
Quick Answer
Kubernetes cost optimization is the practice of reducing cloud waste in K8s environments by rightsizing workloads, eliminating idle resources, leveraging autoscaling, and connecting infrastructure spend to business value. The most effective Kubernetes cost optimization strategies include gaining granular Kubernetes cost monitoring at the pod and namespace level, using horizontal and vertical pod autoscalers, choosing cost-efficient instance types, and reducing unnecessary data transfer. Organizations that implement these best practices cut Kubernetes costs by 30–50% without performance trade-offs.
With 80% of organizations now running Kubernetes in production, up from 66% the year before, according to the CNCF 2024 Annual Survey, K8s has become the default compute layer for modern applications. But adoption doesn’t equal efficiency. Datadog’s State of Cloud Costs report found that 83% of container costs go to idle resources, split between overprovisioned Kubernetes cluster infrastructure (54%) and oversized workload requests (29%).
This guide covers the strategies, architectural changes, and tools that close the gap between what you’re paying and what you’re actually using.
What Is Kubernetes Cost Optimization?
Kubernetes cost optimization is the practice of managing and reducing cloud cost across K8s clusters without degrading performance, reliability, or developer velocity.
It spans several disciplines: resource allocation and rightsizing, autoscaling, instance purchasing strategy, data transfer reduction, Kubernetes cost allocation, and connecting spend to business outcomes through unit economics.
The challenge is structural. Kubernetes pools compute across workloads, which hides cost drivers inside the cluster. Your cloud bill shows EC2 or GCE line items, not which namespaces, pods, or nodes are responsible. Without that visibility, Kubernetes cost reduction turns into guesswork.
As one CloudZero solutions engineer put it during a recent Kubernetes cost management webinar: “A lot of folks are getting asked monthly or quarterly about K8s cost spikes, and for many, it’s still hard to answer.”
Understanding the scale of the waste is the first step toward fixing it.
Report
Finance needs to prove AI’s return: CloudZero report
260 senior finance leaders (more than half CFOs) told us why the speed of seeing AI spend, not the size of it, separates who pulls ahead on AI from who gets burned.
How Much Do Kubernetes Environments Actually Waste?
The numbers are sobering. According to CAST AI’s 2025 Kubernetes Cost Benchmark, only 13% of provisioned CPUs are actually used in production clusters — meaning the vast majority of allocated compute sits idle. Industry estimates consistently place Kubernetes waste at 30–45% of total cluster spend, making it one of the highest-ROI cost optimization targets in any cloud budget.
Industry estimates consistently place overall cloud waste at 25–30% of total spend, according to Gartner.
“Every engineer thinks their workload is the exception, that it actually needs those resources,” says a CloudZero platform engineer. “Our data consistently shows they’re wrong by a factor of three to five.”
Here’s where the money goes in a typical unoptimized deployment:
- Compute Kubernetes overprovisioning is the largest cost driver. Teams set resource requests and limits for worst-case scenarios and never revisit them. The result: nodes running at a fraction of capacity, billed by the hour regardless. CloudZero engineers regularly see clusters where workloads consume less than 15% of requested CPU, the rest is paid-for waste.
- Cross-region and cross-AZ data transfer silently inflates bills. On AWS, cross-AZ data transfer costs $0.01 per GB in each direction. A cluster transferring 10 TB per month across availability zones pays roughly $200 monthly in avoidable network fees.
- Logging and monitoring overhead is the cost nobody expects. Debug-level logging left running in production can generate storage costs that dwarf the pod’s actual compute. CloudZero has observed cases where a pod consuming one-tenth of a node produced log storage costs three times the pod’s compute expense.
- Idle non-production environments left running 24/7 waste resources for 76% of the week. Dev and staging clusters provisioned identically to production are common offenders.
With the waste quantified, the question becomes: where do you start?
How Do You Reduce Kubernetes Costs Without Changing Architecture?
Not every Kubernetes cost optimization effort requires rearchitecting your application. Several high-impact Kubernetes cost reduction strategies come down to process, visibility, and purchasing decisions.
