Quick Answer
Together AI pricing is usage-based, with serverless inference ranging from about $0.05 to $7.00 per million tokens depending on the model. Most commonly used models fall between $0.27 and $3.00 per million tokens. Fine-tuning starts at $0.48 per million tokens and scales with model size. Dedicated GPU endpoints are billed hourly, with examples such as H100 GPUs around $2.99/hour. New users often receive about $25 in free credits, and the platform supports 200+ open-source models. Together AI also provides 68 models at no cost, including production-grade options like Llama 3.3 70B, Qwen 2.5 variants, Gemma models, and Mistral Nemo.
This guide covers every dimension of Together AI cost: serverless rates, fine-tuning charges, GPU cloud pricing, the free tier, and how each compares to the alternatives. It assumes you’re evaluating Together AI for production workloads or scaling beyond free credits, and that cost decisions involve both engineering and finance.
Knowing the price of a token is easy. Knowing what your AI actually costs to run in production; per customer, per feature, per inference call, is a different problem entirely. One that grows more expensive every month you ignore it.
Together AI has built one of the most comprehensive open-source model platforms on the market, with pricing that undercuts proprietary providers like OpenAI by three to 10 times on comparable models. But cheaper tokens don’t automatically mean lower bills. CloudZero’s FinOps in the AI Era research found that one in five organizations experienced AI budget variance of 50% or more. A third didn’t discover cost overruns until the invoice arrived.
This guide covers every dimension of Together AI cost: serverless rates, fine-tuning charges, GPU cloud pricing, the free tier, and how each compares to the alternatives. More importantly, it covers what to do about it. Because the organizations that manage AI costs well don’t just track totals. They connect spend to value.
What Is Together AI And What Does It Do?
Together AI is a cloud platform built specifically for running, fine-tuning, and deploying AI models at scale. Founded by CEO Vipul Ved Prakash and a team that includes FlashAttention creator Tri Dao, the company has raised $534 million in total funding at a $3.3 billion valuation and calls its infrastructure “The AI Native Cloud” — purpose-built for model workloads, not repurposed from general compute.
Together AI’s research team has also advanced speculative decoding, an inference acceleration technique that generates tokens faster by using a smaller draft model to predict outputs that a larger model then verifies.
In practical terms, Together AI does three things:
- Hosts 200+ models behind a single API. Llama, DeepSeek, Qwen, Mistral, Kimi, Gemma, etc. are all accessible through an OpenAI-compatible endpoint, meaning you can swap providers without rewriting application code.
- Offers fine-tuning infrastructure with both LoRA and full fine-tuning, so teams can customize models on proprietary data without managing their own GPU clusters.
- Sells direct GPU access through instant and reserved clusters running NVIDIA H100, H200, and Blackwell B200 hardware, plus batch processing at scale (up to 30 billion tokens per model).
The platform competes with AWS Bedrock and SageMaker, Google Vertex AI, Azure OpenAI, and inference-focused providers like Fireworks AI, Replicate, and Groq. Where Together AI differentiates is breadth: few competitors offer the same combination of model variety, fine-tuning depth, and raw GPU access under one roof. Where it gets complicated is the pricing.
Together AI pricing model includes three deployment tiers, 200+ model-specific rates, and usage patterns that make forecasting genuinely difficult. Understanding it is the first step toward AI cost management. Serverless inference is where most teams start — and where most of the pricing complexity lives.

Research Report
FinOps In The AI Era: A Critical Recalibration
What 475 executives told us about AI and cloud efficiency.
How Does Together AI Serverless Pricing Work?
Serverless inference is the default starting point and where most Together AI API pricing conversations begin. Together AI API pricing is pay-per-token: you send requests through the API, Together AI manages the infrastructure, and you pay for each token processed. No capacity planning, no idle GPU costs.
The catch: every model has its own rate for input tokens and output tokens, and the range spans nearly two orders of magnitude. Choosing the wrong model for your workload doesn’t just affect quality. It also affects your bill by 10 times or more. for input tokens and output tokens, and the range spans nearly two orders of magnitude. Choosing the wrong model for your workload doesn’t just affect quality. It also affects your bill by 10 times or more.
