
Data has exploded — and so have the challenges that come with it. Every click, transaction, and sensor ping generates mountains of data that traditional databases can’t handle.
That’s why more than 94% of organizations now rely on cloud platforms, according to CloudZero’s 2025 cloud report.
The goal isn’t just to store data, but rather, to make sense of it fast. And this is exactly where tools such as Google BigQuery step in.
This guide offers a deeper understanding of BigQuery to help you determine whether it’s the best data warehouse solution for your organization.
What Is BigQuery?
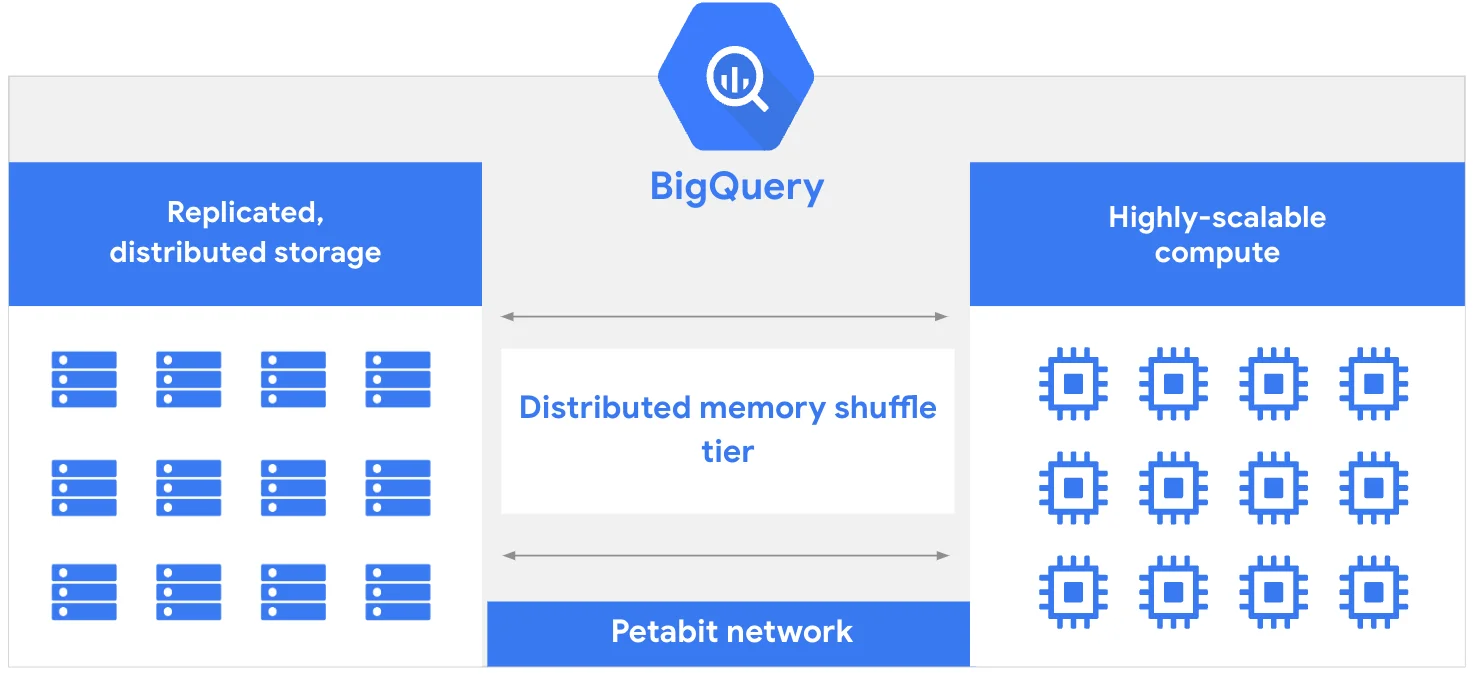
BigQuery is Google Cloud’s enterprise data warehouse built to handle massive datasets for analytics. It enables organizations to run fast, SQL-based queries across structured and semi-structured data from a few gigabytes to multiple petabytes.
It’s known for speed and elasticity. BigQuery distributes processing across Google’s global infrastructure. This allows teams to analyze billions of rows in seconds, even under heavy workloads.
