of them are data scientists and will not be familiar with the programming tools used by engineers.
They can rely on detailed reports and information dashboards with an easy-to-use interface. Redshift can be used to build highly functional dashboards and automatic report creation. It can be used with tools like Amazon Quicksight and third-party tools created by AWS partners.
Log analysis
Behavior analytics is a powerful source of useful insights. It provides information on how a user uses an application, how they interact with it, the duration of use, their clicks, sensor data, and a plethora of other data.
The data can be collected from multiple sources — including a web application used on a desktop, mobile phone, or tablet — and can be aggregated and analyzed to gain insight into user behavior. This coalescing of complex datasets and computing data can be done using Redshift.
The AWS Redshift data warehouse can also be used for traditional data warehousing needs. But solutions like the S3 data lake would likely be better suited for that. Redshift can be used to perform operations on data in S3, and save the output in S3 or Redshift.
The Benefits of Using AWS Redshift
The very distinctive advantage of using AWS Redshift is the cost-benefit to your organization. It costs only a fraction (roughly one-twentieth) of the cost of competitors like Teradata and Oracle.
In addition to cost, there are a number of benefits to using Redshift.
- Speed. With the use of MPP technology, the speed of delivering output on large data sets is unparalleled. No other cloud service providers can match the speed at the cost AWS provides the service.
- Data encryption. Amazon provides the facility for data encryption for any part of Redshift operation. You, as the user, can decide which operations need encryption and which do not. Data encryption provides an added layer of security.
- Use familiar tools. Redshift is based on PostgreSQL. All the SQL queries work with it. Additionally, you are free to choose any SQL, ETL (Extract, Transform, Load), and Business Intelligence (BI) tools you are familiar with. There is no requirement to use the tools provided by Amazon.
- Intelligent optimization. For a large data set, there would be a number of ways to query data with the same parameters. The different commands will have different levels of data utilization. AWS Redshift provides tools and information to improve queries. It will also provide tips to improve the database automatically. These can be utilized for an even faster operation that is less intensive on resources.
- Automate repetitive tasks. Redshift has the provisions by which you can automate tasks that have to be done repeatedly. This could be administrative tasks like generating, daily, weekly, or monthly reports. It could be resource and cost auditing. It can also be regular maintenance tasks to clean up data. You can automate all these with the provisions offered by Redshift.
- Concurrent scaling. AWS Redshift will scale up automatically to support increasing concurrent workloads.
- Query volume. The MPP technology shines in this aspect. You can send thousands of queries to the dataset at any given time. Still, Redshift will not slow down in any shape or form. It will dynamically allocate processing and memory resources to handle higher demand.
- AWS integration. Redshift works well with the rest of the tools from AWS. You can set up the integrations between all the services according to your needs and optimal setup.
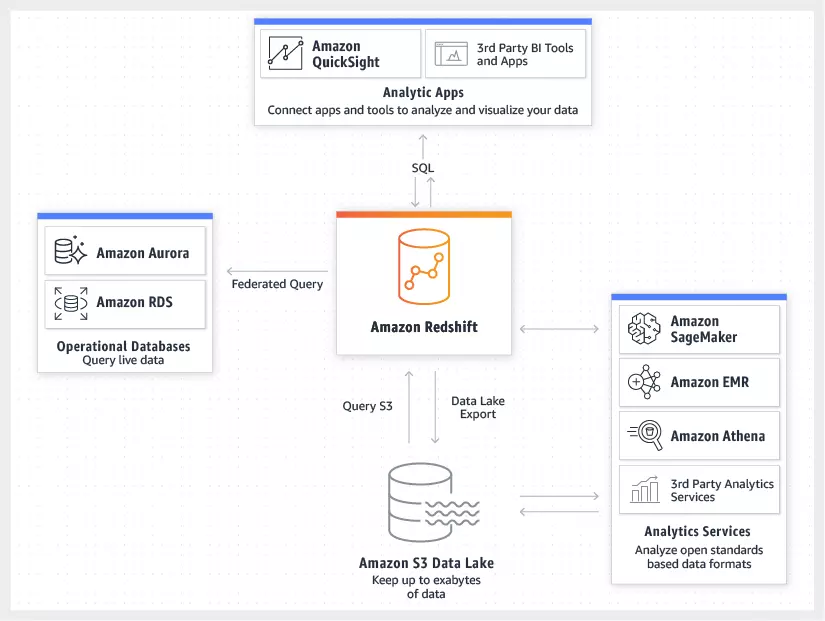
- Redshift API. Redshift has a robust API with extensive documentation. It can be used to send queries and bain results using API tools. The API can also be used within a Python program for easier coding.