Here’s the current serverless Together AI pricing per million tokens for the platform’s most popular models as of mid 2026:
|
Model |
Input ($/1M tokens) |
Output ($/1M tokens) |
|
GLM-5.1 |
$1.40 |
$4.40 |
|
MiniMax M2.7 |
$0.30 |
$0.06 (cached), $1.20 |
|
Kimi K2.6 |
$1.20 |
$0.20 (cached), $4.50 |
|
DeepSeek V4 Pro |
$2.10 |
$0.20 (cached), $4.40 |
|
Qwen3.6-Plus |
$0.50 |
$3.00 |
|
gpt-oss-120B |
$0.15 |
$0.60 |
|
LFM2 24B A2B |
$0.03 |
$0.12 |
|
Qwen3.5-397B-A17B |
$0.60 |
$3.60 |
|
MiniMax M2.5 |
$0.30 |
$0.06 (cached), $1.20 |
|
GLM-5 |
$1.00 |
$3.20 |
|
Qwen3-Coder-Next |
$0.50 |
$1.20 |
|
Kimi K2.5 |
$0.50 |
$2.80 |
Small models under 4B parameters start at roughly $0.10 per million tokens. Embedding models like M2-BERT run even cheaper, in the $0.008–$0.016 range.
Two patterns jump from this table. First, reasoning models like DeepSeek R1 charge asymmetric rates, $3.00 in, $7.00 out, because they generate substantially longer outputs by design. Second, Llama 4 Maverick at $0.27/$0.85 delivers GPT-4-class performance at roughly one-tenth the cost of OpenAI’s GPT-4o ($2.50/$10.00). That gap is the core reason open-source inference has shifted from experiment to production strategy.
Per-token price, though, is only one variable in the total inference cost equation. The real cost includes retrieval, embedding, caching, orchestration, and observability layers that individually look small but compound fast.
CloudZero’s analysis of production AI workloads shows the true cost of a resolved AI task is often 10–50x higher than the posted per-call price once the full stack is accounted for. That’s not a Together AI problem. It’s an architecture problem. The fix starts with visibility into what each layer actually costs.
How Much Does Together AI Fine-Tuning Cost?
Fine-tuning on Together AI is billed per token processed, not per GPU-hour. Total cost depends on model size, fine-tuning method (LoRA or full), and training type (supervised fine-tuning or direct preference optimization).
The formula: Total tokens = (epochs × training dataset tokens) + (evaluations × validation dataset tokens). Multiply by the per-token rate.
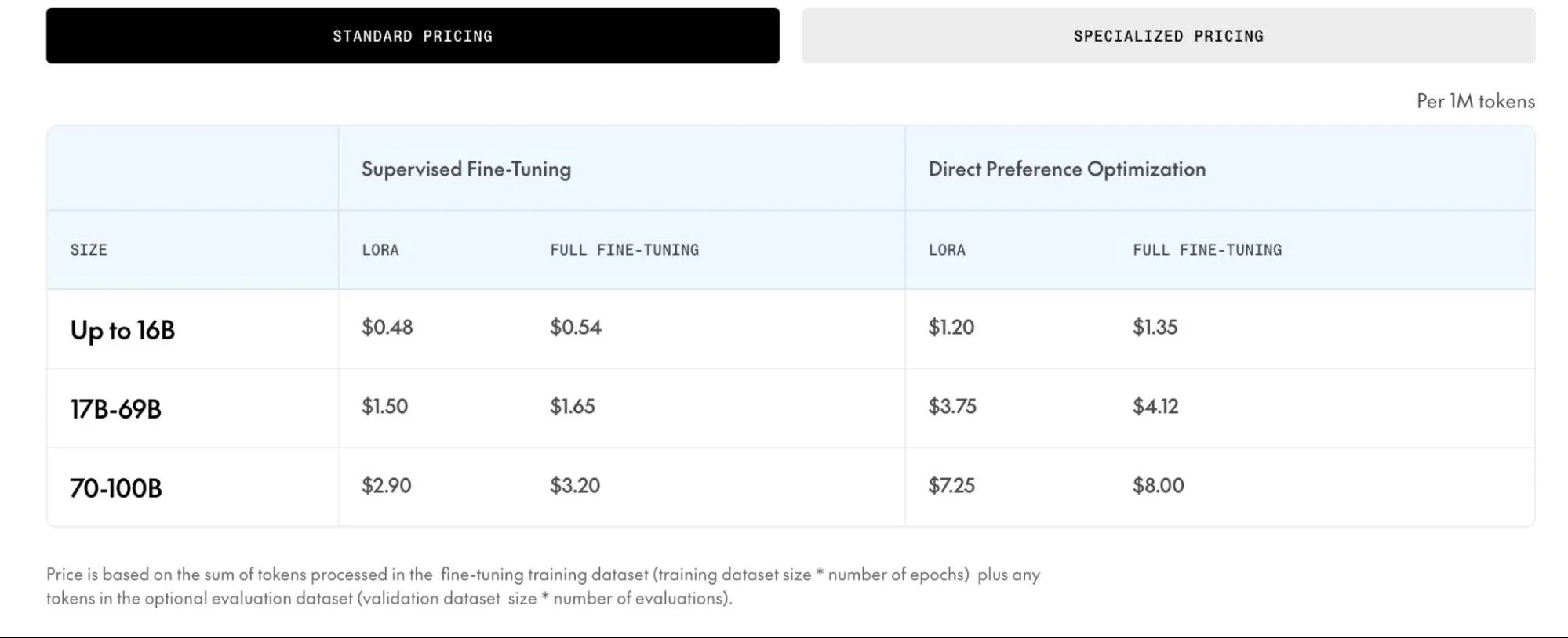