BigQuery also integrates with Google Cloud services such as Looker Studio, Dataflow, and Vertex AI. These connections let teams move data, visualize insights, and apply machine learning, all without leaving the BigQuery environment.
playbook
The AI Cost Optimization Playbook
Traditional cloud cost management is broken. Here’s why — and how to make the switch to cloud cost intelligence.
BigQuery Architecture
BigQuery runs on a distributed architecture that separates storage from compute. This design allows organizations to scale both independently.
Storage layer
Data in BigQuery is stored in Colossus, Google’s distributed file system. Colossus provides automatic replication, fault tolerance, and encryption at rest. The data itself is stored in Capacitor, a columnar format optimized for analytics. Columnar storage improves compression and query speed by reading only the columns needed for analysis.
BigQuery supports partitioned and clustered tables, ensuring that queries only scan relevant data. This minimizes cost and latency. Semi-structured data, such as JSON, is handled efficiently using nested and repeated fields — a feature that lets users analyze complex datasets without flattening them.
Compute layer
Dremel powers query execution, Google’s query engine. When a query runs, Dremel converts it into an execution tree distributed across thousands of worker nodes. The leaf nodes, called slots, scan and filter data in parallel, while intermediate nodes, known as mixers, aggregate results. This parallelism allows BigQuery to process billions of rows in seconds.
Behind the scenes, Borg, Google’s cluster management system, dynamically allocates and schedules compute resources. The system scales compute capacity automatically, depending on query complexity and data volume.
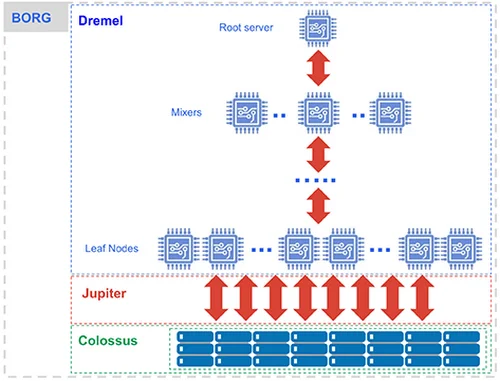
How BigQuery runs: Dremel handles queries, Colossus stores data, Jupiter moves it fast, and Borg manages resources.
Other supporting layers that make up BigQuery’s architecture include:
Metadata
Every distributed system needs a brain to manage schemas, partitions, and query planning. BigQuery’s metadata layer tells the compute engine where data lives and how to read it efficiently. Without this, the system couldn’t handle parallel query planning or cost-efficient execution.
Network layer (Jupiter)
BigQuery runs queries across thousands of machines in parallel. The network layer is what moves that data between storage and compute nodes fast enough for results to return in seconds.
What Is Unique About BigQuery?
BigQuery is the only enterprise-grade data warehouse that lets you query data stored in AWS and Azure directly from Google Cloud. The data stays in its original cloud — Omni, an extension of BigQuery, sends compute to where the data lives. That means no duplication, no ETL, and no egress costs. Snowflake, Redshift, Synapse, and Databricks don’t offer this natively.
While other warehouses integrate with external machine learning platforms, BigQuery is still the only one that trains, evaluates, and deploys ML models entirely inside SQL: no exports, no pipelines, no separate runtime.
Note: While BigQuery is a data warehouse, it can also function as a data lake. It queries external data, such as object data in cloud storage or structured data in Bigtable and Google Drive, through federated queries. Similarly, Snowflake and Redshift can query data in object storage (S3 or Azure Blob) and serve as lakehouse platforms too. Learn more about the difference between data warehouses and data lakes.
When Would You Want To Use BigQuery?
You’d want to use BigQuery when:
Want to build machine learning models without leaving SQL
With BigQuery ML, analysts can train and deploy predictive models right inside the data warehouse using standard SQL — no Python environment or separate ML pipeline required. A fintech team, for instance, can build churn or fraud detection models with simple SQL queries and evaluate them without ever leaving BigQuery.
You’re handling massive data volumes
BigQuery is ideal when your data grows beyond what traditional databases can manage. Think billions of rows from websites, mobile apps, or IoT devices. Spotify, for example, uses BigQuery to process event streams from its global user base, helping it personalize recommendations in near real time.
Need real-time insights
If your business depends on live metrics such as delivery status, user activity, or system health, BigQuery can handle streaming data as it arrives. Retailers use it to track transactions and inventory minute by minute, while logistics companies such as UPS rely on it to monitor operational data and detect anomalies instantly.
