
Cloud cost intelligence has moved beyond simple cost-cutting. Now, it’s about creating value. Cloud costs continue to rise, and workloads are becoming increasingly complex. Teams also need to understand what they’re spending, why, and how that spend ties to business results.
FinOps has become the framework for bringing finance and engineering together. It’s helping teams manage costs, improve margins, and plan with confidence.
But challenges remain. Hybrid and multi-cloud environments, unpredictable AI workloads, and limited visibility make it harder for teams to stay ahead.
That’s where cloud cost intelligence comes in. It delivers the context teams need to connect technical decisions to business outcomes — and to spend smarter.
What Is Cloud Cost Intelligence? (And Why Cost Intelligence Matters)
Cloud cost intelligence is cost data that is aligned with your business and stakeholders. Instead of simply telling you to cut costs, it tells you where you’re spending your money and (more importantly) what that means in the context of your business.
Instead of simply talking about the bill being “too high,” cost becomes a meaningful data point as you discuss trade-offs you could make — ranging from rewriting a feature to changing which pricing tier it belongs to.
Cloud cost intelligence begins by aligning cloud costs with the metrics that matter to everyone in your business — from individual engineers to your CEO. This kind of cost intelligence turns raw billing data into decisions. This includes answers to questions like:
- How much does it cost to build and run each product feature? Are our margins stronger on one product line than another? (See: Rule of 40 — a key metric for SaaS profitability)
- What is the unit cost of different units of value? (e.g., Lyft measures “cost per ride”)
- How is our cost changing over time across different dev teams and business initiatives?
- How much did we save by refactoring an application?
There are many ways to achieve cloud cost intelligence, ranging from building your own to using a SaaS solution like CloudZero — but there’s a common set of data that you’ll need for different stakeholders.
Report
Finance needs to prove AI’s return: CloudZero report
260 senior finance leaders (more than half CFOs) told us why the speed of seeing AI spend, not the size of it, separates who pulls ahead on AI from who gets burned.
Cloud Cost Intelligence For Finance
Finance’s purview is always the financial health of the business, so they care about margins and COGS.
Instead of simply measuring total AWS spending, finance needs data on specific products, features, and business initiatives — the kind of visibility that cloud cost management tools can provide. They also need to understand cloud unit economics and how costs align with key business metrics, such as transactions made or messages sent.
For SaaS companies, finance should understand the cost of each customer. This can inform decisions like renewals, as well as markets to invest in.
You could ask, for example, “Are we making higher margins off enterprise customers than SMB ones?”
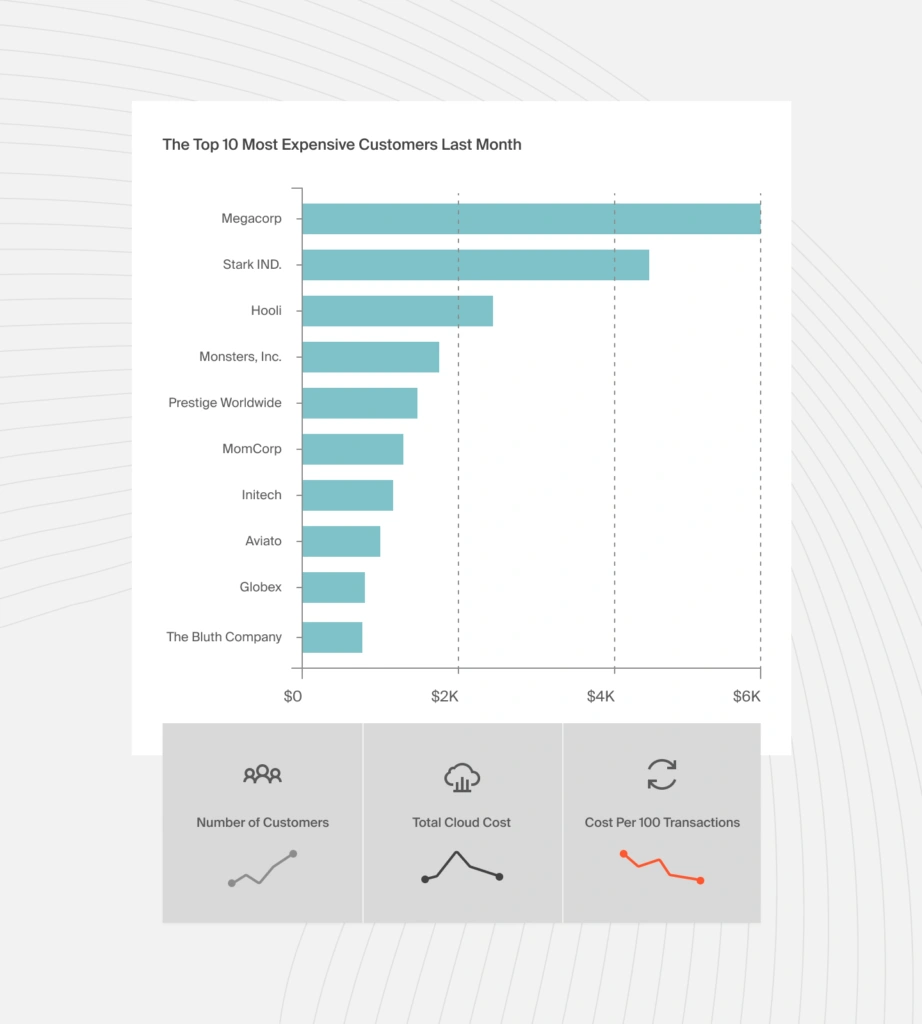
Customer-level cost insight for margin analysis
Cloud Cost Intelligence For Engineering Leaders
Engineering leaders should be the center of cloud cost intelligence.