The hidden cost isn’t the per-token rate. It’s the iteration cycle. A single fine-tuning run on a 7B model with a moderate dataset might cost $10–$30. But production fine-tuning involves 5–15 experimental runs while adjusting hyperparameters, testing data mixes, and evaluating outputs. Budget five to 10 times the cost of a single run, and define success criteria before you start.
LoRA runs roughly 10% cheaper than full fine-tuning and trains faster, making it the default for most production use cases. Inference on fine-tuned LoRA adapters uses standard serverless rates plus a small overhead, which is cheaper than dedicated deployments for teams iterating on custom behavior.
The hidden cost isn’t the per-token rate. It’s the iteration cycle. A single fine-tuning run on a 7B model with a moderate dataset might cost $10–$30. But production fine-tuning involves 5–15 experimental runs while adjusting hyperparameters, testing data mixes, and evaluating outputs.
Budget five to 10 times the cost of a single run, and define success criteria before you start. Without that discipline, fine-tuning budgets behave exactly like the AI cost sprawl CloudZero sees across production environments: small experiments that never get cleaned up, quietly becoming permanent line items.
Fine-tuning, though, is still a serverless operation. When your workloads outgrow shared infrastructure, or when you need the control that comes with dedicated hardware, the economics shift again.
What Does Together AI GPU Cloud Pricing Look Like?
Together AI GPU pricing is structured around on-demand and commitment-based tiers. For teams that need dedicated hardware, large-scale training, high-throughput production inference, or workloads that can’t tolerate shared infrastructure, Together AI offers direct GPU access through its instant clusters.
|
Hardware |
On-demand ($/hr) |
Reserved (1 Week – 1 Month) |
Reserved (2 – 3 Months) |
Reserved (4 – 6 Months) |
|
NVIDIA HGX H100 |
$3.49 |
$2.99 |
$2.69 |
$2.55 |
|
NVIDIA HGX H200 |
$4.19 |
$3.49 |
$3.19 |
$2.89 |
|
NVIDIA HGX B200 (Blackwell) |
$7.49 |
$7.15 |
$6.75 |
$6.39 |
Note: For 6+ months reserved pricing and NVIDIA GB200 NVL72 and NVIDIA GB300 NVL72 pricing, contact sales.