You’re integrating data from multiple sources
BigQuery serves as a seamless central analytics layer for companies utilizing multiple systems, ranging from marketing and CRM platforms to financial tools. Teams can pull data from Google Ads, Salesforce, or internal databases, then run unified reports that break down silos across departments.
Migrating legacy systems to the cloud
Organizations retiring on-premise systems often move their reporting workloads to BigQuery. It’s faster, cheaper, and eliminates the need for hardware or manual maintenance.
Note: Unlike Redshift, Snowflake, Databricks, or Azure Synapse, BigQuery isn’t built for traditional data warehousing. The others maintain persistent compute clusters and active SQL sessions. But BigQuery is stateless and serverless. Each query runs independently, without long-running environments or database-style transactions.
The Pros Of BigQuery
Serverless and no infrastructure management
You don’t need to provision or manage servers, clusters, or nodes. Google handles scaling, infrastructure, and maintenance behind the scenes.
High scalability and performance
It can scan massive datasets so fast, thanks to columnar storage, query optimizations, and disaggregated compute/storage architecture.
Support for external sources
You can query data stored in GCS or external storage via external tables or via BigLake, and use open table formats (Iceberg, Delta, Hudi) for interoperability.
Unlimited retention
No forced data retention limits; you can ingest and keep as much historical data as desired. You can also smoothly blend data from multiple sources.
Governance, security, and data sharing
Provides row- and column-level access controls, data masking, encryption, audit logging, policy tags, and capabilities for sharing datasets across teams.
The Cons Of BigQuery
Limited control over compute and query execution
You can’t deeply tune the underlying compute (e.g., you don’t manage cluster internals). In some workloads, you may want more fine-grained control over parallelism, hardware, caching, or compute behavior.
Not suited for heavy OLTP/frequent updates
BigQuery is not built for high-frequency, low-latency row-level updates or massively concurrent transactional workloads (inserts/updates/deletes). DML exists, but performance and cost can suffer.
Learning curve and SQL dialect differences
Some SQL features or behaviors differ from those of traditional RDBMSs. For new users, understanding partitioning, clustering, cost optimization, query planning, and the BigQuery SQL dialect can take time.
Vendor lock-in
Because BigQuery is tightly coupled with GCP, moving the workload to other providers may pose a challenge.
Cost risks and BigQuery cost optimization challenges
Because BigQuery charges by bytes processed, poorly optimized queries or select over large datasets can become expensive. Without intentional BigQuery cost optimization — such as partitioning tables, using clustered storage, or setting query quotas — costs can spiral quickly. Which brings us to the next section: how much does BigQuery cost?
BigQuery Pricing
BigQuery pricing consists of two main parts: compute and storage. You pay for the queries you run and the data you keep. Everything else, such as loading, exporting, or moving data between regions, is included in the total cost.
Compute pricing
Compute covers the power BigQuery uses to process your queries. You can choose between on-demand or capacity (slot-based) pricing.
- On-Demand: Pay $6.25 per terabyte (TiB) scanned. The first 1 TiB each month is free. Best for small or unpredictable workloads where you only pay when you query.
- Capacity: Buy dedicated slots (virtual CPUs) by the hour under Standard, Enterprise, or Enterprise Plus editions. You can commit for 1 or 3 years to get lower rates, or enable autoscaling for flexible workloads. Perfect for steady query volumes or large teams needing predictable costs.
Storage pricing
You’re billed for the data you store in BigQuery tables. There are two storage types:
- Active storage: Data changed in the last 90 days. Costs about $0.02 per GB per month. (For a broader look at how Google Cloud storage costs work across services, see GCP Storage Pricing.)
- Long-term storage: Data untouched for 90 days automatically drops to $0.01 per GB per month, with the same performance. You also get 10 GB of storage free every month.