- Security. The security of the cloud is handled by Amazon and the security of the applications within the cloud has to be provided by users. Amazon provides provision for access control, data encryption, and virtual private cloud to provide an added level of security.
- Machine Learning. Redshift uses machine learning to predict and analyze queries. This, in addition to MPP, makes the performance of Redshift faster than other solutions in the market.
- Easy deployment. A Redshift cluster can be deployed in any part of the world from anywhere in a matter of just minutes. You can have a high-performing data warehousing solution at the fraction of the price set by competitors in mere minutes.
- Consistent backup. Amazon automatically backs up data regularly. This can be used to restore in the event of any faults, failures, or corruption. The backups are spread across different locations. So this eliminates the risk of faults at a location as a whole.
- AWS analytics. AWS offers plenty of analytical tools. All of these can work well with Redshift. Amazon provides support to integrate other analytical tools with Redshift. Redshift has native integration capabilities with AWS analytics services.
- Open formats. Redshift supports and can provide outputs in many open formats for data. The most common formats supported are Apache Parquet and Optimized Row Columnar (ORC) file formats.
- Partner ecosystem. AWS is one of the oldest cloud service providers. A lot of customers depend on Amazon for their infrastructure. In addition to that AWS has a strong network of partners that builds third-party applications and offers implementation services. This partner ecosystem can also be tapped to see if you can find an implementation solution that is perfect for your organizations.
The data collected will grow every day. Redshift is a hedge against the growing data with increasing analytical complexity. It can be used to build infrastructure that lasts into the future.
Common AWS Redshift Pitfalls to Avoid
Here are some of the common mistakes users encounter when working with AWS Redshift and how to mitigate them.
Treating Redshift like PostgreSQL
Users often assume Redshift will function the same way as PostgreSQL when running queries or managing databases. Redshift is optimized for large-scale data analytics (OLAP). PostgreSQL is built for transaction-based workloads (OLTP). Using Redshift like a transactional database can result in poor performance. To avoid this, remember that Redshift is built for data warehousing and is optimized for bulk operations, not frequent updates or deletes typical in transactional workloads.
Loading data incorrectly
Efficient data loading into Redshift is critical to performance. Users mistakenly load small batches, causing overhead and slower execution. Redshift performs best with large batches, processed in parallel via the COPY command. For optimal speed and resource use, load data in larger chunks from Amazon S3 using COPY.
Ignoring maintenance and backups
Redshift handles backups and maintenance automatically, but users often overlook monitoring these tasks. Without regular backups, data loss is a risk during failures. Additionally, unscheduled maintenance during peak hours can cause performance issues. To prevent this, schedule maintenance during low-usage periods and ensure backup strategies are in place.