Engineering teams need real-time visibility into how their work impacts spend. Alerts and cost metrics embedded in tools they already use, such as Slack, let them respond to budget changes without breaking their workflow.
With this visibility, engineers can track how deployments, scaling decisions, and new features influence spend. It empowers them to make better technical trade-offs, balance performance and cost, and address overspending before it escalates.
Cloud cost intelligence also bridges the gap between engineers and leadership. It helps teams align on priorities, manage technical debt with cost impact in mind, and report clearly on how engineering efforts drive business results.
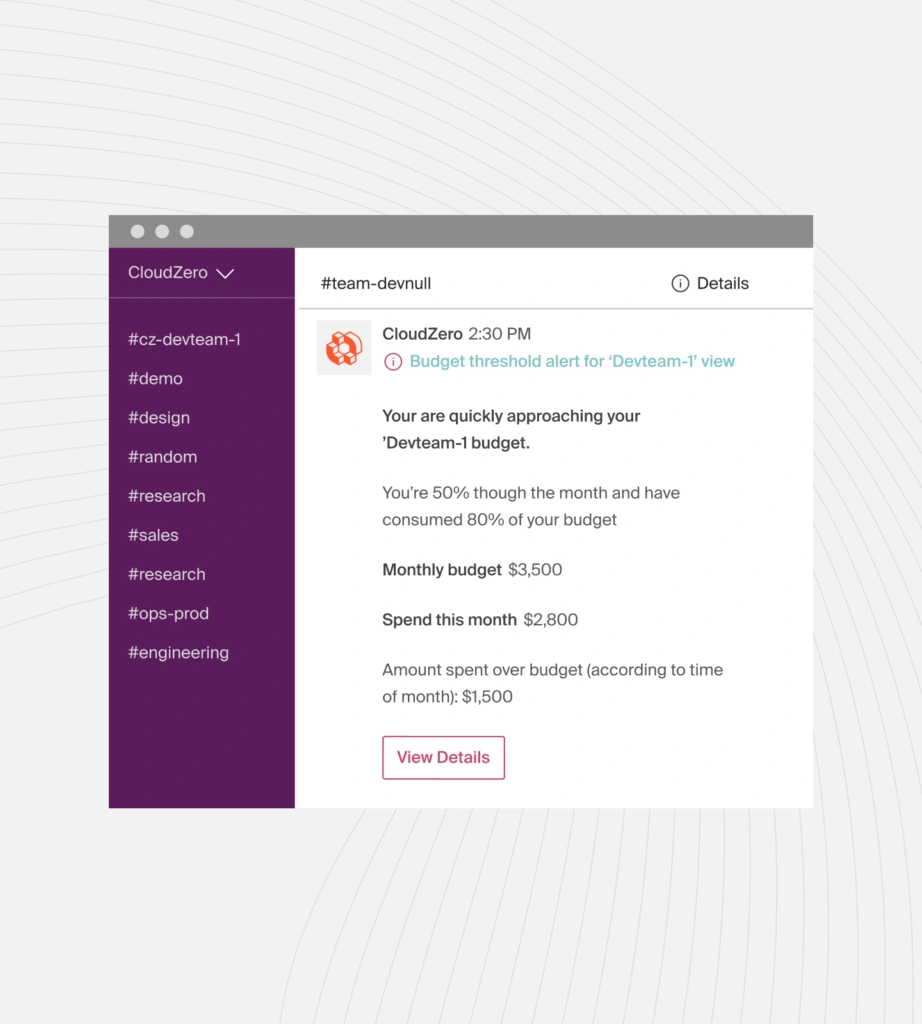
Cloud Cost Intelligence For Product Teams
Product teams use cloud cost intelligence to understand the true cost of every feature. This visibility helps them prioritize investments, validate pricing strategies, and build roadmaps grounded in cost and value. By aligning product metrics with unit costs, they can make informed trade-offs that support profitability.