Other costs that influence BigQuery costs include:
Cost type | Description |
Data ingestion | Loading data from Cloud Storage is free. Streaming inserts via Storage Write API cost ≈ $0.025 / GB (first 2 TiB free) |
Data extraction | Exporting query results to Cloud Storage (same region) is free. Streaming reads cost ≈ $1.10 / TiB read |
Network egress | Moving data across regions or outside Google Cloud adds standard transfer fees |
Replication | Multi-region storage or cross-region copies cost extra for both storage and transfer |
Notebook runtimes | BigQuery Studio notebooks use Colab Enterprise runtimes. You’re billed per runtime-hour based on machine type whenever the notebook is running or scheduled |
BigQuery ML | Training and prediction use standard BigQuery compute pricing ($6.25 per TiB scanned). Remote models that run on Vertex AI incur Vertex AI charges |
BI Engine | An in-memory accelerator you reserve by GiB/hour (region-based pricing). It speeds up dashboards and BI queries, but adds a separate hourly cost |
Flat-rate/capacity | You can buy dedicated slots (virtual CPUs) instead of paying per query. Billed per slot-hour under Standard, Enterprise, or Enterprise Plus editions, with 1- or 3-year commit discounts or autoscaling |
Free operations and tiers | Loading and exporting (same region) are free. You also get 1 TiB of queries and 10 GB of storage free every month; the Sandbox offers the same limits without a billing account |
You can find detailed BigQuery pricing here.
Why BigQuery’s pricing feels complicated
Here is the thing.
BigQuery’s pricing model is complex because it’s built for high flexibility. Here’s why:
- Two pricing systems in one. BigQuery uses both pay-per-query and capacity (slot-based) pricing. This may make it flexible, but it also makes it hard to compare or predict. You’re charged either by bytes scanned or slot hours, depending on which model you use.
- Query design affects your bill. Costs don’t depend on how long a query runs—they depend on how much data it scans. A poorly written query or a missing filter can significantly increase your bill, even if the process is quick.
- Multi-layered pricing. Compute, storage, streaming, ML, BI Engine, and cross-region access are all priced differently. Each layer has its own rules, which means small usage changes can shift your monthly total.
- Constant feature updates. Google keeps adding new products and editions such as BigQuery ML, BigLake, Omni, and slot-based tiers, each with unique pricing. It’s powerful but complex to keep track of.
- Cloud costs are invisible by nature. BigQuery’s pricing mirrors how Google’s backend uses compute, storage, and network resources. You don’t see those directly, so the connection between what you run and what you pay often feels unclear. This is where CloudZero brings order to the chaos.
BigQuery Vs. Snowflake (And Other Cloud Data Warehouses)
BigQuery and Snowflake both handle massive data, but they work differently. BigQuery is serverless — Google manages everything for you. Snowflake provides dedicated compute clusters, so you can control performance and costs more directly.
BigQuery runs only on Google Cloud and scales automatically. It’s simple to use and great for ad-hoc queries or real-time analytics. Snowflake works on AWS, Azure, and GCP, making it ideal for multi-cloud environments and steady, predictable workloads.
BigQuery charges for data processed and stored. Snowflake bills for compute time and storage, and you pay while the warehouses are running. You can pause them anytime. See Snowflake pricing here.
BigQuery suits teams that want simplicity, automation, and streaming power. Snowflake fits those who need flexibility, control, and isolated performance across clouds.
In short, both are fast and scalable. Your choice depends on how much control you want and where your data lives.
- See also how AWS Redshift compares to Snowflake, Databricks, Azure Synapse, and more. Or explore GCP cost optimization tools to reduce your overall Google Cloud spend.
- You can also use BigQuery with MongoDB to run analytics on your application data. See MongoDB pricing along with practical MongoDB cost optimization tips.
How To Manage And Understand Your BigQuery Costs With CloudZero
With CloudZero, you get:
- Complete cost visibility. CloudZero ingests your entire Google Cloud bill, not just BigQuery. It organizes spend by product, team, or environment so you can see exactly how cloud storage, dataflow, and BigQuery interact and drive total cost. For a deeper look at how GCP billing works across services, see GCP Cost Reporting.
- Clear unit economics. You can measure metrics such as cost per query, cost per customer, or cost per dataset. This gives finance and engineering a shared language to evaluate efficiency. This also supports seamless budgeting and forecasting.
- Real-time monitoring and alerts. CloudZero detects cost anomalies, spikes, or runaway jobs across all Google services. It alerts you before a sudden data transfer, streaming insert, or cross-region query that could inflate your bill.
- Informed pricing decisions. By correlating spend with performance, CloudZero helps you decide when to switch from on-demand to reserved slots and where to optimize other GCP services that feed into BigQuery.
 to see CloudZero in action and learn more about how it can help you optimize your GCP costs.
to see CloudZero in action and learn more about how it can help you optimize your GCP costs.