Get granular Kubernetes cost monitoring first
You can’t optimize what you can’t measure. The first step in Kubernetes cost management is breaking costs down beyond the cloud provider bill, into clusters, namespaces, labels, pods, and the services that depend on them.
A Kubernetes cost monitoring platform like CloudZero can allocate 100% of Kubernetes spend, including shared costs that most tools miss, and map it to business context like cost per customer, per product, or per team. “It really gives engineers business context, not only to take action, but also prioritize and deliver value to the business,” notes a CloudZero solutions engineer.
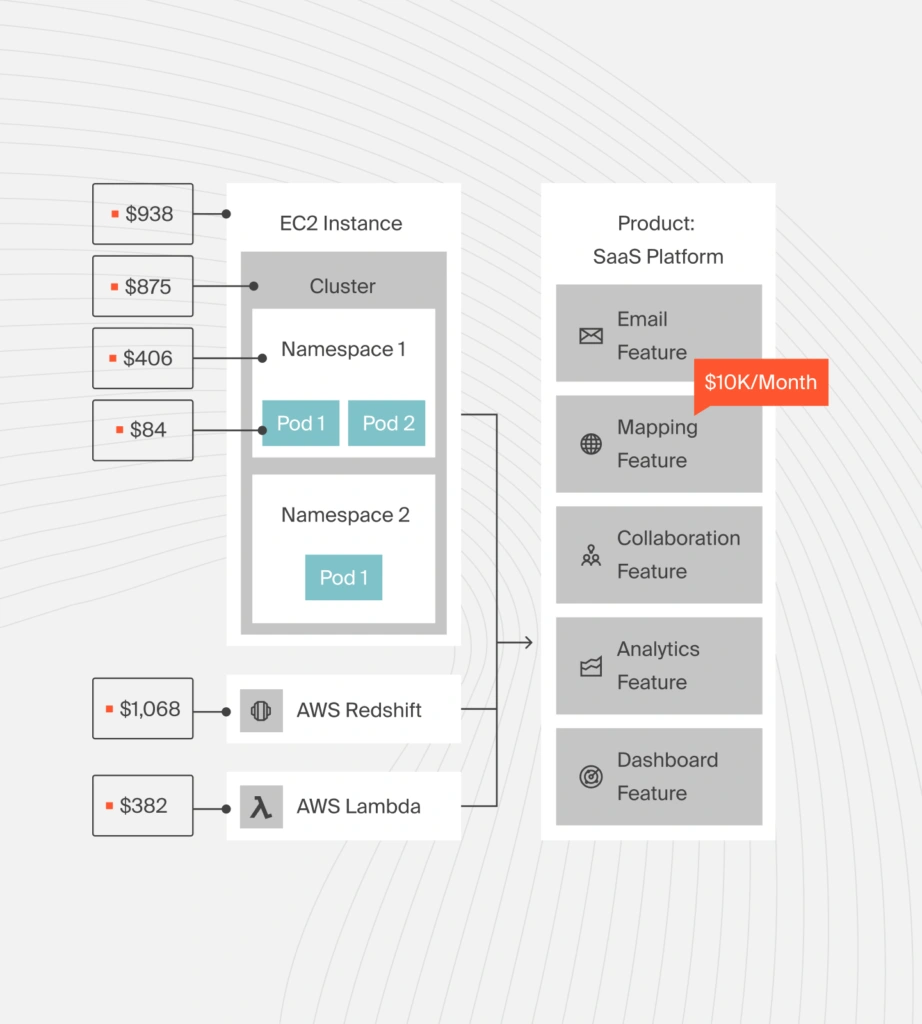
According to CloudZero’s 2024 State of Cloud Cost report, 89% of organizations say a lack of cloud cost visibility impacts their ability to do their job.
Track cost as an engineering metric
Treat cost the way you treat latency or uptime: measure it before and after every change, set acceptable thresholds, and review trends in sprint retrospectives. There’s no inherently “good” or “bad” Kubernetes cost, a mission-critical, revenue-generating service might justify high spend. The goal is awareness and intentional cost allocation, not blind reduction.