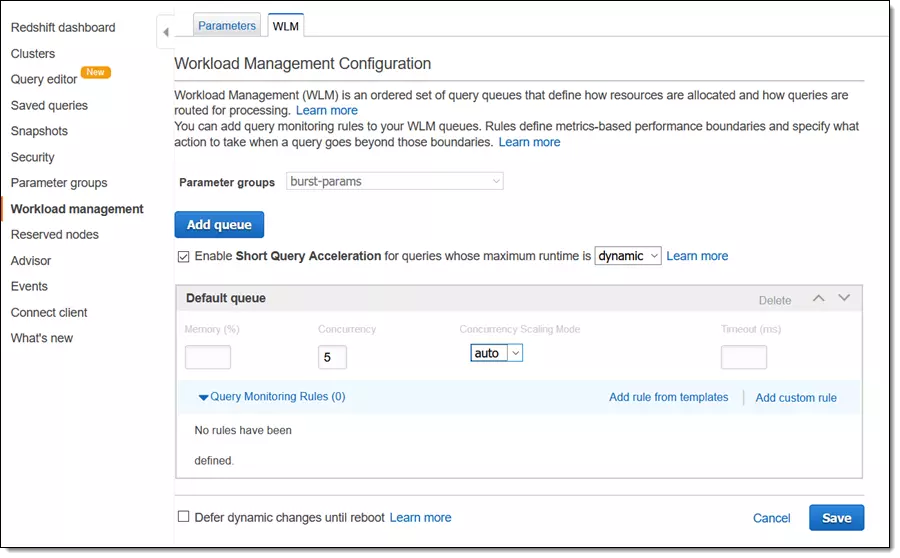
Not utilizing workload management (WLM)
Redshift uses a queue-based system called Workload Management (WLM) to manage queries. Without properly configuring WLM, high-priority queries can get stuck behind lower-priority tasks, leading to inefficient query performance. Many users make the mistake of sticking with the default WLM settings, which may not align with their workload needs. To avoid this pitfall, configure WLM to create custom queues that match your workload. Assign higher memory and priority to critical queries and lower resources to less important jobs.
Poor schema design
Redshift’s columnar database structure demands careful schema design to optimize performance. Failing to plan distribution keys, sort keys, and compression strategies can result in slow queries and inefficient storage use. Design the schema on query patterns, using distribution keys for data balance and sort keys for faster query execution.
Dimensioning the cluster poorly
Choosing the wrong cluster size is a common mistake. Over-provisioning leads to unnecessary costs, while under-dimensioning causes performance issues. Analyze your workload carefully to determine the optimal cluster size, and take advantage of the Redshift Advisor tool for recommendations based on your usage.
Mismanaging concurrency scaling
Concurrency scaling is great for handling heavy query loads, but if you’re not careful, it can lead to unexpected costs. Keep an eye on how often it’s triggered and make sure it fits within your budget.
What Are the Limitations of AWS Redshift?
Redshift has some drawbacks that need to be considered before choosing it as your data warehousing solution.
- Parallel uploads. Redshift does not support all databases for parallel upload. Amazon S3, EMR, and DynamoDB are supported by Redshift for parallel uploads using ultra-fast MPP. For other sources, separate scripts have to be used to upload data. This can be a very slow process.
- Uniqueness. One of the basic tenets of a database is to have unique data and avoid redundancies. AWS Redshift does not provide any tool or means to ensure the uniqueness of data. If you are migrating overlapping data from different sources to Redshift, there will be redundant data points.
- Indexing. This becomes a problem when Redshift is used for data warehousing needs. Redshift uses distribution and sorts keys to index and store data. You will need to know the concepts behind the keys to work on the database. AWS does not provide any system to change the keys or manage them with minimal knowledge.
- OLAP limitations. OLAP databases (which Redshift is) are optimized for analytical queries on a large volume of data. Compared to traditional OLTP (Online Transaction Processing) databases, OLAP lacks in performing basic database tasks. Insert/update/delete operations have performance limitations in OLAP databases. It is often easier to recreate a table with changes than to insert/update tables in Redshift. While OLAP works well with static data, OLTP databases perform better for data modification operations.
- Migration cost. Redshift is used in cases where the data to be stored or worked with is humongous. It will at least be in the range of petabytes. At this level, bandwidth becomes a problem. You will need to transfer this data to AWS locations before you can begin the project. This could be a potential problem for businesses that have network caps for bandwidth. The additional cost will have to be borne by the user. AWS does provide the option to send the data using physical storage devices.