For context, cloud GPU pricing across the major hyperscalers runs approximately $3.00–$6.98 per H100 GPU-hour on demand. Together AI’s rates are competitive with GCP and well below Azure, though the comparison isn’t apples-to-apples, hyperscaler instances include deeper ecosystem integration with IAM, networking, and monitoring.
The GPU pricing conversation is where cost management stops being about rates and starts being about utilization. An H100 at $2.99/hour costs $2,153/month running 24/7. That’s competitive if your workload sustains 80%+ GPU utilization. But research consistently shows that production AI workloads average under 50% sustained GPU utilization even under load.
As Erik Peterson, co-founder and CTO of CloudZero, put it: “AI experiments in your business are icebergs.” The visible spend is the surface. The real cost lives in the utilization patterns underneath. Before committing to any of these tiers, though, most teams start with a lower-stakes question: what can you test for free?
What Do You Get With The Together AI Free Tier?
The Together AI free tier gives new accounts $25 in Together AI free credits, a fivefold increase from the previous $5, with no credit card required. Together AI also provides 68 models at no cost, including production-grade options like Llama 3.3 70B, Qwen 2.5 variants, Gemma models, and Mistral Nemo.
For startups, the offer gets more interesting. Together AI’s Startup Accelerator provides $15,000–$50,000 in platform credits based on company stage, one of the more generous programs in the open-source AI space.
A few things the free tier doesn’t tell you: some premium models and dedicated endpoints require Build Tier 2+, which becomes available after $5 in actual spend. Together AI rate limits also vary by tier, free accounts face stricter throttling on requests per minute and tokens per minute than paid accounts, so prototype latency and throughput won’t match production performance. $25 goes a lot further on Llama 3.2 3B ($0.10/M tokens) than on DeepSeek R1 ($3.00/$7.00 per million tokens), model choice determines if your credits last a week or an afternoon.
The free credits solve the evaluation problem. They don’t solve the production economics problem. For that, you need to track what every inference actually costs your business, which brings us to comparison and optimization.
How Does Together AI Pricing Compare To Alternatives?
The comparison that matters isn’t “which provider is cheapest per token”, it’s “which delivers the best cost-per-unit-of-value for your specific workload.”
Together AI sits in the middle of the open-source inference market, slightly above Groq on price but with far broader model selection and fine-tuning. It’s about 2x more expensive than DeepSeek’s own API for DeepSeek models, but provides a US-based host with consistent latency. Against proprietary providers, the gap is stark: Llama 3.3 70B at $0.88/$0.88 is roughly 4x cheaper than GPT-5.4 on output.
For a team processing 50 million output tokens per month, the difference between $0.88 and $10.00 per million is $456,000 annualized. That’s not a rounding error. That’s headcount.
But here’s the reality that pricing pages don’t show: multi-provider architectures are now standard. CloudZero’s AI cost management data shows organizations routinely running Together AI for bulk inference, OpenAI for complex reasoning, and Anthropic for safety-critical workflows, all simultaneously.
When your AI stack spans three providers, four GPU types, and a dozen models, the “cheapest provider” question becomes irrelevant. The real question is: what does each inference actually cost your business, and is that cost going up or down relative to the value it creates?
How Can You Reduce Together AI Costs?
Lower per-token prices have a paradoxical effect: they tend to increase total spend, because teams deploy more models to more use cases when unit price drops. CloudZero’s FinOps in the AI Era research found that 40% of organizations now spend more than $10 million annually on AI, while mean Cloud Efficiency Rates have declined from 80% to 65% year over year. Spending more while getting less efficient isn’t a pricing problem. It’s a management problem.
1. Right-Size Your Model Selection (Typical Savings: 50–90% On Qualifying Requests)
Llama 3.3 70B at $0.88/M tokens is 9x more expensive than a 3B model at $0.10/M tokens. For classification, extraction, and structured output tasks, smaller models deliver equivalent accuracy. Test before you default to large. If 30% of your traffic shifts to a smaller model, that’s a 20%+ cut in total inference cost.