Buy smarter: Savings plans, reserved instances, and spot
Purchasing strategy alone can deliver dramatic Kubernetes cost savings.
Compute Savings Plans are AWS’s most flexible discount mechanism, offering up to 66% off on-demand pricing across EC2, Fargate, and Lambda. EC2 Instance Savings Plans offer up to 72% off but lock you to a specific instance family and region. Both require a one- or three-year hourly spend commitment.
Spot instances offer discounts up to 90% for interruptible workloads such as batch processing, CI/CD pipelines, and stateless microservices. The risk: spot capacity can be reclaimed with two minutes’ notice. Solutions like Xosphere manage spot interruptions intelligently, extending this option well beyond fault-tolerant batch jobs.
EKS management fees add up quietly. Each EKS Kubernetes cluster costs $0.10 per hour — roughly $73 per month, before any compute charges. Teams running multiple clusters should factor this fixed Kubernetes cluster cost into their optimization calculus.
Audit logging and monitoring costs
A CloudZero engineer at the K8s webinar explained the approach: “We use the 95th percentile to help eliminate those large spikes or one-times during the initial lifecycle. Java’s a popular one, we see the high initial start time, then it levels off.” The lesson: Kubernetes cost optimization best practices require recommendations that reflect how your workloads actually behave, not just what they spiked to once.
Check for debug-level logging left running in production. Evaluate whether third-party cloud monitoring tools are cost-justified compared to native alternatives, and use a unified platform to see those fees alongside your application costs.
Purchasing and process improvements can get you 30–40% of the way there. Architectural changes unlock the rest.
What Architectural Changes Lower Kubernetes Costs The Most?
Architectural Kubernetes optimization delivers the deepest cost reductions but requires more careful implementation.
Rightsize nodes with autoscaling
Reducing the number of running nodes is the most direct path to lower Kubernetes costs. Three autoscaling tools work together:
- Horizontal Pod Autoscaler (HPA) scales the number of pods based on CPU utilization, memory, or custom metrics, handling demand spikes without static peak provisioning. As Datadog’s 2025 State of Containers report notes, 86% of HPA users apply it across most of their clusters, making it a foundational part of Kubernetes resource management.
- Vertical Pod Autoscaler (VPA) adjusts CPU and memory Kubernetes requests vs limits for individual pods based on observed usage, catching chronic overprovisioning that happens when developers set requests once and never revisit them. This is the core of Kubernetes pod rightsizing.
- Cluster Autoscaler (or Karpenter on AWS) adjusts the number and size of nodes to fit current scheduling needs — removing nodes when pods don’t need capacity, adding them when demand increases.
“Autoscaling isn’t set-and-forget. It’s set-and-observe,” says a CloudZero platform engineer. “The teams getting the best results review their scaling parameters monthly, not quarterly.”
Used together, these keep your cluster right-sized continuously, which is the foundation of automated Kubernetes cost optimization.
Reduce cross-region and cross-AZ data transfer
Data transfer charges are Kubernetes’ hidden cost multiplier. Pods communicating across availability zones or regions generate per-GB fees that compound at scale.
Practical steps: keep frequently communicating pods in the same availability zone using topology-aware scheduling, set up VPC endpoints for AWS services so pods don’t route through the public internet, and consider single-zone namespace deployments where multi cloud redundancy isn’t required. CloudZero can help break apart node costs to show what network data fees are costing at each region or availability zone.
Evaluate your multi-cloud strategy honestly
Multi cloud Kubernetes deployments are common but often more expensive than teams expect.
Running clusters across multiple cloud providers introduces cross-cloud networking costs and prevents you from fully leveraging provider-specific discounts. Unless there’s a strong business case for portability, regulatory requirements, vendor risk mitigation, consolidating on a single provider’s managed K8s service usually produces better cost outcomes.
The right tooling can make the difference between all of these strategies staying theoretical and actually driving results.
What Are The Best Kubernetes Cost Optimization Tools In 2026?
The right Kubernetes cost optimization tools depend on whether your priority is visibility, automated optimization, or connecting costs to business outcomes.