AWS Redshift Pricing Model
AWS offers a very flexible pricing scheme for Redshift. The price starts at $0.25 per hour for a terabyte of data and it can be scaled from there. First, you need to opt for the node type you want. AWS Redshift offers three types of nodes.
- RA3 nodes with managed storage. Here, you will need to pick the level of performance you require, and the managed storage will be billed on a pay-as-you-go basis. The number of RA3 clusters you have to choose will depend on the amount of data processed on a daily basis.
- DC2 Nodes. These should be chosen when you need high performance. Local SSD (Solid State Drive) storage is included with the nodes. You will need to add more nodes when the size of the data grows. DC2 nodes are best suited when the data is relatively small in size and needs superlative performance.
- DS2 nodes. It should be opted for when there is a large data set that needs to be stored. DS2 provides only HDD (Hard Disk Drives) and has a slower performance compared to other nodes. But it is also considerably cheaper.
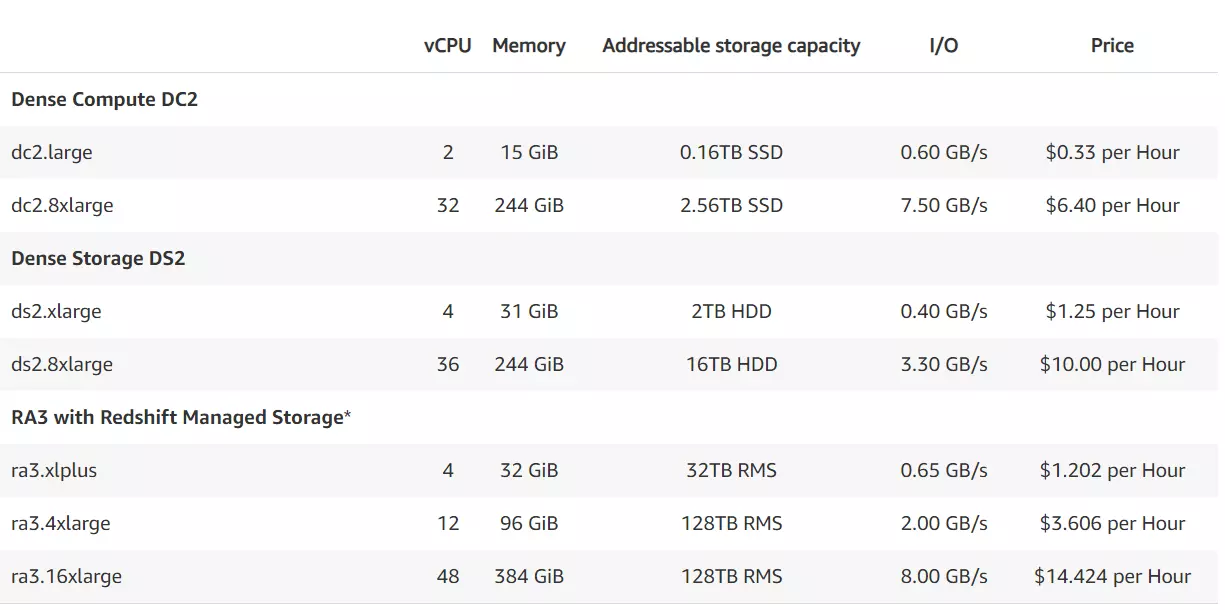
Prices at US-North California center
Redshift also has a pay-as-you-go pricing model according to the requirements.
- Amazon Redshift spectrum pricing. When you need to run SQL queries on a large dataset in an S3 data lake, you pay according to the usage. Even if the data in S3 is of exabyte range, you will only need to pay according to the amount of data scanned. The price was $5 per terabyte scanned for the North California location.