2. Compress Your Prompts (Typical Savings: 70–94% On Input Costs)
Every unnecessary token costs on input and influences output length. Techniques like prompt compression and semantic chunking achieve 70–94% cost savings in production AI systems. At 10 million requests per month, tighter prompts alone save $500–$1,500 before any infrastructure change.
3. Batch Non-Real-Time Workloads (Typical Savings: 50% Flat)
Together AI offers batch processing at discounted rates for workloads that can tolerate latency. Nightly data enrichment, bulk classification, content generation, anything with a 24-hour window should run as batch.
4. Cache At Multiple Layers (Typical Savings: 15–90% Depending On Layer)
Together AI supports prompt caching for recurring prefix patterns. At the application layer, a semantic cache eliminates 15–40% of redundant inference calls. Anthropic’s prompt caching cuts input costs by up to 90% for repeated system prompts. Same principle, any provider. The cheapest inference is the one that never runs.
5. Route Requests By Complexity (Typical Savings: 50–70% On Average Cost Per Call)
A routing layer that sends simple queries to Llama 3.2 3B and reserves DeepSeek R1 for complex reasoning can cut average cost per call by 50–70%. This is the single highest-impact move in LLM cost optimization for teams running multiple models.
6. Monitor Utilization Before Committing To Dedicated (Typical Savings: Prevents 2–3x Overcommit)
A spike-driven workload averaging low utilization will cost more on dedicated instances than serverless, even if peaks are expensive. Track your actual request patterns for two weeks before signing up for reserved capacity. The data should drive the commitment, not the other way around.
7. Track Cost Per Unit, Not Just Total Cost (Typical Savings: 20–40% Through Attribution)
Total inference spend rising is not inherently bad, it might mean your product is growing. What matters is efficiency: is each dollar of AI spend producing more or less output than it did last month? If your Together AI bill doubles while your user base triples, you’re scaling well. If the bill doubles and usage is flat, you have a problem. That unit economics lens is the only way to tell the difference, and it’s where everything connects back to cost intelligence.
How Does CloudZero Help You Manage Together AI And All Your AI Costs?
Together AI’s dashboard shows what you spent on their platform. Useful for a single-provider prototype. Production AI, though, doesn’t live on one provider.
A typical 2026 AI stack includes Together AI for open-source inference, OpenAI or Anthropic for proprietary models, GPU instances on AWS, Azure, or GCP for self-hosted workloads, plus Databricks or Snowflake for data processing. Each provider has its own billing format and its own version of “what you spent.” None of them answer the question that actually matters: across everything, was the spend worth it?
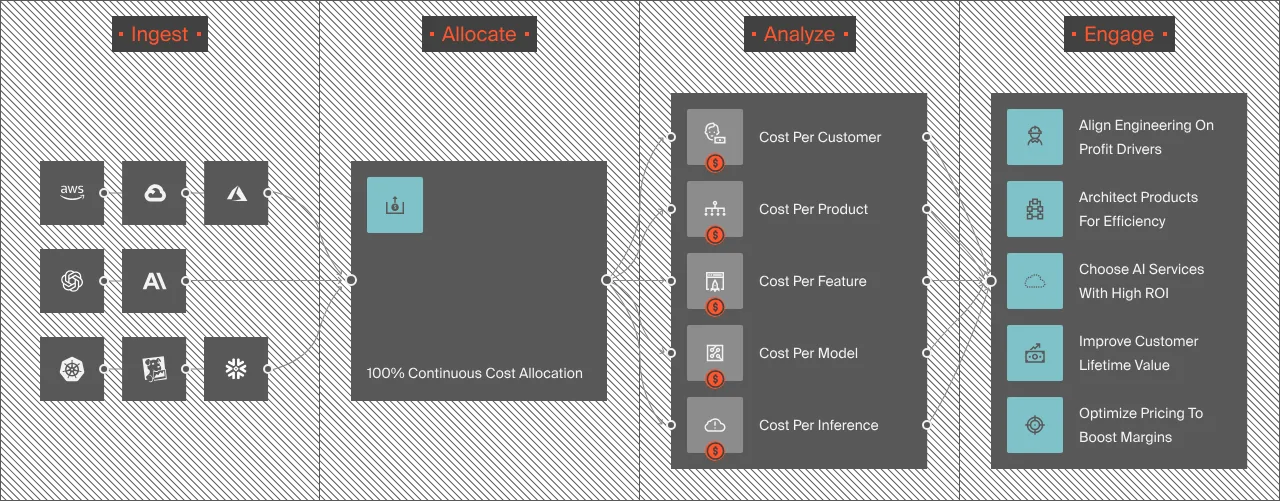
CloudZero is a cloud cost intelligence platform that answers that question. Here’s specifically what it does for teams running Together AI alongside other providers.