Cloud Cost Intelligence For Developers
Developers need to understand the cost of the engineering decisions they make.
No, they don’t need to spend all day thinking about how they can save $5 — but if that $5 is multiplied by every transaction that takes place on the platform they’re building, it could have a massive impact on gross margins.
Engineering leaders need to empower their dev teams with two types of context.
The first is access to cost data in a way that is relevant and understandable to them. It should be aligned with the products and features they are building.
The second is the business context. Engineering leaders should pass down relevant context from the C-suite about how the products they’re building are going to be sold. If a product is being built for a self-serve free tier, it will probably have different unit economics than a product that is sold to a handful of large enterprise accounts.
Engineering leaders can set non-functional requirements and guide their teams during conversations about tradeoffs such as cost, availability, or speed.
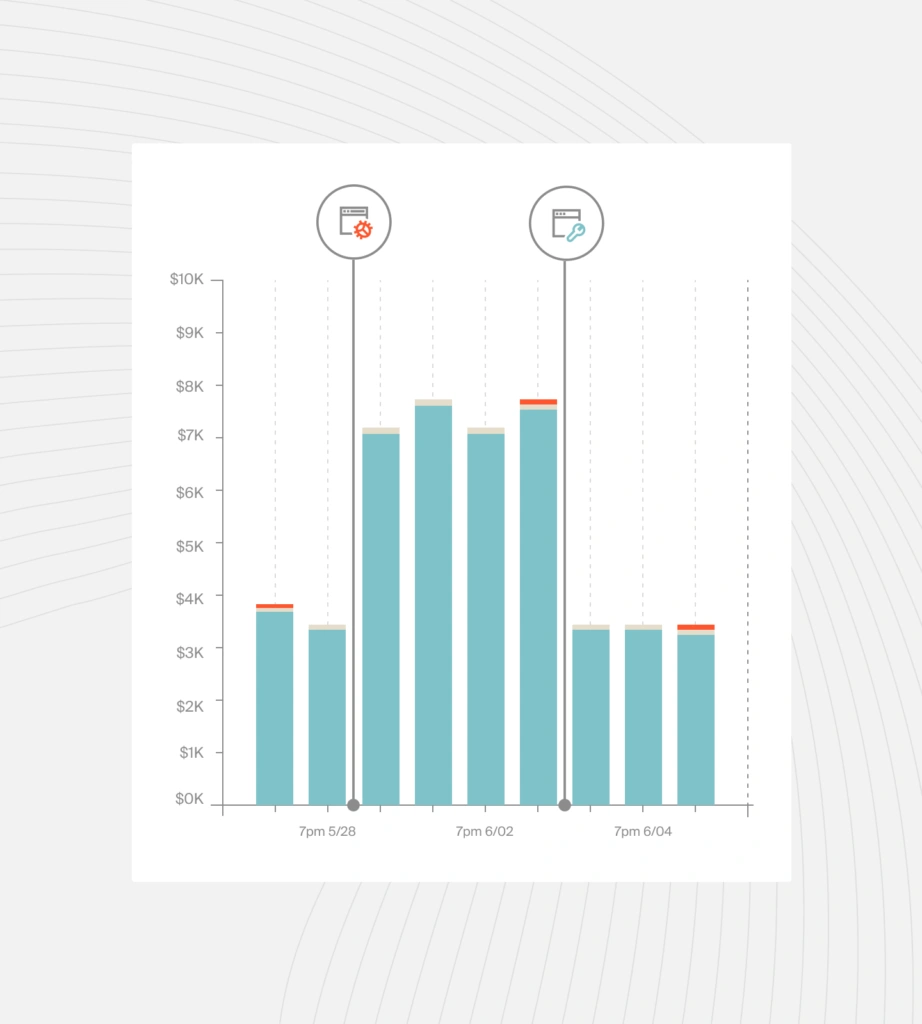
Cost data flowing into the dev workflow
Cloud Cost Intelligence For Security Teams
Security teams need to understand how security-related workloads drive cost. By mapping spend to tools, policies, and compliance efforts, they can plan budgets, flag unusual activity, and help the organization balance strong security with cost efficiency through cost anomaly alerts.