- Concurrency scaling pricing. Concurrency scaling enables you to dynamically allocate resources according to the demand. AWS automatically provides additional resources even if the number of queries and users multiply. You will only need to pay according to the usage. In addition, each cluster has one scaling credit every day. This will be sufficient for 97% of the customers according to past AWS data.
- Redshift managed storage pricing. This pricing model will divide the computing and storage costs of RA3 nodes. That way you need not add more nodes when data requirement increases. RA3 nodes are costlier for storage purposes compared to using separate managed storage.
- Redshift ML. You can use SQL queries to train ML models. You will be able to use the free credits of Amazon Sagemaker before you have to pay for creating ML models.
Detailed pricing details are provided on the AWS Redshift pricing page.
AWS Redshift Alternatives: How Do Redshift Competitors Compare?
Is Redshift the right data platform for you? Maybe. Perhaps not. You can weigh your options by considering these alternatives.
1. Amazon Redshift vs. Snowflake
Storage and compute run on separate layers within Snowflake’s cloud data platform. Scalability and concurrency are seamless with this architecture, ensuring high performance at all times. Redshift does not separate compute from storage. It is still fast for the volume of data it processes, but it can become slow if there’s lots of concurrent usages required.
Here are some additional significant differences between Snowflake and Amazon Redshift:
- With Snowflake, a SaaS, you don’t have to install additional software or hardware. Plus, Snowflake takes care of all system updates, upgrades, and other maintenance for you. As a PaaS, Redshift provides more customizability and capacity, but also requires more maintenance effort.
- Using Massive Parallel Processing, Redshift speeds up and eliminates repetitive ELT/ETL tasks. Snowflake uses a custom approach to reduce latency.
- The Snowflake service automatically compresses your data and charges you based on the compressed volume. Data compression in Redshift is not automated by default.
- You can customize Redshift’s compute nodes and cluster size. Snowflake’s fully managed data cloud allows you to set your cluster size, but you cannot customize compute nodes.
- Redshift supports both cloud and on-premises environments, but Snowflake is only available for cloud-based usage.
- Snowflake offers high performance, cloud-native support, and always-on encryption, while Redshift provides good performance, is cost-effective for large volumes of data, and has excellent AI and machine learning capabilities.
- Redshift works only within Amazon Web Services (AWS), while Snowflake works natively across AWS, Azure, and GCP.
Want to learn more about Snowflake? Start with what Snowflake is or check our quick yet in-depth Snowflake Vs. Amazon Redshift comparison here. It includes pricing differences, too.
2. Amazon Redshift vs. Databricks
There are a number of differences between Databricks and Amazon Redshift, including:
- Databricks is a SaaS, while Redshift is a PaaS. SaaS requires less management effort, but comes at the cost of fewer configuration options and capacity than a PaaS platform.
- Unlike Redshift, Databricks separates compute and storage to support high concurrency rates and independent scaling.
- While Redshift is limited to AWS cloud data functions, Databricks works across AWS, GCP, and Azure.
- Databricks uses Apache Spark, an open-source framework that supports ultra-fast in-memory processes versus Amazon Redshift.
- While Databricks runs Spark SQL to interact with structured data, Redshift is based on PostgreSQL for handling structured, semi-structured, and unstructured data warehouse functions.
Check out this Databricks pricing guide to learn more about Databricks features, services, and more.
3. Amazon Redshift vs. Amazon Athena
Some quick differences between Athena and Redshift include:
- Redshift is built to run fast petabyte-scale data warehouse requirements while Athena is designed to be an ultra-fast and portable serverless option.
- Unlike Amazon Athena, Redshift supports User Defined Functions (UDFs) with scalar and aggregate functions.
- While Redshift is based on PostgreSQL, Amazon Athena is ideal for operations using Presto and ANSI SQL based datasets on Amazon S3.
- Amazon Athena delivers near-instant startup and scalability compared to 15-60 minutes it takes with Redshift.
- While Amazon Redshift requires additional ELT/ETL steps to work, Athena analyzes data where it lives.