- Cross-provider AI cost visibility. CloudZero ingests billing data from AWS, Azure, GCP, Oracle Cloud, OpenAI, Anthropic, Snowflake, Databricks, Datadog, MongoDB, and more through a single integration layer. Together AI costs flow in via the AnyCost API, which normalizes any cost source into the same data model. Every dollar of AI spend, regardless of where it originated, lands in one view, allocated and attributable.
- CloudZero was the first cloud cost platform to integrate directly with Anthropic, and its OpenAI integration delivers cost and usage data by model, team, feature, and customer.
- Cost per customer, cost per feature, cost per inference. This is CloudZero’s core differentiator, and the reason it matters for Together AI users specifically. Instead of seeing “we spent $14,000 on inference last month,” you see that $8,200 went to your recommendations engine serving 40,000 customers ($0.21 per customer per month), $3,100 went to search, and $2,700 went to an internal tool used by 12 people ($225 per user). One is efficient. One probably isn’t. Without unit economics, you’d never know, and your finance team would treat all $14,000 as a single line item to cut.
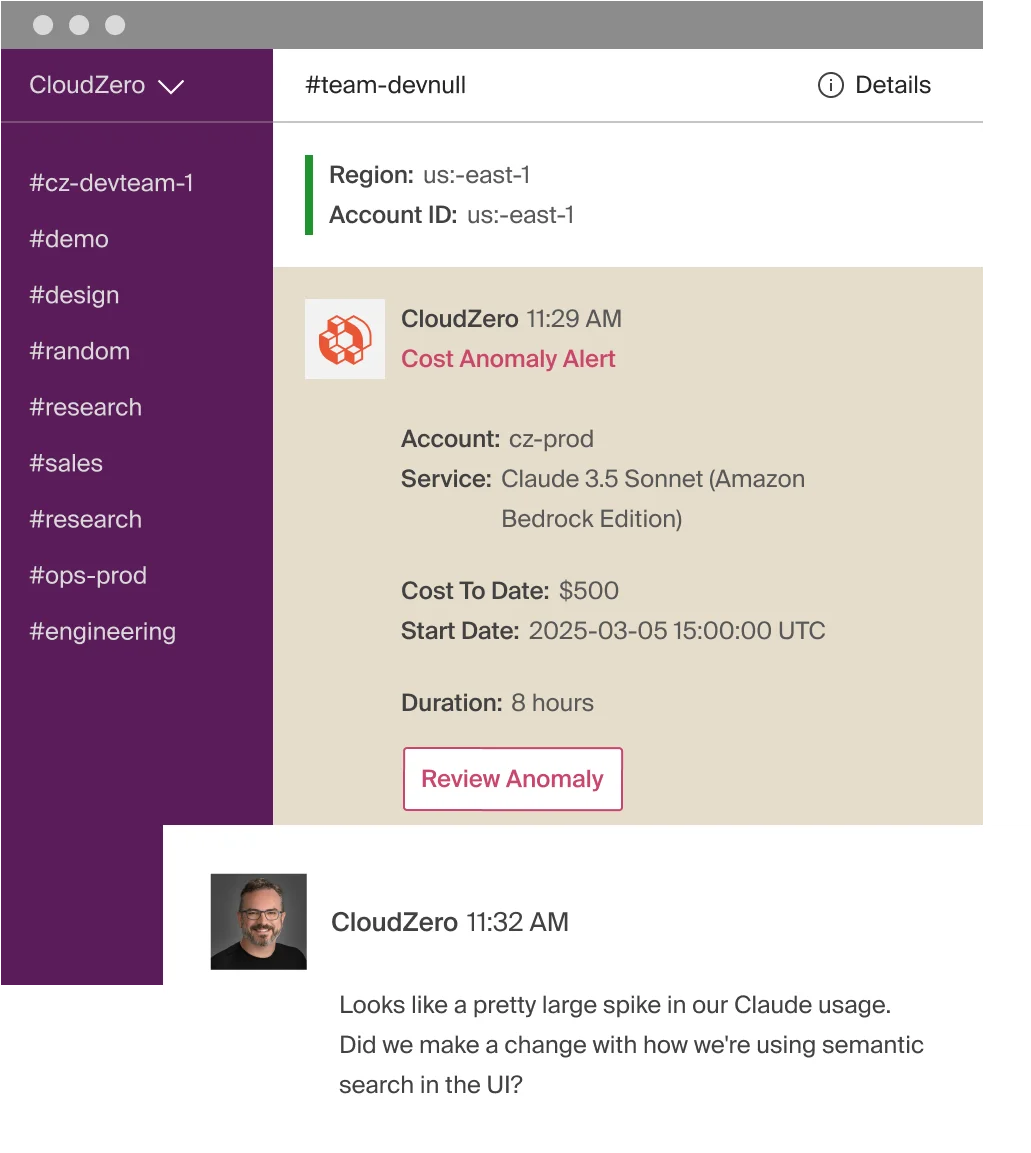
- Anomaly detection that routes to the right team. If your Together AI spend spikes because a prompt regression doubled average token count, or a new feature launch tripled inference volume overnight, CloudZero flags it in real time. Native dashboards show you the damage after the month closes. CloudZero shows you the anomaly while there’s still time to act, and routes the alert to the team that owns the workload, not a generic Slack channel.
- Forecasting from real usage, not averages. CloudZero builds cost forecasts from actual consumption patterns, giving finance teams projections grounded in real engineering behavior. For teams whose AI spend changes monthly as models, workloads, and user volumes shift, real-data forecasting is the difference between a budget and a guess.