Tool | Best for | K8s cost allocation | Multi-cloud | Unit economics | Pricing model |
Full K8s cost management + business intelligence | Cluster, namespace, label, pod | AWS, GCP, Azure, Oracle, etc. | Cost per customer, feature, team | Tiered pricing model | |
Self-hosted k8s cost monitoring | Namespace, deployment, service | AWS, GCP, Azure, IBM | Limited | Free tier + paid | |
Automated node optimization | Namespace, workload | AWS, GCP, Azure | No | Free monitoring + paid | |
Enterprise financial management | Node, namespace, labe | AWS, GCP, Azure, IBM | Limited | Enterprise contract | |
AWS-native Kubernetes cost analysis | Tag, service-level | AWS only | No | Free (basic) + paid |
CloudZero
CloudZero stands apart because it treats Kubernetes cost optimization as a business problem, not just a technical one. Beyond unit economics, the platform allocates 100% of Kubernetes spend regardless of labeling quality, unifies K8s costs with all other cloud spend in a single view, provides hourly granularity down to the pod level, flags cost anomalies with real-time alerts, and surfaces automated savings opportunities through CloudZero Insights.
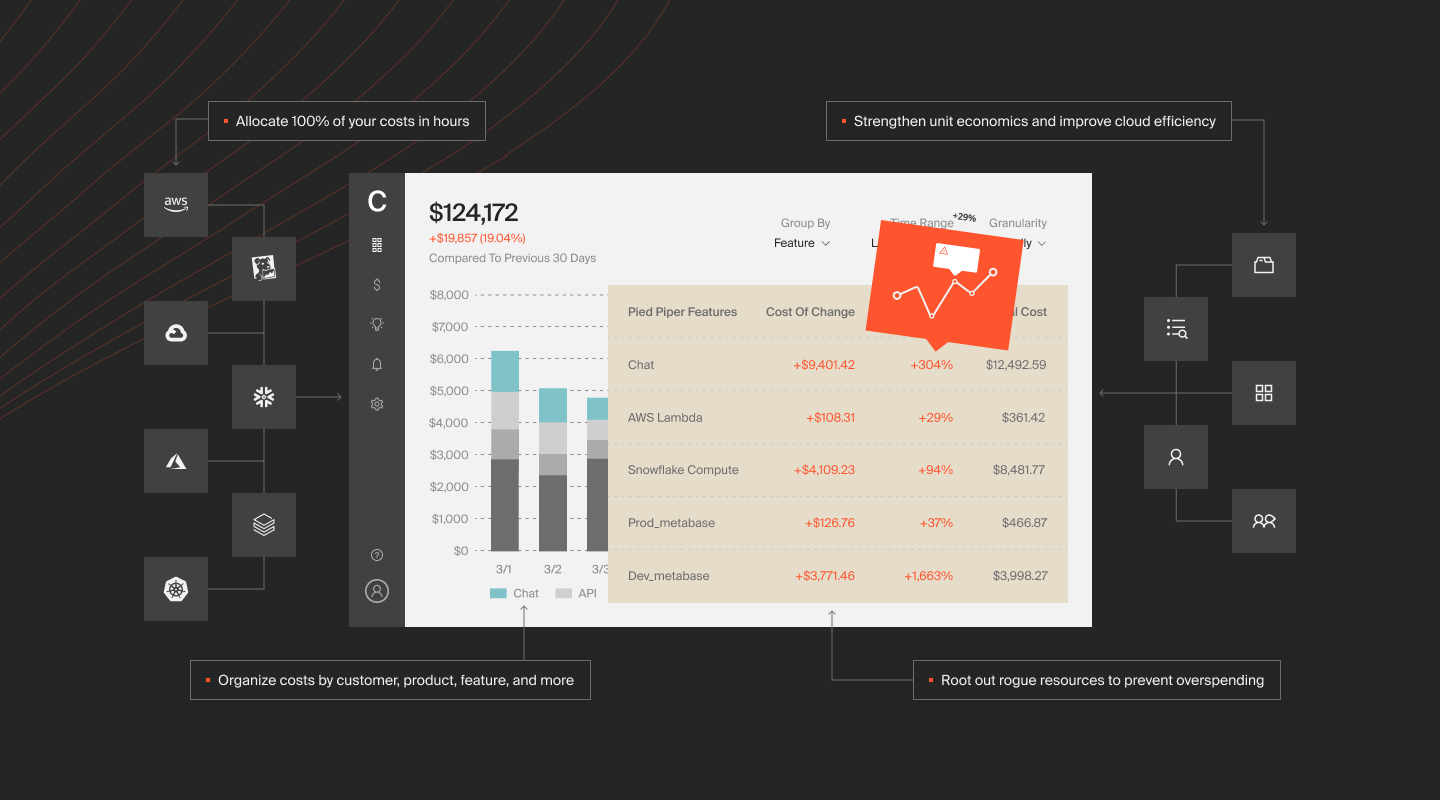
The result: engineering, finance, and FinOps teams share one source of truth for Kubernetes costs, which is what makes optimization stick.