- Because Athena is built on an open-source framework (Apache Spark), it supports more than 25 data sources, including both on-premises and cloud-based one that use Python and SQL.
- Amazon Athena accommodates complex data types including arrays, structs, and maps compared to Redshift which does not support some types, such as arrays and Object Identifier Types.
See our snackable Amazon Athena guide to learn more about the AWS serverless service.
4. Amazon Redshift vs. Azure Synapse Analytics
Redshift and Azure Synapse use shared-nothing MPP technology to process multiple queries simultaneously. They do, however, have some notable differences:
- Azure Synapse Analytics is Microsoft’s native cloud data platform and analytics solution. Redshift is also only available through AWS.
- Synapse Analytics separates compute and storage layers, allowing each layer to scale independently and reduce latency. The Redshift platform bundles compute and storage, which can cause it to slow down during peak concurrency loads.
- Redshift clusters take 15-60 minutes to scale up or down while Azure Synapse Analytics takes under 15 minutes.
- While Redshift applies permissions to tables as a whole, Azure Synapse Analytics provides specific permissions on tables, schemas, views, procedures, individual columns, and other objects.
5. Amazon Redshift vs. Amazon RDS
Here’s a quick look at the differences between Amazon Relational Database Service and Amazon Redshift.
- Amazon RDS is a fully managed Database-as-a-Service solution while Redshift is a managed data warehouse platform (and supports a data lake approach as well).
- Redshift is designed to access data residing locally in a cluster or externally from third-party sources. But RDS databases are not intended for access to data outside their local storage systems and predefined formats.
- Amazon Redshift can handle petabyte-scale data volumes (up to 128 TB per node), but most database engines in Athena are limited to 64 TB.
- There are more configuration options available with Amazon RDS than with Redshift. As an example, RDS allows you to select your preferred AWS instance family, node type, and size, storage capacity, and storage types, whereas Redshift allows limits configuration to the type, size, and number of nodes you want.
Would you like to learn more about RDS? Here’s a bookmarkable guide to Amazon RDS pricing and more.
Want to use a database service that isn’t from Amazon Web Services? In that case, check out our MongoDB pricing guide as well.
Managing and Understanding Your AWS Redshift Costs
AWS Redshift can integrate with Amazon S3, AWS Glue, Amazon Kinesis Data Firehose, Amazon Quicksight, and over 170 other AWS services. Though each service has advantages, using them all simultaneously can drastically inflate your AWS bill.
Many of the services you use might be redundant, and there will be better ways to reduce costs.
Additionally, mapping costs from specific services that make up your products and features can be a nearly impossible task when done manually or using a traditional cloud cost management tool.
Whether your goal is to reduce your AWS bill with AWS cost optimization tools, understand your cloud costs, or map costs to the products or features your business cares about, CloudZero can help you achieve all three and gain true cloud cost visibility.
 to see CloudZero in action and learn more about how it can help you optimize your Redshift and other AWS costs.
to see CloudZero in action and learn more about how it can help you optimize your Redshift and other AWS costs.
FAQ
What does Redshift do in AWS?
Amazon Redshift is a data warehousing service that enables fast querying and analysis of large volumes of data. It enables users to gain insights from structured and unstructured data.
Is AWS Redshift an ETL tool?
No, AWS Redshift is not an ETL tool. It’s a data warehouse, but it works with ETL tools such as AWS Glue to load and transform data for analysis.
Is Amazon Redshift a SQL database?
Yes, Amazon Redshift is a SQL-based database for analytics and large-scale data queries, built on PostgreSQL.
What is the difference between S3 and Redshift?
Amazon S3 is a storage service for raw data, while Redshift is a data warehouse for analyzing that data. Redshift delivers fast queries and insights, whereas S3 is optimized for storage.


FinOps In The AI Era: A Critical Recalibration
What 475 executives told us about AI and cloud efficiency.