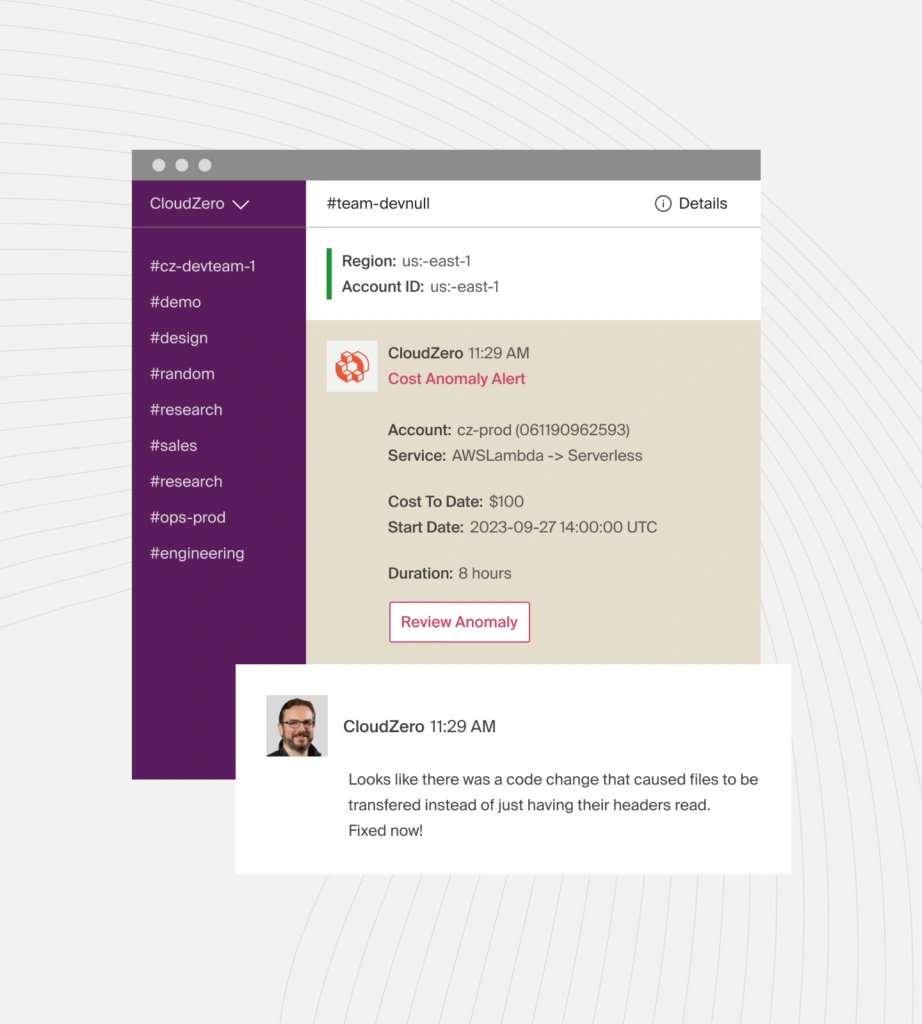
Cloud Cost Intelligence For AI Teams
AI workloads are expensive and unpredictable. Cost intelligence helps AI teams track spend by model, workload, or experiment. With the right data, they can control training costs, plan for scaling production models, and collaborate with finance to keep margins healthy as AI usage grows.
Related reads:
What next?
Take The Cost Intelligence Path With CloudZero
We’ve mostly been discussing the importance of understanding how much it costs to run a particular feature or application, but that’s not the only important distinction in cloud costs.
Every organization will incur cloud costs associated with research and development, as well as costs related to internal systems that don’t generate revenue.
These are certainly business expenses in the same way that office space and coffee are. Still, they should be broken out of the unit cost analysis of specific applications and features, because they don’t provide meaningful information about how profitable a certain feature is.
Nonetheless, these background costs shouldn’t be ignored, either.
In one case we saw, the company had a “playground” account for developers to try out new technology.
What they didn’t realize was that certain queries were costing $1,000 each — with a simple adjustment, they cut that number in half.
Being able to break costs down accurately is essential when talking with investors — otherwise, you risk making the product seem less profitable than it actually is. It’s also important for developing a long-term business strategy and making better decisions around pricing and feature offerings.