- GPU workload attribution. For self-hosted models on GPU infrastructure, CloudZero’s GPU reservation attribution connects every dollar of GPU spend to the training job, inference endpoint, or team that consumed it. Most Kubernetes cost tools either ignore GPU attribution or handle it inconsistently. CloudZero solved this at the agent level, automatically, no configuration required.
Organizations including Toyota, Duolingo, Grammarly, DraftKings, Moody’s, and Skyscanner trust CloudZero to manage over $15 billion in cloud and AI spend. One global SaaS platform managing costs across 50+ LLMs uncovered $1 million+ in immediate AI savings after implementing CloudZero, with a 50%+ reduction in compute costs. Upstart saved $20 million. PicPay saved $18.6 million.
Together AI gives you competitive per-token pricing. CloudZero tells you if those tokens are producing value. That’s the difference between managing a bill and managing a business.  or get a free cloud cost assessment to see where your AI and cloud costs currently stand. You can also take a self-guided product tour to experience CloudZero for yourself.
or get a free cloud cost assessment to see where your AI and cloud costs currently stand. You can also take a self-guided product tour to experience CloudZero for yourself.
Key Takeaways
- Together AI serverless inference ranges from about $0.05 to $7.00 per million tokens, with most production models between $0.27 and $3.00.
- GPU hourly rates start at $2.55/hour (H100 reserved) and go up to $7.49/hour (B200 on-demand). Utilization below 50% makes dedicated instances more expensive than serverless.
- The $25 free credit tier and 68 free models make evaluation low-risk, but prototype economics don’t predict production costs.
- Open-source inference through Together AI is typically three to 10 times cheaper than proprietary providers for comparable model quality.
- Multi-provider AI stacks are now standard. Tracking cost per unit of value across all providers — not just per-token price on one — is the only way to know if AI spend is producing returns.
Frequently Asked Questions About Together AI Pricing


FinOps In The AI Era: A Critical Recalibration
What 475 executives told us about AI and cloud efficiency.