IBM Kubecost
Kubecost is a strong open source option for teams that need self-hosted Kubernetes cost monitoring with Prometheus and Grafana integration. It doesn’t require sending billing data to a third party, which appeals to security-conscious teams.
CAST AI
CAST AI focuses on automated Kubernetes cost optimization — Kubernetes workload rightsizing, bin-packing, and spot instance management. It is a good fit for teams that want hands-off compute optimization without deep cost allocation or unit economics.
IBM Cloudability
IBM Cloudability provides enterprise-grade financial cost management but is less Kubernetes-native than purpose-built tools.
AWS Cost Explorer
AWS Cost Explorer offers useful high-level Kubernetes cost views and forecasting but lacks the granularity to allocate shared Kubernetes costs at the namespace or pod level.
Choosing a tool is the beginning. The real goal is connecting all of this cost intelligence to what your business actually cares about.
Frequently Asked Questions About Kubernetes Cost Optimization
How Does CloudZero Help You Optimize And Manage Kubernetes Costs?
Reducing raw spend is only half the equation. The more important question, the one CloudZero was built to answer, is whether the spend was worth it.
CloudZero approaches Kubernetes cost optimization from several angles:
- 100% cost allocation, even without perfect labels. Most tools depend on tagging hygiene to allocate Kubernetes costs. CloudZero doesn’t. It allocates every dollar of K8s spend to clusters, namespaces, labels, and pods regardless of labeling quality, then maps that spend to the business dimensions that matter.
- Unified view of K8s + all other cloud spend. Most platforms segregate Kubernetes costs, which makes it harder to see the full picture. CloudZero unifies K8s spend with AWS, Azure, GCP, Snowflake, Datadog, and any other cost source into a single pane of glass.
- Hourly granularity at the pod level. CloudZero breaks down spend into cluster, namespace, label, and pod with hourly resolution, giving engineers the precision they need for Kubernetes cost analysis and Kubernetes cost reporting.
- Anomaly detection and real-time alerts. Machine learning algorithms flag unusual Kubernetes spending patterns before they become budget crises, sending alerts that help teams address cost spikes in hours instead of weeks.
- Budgeting and forecasting. Historical spend data fuels forecasts that help finance and engineering teams plan ahead, turning reactive Kubernetes cost management into a proactive discipline.
- Unit economics and business context. This is CloudZero’s core differentiator. Instead of asking “how much does Kubernetes cost?” you ask “what does it cost to serve each customer?” or “what’s the cost per transaction for this feature?” Discovering that your chat service costs $0.12 per active user while your analytics pipeline costs $0.03 tells you exactly where optimization effort has the biggest business impact. Without unit economics, both services look like undifferentiated Kubernetes spend.
“You don’t save money by knowing your bill. You save money by knowing why your bill looks the way it does, and whether the spend is delivering value,” says a CloudZero platform engineer.
Ready to see where your Kubernetes costs are actually going?  to get granular visibility into your K8s spend.
to get granular visibility into your K8s spend.