Enter CloudZero
CloudZero changes the way teams understand cloud spend. Instead of chasing costs after the bill arrives, you see what’s driving spend in real time — by product, feature, team, or customer.
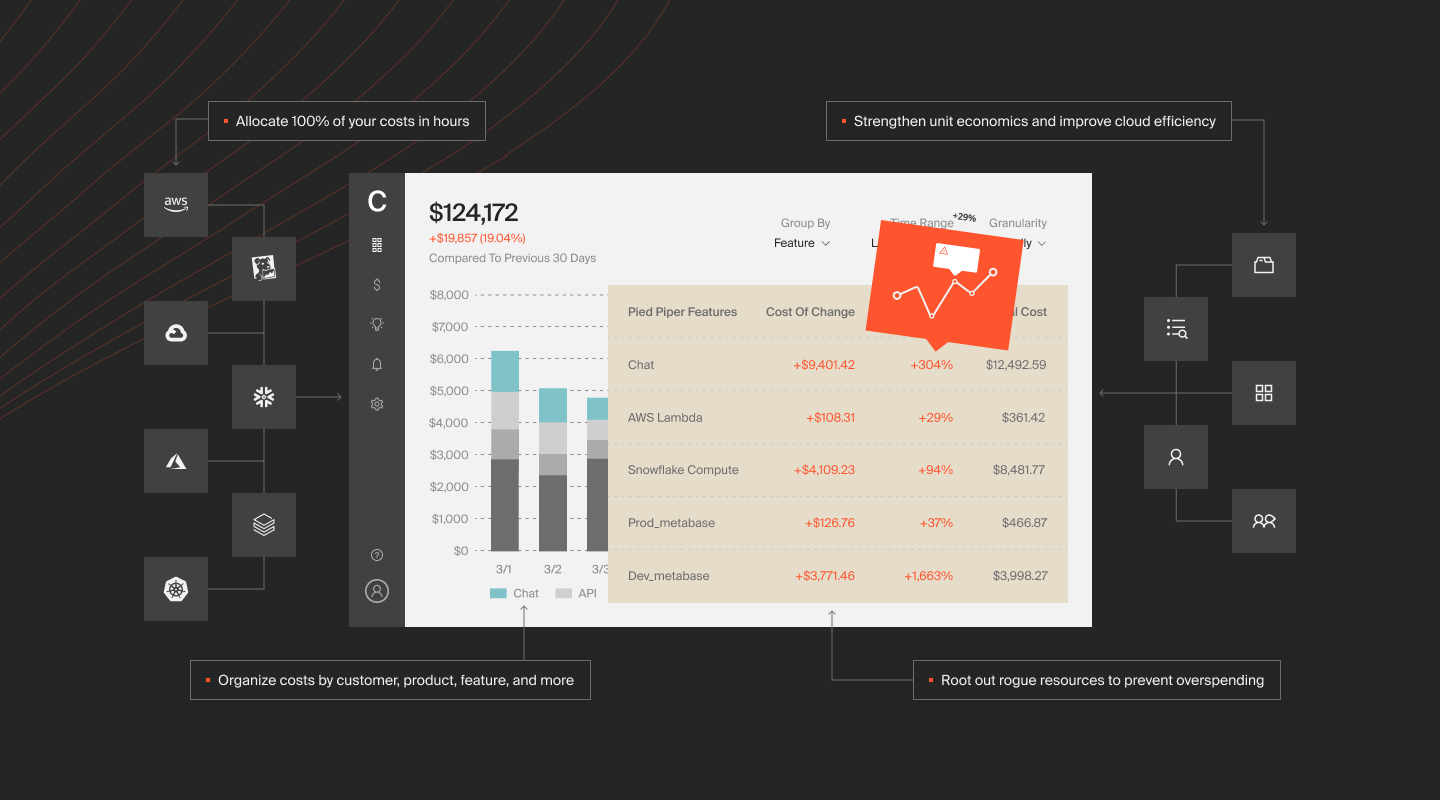
This is the cost intelligence way. It gives engineering, finance, and product teams shared visibility. It integrates technical choices with business outcomes. And it helps you control costs without slowing innovation.
With CloudZero, every dollar is tracked, explained, and aligned to your goals. That’s how leading companies such as Toyota, Duolingo, Drift, Skyscanner, and more trust and use CloudZero to strengthen margins, improve efficiency, and grow with confidence.
 and see how CloudZero turns raw cloud spend into actionable cost intelligence.
and see how CloudZero turns raw cloud spend into actionable cost intelligence.











